quicklist概述
上一节中,我们有说到Redis中的列表对象在版本3.2之前,列表底层的编码是 ziplist 和 linkedlist 实现的, 但是在版本3.2之后,重新引入了一个 quicklist 的数据结构,列表的底层都由quicklist实现。
在早期的设计中, 当列表对象中元素的长度比较小或者数量比较少的时候,采用ziplist来存储,当列表对象中元素的长度比较大或者数量比较多的时候,则会转而使用双向列表linkedlist来存储。
这两种存储方式都各有优缺点
- 双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝。
早期版本在这边选择的折中方案是两种数据类型的转换,但是在3.2版本之后,不知道出于什么原因, 猜测会不会因为转换也是个费时且复杂的操作,引入了一种新的数据格式,结合了双向列表linkedlist和ziplist的特点,称之为quicklist。所有的节点都用quicklist存储,省去了到临界条件是的格式转换。
那么quicklist是一种什么样的格式呢?简单的说,我们仍旧可以将其看作一个双向列表,但是列表的每个节点都是一个ziplist,其实就是linkedlist和ziplist的结合。quicklist中的每个节点ziplist都能够存储多个数据元素。
quicklist实现
接下去我们看下quicklist的具体实现。
quicklist的定义如下:
typedef struct quicklist {
quicklistNode *head; // 指向quicklist的头部
quicklistNode *tail; // 指向quicklist的尾部
unsigned long count; // 列表中所有数据项的个数总和
unsigned int len; // quicklist节点的个数,即ziplist的个数
int fill : 16; // ziplist大小限定,由list-max-ziplist-size给定
unsigned int compress : 16; // 节点压缩深度设置,由list-compress-depth给定
} quicklist;可以看到,这边其实有两个统计值,count用来统计所有数据项的个数总和,len用来统计quicklist的节点个数, 因为每个节点ziplist都能存储多个数据项,所以有了这两个统计值。
另外,插一点,quicklist的这个结构体在源码中说是占用了32byte的空间,怎么计算的呢?这边涉及到了位域的概念,所谓”位域“是把一个字节中的二进位划分为几 个不同的区域, 并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。比如这个“int fill : 16” 表示不用整个int存储fill,而是只用了其中的16位来存储。
好了,回到正题。
quicklist的节点node的定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向上一个ziplist节点
struct quicklistNode *next; // 指向下一个ziplist节点
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构
unsigned int sz; // 表示指向ziplist结构的总长度(内存占用长度)
unsigned int count : 16; // 表示ziplist中的数据项个数
unsigned int encoding : 2; // 编码方式,1--ziplist,2--quicklistLZF
unsigned int container : 2; // 预留字段,存放数据的方式,1--NONE,2--ziplist
unsigned int recompress : 1; // 解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为1,之后再重新进行压缩
unsigned int attempted_compress : 1; // 测试相关
unsigned int extra : 10; // 扩展字段,暂时没用
} quicklistNode;这样, 我们就可以知道整个quicklist的结构
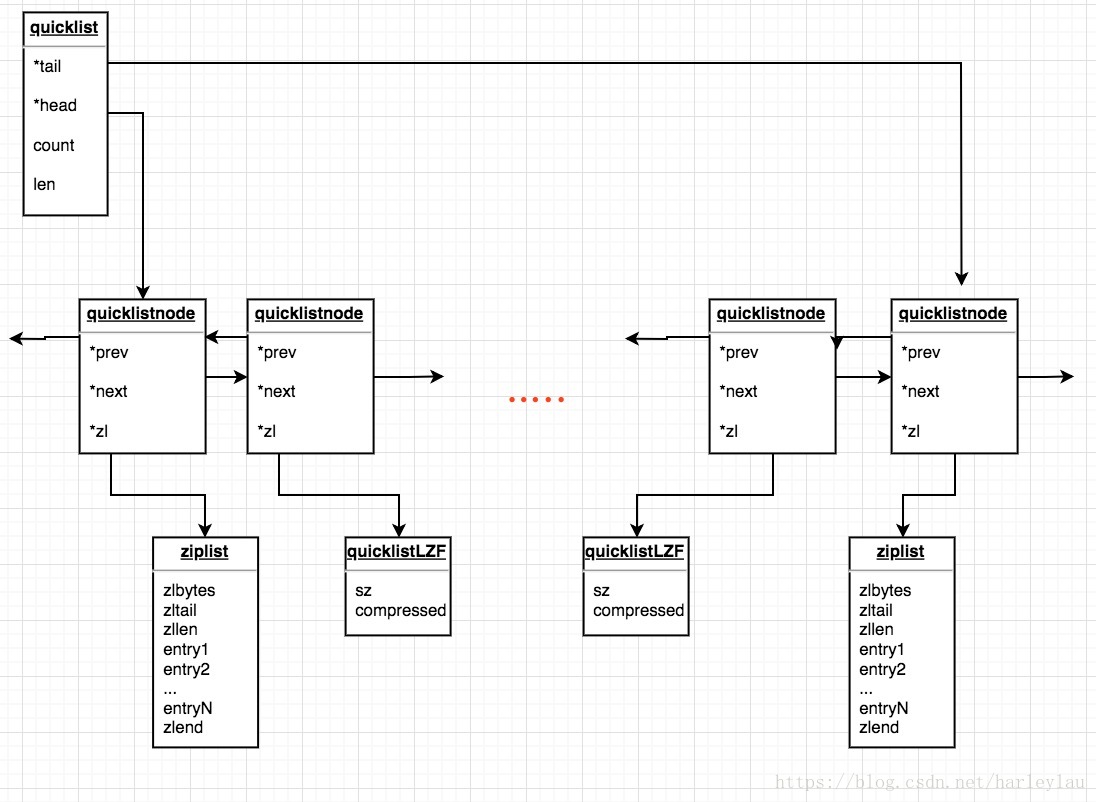
图上显示了两种ziplist的结构,一种是经过压缩的,一种是未经压缩的。
quicklist操作
创建quicklist
/* Create a new quicklist.
* Free with quicklistRelease(). */
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist)); // 分配空间
quicklist->head = quicklist->tail = NULL; // 头尾指针为空
quicklist->len = 0; // 列表长度为0
quicklist->count = 0; // 数据项总和为0
quicklist->compress = 0; // 设定压缩深度
quicklist->fill = -2; // 设定ziplist大小
return quicklist;
}quicklist中的节点创建
REDIS_STATIC quicklistNode *quicklistCreateNode(void) {
quicklistNode *node;
node = zmalloc(sizeof(*node)); // 分配空间
node->zl = NULL; // 初始化指向ziplist的指针
node->count = 0; // 数据项个数为0
node->sz = 0; // ziplist大小为0
node->next = node->prev = NULL; // 前后指针为空
node->encoding = QUICKLIST_NODE_ENCODING_RAW; // 节点编码方式
node->container = QUICKLIST_NODE_CONTAINER_ZIPLIST; // 数据存放方式
node->recompress = 0; // 初始化压缩标记
return node;
}quicklist的push操作
quicklist的push操作其实就是在双向列表的头节点或尾节点上插入一个新的元素。从上面我们知道,quicklist的每个节点都是一个ziplist,所以这个push操作就涉及到一个问题,当前节点的ziplist是否能够放进新元素。
- 如果ziplist能够放入新元素,即大小没有超过限制(list-max-ziplist-size),那么直接调用ziplistPush函数压入
- 如果ziplist不能放入新元素,则新建一个quicklist节点,即新的ziplist,新的数据项会被插入到新的ziplist,新的quicklist节点插入到原有的quicklist上
/* Wrapper to allow argument-based switching between HEAD/TAIL pop */
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}函数里边, 根据是头部插入还是尾部插入调用不同的函数。先看头部插入的情况:
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
// 判断头部节点是否能够插入新元素
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
// 如果能够插入,则执行ziplistPush插入新元素的当前节点的ziplist
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
// 更新头部大小
quicklistNodeUpdateSz(quicklist->head);
} else {
// 否则的话,需要创建新的quicklist节点
quicklistNode *node = quicklistCreateNode();
// 将新节点压入新创建的ziplist中,并与新创建的quicklist节点关联起来
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
// 更新头部信息
quicklistNodeUpdateSz(node);
// 将新创建的节点插入到quicklist中
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
// 更新quicklist的数据项个数
quicklist->count++;
// 更新头结点的数据项个数
quicklist->head->count++;
return (orig_head != quicklist->head);
}在尾部插入数据的操作也是类似的, 不多具体介绍, 我们再看一下判断当前ziplist节点是否能插入的函数。
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) { // 判断当前node是否还能插入数据
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
if (sz < 254) // 小于254时后一个节点的pre只有1字节,否则为5字节
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64) // 小于64字节当前节点的encoding为1
ziplist_overhead += 1;
else if (likely(sz < 16384)) // 小于16384 encoding为2字节
ziplist_overhead += 2;
else // encoding为5字节
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead; // 忽略了连锁更新的情况
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill))) // // 校验fill为负数是否超过单存储限制
return 1;
else if (!sizeMeetsSafetyLimit(new_sz)) // 校验单个节点是否超过8kb,主要防止fill为正数时单个节点内存过大
return 0;
else if ((int)node->count < fill) // fill为正数是否超过存储限制
return 1;
else
return 0;
}quicklist还能在指定的位置插入数据,quicklistInsertAfter和quicklistInsertBefore就是分别在指定位置后面和前面插入数据项。当然,和在头尾节点插入一样, 任意位置插入也是需要判断当前插入节点是否能够放得下当前的元素的,这边的情况会比头尾节点更为复杂,比如在当前节点放不下的时候,还需要检查一下旁边的节点是否能够放下这个数据,能够放下的话可以放置在旁边的节点上,如果也不行的话,就是需要新建一个ziplist节点。
写到最后,发现虽然通篇在说每个节点ziplist能够容纳多个元素,但是没有具体介绍配置的参数。不过,从上边的分析也能看出来,这个是有quicklist的结构中的fill字段指定的, 这个fill字段会读取配置中的list-max-ziplist-size参数值。
这个参数它可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成3的时候,表示每个quicklist节点的ziplist最多包含3个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
还有一个参数list-compress-depth表示列表两头不压缩的节点的个数
- 0 特殊值,表示不压缩
- 1 表示quicklist两端各有一个节点不压缩,中间的节点压缩
- 2 表示quicklist两端各有两个节点不压缩,中间的节点压缩
- 3 表示quicklist两端各有三个节点不压缩,中间的节点压缩