

尽管外部缓存是减少延迟的好帮手,但它们通常会带来比好处更多的问题。以下是如何解决这个问题。
译自Why and How Teams Are Replacing External Database Caches,作者 Felipe Cardeneti Mendes。
当现有数据库无法满足所需的服务级别协议 (SLA) 时,团队通常会考虑外部缓存。这是一个明确的以性能为导向的决策。将外部缓存置于数据库前面通常是为了补偿由各种因素(例如低效的数据库内部、驱动程序使用、基础设施选择、流量高峰等)造成的次优延迟。
缓存似乎是一种快速且简单的解决方案,因为部署可以在没有巨大麻烦且无需承担数据库扩展、数据库架构重新设计甚至更深入的技术转换的重大成本的情况下实施。然而,外部缓存并不像通常所说的那么简单。它们可能是分布式应用程序架构中比较有问题的组件之一。
在某些情况下,这是一种必要的恶,例如当您需要频繁访问由冗长且昂贵的计算产生的转换数据时,并且您已经尝试了所有其他减少延迟的方法。但在许多情况下,性能提升根本不值得。您解决了一个问题,但又产生了其他问题。
以下是与外部缓存相关的经常被忽视的风险,以及三个团队通过用单一解决方案替换其核心数据库和外部缓存来实现性能提升和节省成本的方法。剧透:他们采用了 ScyllaDB,这是一种高性能数据库,通过利用专门的内部缓存来实现改进的长尾延迟。
为什么不缓存?
在 ScyllaDB,我们与无数团队合作,这些团队在努力应对传统数据库性能提升尝试的成本、麻烦和限制。以下是我们看到团队在将外部缓存置于其数据库前面时遇到的主要困难。
外部缓存增加了延迟
单独的缓存意味着在途中又多了一次跳转。当缓存围绕数据库时,第一次访问发生在缓存层。如果数据不在缓存中,则请求将被发送到数据库。这会给未缓存数据的本来就慢的路径增加延迟。有人可能会声称,当整个数据集适合缓存时,额外的延迟不会发挥作用。然而,除非您的数据集相当小,否则将其全部存储在内存中会大大增加成本,因此对于大多数组织来说,这是极其昂贵的。
外部缓存是一种额外成本
缓存意味着昂贵的 DRAM,这意味着每千兆字节的成本高于固态磁盘。(有关此内容的更多详细信息,请参见Grafana 的 Danny Kopping 在 P99 CONF 上的演讲。)与其为缓存配置一个完全独立的基础设施,通常最好使用现有的数据库内存,甚至增加它以进行内部缓存。当正确调整大小时,现代数据库缓存可以与传统的内存中缓存解决方案一样高效。当工作集大小太大而无法放入内存时,数据库通常会在优化对闪存存储的 I/O 访问方面表现出色,从而使单独的数据库(无外部缓存)成为首选且更便宜的选择。
外部缓存降低了可用性
没有哪种缓存的高可用性解决方案能与数据库本身相媲美。现代分布式数据库有多个副本;它们还具有拓扑感知和速度感知,并且可以在不丢失数据的情况下承受多次故障。
例如,常见的复制模式是三个本地副本,这通常允许在这些副本之间平衡读取,以有效利用数据库的内部缓存机制。考虑一个具有三个副本因子的九节点集群:从本质上讲,每个节点将保存您总数据集大小的大约三分之一。由于请求在不同的副本之间平衡,因此这为您提供了更多空间来缓存数据,从而可以消除对外部缓存的需求。相反,如果外部缓存恰好在大量冷请求之前使条目失效,则可用性可能会受到一段时间的影响,因为数据库在其内部缓存中没有该数据(更多内容见下文)。
缓存通常缺乏高可用性属性,并且根据其启发式方法很容易发生故障或使记录无效。部分故障更为常见,在一致性方面甚至更糟。当缓存不可避免地发生故障时,数据库将受到未经缓解的查询洪流的冲击,并可能破坏您的 SLA。此外,即使缓存本身具有一些高可用性功能,它也无法协调处理此类故障及其前面的持久性数据库。底线:依赖数据库,而不是让您的延迟 SLA 依赖于缓存。
应用程序复杂性——您的应用程序需要处理更多情况
外部缓存会引入应用程序和操作复杂性。一旦您拥有外部缓存,您就有责任使缓存与数据库保持最新。无论您的缓存策略如何(例如直写、缓存旁路等),都会有一些边缘案例,其中您的缓存可能与数据库不同步,您必须在应用程序开发期间考虑这些情况。您的客户端设置(例如故障转移、重试和超时策略)需要匹配缓存和数据库的属性,以便在缓存不可用或变冷时发挥作用。通常,此类场景很难测试和实现。
外部缓存破坏数据库缓存
现代数据库具有嵌入式缓存和管理它们的复杂策略。当您在数据库前面放置缓存时,大多数读取请求只会到达外部缓存,而数据库不会将这些对象保存在其内存中。结果,数据库缓存变得无效。当请求最终到达数据库时,其缓存将变冷,并且响应将主要来自磁盘。结果,从缓存到数据库再返回到应用程序的往返行程可能会增加延迟。
外部缓存可能会增加安全风险
外部缓存为您的基础设施增加了全新的攻击面。加密、隔离和对数据进行访问控制放在缓存中可能与数据库层本身的不同。
外部缓存忽略数据库知识和数据库资源
数据库非常复杂,专为系统上的专用 I/O 工作负载而构建。许多查询访问相同的数据,并且可以将一定数量的工作集大小缓存在内存中以节省磁盘访问。一个好的数据库应该有复杂的逻辑来决定它应该缓存哪些对象、索引和访问。数据库还应该有驱逐策略,以确定新数据何时应该替换现有(较旧)缓存对象。
扫描抗性缓存就是一个例子。在扫描大型数据集(例如大范围或全表扫描)时,会从磁盘读取大量对象。数据库可以意识到这是一个扫描(而不是常规查询),并选择将其对象保留在其内部缓存之外。但是,外部缓存(遵循直读策略)会将结果集像其他任何结果集一样对待,并尝试缓存结果。数据库会根据传入的请求速率自动将缓存的内容与磁盘同步,因此用户和开发人员无需执行任何操作即可确保对最近写入数据的查找具有性能和一致性。因此,如果由于某种原因,您的数据库响应不够快,则意味着:
- 缓存配置错误。
- 没有足够的 RAM 用于缓存。
- 工作集大小和请求模式不适合缓存。
- 数据库缓存实现很差。
更好的选择:让数据库处理它
如何在没有外部数据库缓存的风险下满足您的 SLA?许多团队发现,通过迁移到更快的数据库(例如 ScyllaDB)并使用专门的内部缓存,他们能够以更少的麻烦和更低的成本满足其延迟 SLA。当然,结果会根据工作负载特征和技术要求而有所不同。但对于可能实现的目标,请考虑这些团队能够实现的目标。
SecurityScorecard 通过每年节省 100 万美元实现延迟减少 90%
SecurityScorecard 旨在通过改变数千个组织了解、缓解和沟通网络安全的方式,让世界变得更加安全。其评级平台是对组织的整体网络安全和网络风险敞口的客观、数据驱动和可量化的衡量标准。
团队之前的数据架构在一段时间内为他们提供了良好的服务,但无法跟上他们的增长速度。他们的平台 API 查询了三个数据存储中的一个:Redis(用于更快地查找 1200 万张记分卡)、Aurora(用于存储跨节点的 40 亿个测量统计数据)或 Hadoop 分布式文件系统上的 Presto 集群(用于对历史结果进行复杂的 SQL 查询)。
随着数据和请求的增长,挑战随之而来。Aurora 和 Presto 在高吞吐量下延迟激增。Redis 的最大可能实例仍然不够用,而且他们不想使用 Redis 集群的复杂性。
为了在快速业务增长所需的新的规模上降低延迟,该团队转向了 ScyllaDB Cloud,并开发了一个新的评分 API,将延迟敏感性较低的要求路由到 Presto 和 S3 存储。以下是此架构的可视化,并且相当简单:
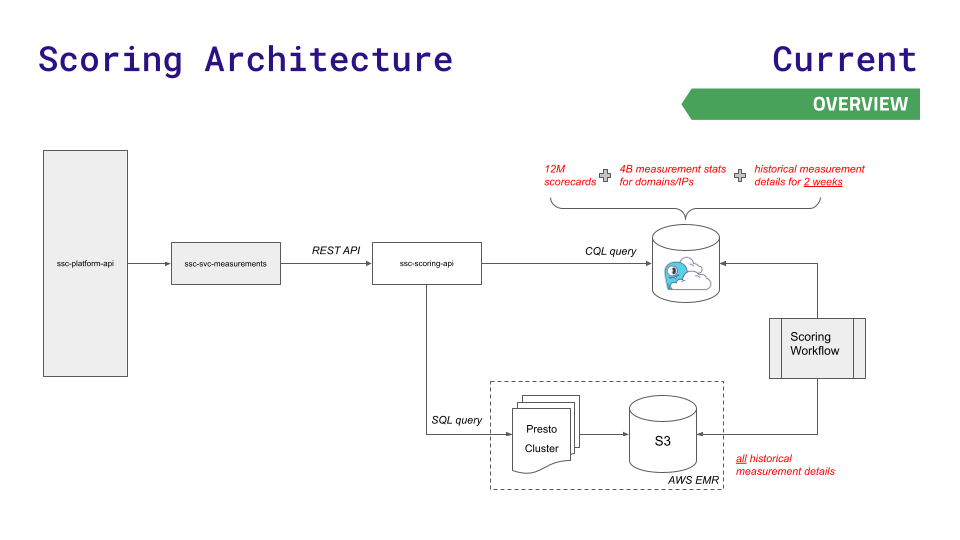
此举导致:
- 大多数服务端点的延迟降低 90%
- 与 Presto/Aurora 性能相关的生产事件减少 80%
- 每年节省 100 万美元的基础设施成本
- 数据管道处理速度提高 30%
- 大幅改善客户体验
[阅读有关 SecurityScorecard 用例的更多信息]
IMVU 将 Redis 成本降低到 100 倍
IMVU 是一个流行的社交社区,它使世界各地的人们能够使用台式机、平板电脑和移动设备上的 3D 头像进行互动。为了满足不断增长的规模要求,IMVU 决定需要比其之前的数据库架构(MySQL 和 Redis 前面的 Memcached)性能更高的解决方案。该团队寻找更易于配置、更易于扩展且(如果成功)更易于扩展的东西。
“Redis 非常适合原型制作功能,但一旦我们实际推出,开支就变得难以证明了,”IMVU 的高级软件工程师 Ken Rudy 说。“ScyllaDB 经过优化,可以将所需数据保存在内存中,并将所有其他内容保存在磁盘中。ScyllaDB 使我们能够为 Redis 可以处理的规模的百倍规模保持相同的响应能力。”
Comcast 使用 250 万美元的年节省额将长尾延迟降低 95%
Comcast 是一家全球媒体和技术公司,拥有三项主要业务:Comcast Cable,美国最大的视频、高速互联网和电话提供商之一,面向住宅客户;NBCUniversal 和 Sky。Comcast 的 Xfinity 服务为 1500 万户家庭提供服务,每天有超过 20 亿次 API 调用(读/写)和超过 2 亿个新对象。在七年时间里,该项目从支持 30,000 台设备扩展到超过 3100 万台设备。
Cassandra 的长尾延迟在公司快速增长的规模下被证明是不可接受的。为了向用户掩盖 Cassandra 的延迟问题,该团队在其数据库前放置了 60 台缓存服务器。使此缓存层与数据库保持一致给管理员带来了很大的麻烦。由于缓存和相关基础设施必须在数据中心之间复制,因此 Comcast 需要保持缓存处于活动状态。他们实施了一个缓存预热器,该预热器检查写入量,然后在数据中心之间复制数据。
在努力应对这种方法的开销后,Comcast 很快转向了 ScyllaDB。ScyllaDB 旨在通过其内部缓存机制最大程度地减少延迟峰值,使 Comcast 能够消除外部缓存层,提供了一个简单框架,其中数据服务直接连接到数据存储。Comcast 能够用仅 78 个 ScyllaDB 节点替换 962 个 Cassandra 节点。他们在完全消除 60 台缓存服务器的同时提高了整体可用性和性能。结果:P99、P999 和 P9999 延迟降低了 95%,并且能够处理两倍以上的请求——运营成本为 60%。这最终为他们每年节省了 250 万美元的基础设施成本和人员开销。
结束语
尽管外部缓存是减少延迟(例如提供不需要任何持久性级别的静态内容和个性化数据)的绝佳伴侣,但当它们放置在数据库前面时,通常会带来比好处更多的问题。
最主要的权衡包括成本增加、应用程序复杂性增加、到数据库的额外往返以及额外的安全表面。通过重新考虑现有的缓存策略并切换到在规模上提供可预测低延迟的现代数据库,团队可以简化其基础设施并最大程度地降低成本。同时,他们仍然可以在没有外部缓存带来的额外麻烦和复杂性的情况下满足其 SLA。
一个不知名的开源项目可以带来多少收入 微软中国 AI 团队集体打包去美国,涉及数百人 华为官宣余承东职务调整 15 年前被钉在“FFmpeg 耻辱柱”,今天他却得谢谢咱——腾讯QQ影音一雪前耻? 华中科技大学开源镜像站正式开放外网访问 报告:Django 仍然是 74% 开发者的首选 Zed 编辑器在 Linux 支持方面取得进展 知名开源公司前员工爆料:技术 leader 被下属挑战后狂怒爆粗、辞退怀孕女员工 阿里云正式发布通义千问 2.5 微软向 Rust 基金会捐赠 100 万美元本文在云云众生(https://yylives.cc/)首发,欢迎大家访问。