在很多小白学习Python的过程中 都不知道怎么去学习Python,也不知道零基础应该从什么地方开始下手,于是就东学一点西学一点,到后来发现这里也懂点,那里也懂点!实际上什么都不懂!
那么零基础开始学习应该从哪里开始学习呢?

一、Python的开发环境安装
这个是毋庸置疑的,你连Python的环境都没有安装好的话,那你怎么写代码呢?
安装教程 直接百度上面有很详细的讲解。
怎么设置环境变量?
百度也有的,能百度的问题都不是问题!与其做伸手党,还不如直接百度。
二、熟练使用IDLE的使用
很多初学Python的小伙伴都有一个共同的问题,那就是安装Python后,不知道怎么使用!
win + S 搜索IDLE
或者在菜单里面

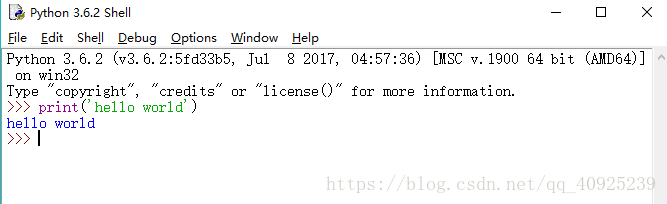
国际惯例:hello world
三、Python的基本使用
变量
获取用户的输入
输出信息
运行Python代码:IDLE运行、控制台运行
四、基本数据类型
字符串:
- 字符串定义
- 字符串索引
- 字符串的拼接
- 字符串格式化
S = '' # 空字符串
S = "spam’s" # 双引号和单引号相同
S = "s\np\ta\x00m" # 转义字符
S = """spam""" # 三重引号字符串,一般用于函数说明
S = r'\temp' # Raw字符串,不会进行转义,抑制转义
S = b'Spam' # Python3中的字节字符串
S = u'spam' # Python2.6中的Unicode字符串
s1+s2, s1*3, s[i], s[i:j], len(s) # 字符串操作
'a %s parrot' % 'kind' # 字符串格式化表达式
'a {0} parrot'.format('kind') # 字符串格式化方法
for x in s: print(x) # 字符串迭代,成员关系
[x*2 for x in s] # 字符串列表解析
','.join(['a', 'b', 'c']) # 字符串输出,结果:a,b,c列表:
索引
添加
移除
链接
排序
L = [[1, 2], 'string', {}] # 嵌套列表
L = list('spam') # 列表初始化
L = list(range(0, 4)) # 列表初始化
list(map(ord, 'spam')) # 列表解析
len(L) # 求列表长度
L.count(value) # 求列表中某个值的个数
L.append(obj) # 向列表的尾部添加数据,比如append(2),添加元素2
L.insert(index, obj) # 向列表的指定index位置添加数据,index及其之后的数据后移
L.extend(interable) # 通过添加iterable中的元素来扩展列表,比如extend([2]),添加元素2,注意和append的区别
L.index(value, [start, [stop]]) # 返回列表中值value的第一个索引
L.pop([index]) # 删除并返回index处的元素,默认为删除并返回最后一个元素
L.remove(value) # 删除列表中的value值,只删除第一次出现的value的值
L.reverse() # 反转列表
L.sort(cmp=None, key=None, reverse=False) # 排序列表
a = [1, 2, 3], b = a[10:] # 注意,这里不会引发IndexError异常,只会返回一个空的列表[]
a = [], a += [1] # 这里实在原有列表的基础上进行操作,即列表的id没有改变
a = [], a = a + [1] # 这里最后的a要构建一个新的列表,即a的id发生了变化字典:
键值对
获取
添加
移除
更新
D = {}
D = {'spam':2, 'tol':{'ham':1}} # 嵌套字典
D = dict.fromkeys(['s', 'd'], 8) # {'d': 8, 's': 8}
D = dict(name = 'tom', age = 12) # {'age': 12, 'name': 'tom'}
D = dict([('name', 'tom'), ('age', 12)]) # {'age': 12, 'name': 'tom'}
D = dict(zip(['name', 'age'], ['tom', 12])) # {'age': 12, 'name': 'tom'}
D.keys() D.values() D.items() # 字典键、值以及键值对
D.get(key, default) # get函数
D.update(D_other) # 合并字典,如果存在相同的键值,D_other的数据会覆盖掉D的数据
D.pop(key, [D]) # 删除字典中键值为key的项,返回键值为key的值,如果不存在,返回默认值D,否则异常
D.popitem() # pop字典中的一项(一个键值对)
D.setdefault(k[, d]) # 设置D中某一项的默认值。如果k存在,则返回D[k],否则设置D[k]=d,同时返回D[k]。
del D # 删除字典
del D['key'] # 删除字典的某一项
if key in D: if key not in D: # 测试字典键是否存在
# 字典注意事项:(1)对新索引赋值会添加一项(2)字典键不一定非得是字符串,也可以为任何的不可变对象五、流程控制
选择:
if
if/else
if/elif/else
循环:
while
break
continue
迭代:
range
for..in..
A = 1 if X else 2
A = 1 if X else (2 if Y else 3)
# 也可以使用and-or语句(一条语句实现多个if-else)
result = (a > 20 and "big than 20" or a > 10 and "big than 10" or a > 5 and "big than 5")
while a > 1:
......
else:
......
# else语句会在循环结束后执行,除非在循环中执行了break,同样的还有for语句
for i in range(5):
......
else:
......
for (a, b) in [(1, 2), (3, 4)]: # 最简单的赋值
for ((a, b), c) in [((1, 2), 3), ((4, 5), 6)]: # 自动解包赋值
for ((a, b), c) in [((1, 2), 3), ("XY", 6)]: # 自动解包 a = X, b = Y, c = 6
for (a, *b) in [(1, 2, 3), (4, 5, 6)]: # 自动解包赋值六、函数
函数相关的语句和表达式
myfunc('spam') # 函数调用
def myfunc(): # 函数定义
return None # 函数返回值
global a # 全局变量
nonlocal x # 在函数或其他作用域中使用外层(非全局)变量
yield x # 生成器函数返回
lambda # 匿名函数匿名函数:lambda
f = lambda x, y, z : x + y + z # 普通匿名函数,使用方法f(1, 2, 3)
f = lambda x = 1, y = 1: x + y # 带默认参数的lambda函数
def action(x): # 嵌套lambda函数
return (lambda y : x + y)
f = lambda: a if xxx() else b # 无参数的lambda函数,使用方法f()七、类
最普通的类
class C1(C2, C3):
spam = 42 # 数据属性
def __init__(self, name): # 函数属性:构造函数
self.name = name
def __del__(self): # 函数属性:析构函数
print("goodbey ", self.name)
I1 = C1('bob')类方法调用的两种方式
instance.method(arg...)
class.method(instance, arg...)
八、模块及包
创建模块
导入模块
创建包
pip安装包
import module1, module2 # 导入module1 使用module1.printer()
from module1 import printer # 导入module1中的printer变量 使用printer()
from module1 imoprt * # 导入module1中的全部变量 使用不必添加module1前缀
import dir1.dir2.mod # d导入包(目录)dir1中的包dir2中的mod模块 此时dir1必须在Python可搜索路径中
from dir1.dir2.mod import * # from语法的包导入
from . import spam # 导入当前目录下的spam模块(错误: 当前目录下的模块, 直接导入即可)
from .spam import name # 导入当前目录下的spam模块的name属性(错误: 当前目录下的模块, 直接导入即可,不用加.)
from .. import spam # 导入当前目录的父目录下的spam模块