spring MVC中的controller是单例模式(只是表示多个请求变量共享),但是是多线程,各个线程之间不影响!
spring mvc 的Controller类默认Scope是单例(singleton)的
By Lee - Last updated: 星期一, 二月 10, 2014 Leave a Comment
使用Spring MVC有一段时间了,之前一直使用Struts2,在struts2中action都是原型(prototype)的, 说是因为线程安全问题,对于Spring MVC中bean默认都是(singleton)单例的,那么用@Controller注解标签注入的Controller类是单例实现的?
测试结果发现spring3中的controller默认是单例的,若是某个controller中有一个私有的变量i,所有请求到同一个controller时,使用的i变量是共用的,即若是某个请求中修改了这个变量a,则,在别的请求中能够读到这个修改的内容。 若是在@Controller之前增加@Scope(“prototype”),就可以改变单例模式为多例模式
redis与memcached的区别
0.Redis只使用单核,而Memcached可以使用多核
1.存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化
2.数据支持类型:
redis在数据支持上要比memecache多的多。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
3.使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4.运行环境不同:
redis目前官方只支持Linux 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
设计模式的六大原则
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;F:\Program Files\IBM\WebSphere MQ\java\lib\com.ibm.mqjms.jar;F:\Program Files\IBM\WebSphere MQ\java\lib\com.ibm.mq.jar
单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系(对类进行修改时尽量不要重写父类方法也不要重载父类方法);依赖倒置原则告诉我们要面向接口编程(高层不应该依赖于底层而是依赖于抽象,底层不应该依赖于细节也是依赖于抽象);接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
面向对象特征:抽象,继承,封装,多态
有2种办法让HashMap线程安全,分别如下:
方法一:通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的。 这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现。
方法一:通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的。 这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现。
方法二:重新改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap. 这个方法比方法一有了很大的改进。
collection与collections的区别
Collection 是集合类的上级接口,继承与他的接口主要有Set 和List.
Collections 是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安
全化等操作。
sleep() 和wait() 有什么区别?
sleep 是线程类(Thread )的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控
状态依然保持,到时后会自动恢复。调用 sleep 不会释放对象锁。
wait 是Object 类的方法,对此对象调用 wait 方法导致本线程放弃对象锁,进入等待此对象的等待锁定
池,只有针对此对象发出notify 方法(或notifyAll )后本线程才进入对象锁定池准备获得对象锁进入运
行状态。
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
在java代码中,如果调用方法后可能会出现异常,则必须对异常进行处理,写java代码时自动抛出的异常称为检测性异常,例如在写文件时会自动抛出IOException;有些异常不会自动抛出,比如在执行parseIntger()方法时,如果括号中的参数不可以转换为整数,则会抛出异常,应用程序会终止,而在写代码的时候却不需要处理这个异常,这样的异常称为非检测性异常
给我一个你最常见到的runtime exception。
ArithmeticException, ArrayStoreException, BufferOverflowException,
BufferUnderflowException, CannotRedoException, CannotUndoException,
ClassCastException, CMMException, ConcurrentModificationException, DOMException,
EmptyStackException, IllegalArgumentException ( 不合法的参数异常) ,
IllegalMonitorStateException, IllegalPathStateException, IllegalStateException,
ImagingOpException, IndexOutOfBoundsException, MissingResourceException,
NegativeArraySizeException, NoSuchElementException, NullPointerException,
ProfileDataException, ProviderException, RasterFormatException, SecurityException,
SystemException, UndeclaredThrowableException, UnmodifiableSetException,
UnsupportedOperationException
单例模式
class Singleton{
private static Singleton instance=null;
public static synchronized Singleton getInstance(){
if(instance ==null)
return new Singleton ();
return instance;
}
}
AOP的jdk动态代理技术
要了解这个要先了解代理模式(为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用)
静态代理就如设计模式中所讲,其中优点:1.客户端和代理对象的桥梁2.无侵入的增强业务代码3.增强点多样化(在做被代理的对象的事情时可以在代理前入,后入,异常增加自己的业务),其中缺点:扩展能力差,可维护性差
其中根据配置的被拦截的类的名称来获取其实例然后代理涉及到java反射机制
- /*
- User u = new User();
- u.age = 12; //set
- System.out.println(u.age); //get
- */
- //获取类
- Class c = Class.forName("User");
- //获取id属性
- Field idF = c.getDeclaredField("id");
- //实例化这个类赋给o
- Object o = c.newInstance();
- //打破封装
- idF.setAccessible(true); //使用反射机制可以打破封装性,导致了java对象的属性不安全。
- //给o对象的id属性赋值"110"
- idF.set(o, "110"); //set
- //get
- System.out.println(idF.get(o));
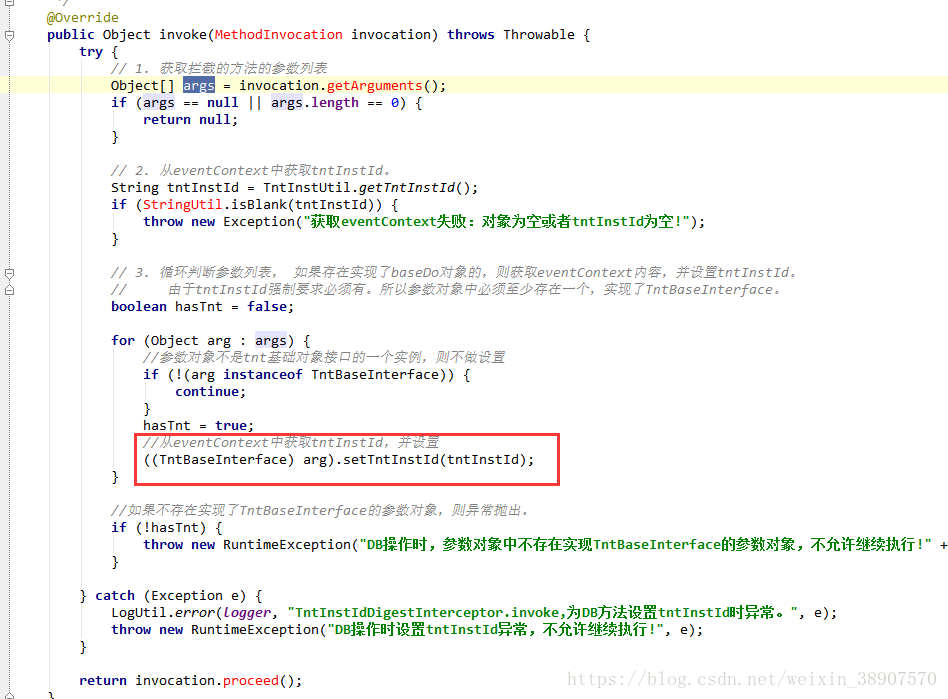
也可通过另外一种方式来注入值,其中TntBaseInterface的属性在被拦截的方法中的参数对象里面的属性一定存在并一致
1.整型
类型 存储需求 bit数 取值范围
byte 1字节 1*8 (-2的31次方到2的31次方-1)
short 2字节 2*8 -32768~32767
int 4字节 4*8 (-2的63次方到2的63次方-1)
long 8字节 8*8 -128~127
2.浮点型
类型 存储需求 bit数 备注
float 4字节 4*8 float类型的数值有一个后缀F(例如:3.14F)
double 8字节 8*8 没有后缀F的浮点数值(如3.14)默认为double类型
3.char类型
类型 存储需求 bit数
类型 存储需求 bit数 取值范围
byte 1字节 1*8 (-2的31次方到2的31次方-1)
short 2字节 2*8 -32768~32767
int 4字节 4*8 (-2的63次方到2的63次方-1)
long 8字节 8*8 -128~127
2.浮点型
类型 存储需求 bit数 备注
float 4字节 4*8 float类型的数值有一个后缀F(例如:3.14F)
double 8字节 8*8 没有后缀F的浮点数值(如3.14)默认为double类型
3.char类型
类型 存储需求 bit数
char 2字节 2*8
一个中文占两个字节,一个英文字母占一个字节
多线程有两种实现方法,分别是继承 Thread 类与实现Runnable 接口
同步的实现方面有两种,分别是 synchronized,wait 与notify
servlet返回ajax数据
PrintWriter out = response.getWriter();
out.println("1");
Java 中的线程有四种状态分别是:运行、就绪、挂起、结束
Map是java中的接口,Map.Entry是Map的一个内部接口。
Map提供了一些常用方法,如keySet()、entrySet()等方法。
keySet()方法返回值是Map中key值的集合;entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
TreeMap<Integer, Integer> tm= new TreeMap<Integer,Integer>();
tm.put(1, 1);
tm.put(2, 2);
Iterator<Entry<Integer, Integer>> it=tm.entrySet().iterator();
while(it.hasNext()){
System. out.println(it.next().getValue()+ "值");
}
Spring
控制反转,和依赖注入是同一个意思,我觉得应该重点去了解什么是依赖,而后控制反转、依赖注入就有体会了;关于依赖,可以查看UML相关的书籍,重点去看java对象之间的关系是怎样的,而所谓的依赖就是对象之间的一种关系,比如a对象依赖于b对象,那么a类中就会有b类的引用(简单理解就是拥有b类的这么一个属性),也就是说a对象要想执行一个完整的功能,必须建立一个前提——a对象中的b类属性已经实例话,并且拥有b类的一切功能;现在可以去了解什么是依赖注入了,就像前面说过的,a对象想完成一个完整的功能,要先为自己的b类属性实例化,而在MVC模式中,这种现象很常见,为了简化这种实例化的工作,spring容器就产生了,它可以统一管理这种实例化频繁的操作,就是说这种本来应由自己实例化的工作交给Spring容器去控制了,也就是说控制反转了,实现的方案之一是在上述a类中提供一个关于b类的setter方法,这个方法会被Spring容器控制。
AOP,还是以上面的例子。
比如你想在每次写字之前都检查一下笔里有没有墨水了,通常的做法是:在写字这个Action里调用判断是否有墨水的方法。这样做的不好一个方面是,写字的action和是否有墨水的方法产生了依赖,如果你有十几支不同的笔写字,每一个笔的Action里都要调用判断是否有墨水的方法;另一个方面是:就面向对象的程序设计来说,写字和判断是否有墨水的方法是同一等级的,如果你让写字这个动作来判断是否有墨水不够人性化,有违面向对象的程序设计的思想。
如果用Spring的AOP,是把写字的Action作为一个切面,在每次调用不同的笔来写字的方法之前,调用判断是否有墨水的方法。它是由<aop:config/>标签在Spring配置文件里定义的,形式如:
<aop:config>
<aop:pointcut id="allManagerMethod" expression="execution(* com.baidu.dao.write*(..))"/>
<aop:advisor pointcut-ref="allManagerMethod" advice-ref="txAdvice"/>
</aop:config>
如果用Spring的AOP,是把写字的Action作为一个切面,在每次调用不同的笔来写字的方法之前,调用判断是否有墨水的方法。它是由<aop:config/>标签在Spring配置文件里定义的,形式如:
<aop:config>
<aop:pointcut id="allManagerMethod" expression="execution(* com.baidu.dao.write*(..))"/>
<aop:advisor pointcut-ref="allManagerMethod" advice-ref="txAdvice"/>
</aop:config>
这里,对com.baidu.dao下所有以write开头的方法做了一个切面,做要做的操作是以下面的pointcut-ref="allManagerMethod"来定义的。
Aop应用场景
数据库事务处理
实现登录的日志管理
SpringMVC运行原理
- 客户端请求提交到DispatcherServlet
- 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller
- DispatcherServlet将请求提交到Controller
- Controller调用业务逻辑处理后,返回ModelAndView
- DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
- 视图负责将结果显示到客户端
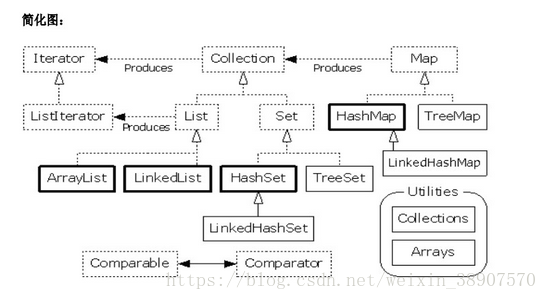
java集合框架图
函数式编程(FP)是一种软件开发风格,它注重不依赖于编程状态的函数(是动态的)。函数式代码易于测试和复用,容易实现并发,且不容易受到bug的攻击(通过函数之间的互相调用完成功能)
之所以静态的方法不可以访问非静态的方法,因为静态static是静态的实例资源,而非静态的方法还没有创建实例
垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于 GC 来说,当程序员创建对象时, GC 就开始监控这个对象的地址、大小以及使用情况。通常, GC
采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是 "可达的" ,哪些对
象是 "不可达的" 。当GC 确定一些对象为 "不可达" 时,GC 就有责任回收这些内存空间。可以。程序员可
以手动执行 System.gc(),通知GC 运行,但是 Java 语言规范并不保证GC 一定会执行。
Spring既是一个AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替换对象。有了 Spring,只要用 JavaBean 属性和配置文件加入依赖性(协作对象)。然后可以很容易地在需要时替换具有类似接口的协作对象
JavaBean是一个组件,而EJB就是一个组件框架
JavaBean面向的是业务逻辑和表示层的显示,通过编写一个JavaBean,可以将业务逻辑的事件和事务都放在其中,然后通过它的变量属性将所需要的内容在表示层传递显示。
EJB是部署在服务器上的可执行组件或商业对象。EJB有一个部署描述符,通过这个部署描述符可以对EJB的属性进行描述。EJB不和表示层交互
首先,EJB是指运行在EJB容器中的JavaBean。Tomcat是Web容器的参考实现。一个完整的JavaEE服务器应该包括Web容器和 EJB容器。
其次,Web容器中无法运行EJB,同时所有的JavaBean都是在服务器端运行的。如果有在客户端的话,就变成C/S结构了。
spring工作原理:
1.spring mvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。 2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端。
struts2工作原理:
1.客户端(Client)向Action发用一个请求(Request)
2.Container通过web.xml映射请求,并获得控制器(Controller)的名字
3.容器(Container)调用控制器(StrutsPrepareAndExecuteFilter或FilterDispatcher)。在Struts2.1以前调用FilterDispatcher,Struts2.1以后调用StrutsPrepareAndExecuteFilter
4.控制器(Controller)通过ActionMapper获得Action的信息
5.控制器(Controller)调用ActionProxy
6.ActionProxy读取struts.xml文件获取action和interceptor stack的信息。
7.ActionProxy把request请求传递给ActionInvocation
8.ActionInvocation依次调用action和interceptor
9. 根据action的配置信息,产生result
10.Result信息返回给ActionInvocation
11.产生一个HttpServletResponse响应
12.产生的响应行为发送给客服端。
springmvc与struts2的区别:
1、Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
2、由上边原因,SpringMVC的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码 读程序时带来麻烦,每次来了请求就创建一个Action,一个Action对象对应一个request上下文。
3、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
3、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
4、 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
5、SpringMVC的入口是servlet,而Struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
6、SpringMVC集成了Ajax,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
7、SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱。
8、spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC一样的效果,但是需要xml配置的地方不少)。
9、 设计思想上,Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展。
10、SpringMVC开发效率和性能高于Struts2。
11、SpringMVC可以认为已经100%零配置。
SSH:
Struts(表示层)+Spring(业务层)+Hibernate(持久层)
Struts: Struts是一个表示层框架,主要作用是界面展示,接收请求,分发请求。 在MVC框架中,Struts属于VC层次,负责界面表现,负责MVC关系的分发。(View:沿 用JSP,HTTP,Form,Tag,Resourse ;Controller:ActionServlet,struts-config.xml,Action)
Hibernate: Hibernate是一个持久层框架,它只负责与关系数据库的操作。
Spring: Spring是一个业务层框架,是一个整合的框架,能够很好地黏合表示层与持久层。
struts1和struts2的区别:
Action 类:
• Struts1要求Action类继承一个抽象基类。Struts1的一个普遍问题是使用抽象类编程而不是接口,而struts2的Action是接口。
• Struts 2 Action类可以实现一个Action接口,也可实现其他接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去 实现 常用的接口。Action接口不是必须的,任何有execute标识的POJO对象都可以用作Struts2的Action对象。
线程模式:
• Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。
• Struts2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题)
hibernate
工作原理:
1. 读取并解析配置文件
2. 读取并解析映射信息,创建SessionFactory
3. 打开Sesssion
4. 创建事务Transation
5. 持久化操作
6. 提交事务
7. 关闭Session
8. 关闭SesstionFactory
工作流程:
(1)先是创建pojo类(javaBean)
(2)再是创建映射文件(.hbm.xml)
(3)创建配置文件(hibernate.hbm.xml)
工作流程:
(1)先是创建pojo类(javaBean)
(2)再是创建映射文件(.hbm.xml)
(3)创建配置文件(hibernate.hbm.xml)
(4)后调用Hibernate API对数据库进行CRUD操作.
hibernate与mybatics的区别
1. hibernate是全自动,而mybatis是半自动。
2. hibernate数据库移植性远大于mybatis。
3. hibernate拥有完整的日志系统,mybatis则欠缺一些。
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
4. mybatis相比hibernate需要关心很多细节
5. sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
spring中的BeanFactory与ApplicationContext的作用有哪些
1. BeanFactory负责读取bean配置文档,管理bean的加载,实例化,维护bean之间的依赖关系,负责bean的声明周期。
2. ApplicationContext除了提供上述BeanFactory所能提供的功能之外,还提供了更完整的框架功能:
a. 国际化支持
b. 资源访问:Resource rs = ctx. getResource(”classpath:config.properties”), “file:c:/config.properties”
c. 事件传递:通过实现ApplicationContextAware接口
常用的获取ApplicationContext的方法:
可以配置监听器或者servlet来实现
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
三种方式可以得到Bean并进行调用:
1、使用 BeanWrapper
HelloWorldhw=new HelloWorld();
BeanWrapperbw=new BeanWrapperImpl(hw);
bw.setPropertyvalue(”msg”,”HelloWorld”);
system.out.println(bw.getPropertyCalue(”msg”));
2、使用BeanFactory
InputStream is=new FileInputStream(”config.xml”);
XmlBeanFactory factory=new XmlBeanFactory(is);
HelloWorldhw=(HelloWorld) factory.getBean(”HelloWorld”);
system.out.println(hw.getMsg());
3、使用ApplicationConttext
ApplicationContextactx=new FleSystemXmlApplicationContext(”config.xml”);
HelloWorldhw=(HelloWorld) actx.getBean(”HelloWorld”);
System.out.println(hw.getMsg());
ORM
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
写clone()方法时通常有一行代码,是什么
clone有缺省行为,super.clone();他负责产生正确大小的空间,并逐位复制
Clone方法
class CloneClass implements Cloneable{
public int aInt;
public Object clone(){
CloneClass o = null;
try{
o = (CloneClass)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return o;
}
public int aInt;
public Object clone(){
CloneClass o = null;
try{
o = (CloneClass)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return o;
}
}
序列化和反序列化
概念
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
应用场景
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以 采用默认的序列化方式 。
java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以 采用默认的序列化方式 。
对象序列化包括如下步骤:
1) 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2) 通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2) 通过对象输入流的readObject()方法读取对象。
多线程同步机制包括:
1.Event事件(一个事件具有两种状态:有信号状态,无信号状态)
2.临界区Critical Section(使用临界区域的第一个忠告就是不要长时间锁住一份资源 )
3.互斥器Mutex
4.信号量Semaphore
信号量 是最具历史的同步机制。信号量是解决producer/consumer 问题的关键要素。
对应的MFC 类是Csemaphore。Win32 函数 CreateSemaphore ()用来产生信号量。
ReleaseSemaphore()用来解除锁定。Semaphore 的现值代表的意义是可用的资源数,
如果Semaphore 的现值为1,表示还有一个锁定动作可以成功。如果现值为5,就表示还
有五个锁定动作可以成功。当调用Wait…等函数要求锁定,如果Semaphore 现值不为0,
Wait…马上返回,资源数减1。当调用ReleaseSemaphore()资源数加1,当然不会超过
初始设定的资源总数。
class ClassA {}
class ClassB extends ClassA {}
class ClassC extends ClassA {}
and:
ClassA p0 = new ClassA();
ClassB p1 = new ClassB();
ClassC p2 = new ClassC();
ClassA p3 = new ClassB();
ClassA p4 = new ClassC();
Which three are valid? (Choose three.)
A. p0 = p1;
B. p1 = p2;
C. p2 = p4;
D. p2 = (ClassC)p1;
E. p1 = (ClassB)p3;
F. p2 = (ClassC)p4;
答案:AEF
考点:继承环境下的引用变量指向
说明:
父类引用变量可以指向子类对象; 子类引用变量不能指向父类对象。
拥有同一父类的兄弟类之间不能互相指向。
技术演进出来的数据库连接池
我们知道,对于共享资源,有一个很著名的设计模式:资源池(resource pool)。该模式正是为了解决资源的频繁分配﹑释放所造成的问题。为解决上述问题,可以采用数据库连接池技术。数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接。更为重要的是我们可以通过连接池的管理机制监视数据库的连接的数量﹑使用情况,为系统开发﹑测试及性能调整提供依据。
三.连接池还要考虑更多的问题
1、并发问题
为了使连接管理服务具有最大的通用性,必须考虑多线程环境,即并发问题。这个问题相对比较好解决,因为java语言自身提供了对并发管理的支持,使用synchronized关键字即可确保线程是同步的。使用方法为直接在类方法前面加上synchronized关键字,如:
publicsynchronized connection getconnection()
2、多数据库服务器和多用户
对于大型的企业级应用,常常需要同时连接不同的数据库(如连接oracle和sybase)。如何连接不同的数据库呢?我们采用的策略是:设计一个符合单例模式的连接池管理类,在连接池管理类的唯一实例被创建时读取一个资源文件,其中资源文件中存放着多个数据库的url地址等信息。根据资源文件提供的信息,创建多个连接池类的实例,每一个实例都是一个特定数据库的连接池。连接池管理类实例为每个连接池实例取一个名字,通过不同的名字来管理不同的连接池。
对于同一个数据库有多个用户使用不同的名称和密码访问的情况,也可以通过资源文件处理,即在资源文件中设置多个具有相同url地址,但具有不同用户名和密码的数据库连接信息。
3、事务处理
我们知道,事务具有原子性,此时要求对数据库的操作符合“all-all-nothing”原则即对于一组sql语句要么全做,要么全不做。
在java语言中,connection类本身提供了对事务的支持,可以通过设置connection的autocommit属性为false 然后显式的调用commit或rollback方法来实现。但要高效的进行connection复用,就必须提供相应的事务支持机制。可采用每一个事务独占一个连接来实现,这种方法可以大大降低事务管理的复杂性。
4、连接池的分配与释放
连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。
对于连接的管理可使用空闲池。即把已经创建但尚未分配出去的连接按创建时间存放到一个空闲池中。每当用户请求一个连接时,系统首先检查空闲池内有没有空闲连接。如果有就把建立时间最长(通过容器的顺序存放实现)的那个连接分配给他(实际是先做连接是否有效的判断,如果可用就分配给用户,如不可用就把这个连接从空闲池删掉,重新检测空闲池是否还有连接);如果没有则检查当前所开连接池是否达到连接池所允许的最大连接数(maxconn)如果没有达到,就新建一个连接,如果已经达到,就等待一定的时间(timeout)。如果在等待的时间内有连接被释放出来就可以把这个连接分配给等待的用户,如果等待时间超过预定时间timeout 则返回空值(null)。系统对已经分配出去正在使用的连接只做计数,当使用完后再返还给空闲池。对于空闲连接的状态,可开辟专门的线程定时检测,这样会花费一定的系统开销,但可以保证较快的响应速度。也可采取不开辟专门线程,只是在分配前检测的方法。
5、连接池的配置与维护
连接池中到底应该放置多少连接,才能使系统的性能最佳?系统可采取设置最小连接数(minconn)和最大连接数(maxconn)来控制连接池中的连接。最小连接数是系统启动时连接池所创建的连接数。如果创建过多,则系统启动就慢,但创建后系统的响应速度会很快;如果创建过少,则系统启动的很快,响应起来却慢。这样,可以在开发时,设置较小的最小连接数,开发起来会快,而在系统实际使用时设置较大的,因为这样对访问客户来说速度会快些。最大连接数是连接池中允许连接的最大数目,具体设置多少,要看系统的访问量,可通过反复测试,找到最佳点。
如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。
事务的四个特性
1、一致性:事务在完成时,必须使所有的数据都保持一致状态,而且在相关数据中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构都应该是正确的。
2、原子性:将事务中所做的操作捆绑成一个原子单元,即对于事务所进行的数据修改等操作,要么全部执行,要么全部不执行。
3、隔离性:由并发事务所做的修改必须与任何其他事务所做的修改相隔离。事务查看数据时数据所处的状态,要么是被另一并发事务修改之前的状态,要么是被另一并发事务修改之后的状态,即事务不会查看由另一个并发事务正在修改的数据。这种隔离方式也叫可串行性。
4、持久性:事务完成之后,它对系统的影响是永久的,即使出现系统故障也是如此。
事务问题
1. 脏读 :脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问 这个数据,然后使用了这个数据。
比如事务1,修改了某个数据 事务2,刚好访问了事务1修改后的数据
此时事务1,回滚了操作 事务2,读到还是回滚前的数据
此时,事务2读到的就是在内存中,而不是在数据库中的数据(事务1还未提交)
2. 不可重复读 :是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两 次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。
事务1,查询某个数据 事务2,修改了某个数据,提交
事务1,再次查询这个数据
这样事务1两次查询的数据不一样,称为不可重复读
3. 幻读 : 是值第一个事务查询或操作一堆数据,事务2此时插入一条数据并提交,事务1再次查询或操作时,突然发现多了一条数据,像是幻觉一样。与不可重复读类似,不过后者是修改了某一条,某条不同,而前者是增加了一条。
解决方案
编辑
为了避免上面出现的几种情况,在标准SQL规范中,定义了4个事务隔离级别,不同的隔离级别对事务的处理不同。
未授权读取
也称为读未提交(Read Uncommitted):允许脏读取,但不允许更新丢失。如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。
授权读取
也称为读提交(Read Committed):允许不可重复读取,但不允许脏读取。这可以通过“瞬间共享读锁”和“排他写锁”实现。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
可重复读取(Repeatable Read)
可重复读取(Repeatable Read):禁止不可重复读取和脏读取,但是有时可能出现幻读数据。这可以通过“共享读锁”和“排他写锁”实现。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
序列化(Serializable)
序列化(Serializable):提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,不能并发执行。仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
web.xml默认加载顺序
servlet-context=>listener=>filter=>servlet
数据库中
char和vachar2的区别:char最大可以容纳2个字节,varchar2最多可以容纳4个字节,此为可变长字段
统一认证实现机制
1.用户通过浏览器访问接入统一认证的应用系统,访问地址如下:http://helloservice/main.jsp。
2.应用系统发现用户尚未登录,将用户浏览器重定向到统一认证CASServer的登录界面, 同时在重定向的URL上用service参数将用户的目标地址传给CAS服务器,以及应用系统id(此值由统一认证分配), 地址如下:http://CASserver/login?service=http%3A%2F%2Fhelloservice%2Fmain.jsp&appid=1。
3.CAS服务器发现用户未登录过CAS服务,显示登录页面,用户在CASServer的登录页面上输入用户名、密码登录,CASServer服务器认证通过后,生成一个ticket,并带在目标地址的尾部返回给客户端浏览器,地址如下:http://helloservice/main.jsp?ticket=CASticket。
4.用户浏览器重定向CASServer返回的URL地址。
5.应用系统获得ticket凭证,并将appid一起,通过URL地址:http://CASserver/validate?ticket=CASticket&appid=1向CAS认证中心确认对应的服务请求和凭证是否有效。
6.CAS服务器返回的验证结果,应用系统根据CAS服务器返回的结果,如果凭证有效,则通过结果获取用户号信息,并允许用户进http://helloservice/main.jsp所指向的页面;否则,再次重定向到http://CASserve/login?service=http%3A%2F%2Fhelloservice%2Fmain.jsp&appid=1上要求用户进行认证。
jvm类加载器的过程
加载:就是将class二进制文件由类加载器加载到内存。
连接-验证:主要验证class文件的格式是否正确,语法是否正确,字节码是否正确,二进制是否兼容。
连接-准备:为类的静态变量分配空间,且赋予默认的初始值。
连接-解析:将class文件中符号引用转变成直接引用。
初始化:为类的静态变量赋予正确的初始值,只有在类首次主动使用的时候,才会进行初始化。
介绍一下JVM将何时结束线程的生命
(1)程序执行System.exit()
(2)程序正常结束
(3)程序抛出异常,一直向上抛出,没有try{}catch()finally{}处理。
(4)由于操作系统的异常,导致JVM退出
jvm结构图

单例模式的应用场景
1.共享资源配置的读取
2.数据库获取连接,连接池原理