
随着数字化转型的浪潮兴起,越来越多企业认识到工业物联网在提升工业生产安全性和效率方面的关键作用。然而,随着设备规模的扩大和工艺复杂性的提升,智能化运维监管成为工业企业急需解决的重要挑战。
智能运维是一种利用先进技术和数据分析方法来提高生产设备和工艺系统可靠性、安全性与效率的方法。它结合了物联网、人工智能和大数据分析等技术,通过实时监测、故障预测、优化维护计划和自动化操作等手段,帮助企业实现设备故障的及时诊断和修复,降低生产停机时间,并提升设备利用率和生产质量。智能运维不仅可以减少人为错误和人力成本,还可以提高生产过程的可持续性和环境友好性,对提升企业竞争力和促进可持续发展具有重要意义。
DolphinDB 是由浙江智臾科技有限公司研发的一款高性能分布式时序数据库,能够完美解决智能运维领域面临的大数据量和实时性要求高的问题。DolphinDB 不仅支持数据的存储,还具备强大的数据处理和分析能力。它集成了功能强大的编程语言和高容量高速度的流数据分析系统,为智能运维提供了轻量级、一站式的解决方案,而无需复杂的系统架构。
1. 智能运维面临的挑战
智能运维面临着几个关键挑战:
- 设备异构性:一个大型工业平台系统通常包含众多不同类型、不同品牌的设备,这些设备可能使用各种不同的通信协议和数据格式。不同设备数据的接入、管理是一大难题。
- 数据激增与复杂性:随着工业设备和系统的智能化程度提高,产生的数据规模急剧增加。这些数据不仅在数量上巨大,而且包含了更多的复杂性和多样性,传统的运维手段难以满足对数据的高效处理和深度分析需求。
- 实时性与准确性要求提升:众多行业对设备状态、生产过程等实时性要求越来越高,需要实时监测和故障诊断,以确保生产的连续性和可靠性。传统的运维模式可能无法满足对实时性和准确性的双重需求,需要更加智能、高效的运维方式。
2. 解决方案
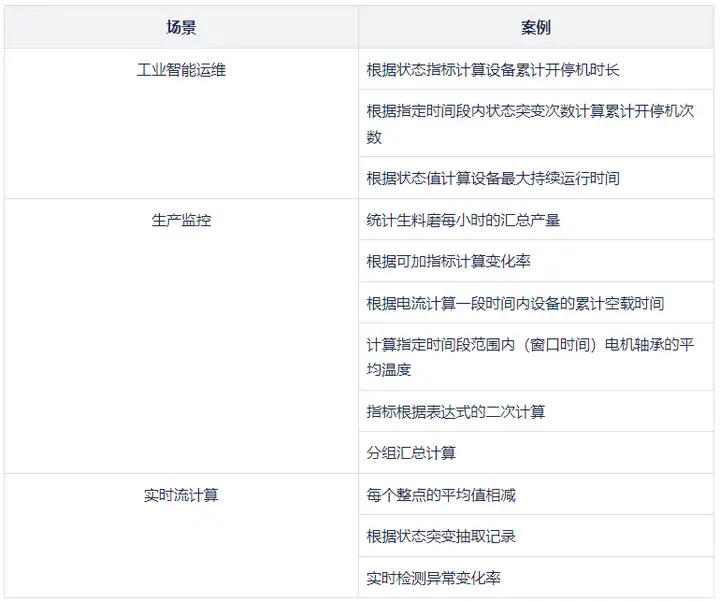
本文将通过十二个典型工业生产的智能运维场景,来验证 DolphinDB 在工业物联网智能运维方面的应用能力:
架构图如下:
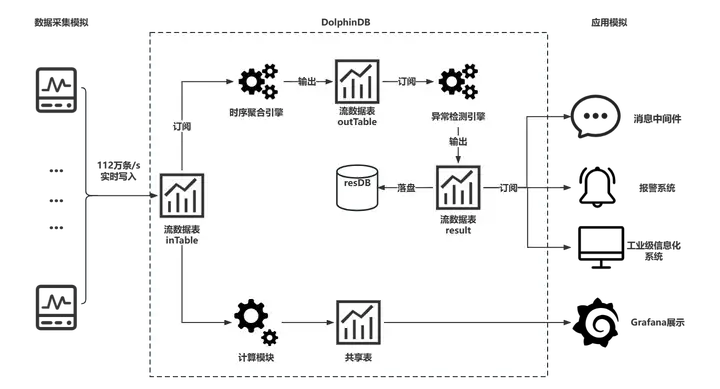
下文中,我们将详细介绍 DolphinDB 的安装部署、数据准备以及功能的实现过程。
3. 前期准备
3.1 安装部署
3.2 模拟环境
在此案例中,我们需要处理 100 台设备,每台设备有 1000 个测点,采集频率为每 5 分钟 1 次。为了对这些数据进行有效的建模,我们使用了宽表模型,其中包含了 6 个字段,分别为数采时间、设备编号、逻辑位置 ID、物理位置 ID、属性测点编码和测点值。
| 字段名 | ts | deviceCode | logicalPositionId | physicalPositionId | propertyCode | propertyValue |
|---|---|---|---|---|---|---|
| 字段描述 | 数采时间 | 设备编号 | 逻辑位置ID | 物理位置ID | 属性测点编码 | 测点值 |
| 数据类型 | DATETIME | SYMBOL | SYMBOL | SYMBOL | SYMBOL | INT |
| 字节占用 | 4 | 4 | 4 | 4 | 4 | 4 |
在此案例中,我们需要记录 100 台设备在 10 天内产生的数据,共 2.88 亿条。
DolphinDB 数据库支持多种分区类型,包括范围分区、哈希分区、值分区、列表分区和复合分区。用户可以根据自己的需求选择不同的分区类型。在本案例中,我们选择了值分区。对于 10 天产生的数据,会按照天进行切分,将每天产生的数据放在同一个分区中。这种分区方式能够提高查询效率,使得查询只需要访问特定的分区,而不需要扫描整个数据表。
create database "dfs://db_test" partitioned by VALUE([2022.11.01]),engine='TSDB'
create table "dfs://db_test"."collect"(
ts DATETIME,//数采时间
deviceCode SYMBOL,//设备编号
logicalPositionId SYMBOL,//逻辑位置ID
physicalPositionId SYMBOL,//物理位置ID
propertyCode SYMBOL,//属性测点编码
propertyValue INT//测点值
)
partitioned by ts
sortColumns=[`deviceCode,`ts]完成了建表建库后,我们将使用自定义函数模拟 100 台设备在 10 天内产生的 2.88 亿条数据,并将生成的数据写入 DolphinDB 数据库。详细的实现过程请参考文章末尾的完整示例代码。
4. 功能实现
4.1 工业智能运维
首先,DolphinDB 可以实现设备的全寿命周期管理。通过设备完整、实时的监测数据,全面掌握设备的异常及故障情况。根据历史数据及设定的条件,系统自动分析设备维修保养的频度,并生成相应的任务单,并定时提醒相关责任人。同时,DolphinDB 能够在线跟踪维修保养的过程,并进行记录与分析评估。通过实现计划性维修及预测性保养,并能够消除大面积盲目定期大修与保养的大量无效人工,从而保障设备的运行效果,并延长设备的寿命。
此外,DolphinDB 具备强大的数据挖掘和分析能力,可以帮助企业深度挖掘和分析设备数据,生成丰富多样的统计报表。例如,可以对设备的总能耗、分项能耗进行统计分析,包括按日、周、月、年等任意时间段进行同比、环比和趋势预测。还可以对各区域(考核单元)的能耗总量进行统计,并按时间段的占比和排名进行分析。DolphinDB 还能对重点设备的分项能耗占比和排名进行详尽的分析。
最后,实时监测和有效报警是提升运维安全保障能力的关键环节。DolphinDB 可以实时监测设备的运行状态,并配置异常预警报警参数。基于实时监测设备参数变化趋势,DolphinDB 植入了多参数报警算法进行诊断分析,并可对超过预警和报警阈值的设备或参数进行实时报警。报警支持按需订阅,可以通过邮件、手机短信等方式通知相关责任人,并能根据报警信息触发业务工单,及时通知相关维护人员,从而提高设备的安全保障能力。
DolphinDB 的这些功能,包括计算设备累计开停机时长、开停机次数、最大持续运行时间和实时监控设备状态等,能够为工业智能运维提供强有力的支持,详见以下各例。
案例 1:根据状态指标计算设备累计开停机时长
设备累计开停机时长是设备全寿命周期管理中的一个常见指标。
计算过程中主要涉及两个字段:propertyValue 和 ts。其中,propertyValue 记录设备的状态,0 表示关机,1 表示开机;ts 是时间戳。计算过程如下:
- 用
deltas函数来计算相邻时间戳之间的差值。 - 用
bar(ts,1H)将时间戳按小时进行划分,将数据分组。 - 根据设备状态
propertyValue对同一小时内的数据进行进一步分组。 - 对同一组内的时间差值求和,从而得到设备的累计开停机时长。
通过以上步骤计算得到的数据可以被推送给业务应用,为运维人员了解设备状态并制定维护计划提供帮助。
//案例 1:根据状态指标计算设备累计开停机时长
dt=select * from pt where deviceCode="361RP88" and propertyCode="361RP88002"
//处理累计时长
t = select *,deltas(ts) as duration from dt
//输出(分钟)
select sum(duration)/60 as duration from t group by bar(ts,1H) as bar_ts,deviceCode,logicalPositionId,physicalPositionId,propertyValue案例 2:根据指定时间段内状态突变次数计算累计开停机次数
指定时间段内设备开停机次数的计算过程主要涉及的字段为 propertyValue,该字段记录了设备的状态。其中,0 表示关机,1 表示开机。计算过程如下:
- 用
deltas函数计算相邻两个propertyValue间的差值。可能结果有三种:0、1 和 -1。其中,0 表示状态没有变化,1 表示状态由开机变为关机,-1 表示状态由关机变为开机。 - 统计结果中 1 和 -1 的个数,以获得开停机的次数。这些数据可以进一步推送到业务系统,帮助运维人员了解设备的状态,并制定维护计划。
//案例 2:根据指定时间段内状态突变次数计算累计开停机次数
t= select *,deltas(propertyValue) from dt where ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59
//输出
select count(*) from t where deltas_propertyValue in (1,-1) group by deviceCode,logicalPositionId,physicalPositionId,bar(ts,1H),deltas_propertyValue案例 3:根据状态值,计算设备最大持续运行时间
设备的最大持续运行时间是设备全寿命周期管理中一个常见的指标。在计算过程中的主要关注字段为设备状态字段 propertyValue,其中,0 表示设备关机,1 表示设备开机。因此,propertyValue 的值由 0 变为 1 表示一次开机,由 1 变为 0 表示一次停机。通过计算各状态的持续时长,并进行筛选最大值便可得到设备最大持续运行时间。得益于众多功能强大的内置函数,DolphinDB 只需要三条语句便可实现这个复杂的逻辑过程。
在 DolphinDB 中,可以使用 deltas、segment 和 iif 等函数来实现该计算,过程如下:
- 用
deltas函数计算时间戳之间的差值,得到每个时间点与前一个时间点的时间差。 - 用
segment函数对数据按设备状态进行分组,将具有相同propertyValue值的数据分为一组。 - 用
iif函数对每个数据进行条件判断,在propertyValue为 1 时返回时间差,否则返回 0。 - 用
sum函数求和得到开机状态持续的时长。 - 用
max函数筛选出最长的持续时间,即为设备的最大持续运行时间。
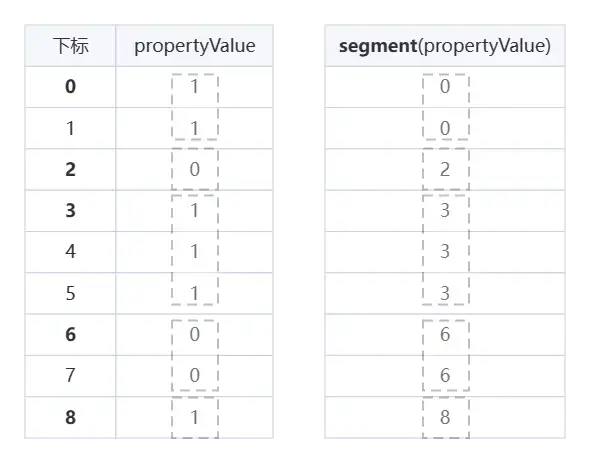
segment函数
//案例 3:根据状态值,计算设备最大持续运行时间
//数据准备,累计时间
t = select *,deltas(ts) as duration from dt where ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59 order by ts
t=select sum(iif(propertyValue==1, duration, 0)) as duration_running_max,sum(iif(propertyValue==1, 0,duration)) as duration_stop_max from t group by deviceCode,logicalPositionId,physicalPositionId,segment(propertyValue)
//输出(分钟)
select max(duration_running_max)/60 as duration_running_max,max(duration_stop_max)/60 as duration_stop_max from t group by deviceCode,logicalPositionId,physicalPositionId4.2 生产监控
案例 4:计算生料磨每小时的总产量
在工业场景中,计算单位时间内的产量是一项常见需求。以下以计算生料磨每小时的总产量为例,介绍 DolphinDB 提供的解决方案。
通过使用 DolphinDB 中的bar、group by 和 sum 函数,一条语句就能够轻松地完成任务。其中,bar(ts, 1H) 函数能够将时间戳 ts 按小时划分,group by 函数能够对数据进行分组,而 sum 函数则能够对组内数据进行求和,从而得到每小时的总产量。
此外,DolphinDB 还提供了函数视图功能,它类似关系数据库中的存储过程,可以封装复杂的业务逻辑,方便用户调用。
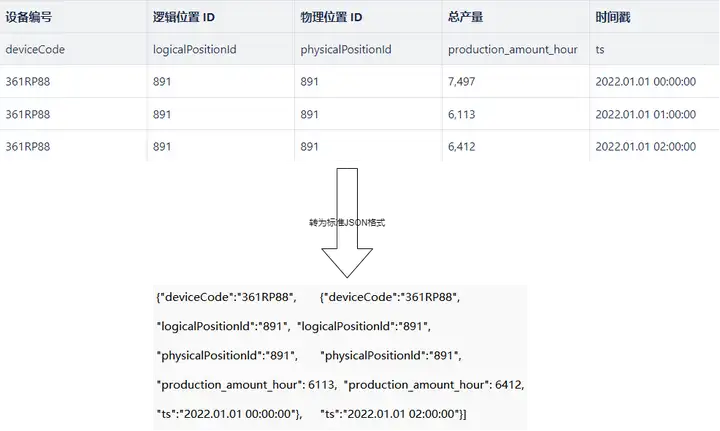
//案例 4:实时计算生料磨每小时的汇总产量
device="361RP88" //设备编号
point="361RP88001" //测点编号,记录产量的测点,得到的propertyValue表示产量值
pt=loadTable("dfs://db_test",`collect)
timer t=select deviceCode,logicalPositionId,physicalPositionId,sum(propertyValue) as production_amount_hour,ts from pt where ts between 2022.01.01 00:00:00 : 2022.01.01 02:59:59 and deviceCode=device and propertyCode=point group by bar(ts,1H) as ts,deviceCode,logicalPositionId,physicalPositionId
t
//自定义函数视图,供应用端调用:
def production_amount_hour(device,point,begintime,endtime){
//业务判断,合法性校验
if (datetime(endtime)-datetime(begintime)>24*3600*30){
return(toStdJson([-1,"查询时间不能超过30天"]))
}
t=select deviceCode,logicalPositionId,physicalPositionId,sum(propertyValue) as production_amount_hour,ts from loadTable("dfs://db_test",`collect) where ts between begintime : endtime and deviceCode=device and propertyCode=point group by bar(ts,1H) as ts,deviceCode,logicalPositionId,physicalPositionId
return t
}
//添加函数视图
addFunctionView(production_amount_hour)
production_amount_hour(device,point,2022.01.01 00:00:00,2022.03.01 00:00:00) //业务判断
production_amount_hour(device,point,2022.01.01 00:00:00,2022.01.01 23:59:59) //应用端正常查询,并输出结果案例 5:根据指定指标计算变化率
电流是工业物联网中常见的监控指标之一,电流保持平稳状态对设备的正常运行至关重要。电流突变可能会导致电路的短路、过载、电压波动等问题,严重情况下甚至会引发火灾、爆炸等安全事故。因此,实时监测电流变化并进行安全预警具有重要意义。
DolphinDB 能够实时计算电流的变化率,并对超出指定值的数据进行记录和推送信息,形成安全预警,从而预防安全事故的发生。电流突变率的计算表达式为 (当前电流值- 前一时刻的电流值)/ 前一时刻的电流值。DolphinDB 可以用一条语句轻松实现获取当前时间的前一时刻的数据。具体实现过程是:
- 通过
deltas计算当前数据与前一时刻数据的差值。 - 计算获得最终结果数据。
对于计算出来的电流突变率,如果超过了指定阈值,DolphinDB 会将其记录下来,并推送给管理人员进行安全预警,从而及时防范安全事故的发生。这种实时监测和预警的方法可以有效地提高设备的安全性和稳定性。
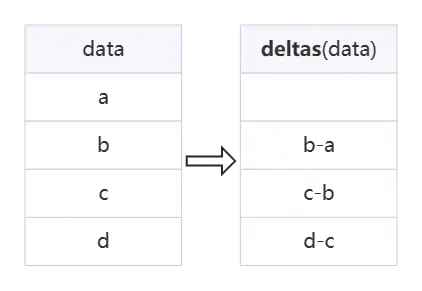
deltas函数
//案例 5:根据可加指标实时计算变化率,超出指定值进行记录
//数据准备
device="361RP88" //设备编号
point="361RP88006" //测点编号,记录电流的测点,得到的propertyValue表示电流值
t=select * from pt where deviceCode=device and propertyCode=point and ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59
//统计变化率
t = select *,prev(propertyValue) as propertyValue_before,propertyValue as propertyValue_now from t
select ts,deviceCode,logicalPositionId,physicalPositionId,propertyCode,propertyValue_before,propertyValue_now, string(format(abs(propertyValue_now-propertyValue_before)*100.0/propertyValue_before,"0.00"))+"%" as rate from t where abs(propertyValue_now-propertyValue_before)/propertyValue_before>1案例 6:根据电流计算一段时间内设备的累计空载时间
设备空载通常指设备在运行时没有工作负载或负载非常小。例如,一台电动机在没有连接到任何负载或者连接到一个非常小的负载时,它处于空载状态。在这种状态下,设备的运行通常会浪费能源,也可能会对设备造成损坏。
电流值小于 60 时,我们可以认为设备处于空载状态。以下是 DolphinDB 实现计算累计空载时间的过程,得到的结果之后可以推送给业务系统进行空载状态预警。
//案例 6:根据电流计算一段时间内设备的累计空载时间
device="361RP17" //设备编号
point="361RP17007" //测点编号,记录电流的测点,得到的propertyValue表示电流值
t=select * from pt where deviceCode=device and propertyCode=point and ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59
//统计空载时间
t = select *,deltas(ts) as duration,nullFill(prev(propertyValue),propertyValue) as before from t where deviceCode=device and propertyCode=point and ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59
//输出
select sum(duration)/60 from t where before<=60 group by bar(ts,1H),deviceCode,logicalPositionId,physicalPositionId案例 7:计算指定时间段范围内(窗口时间)电机轴承的平均温度
电机轴承的温度是设备正常运行的一个重要指标。为实时监测电机轴承温度并进行安全预警,DolphinDB 使用 mavg 函数计算 10 分钟窗口内电机轴承温度的平均值,从而有效地反映电机轴承的运行状态。并且,基于这个平均温度,可以计算出温度突变率,及时发现异常情况 ,并进行相应的安全预警。通过这种实时监测和预警的方法,可以有效地保障设备的安全性和稳定性,提高设备的运行效率和寿命。
//案例 7:计算指定时间段范围内(窗口时间)电机轴承的平均温度
device="361RP17" //设备编号
point="361RP17008" //测点编号,记录电机轴承温度的测点,得到的propertyValue表示温度
//输出
select *,mavg(propertyValue,2) from pt where deviceCode=device and propertyCode=point and ts between 2022.01.01 00:00:00 : 2022.01.01 01:59:59案例 8:指标根据表达式的二次计算
DolphinDB 支持根据指定规则批量修改表内容,灵活方便。DolphinDB 可以根据指定的规则对表中的数据进行分类和修改。以下是根据温度进行等级划分的规则:
- A 等级:温度小于或等于 60
- B 等级:温度大于 60 小于 80
- C 等级:温度大于或等于 80
根据这个规则,可以对数据进行分类并加上相应的等级标签。
DolphinDB 采用列式存储方式,可以轻松地实现对指定列的批量修改。与传统的关系数据库如 MySQL 和PostgreSQL 采用的行式存储不同,DolphinDB 避免了逐个元素赋值的繁琐复杂过程,大大节省了时间。这种灵活、方便的批量修改表内容的功能为数据分析和管理提供了更多的便利和效率。
列式存储和行式存储
//案例 8:指标根据表达式的二次计算
device="361RP17" //设备编号
point="361RP17009" //测点编号,记录温度的测点,得到的propertyValue表示温度
dt=select * from pt where deviceCode=device and propertyCode=point
update!(dt,`propertyValue,rand(100,dt.size()))
//取值
a=select * from dt where propertyValue <=60
b=select * from dt where propertyValue >60 and propertyValue<80
c=select * from dt where propertyValue >=80
//分类
a.addColumn(`temperature_level,SYMBOL)
b.addColumn(`temperature_level,SYMBOL)
c.addColumn(`temperature_level,SYMBOL)
a[`temperature_level]="A"
b[`temperature_level]="B"
c[`temperature_level]="C"
//合并数据
t=a.append!(b).append!(c)
//输出
select * from t order by ts案例 9:分组汇总计算,条件筛选
DolphinDB 可以轻松地支持亿级数据的分组汇总计算和条件筛选,并且能够在毫秒级别响应请求。以下是计算设备 361RP88 在 2022 年 1 月 1 日 23:00:00 之前一小时内平均温度的示例代码:
//案例 9:分组汇总计算,条件筛选
device="361RP88" //设备编号
point="361RP88010" //测点编号,记录温度的测点,得到的propertyValue表示温度
//过去一小时数据
now=2022.01.01 23:00:00
dt=select * from pt where ts>=datetime(now)-3600 and ts<now and deviceCode=device and propertyCode=point
//输出
select deviceCode,propertyCode,now as max_ts,avg(propertyValue) as hour_avg from dt group by deviceCode,propertyCode4.3 实时流计算
实时流处理是指对持续增长的动态数据进行实时的收集、清洗、统计和存储,并实时展示处理结果。在智能运维领域,流数据处理需求非常常见。例如,在工业物联网中,设备传感器会持续产生数据,智能运维系统需要实时监控这些数据。
DolphinDB 可以在实时数据流计算场景中高效地计算。用户可以通过简单的表达式实现复杂的流计算。DolphinDB 的流式数据处理引擎能够实现低延迟、高吞吐的流式数据分析,并提供了十种不同的引擎以满足不同的计算需求。此外,DolphinDB 数据库支持多种数据终端输出,如共享内存表、流数据表、消息中间件、数据库和 API 等。在计算复杂表达式时,用户还可以通过级联多个流数据引擎来实现复杂的数据流拓扑。
案例 10:每个整点的平均值相减
DolphinDB 内置的多种流数据处理引擎支持流数据的发布、订阅、预处理、实时内存计算、复杂指标的滚动窗口计算、实时关联以及异常数据检测。
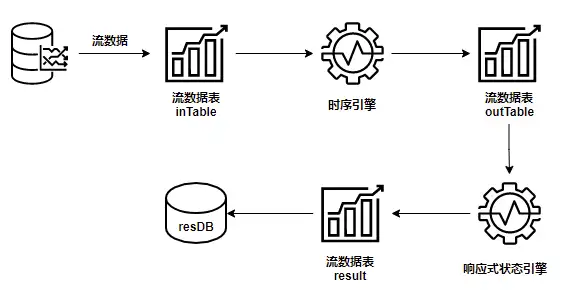
下例展示了如何通过 DolphinDB 实现每个整点平均值的相减,过程如下:
- 建立一个时序引擎以计算每个整点内数据平均值。
- 用响应式状态引擎计算平均值间的差值。
- 输出计算结果到 result 表。
//案例 10:每个整点的平均值相减,比如1~2点的值减去0~1点的值,如此循环。
//步骤说明:
//步骤一:用时序引擎,数据按整点规整。
//步骤二:用响应式状态引擎,进行差值计算。
//步骤三:输出到result表
//数据写入
share streamTable(1000:0, `ts`deviceCode`logicalPositionId`physicalPositionId`propertyCode`propertyValue,
[DATETIME,SYMBOL,SYMBOL,SYMBOL,SYMBOL,DOUBLE]) as inTable
//时序引擎的输出表
share streamTable(1000:0, `ts`deviceCode`propertyCode`propertyValue,
[DATETIME,SYMBOL,SYMBOL,DOUBLE]) as outTable
//时序引擎,实时计算均值指标(窗口1h,步长1h,每个设备的每个测点为一组进行分组计算)
hour = createTimeSeriesEngine(name="hour", windowSize=3600, step=3600, metrics=<[avg(propertyValue)]>, dummyTable=inTable, outputTable=outTable, timeColumn=`ts, keyColumn=[`deviceCode,`propertyCode])
subscribeTable(tableName="inTable", actionName="act_hour", offset=0, handler=append!{hour}, msgAsTable=true, batchSize=50, throttle=1, hash=0)
//状态响应引擎,每个相邻整点值相减
share streamTable(1000:0, `deviceCode`propertyCode`ts`sub_propertyValue,
[SYMBOL,SYMBOL,DATETIME,DOUBLE]) as result
sub_hour = createReactiveStateEngine(name="sub_hour", metrics = <[ts,deltas(propertyValue)]>, dummyTable=outTable, outputTable=result, keyColumn=[`deviceCode,`propertyCode])
subscribeTable(tableName="outTable", actionName="act_sub_hour", offset=0, handler=append!{sub_hour}, msgAsTable=true, batchSize=50, throttle=1, hash=0)
//将某个设备的数据写入,启动流式框架
pt = loadTable("dfs://db_test", "collect");
select count(*) from pt;
t = select * from pt where deviceCode = "361RP00" and propertyCode = "361RP00000"
inTable.append!(t);
//流数据引擎计算窗口内的平均值
select * from outTable where deviceCode = "361RP00" and propertyCode = "361RP00000";
//sql查询窗口内的平均值
select format(avg(propertyValue),"0.00") from t where deviceCode = "361RP00" and propertyCode = "361RP00000" group by datehour(ts)案例 11:根据状态突变,抽取记录(实时流计算)
下例展示了流数据响应式状态引擎如何检测设备的状态变化,并将测得的开停机记录推送给 Python 端的实现过程。
//案例 11:根据状态突变,抽取记录(实时流计算)
//新建流数据表,接收实时写入数据
share streamTable(20000:0,pt.schema().colDefs.name,pt.schema().colDefs.typeString) as mainStream
//新建流数据表,保存处理后结果数据
share streamTable(20000:0,`propertyCode`ts`deviceCode`logicalPositionId`physicalPositionId`propertyValue,[SYMBOL,DATETIME,SYMBOL,INT,INT,INT]) as calc_result
//使用流数据异常检测引擎,进行数据筛选处理
engine = createReactiveStateEngine("engine_status", <[ts,deviceCode,logicalPositionId,physicalPositionId,propertyValue]>, mainStream, calc_result,`propertyCode,<propertyValue!=prev(propertyValue)>)
//开启订阅
subscribeTable(tableName="mainStream", actionName="act_subscribe_calculate", offset=0, handler=append!{engine}, msgAsTable=true, batchSize=10000, throttle=1,hash=1);
//使用回放,模拟持续写入流数据表的场景
dt=select * from pt where deviceCode="361RP17" and propertyCode="361RP17002" and ts between 2022.01.01 00:00:00:2022.01.01 01:00:00 order by ts
update!(dt,`propertyValue,rand(0 1,dt.size()))
//批处理调用replay函数,后台执行回放
rate=5*60 //回放倍速(每秒播放5分钟的数据,每小时数据12秒执行完毕)
submitJob("replay_output", "replay_output_stream", replay, dt ,mainStream, `ts, `ts, rate,false)
//推送到应用端。《subScribe_result.py》,详情可查看python对流数据的订阅。
/*** python代码开始 ****
from threading import Event
import dolphindb as ddb
import pandas as pd
import numpy as np
s = ddb.session()
s.enableStreaming(8000)
def handler(lst):
print(lst)
s.subscribe("127.0.0.1", 8848, handler, "calc_result")
Event().wait()
*** python代码结束 ****/案例 12:实时检测异常值,以指标变化率为例
为了帮助用户检测异常情况,DolphinDB 提供了流数据异常检测引擎。该引擎可根据指定的异常指标,检测每条记录,将异常的结果输出。
下例以案例 5 中指标变化率为指标,实时检测指标变化率是否超过阈值,将案例 5 中的事后异常分析转为实时异常检测。
//新建流数据表,接收实时写入数据
share streamTable(20000:0,pt.schema().colDefs.name,pt.schema().colDefs.typeString) as mainStream
//新建流数据表,保存异常结果
share streamTable(1000:0, `ts`propertyCode`type`metric, [DATETIME, SYMBOL, INT, STRING]) as anomalyRes
// 创建异常检测引擎
detect_rate = createAnomalyDetectionEngine(name="detect_rate",metrics=<[abs(propertyValue \ prev(propertyValue)-1)>1]>,dummyTable=mainStream,
outputTable=abnormalRes,timeColumn=`ts,keyColumn=`propertyCode)
// 订阅实时数据
subscribeTable(tableName=`mainStream,actionName='detect_rate',offset=-1,handler=append!{detect_rate},msgAsTable=true)
//使用回放,模拟持续写入流数据表的场景
device="361RP017"
point="361RP017006"
rate=5*60 //回放倍速(每秒播放5分钟的数据,每小时数据12秒执行完毕)
begintime=2022.01.01 00:00:00 //数据开始时间
endtime =2022.01.01 02:00:00 //数据结束时间
dt=select * from pt where deviceCode=device and propertyCode=point and ts between begintime:endtime order by ts
submitJob("replay_output", "replay_output_stream", replay, dt ,mainStream, `ts, `ts, rate,false)
select * from abnormalRes 5. 可视化运维与告警
5.1 运维指标可视化
DolphinDB 开发了 Grafana 数据源插件 (dolphindb-datasource),让用户在 Grafana 面板 (dashboard) 上通过编写查询脚本、订阅流数据表的方式,与 DolphinDB 进行交互 (基于 WebSocket),实现 DolphinDB 时序数据的可视化。dolphindb-datasource 的安装使用请参考:Grafana 数据源连接器。
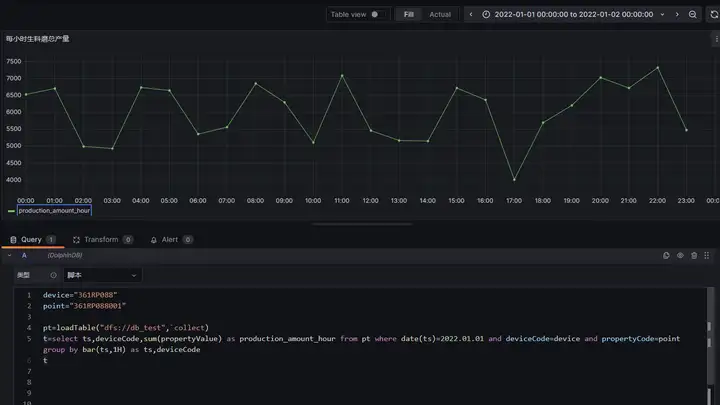
完成上述部署安装后,即可使用 Grafana 可视化运维指标,本节以案例 4 监控每小时的总产量为例。
如下图所示,将案例 4 中的计算脚本输入 Grafana 即可将查询结果以图表形式输出。
上述查询中,每个 panel 只能监控一个设备的总产量,如果需要监控所有设备的总产量,可将查询语句改为以下查询:
t = select sum(propertyValue) as production_amount_hour from pt where date(ts)=2022.01.01 group by bar(ts,1H) as ts,deviceCode
select production_amount_hour from t pivot by ts,deviceCodepivot by 是 DolphinDB 的独有功能,是对标准 SQL 语句的拓展。它将表中一列或多列的内容按照两个维度重新排列,亦可配合数据转换函数使用,其使用方法详见 pivot by。
5.2 异常告警
DolphinDB 开发了 httpClient 插件,可以便捷地进行HTTP请求或发送邮件,httpClient 插件的部署安装详见:HttpClient。
本节将以案例 12 为例,介绍在 DolphinDB 检测出异常数据之后,如何将异常数据进行输出告警。
//加载 httpClient 插件
try{loadPlugin('./plugins/httpClient/PluginHttpClient.txt')}catch(ex){}
//定义邮件发送的订阅函数
def sendEmail(userId,pwd,recipient,mutable msg){
ts = exec ts from msg
propertyCode = exec propertyCode from msg
sendMsg = string(ts)+" the propertyCode "+string(propertyCode)+" rate is greater than 1"
sendMsg = concat(sendMsg,"<br>")
httpClient::sendEmail(userId,pwd,recipient,"rate is greater than 1",sendMsg)
}
//订阅异常检测结果表发送告警
userId = 'xxxx' //发送者邮箱
pwd='xxx'//发送者邮箱密码
recipient='xxx'//接收邮箱
//订阅异常检测结果表
subscribeTable(tableName=`abnormalRes,actionName='sendEmail',offset=0,handler=sendEmail{userId,pwd,recipient},msgAsTable=true,batchSize=10000,throttle=10)上述脚本将订阅异常检测结果表,实时将异常结果以邮件形式发送给接受者,从而达到实时告警的目的。除了邮件告警的形式外,httpClient 还支持企业微信、钉钉等第三方平台,详见:利用 HttpClient 插件整合外部消息。
6. 附录
完整测试代码:Intelligent_O&M_demo.dos
我决定放弃开源 鸿蒙之父王成录:开源鸿蒙是我国基础软件领域唯一一次架构创新 工业软件大事件 —— OGG 1.0 发布,华为贡献全部源代码 Google Reader 被“代码屎山”杀死 Fedora Linux 40 正式发布 前微软开发人员:Windows 11 性能“糟糕得可笑” 马化腾周鸿祎握手“泯恩仇” 知名游戏公司出新规:员工娶妻彩礼不得超过 10 万元 Ubuntu 24.04 LTS 正式发布 拼多多因不正当竞争被判赔偿 500 万元