1. Beautiful Soup的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
2. Beautiful Soup 安装
pip install beautifulsoup4
3. 创建 Beautiful Soup 对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
另外,我们还可以用本地 HTML 文件来创建对象,例如
soup = BeautifulSoup(open('index.html'))
下面我们来打印一下 soup 对象的内容,格式化输出
print soup.prettify()
基本使用
标签选择器 在快速使用中我们添加如下代码: print(soup.title) print(type(soup.title)) print(soup.head) print(soup.p) 通过这种soup.标签名 我们就可以获得这个标签的内容 这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如上面我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容 获取名称 当我们通过soup.title.name的时候就可以获得该title标签的名称,即title 获取属性 print(soup.p.attrs['name']) print(soup.p['name']) 上面两种方式都可以获取p标签的name属性值 获取内容 print(soup.p.string) 结果就可以获取第一个p标签的内容: The Dormouse's story 嵌套选择 我们直接可以通过下面嵌套的方式获取 print(soup.head.title.string)
子节点和子孙节点
contents的使用
通过下面例子演示:
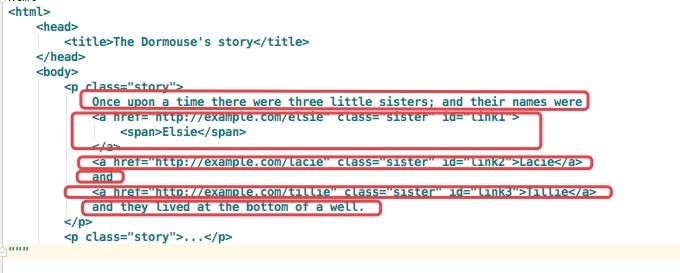
html = """ <html> <head> <title>The Dormouse's story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html,'lxml') print(soup.p.contents)
结果是将p标签下的所有子标签存入到了一个列表中
列表中会存入如下元素

children的使用
通过下面的方式也可以获取p标签下的所有子节点内容和通过contents获取的结果是一样的,但是不同的地方是soup.p.children是一个迭代对象,而不是列表,只能通过循环的方式获取素有的信息
print(soup.p.children)
for i,child in enumerate(soup.p.children):
print(i,child)
通过contents以及children都是获取子节点,如果想要获取子孙节点可以通过descendants
print(soup.descendants)同时这种获取的结果也是一个迭代器
父节点和祖先节点
通过soup.a.parent就可以获取父节点的信息
通过list(enumerate(soup.a.parents))可以获取祖先节点,这个方法返回的结果是一个列表,会分别将a标签的父节点的信息存放到列表中,以及父节点的父节点也放到列表中,并且最后还会讲整个文档放到列表中,所有列表的最后一个元素以及倒数第二个元素都是存的整个文档的信息
兄弟节点
soup.a.next_siblings 获取后面的兄弟节点
soup.a.previous_siblings 获取前面的兄弟节点
soup.a.next_sibling 获取下一个兄弟标签
souo.a.previous_sinbling 获取上一个兄弟标签
get_text()
如果只想得到tag中包含的文本内容,那么可以调用 get_text() 方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
markup = '<a href="http://example.com/">\nI linked to <i>example.com</i>\n</a>' soup = BeautifulSoup(markup) soup.get_text() u'\nI linked to example.com\n' soup.i.get_text() u'example.com'
可以通过参数指定tag的文本内容的分隔符:
# soup.get_text("|")
u'\nI linked to |example.com|\n'
还可以去除获得文本内容的前后空白:
# soup.get_text("|", strip=True)
u'I linked to|example.com'
或者使用 .stripped_strings 生成器,获得文本列表后手动处理列表:
[text for text in soup.stripped_strings]
# [u'I linked to', u'example.com']
.string
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点:
title_tag.string
# u'The Dormouse's story'
如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同:
head_tag.contents # [<title>The Dormouse's story</title>] head_tag.string # u'The Dormouse's story'
如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None :
print(soup.html.string)
# None
参考文档:https://cuiqingcai.com/1319.html