Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
四种对象:
Tag: 标签对象
NavigableString : 字符内容操作对象
BeautifulSoup: 文档对象
Comment:
下表列出了主要的解析器,以及它们的优缺点

一.bs4常用操作
下面的代码为打开的文件代码
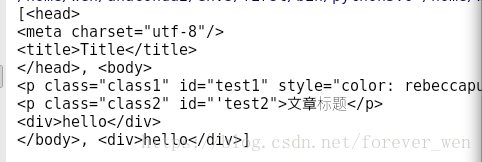
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p id="test1" class="class1" style="color: rebeccapurple">westos1</p>
<p id="'test2" class="class2">文章标题</p>
<div>hello</div>
</body>
</html>
1.获取标签内容
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 获取标签, 默认获取找到的第一个符合的内容
print(soup.title)
print(type(soup.title))
print(soup.p)
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 获取标签, 默认获取找到的第一个符合的内容
print(soup.title)
print(type(soup.title))
print(soup.p)

2.获取标签的属性及属性的修改
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
tag = soup.p # 每个tag都有自己的名字,通过 .name 来获取
print(tag.name)
print(soup.p.attrs) #直接”点”取属性
# 获取标签指定属性的内容
print(soup.p['id'])
print(soup.p['class'])
print(soup.p['style'])
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
tag = soup.p # 每个tag都有自己的名字,通过 .name 来获取
print(tag.name)
print(soup.p.attrs) #直接”点”取属性
# 获取标签指定属性的内容
print(soup.p['id'])
print(soup.p['class'])
print(soup.p['style'])

from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 获取标签指定属性的内容
print(soup.p['id'])
# 对属性进行修改
soup.p['id'] = 'modifyid'
print(soup.p)
print(type(soup.p))

3. 获取标签的文本内容
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(dir(soup.title))
print(soup.title.text)
print(soup.title.string)
print(soup.title.name)
print(soup.head.title.string)
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(dir(soup.title))
print(soup.title.text)
print(soup.title.string)
print(soup.title.name)
print(soup.head.title.string)
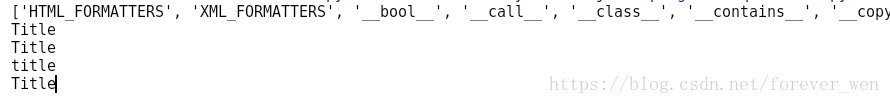
4. 操作子节点
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(soup.head.contents)
print(soup.head.children)
for el in soup.head.children:
print('--->', el)
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(soup.head.contents)
print(soup.head.children)
for el in soup.head.children:
print('--->', el)

5.面向对象的匹配
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 查找指定的标签内容(指定的标签)
res1 = soup.find_all('p')
print(res1)
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 查找指定的标签内容(指定的标签)
res1 = soup.find_all('p')
print(res1)

对于正则表达式进行编译, 提高查找速率
from bs4 import BeautifulSoup
import re
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 查找指定的标签内容(指定的标签)--与正则的使用
res1 = soup.find_all(re.compile(r'd+'))
print(res1)
###仔细查找
import re
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 详细查找标签
print(soup.find_all('p', id='test1'))
print(soup.find_all('p', id=re.compile(r'test\d{1}')))
print(soup.find_all('p', class_="class1"))
print(soup.find_all('p', class_=re.compile(r'class\d{1}')))
# 查找多个标签
print(soup.find_all(['p', 'div']))
print(soup.find_all([re.compile('^d'), re.compile('p')]))
# 内容的匹配
print(soup.find_all(text='文章标题'))
print(soup.find_all(text=re.compile('标题')))
print(soup.find_all(text=[re.compile('标题'), 'Title']))

6.CSS匹配
import re
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# CSS常见选择器: 标签选择器(div), 类选择器(.class1), id选择器(#idname), 属性选择器(p[type="text"])
# 标签选择器(div)
res1 = soup.select("p")
print(res1)
# 类选择器(.class1)
res2 = soup.select(".class2")
print(res2)
# id选择器(#idname)
res3 = soup.select("#test1")
print(res3)
# 属性选择器(p[type="text"]
print(soup.select("p[id='test1']"))
print(soup.select("p['class']"))
import re
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# CSS常见选择器: 标签选择器(div), 类选择器(.class1), id选择器(#idname), 属性选择器(p[type="text"])
# 标签选择器(div)
res1 = soup.select("p")
print(res1)
# 类选择器(.class1)
res2 = soup.select(".class2")
print(res2)
# id选择器(#idname)
res3 = soup.select("#test1")
print(res3)
# 属性选择器(p[type="text"]
print(soup.select("p[id='test1']"))
print(soup.select("p['class']"))
关于bs4的更多操作可以参考以下文档
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id82

二.练习
1.获取豆瓣最新电影的电影名称,id号,演员和导演
1)以文件的形式保存到本地
import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/cinema/nowplaying/xian/"
# 1). 获取页面信息
response = requests.get(url)
content = response.text
# print(content)
# 2). 分析页面, 获取id和电影名
soup = BeautifulSoup(content, 'lxml')
# 线找到所有的电影信息对应的li标签;
nowplaying_movie_list = soup.find_all('li', class_='list-item')
# 存储所有电影信息[{'title':"名称", "id":"id号"}]
# 依次遍历每一个li标签, 再次提取需要的信息
for item in nowplaying_movie_list:
print(item)
# print(type(item['data-title']))
with open('movie.txt','a+') as f:
f.write("影名:" + item['data-title']+ ","
+"id:" + item['id'] + ","
+ "演员表:" + item['data-actors'] + ","
+ "导演:" + item['data-director'] +'\n')
2)以列表的形式输出

import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/cinema/nowplaying/xian/"
# 1). 获取页面信息
response = requests.get(url)
content = response.text
# 2). 分析页面, 获取id和电影名
soup = BeautifulSoup(content, 'lxml')
# 线找到所有的电影信息对应的li标签;
nowplaying_movie_list = soup.find_all('li', class_='list-item')
# 存储所有电影信息[{'title':"名称", "id":"id号"}]
movies_info = []
# 依次遍历每一个li标签, 再次提取需要的信息
for item in nowplaying_movie_list:
nowplaying_movie_dict = {}
# 根据属性获取title内容和id内容
# item['data-title']获取li标签里面的指定属性data-title对应的value值;
nowplaying_movie_dict['title'] = item['data-title']
nowplaying_movie_dict['id'] = item['id']
nowplaying_movie_dict['actors'] = item['data-actors']
nowplaying_movie_dict['director'] = item['data-director']
# 将获取的{'title':"名称", "id":"id号"}添加到列表中;
movies_info.append(nowplaying_movie_dict)
print(movies_info)
