上一篇我们介绍了JVM的基本信息,以及内存结构(堆、栈、方法区、程序计数器、本地方法栈)。本篇我们来介绍内存结构中不同区域的交互,以及内存处理机制。
一、栈、堆、方法区交互
在探讨交互之前,我们先回顾一下栈、堆、方法区的作用:
(1)栈存储的是局部变量信息
(2)堆存储的是类的实例对象(也就是new出来的东西)
(3)方法区存储的是类的结构信息,包括常量池、静态变量、构造函数等。
下面是两个类,一个是AppMain,主要用来执行测试类:
在运行AppMain类的mian方法时,栈、堆以及方法区在运行时数据区的交互情况如下:
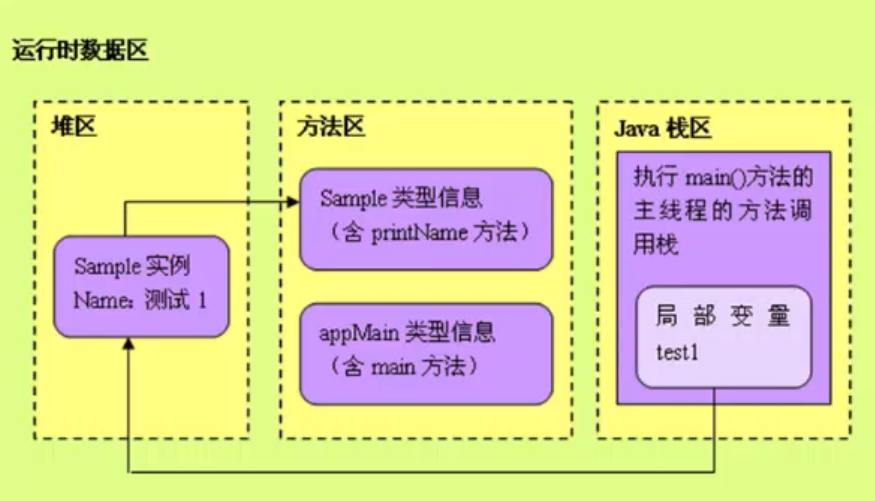
当执行mian方法时,“Sample test1 = new Smaple("测试1");”语句中,test1时一个局部变量(一个引用),局部变量都保存在栈内存中,而“new Smaple("测试1")”的是test1这个引用指向的实例,该实例被存储在堆内存中,而Sample实例被创建后,赋值的name在Sample类中也是一个局部变量,它也被存储在栈内存中,它被赋值的"测试1"或"测试2"是name引用指向的实例对象,被存放在堆内存中。而Sample的类信息,printName方法,以及AppMain的类信息,main方法,都被存储在方法区中,当需要执行方法时,需要在方法区中加载该类的方法定义。
二、内存模型
Java内存模型(Java Memory Model)简称“JMM”,该内存模型满足“原子性”、“可见性”和“有序性”。
对于Java的内存模型,每一个线程都有一个工作内存,还有一个内存是主内存,主内存是所有线程共享的内存,而工作内存是每个线程私有的内存。工作内存和主内存是需要保持同步关系的,即主内存中有变量的原始值,而工作内存中存放了主内存中变量的拷贝。
①原子性
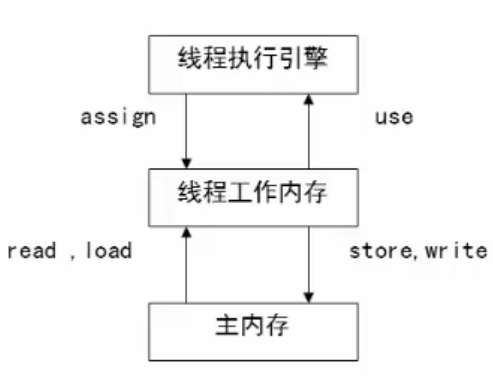
工作内存和主内存之间的同步,主要是通过“assign”、“use”、“read”、“load”、“store”、“write”操作来完成的:

当一个数据从主内存复制到工作内存时,出现两个动作:
(1)主内存执行read读操作,将读出的变量传送到工作内存
(2)工作内存执行load操作,加载从主内存中读取的变量
当一个数据从工作内存复制到主内存时,出现两个动作:
(1)工作内存执行store存储操作,将变量传送到主内存
(2)主内存接收到工作内存的变量后,执行write操作将变量存储
以上的每一个操作都是原子的,即在执行期间不会中断,即保证了操作的“原子性”。
②可见性
但正是因为上面的“原子性”,对于普通变量,一个线程中更新的值,不能马上反应在其他变量中。因为每个线程的变量都存储在自己的工作内存中,想要共享数据就要到主内存中取其他线程工作内存的复制,而工作内存的变量同步到主内存是有时差的,所以多个线程的操作不会立刻反应在主内存的变量中。此时就需要满足变量的“可见性”,即一处修改,处处更新。
下图就是线程的工作内存(也可称作本地内存),和主内存之间的变量关系:

这里,如果需要在其他变量中立即可见,需要使用volatile关键字。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
下面就是一个使用了volatile关键字的java代码:
volatile关键字总结:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证变量的“可见性”。
还有一个final关键字,保证的是一旦变量初始化完成,其它线程即可见。
③有序性
我们都知道,多线程是共用系统内存的,为了让多个程序跑起来,内存会分别轮番将内存让步给各个线程去执行,保证一段时间内所有线程都保持同步(平行)运行状态,而不是结构式的串行运行。
如果站在一个线程的内部观察程序的执行操作,所有操作都是按照事先编写好的代码一步一步执行的,是有序的。而站在其它线程的角度上观察这个线程的执行操作,会因为内存分配的先后导致的一系列原因,导致被观察的线程的操作是无序的。
上面的话可能有点绕,我们举个例子,线程A的操作是先更新变量a,再更新变量b,而由于工作内存和主内存的更新延迟,线程B有可能先看到变量b的更新,再看到变量a的更新。
产生无序的原因有很多种,主要的两个原因就是“指令重排”和“主内存同步延时”。关于主内存同步延时的问题前面已经提到过,这里我们主要来探讨指令重排的问题。
什么是“指令重排”?为了让系统的性能提高,程序可能会将代码的执行顺序做一些改变,例如下面的例子:
a=1;b=2;
上面的一段赋值语句就可以进行重排,因为两者之间没有任何的关联性,且重拍后对程序的执行结果没有任何影响。
而有一些操作就不能够进行重排,例如:

这是因为后面的语句与前面的语句有很强烈的关联性,即没有前面语句的执行,后面的语句就无法执行,亦或是后面的语句先执行就会导致整个运算结果发生变化。
另外,编译器不考虑多线程之间的语义。
下面举一个指令重排的具体例子:

可以看到,在线程A中,由于"a=1'和"flag=true"之间没有数据依赖关系,故两者可以重排。此时除了正常的执行顺序外,还有两种执行可能:
线程A先给flag赋值,然后再给a赋值:
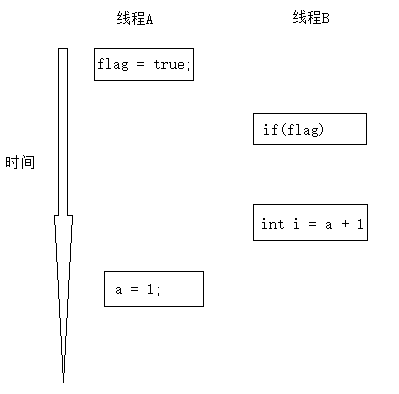
此时a还是0,i的赋值就会是0+1为1,而不是期待的2。
线程B先进行i的运算,将运算结果保存在缓存中,然后执行线程A:

此时先给i赋值时,a还是0,i的赋值就会是0+1为1,而不是期待的2。
就可能因为指令重排的原因,发生这两种情况,导致线程B的i有可能得到错误的赋值。
前面我们说到,synchronized和Lock能够保证“可见性”,同理,我们也可以使用synchronized和Lock来保证多线程执行的“有序性”。
上面的代码可以更改为:

此时会因为加了synchronized关键字的方法,在没有执行结束之前是被锁的状态,此时内存不会在方法执行了一半的时候让步给其它内存,而是要执行结束后才把内存让步给其它线程。此时不管线程内部如何进行指令重排,也不会与影响线程A的最终执行结果。
指令重排的基本原则:

三、代码的运行机制
介绍完了内存结构,我们再来补充一下代码的运行机制。一般分为两种:
(1)解释运行
解释运行将源语言书写的源程序作为输入,解释一句后提交计算机执行一句,并不形成目标程序。
(2)编译运行(JIT)
编译运行会将高级语言(Java/c/Python等)源程序作为输入,进行翻译转换,产生出机器语言的目标程序,然后再让计算机去执行这个目标程序,得到计算结果。
值得一提的是,大多数的编译程序直接产生机器语言的目标代码,形成可执行的目标文件,但也有的编译程序则先产生汇编语言一级的符号代码文件,然后再调用汇编程序进行翻译加工处理,最后产生可执行的机器语言目标文件。
好玩的一种比喻就是:编译运行就是做好一桌子菜做熟了再开吃,而解释运行像是吃火锅,夹一个菜弄熟了吃一个。而解释运行效率低一些的原因就是要一边煮一边吃...哈哈
转载请注明出处:https://blog.csdn.net/acmman/article/details/80374774
一、栈、堆、方法区交互
在探讨交互之前,我们先回顾一下栈、堆、方法区的作用:
(1)栈存储的是局部变量信息
(2)堆存储的是类的实例对象(也就是new出来的东西)
(3)方法区存储的是类的结构信息,包括常量池、静态变量、构造函数等。
下面是两个类,一个是AppMain,主要用来执行测试类:
public class AppMain{//运行时,jvm把AppMain的信息都放入方法区
public static void main(String[] args){//main方法本身也放入方法区
Sample test1 = new Smaple("测试1");
//test1是引用,所以放到栈区里,Sample是自定义对象应该放到堆里面
Sample test2 = new Smaple("测试2");
test1.printName();
test1.printName();
}
}一个是Sample类,主要用来接收参数,并提供打印参数的方法:
public class Sample{//运行时,jvm把Sample的信息都放入方法区
private String name;
//new Sample实例后,name引用放入栈区里,name对象放入堆里。
public Smaple(String name){
this.name = name;
}
//print方法本身放入方法区里
public void printName(){
System.out.println(name);
}
}
在运行AppMain类的mian方法时,栈、堆以及方法区在运行时数据区的交互情况如下:
当执行mian方法时,“Sample test1 = new Smaple("测试1");”语句中,test1时一个局部变量(一个引用),局部变量都保存在栈内存中,而“new Smaple("测试1")”的是test1这个引用指向的实例,该实例被存储在堆内存中,而Sample实例被创建后,赋值的name在Sample类中也是一个局部变量,它也被存储在栈内存中,它被赋值的"测试1"或"测试2"是name引用指向的实例对象,被存放在堆内存中。而Sample的类信息,printName方法,以及AppMain的类信息,main方法,都被存储在方法区中,当需要执行方法时,需要在方法区中加载该类的方法定义。
二、内存模型
Java内存模型(Java Memory Model)简称“JMM”,该内存模型满足“原子性”、“可见性”和“有序性”。
对于Java的内存模型,每一个线程都有一个工作内存,还有一个内存是主内存,主内存是所有线程共享的内存,而工作内存是每个线程私有的内存。工作内存和主内存是需要保持同步关系的,即主内存中有变量的原始值,而工作内存中存放了主内存中变量的拷贝。
①原子性
工作内存和主内存之间的同步,主要是通过“assign”、“use”、“read”、“load”、“store”、“write”操作来完成的:
当一个数据从主内存复制到工作内存时,出现两个动作:
(1)主内存执行read读操作,将读出的变量传送到工作内存
(2)工作内存执行load操作,加载从主内存中读取的变量
当一个数据从工作内存复制到主内存时,出现两个动作:
(1)工作内存执行store存储操作,将变量传送到主内存
(2)主内存接收到工作内存的变量后,执行write操作将变量存储
以上的每一个操作都是原子的,即在执行期间不会中断,即保证了操作的“原子性”。
②可见性
但正是因为上面的“原子性”,对于普通变量,一个线程中更新的值,不能马上反应在其他变量中。因为每个线程的变量都存储在自己的工作内存中,想要共享数据就要到主内存中取其他线程工作内存的复制,而工作内存的变量同步到主内存是有时差的,所以多个线程的操作不会立刻反应在主内存的变量中。此时就需要满足变量的“可见性”,即一处修改,处处更新。
下图就是线程的工作内存(也可称作本地内存),和主内存之间的变量关系:
这里,如果需要在其他变量中立即可见,需要使用volatile关键字。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
下面就是一个使用了volatile关键字的java代码:
public class VolatileStopThread extends Thread{
private volatile boolean stop = false;
public void stopMe(){
stop = true;
}
public void run(){
int i=0;
while(!stop){
i++;
}
System.out.println("Stop thread");
}
public static void main(String[] args)throws InterruptedException{
VolatileStopThread t = new VolatileStopThread();
t.start();
Thread.sleep(1000);
t.stopMe();
Thread.sleep(1000);
}
}上面代码的意思就是,有一个线程在不停的对一个变量进行加操作,而另外一个线程可以指定该线程是否停止,会将stop设置为true,当stop为true的时候,该线程就会停止操作。即一个线程一直在监听stop值,而另一个线程会修改该线程的stop值,当stop被修改后,拥有stop值得线程就会做出相应动作。此时我们在stop变量上添加了volatile变量,表示一旦这个值在其它工作内存中被修改,会立即同步到主内存,而其他线程需要读取时,它会去内存中读取新值。
volatile关键字总结:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证变量的“可见性”。
还有一个final关键字,保证的是一旦变量初始化完成,其它线程即可见。
③有序性
我们都知道,多线程是共用系统内存的,为了让多个程序跑起来,内存会分别轮番将内存让步给各个线程去执行,保证一段时间内所有线程都保持同步(平行)运行状态,而不是结构式的串行运行。
如果站在一个线程的内部观察程序的执行操作,所有操作都是按照事先编写好的代码一步一步执行的,是有序的。而站在其它线程的角度上观察这个线程的执行操作,会因为内存分配的先后导致的一系列原因,导致被观察的线程的操作是无序的。
上面的话可能有点绕,我们举个例子,线程A的操作是先更新变量a,再更新变量b,而由于工作内存和主内存的更新延迟,线程B有可能先看到变量b的更新,再看到变量a的更新。
产生无序的原因有很多种,主要的两个原因就是“指令重排”和“主内存同步延时”。关于主内存同步延时的问题前面已经提到过,这里我们主要来探讨指令重排的问题。
什么是“指令重排”?为了让系统的性能提高,程序可能会将代码的执行顺序做一些改变,例如下面的例子:
a=1;b=2;
上面的一段赋值语句就可以进行重排,因为两者之间没有任何的关联性,且重拍后对程序的执行结果没有任何影响。
而有一些操作就不能够进行重排,例如:
这是因为后面的语句与前面的语句有很强烈的关联性,即没有前面语句的执行,后面的语句就无法执行,亦或是后面的语句先执行就会导致整个运算结果发生变化。
另外,编译器不考虑多线程之间的语义。
下面举一个指令重排的具体例子:
可以看到,在线程A中,由于"a=1'和"flag=true"之间没有数据依赖关系,故两者可以重排。此时除了正常的执行顺序外,还有两种执行可能:
线程A先给flag赋值,然后再给a赋值:
此时a还是0,i的赋值就会是0+1为1,而不是期待的2。
线程B先进行i的运算,将运算结果保存在缓存中,然后执行线程A:
此时先给i赋值时,a还是0,i的赋值就会是0+1为1,而不是期待的2。
就可能因为指令重排的原因,发生这两种情况,导致线程B的i有可能得到错误的赋值。
前面我们说到,synchronized和Lock能够保证“可见性”,同理,我们也可以使用synchronized和Lock来保证多线程执行的“有序性”。
上面的代码可以更改为:
此时会因为加了synchronized关键字的方法,在没有执行结束之前是被锁的状态,此时内存不会在方法执行了一半的时候让步给其它内存,而是要执行结束后才把内存让步给其它线程。此时不管线程内部如何进行指令重排,也不会与影响线程A的最终执行结果。
指令重排的基本原则:
三、代码的运行机制
介绍完了内存结构,我们再来补充一下代码的运行机制。一般分为两种:
(1)解释运行
解释运行将源语言书写的源程序作为输入,解释一句后提交计算机执行一句,并不形成目标程序。
(2)编译运行(JIT)
编译运行会将高级语言(Java/c/Python等)源程序作为输入,进行翻译转换,产生出机器语言的目标程序,然后再让计算机去执行这个目标程序,得到计算结果。
值得一提的是,大多数的编译程序直接产生机器语言的目标代码,形成可执行的目标文件,但也有的编译程序则先产生汇编语言一级的符号代码文件,然后再调用汇编程序进行翻译加工处理,最后产生可执行的机器语言目标文件。
好玩的一种比喻就是:编译运行就是做好一桌子菜做熟了再开吃,而解释运行像是吃火锅,夹一个菜弄熟了吃一个。而解释运行效率低一些的原因就是要一边煮一边吃...哈哈
转载请注明出处:https://blog.csdn.net/acmman/article/details/80374774