简介:
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
在本文,本人将教大家如何使用jsoup抓取一些简单的页面信息
准备:
jsoup的jar包:
https://jsoup.org/download
开发工具:eclipse
思路:
我们首先利用jsoup把网络上的html解析成字符串,然后把字符串转换成Document,然后选取某些我们想要的信息遍历出来。
流程:
1.创建一个web项目,起好项目名,导入jar包
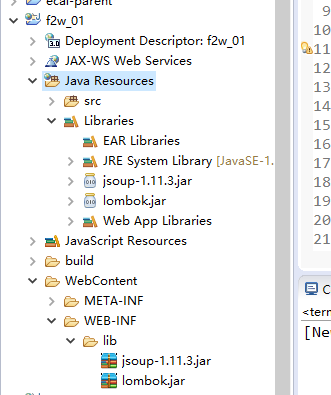
lombok是为了省略get和set方法的,详细请参阅
https://blog.csdn.net/qq_41441210/article/details/79891093
2.创建目录结构
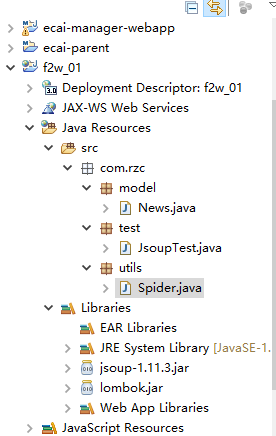
model中的News是封装的新闻实体对象
utils中的Spider是我们写的一个工具类
test中的JsoupTest是我们写的一个测试类
3.代码如下
实体类:
package com.rzc.model;
import lombok.Data;
@Data // lombok注解,相当于get、set方法和toString等都默认生成
public class News {
private String title; // 新闻标题
private String article; // 新闻内容
private String publishTime; // 新闻发布时间
private String keyword; // 新闻关键字
private String author; // 新闻作者
}
工具类:
package com.rzc.utils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.rzc.model.News;
public class Spider {
// 获取页面加载内容
public Document loadDocumentData(String url) {
// 创建文档对象
Document doc = null;
// 根据url将某页信息转换成文档
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 返回文档
return doc;
}
// 获取a标签中的href的内容
public List<String> parseDoc(Document doc) {
// 实例化list
List<String> list = new ArrayList<String>();
// 根据指定class获取对象(这里我们查看页面源码,选取了一个class为 new_top 的新闻 列表)
Elements elements = doc.getElementsByClass("news_top");
// 根据指定的标签获取连接内容(这里选取的是a标签中的内容)
Elements links = elements.get(0).getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
// 讲遍历出来的每一个a标签对象中的href属性循环存入list中
list.add(links.get(i).attr("href"));
}
// 返回list
return list;
}
// 按照要求获取news对象
public News parseDetaile(Document doc) {
// 实例化news对象
News news = new News();
// 按照class获取文档对象 main_title的文本信息,并将该信息存入title中
String title = doc.getElementsByClass("main_title").text();
// 查照选择器data-sourse后面的.data信息,并将该信息存入publishTime中
String publishTime = doc.select(".data-sourse > .data").text();
// 按照class获取文档对象 caricle 的文本信息,并将该信息存入 article 中
String article = doc.getElementsByClass("article").text();
// 按照class获取文档对象 keyword 的文本信息,并将该信息存入 keyword 中
String keyword = doc.getElementsByClass("keyword").text();
// 按照class获取文档对象 show_author 的文本信息,并将该信息存入 author 中
String author = doc.getElementsByClass("show_author").text();
// 将以上信息填充到news对象中
news.setTitle(title);
news.setPublishTime(publishTime);
news.setArticle(article);
news.setKeyword(keyword);
news.setAuthor(author);
return news;
}
}
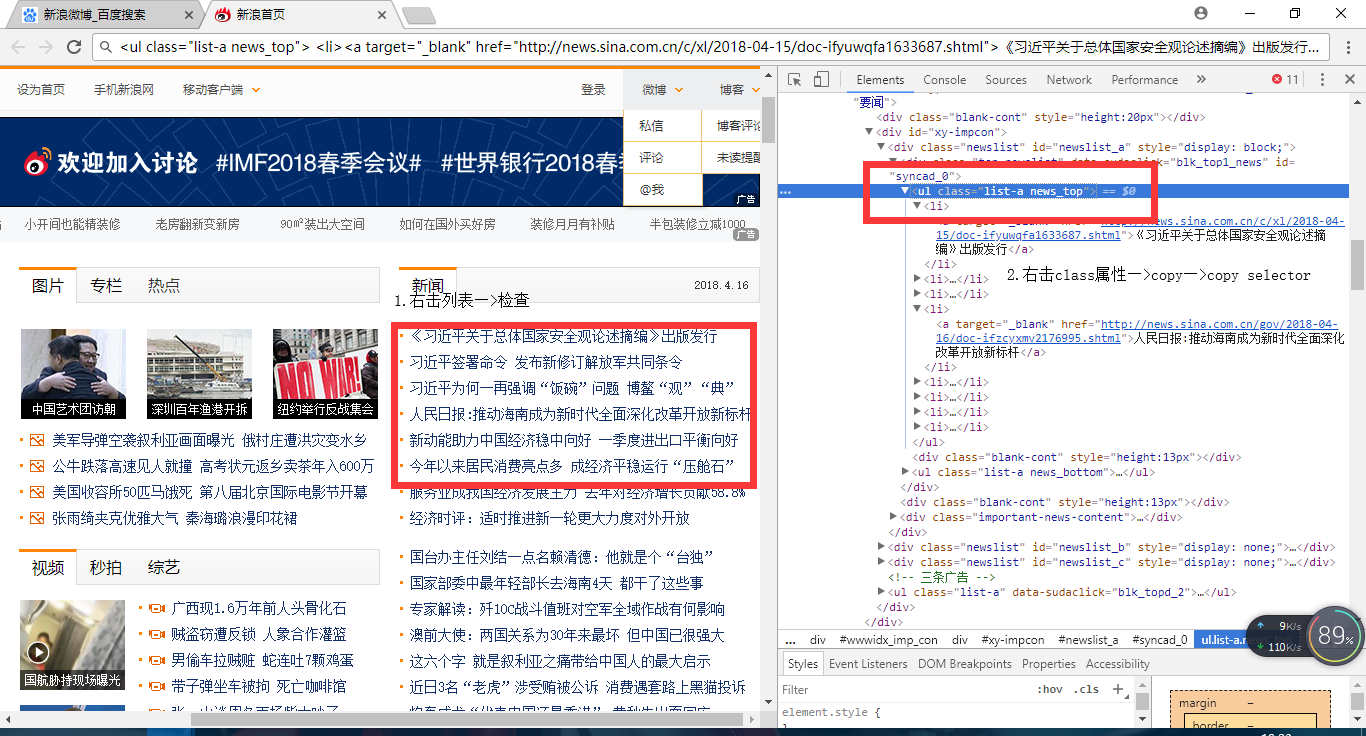
从页面信息中按照标签选择自己需要的信息,然后根据标签之类的属性去获取对象这里列举其中的新闻信息对象的查找方法,其他的不一而足,随机应变
测试类:
package com.rzc.test;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Document;
import com.rzc.model.News;
import com.rzc.utils.Spider;
public class JsoupTest {
public static void main(String[] args) {
// 实例化工具类对象
Spider spider = new Spider();
// 根据url获取文档(这里的url是新浪首页)
Document doc = spider.loadDocumentData("http://www.sina.com.cn");
// 获取文档中a标签 中href属性中的内容
List<String> list = spider.parseDoc(doc);
// 实例化新闻列表
List<News> newsList = new ArrayList<News>();
// 循环遍历新闻列表中的每一个对象
for(String url:list){
// 获取整个文档
Document document = spider.loadDocumentData(url);
// 获取每个文档中的新闻对象
News news = spider.parseDetaile(document);
// 将文档中的新闻对象添加到新闻列表中
newsList.add(news);
// 测试输出新闻列表信息
System.out.println(news);
}
}
}
输出结果

文章就介绍到这里,谢谢大家的观看,不足之处,还请指出!