
在刚刚过去的2024春季发布会上,袋鼠云带来了数栈产品V6.2版本的全新发布。其中,EasyMR 作为数栈V6.2中的一项关键能力,代表了袋鼠云对大数据生态的深入理解和持续创新。
EasyMR(后文统称EMR)是袋鼠云基于 Hadoop、Hive、Spark、Flink、HBase 等开源组件,构建的弹性计算引擎,提供安全可靠、弹性伸缩、低成本的大数据存储与计算服务。其中自主研发的 EasyManager 企业级大数据运维管理平台支持 Hadoop 集群的一站式创建、管理、部署、运维与监控功能,提供高效搭建数据中台解决方案。
面对企业日益增长的数据处理和分析需求,EMR6.2版本,将为用户提供更为出色的大数据运维服务及计算性能优化。以下是针对 EMR6.2 版本四大功能优化的详细介绍,帮助用户全面了解这一创新产品。
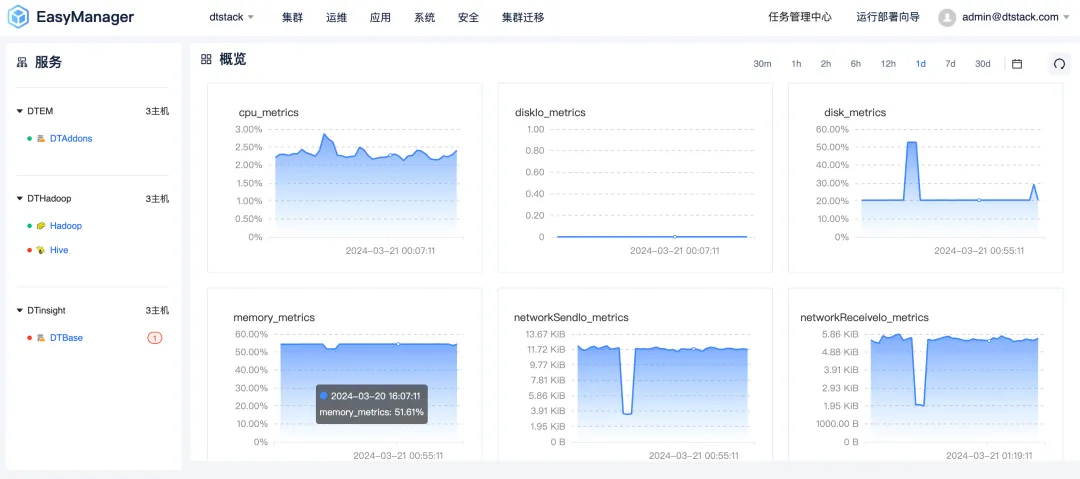
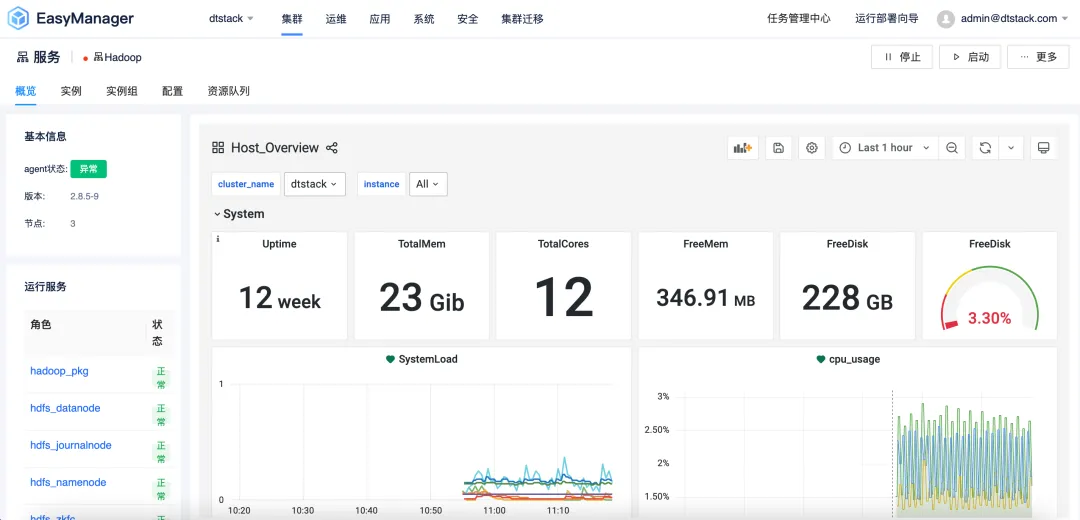
UI全面焕新升级:简约舒适的交互体验
袋鼠云深知用户体验的重要性,因此在 EMR6.2 版本中,我们对 UI 界面进行了全面的焕新升级。新的界面设计遵循了简约而不失优雅的风格,旨在为用户提供一个直观、舒适的交互体验。无论是新手还是资深用户,都能迅速上手,轻松管理复杂的大数据集群。
此外,我们还优化了界面的响应速度和操作流畅性,确保用户在集群运维时能够享受到更加顺滑的操作体验。
差异化配置:满足多样化需求
EMR6.2 版本引入了实例组-差异化配置功能,允许用户根据自己的具体需求定制集群配置。用户可以把 EMR 集群中的不同节点构建独立实例组,实例组中设置特定的配置参数,以实现更好的性能、资源利用和任务调度。
无论是对于成本敏感的初创企业,还是对于性能有更高要求的大型企业,EMR6.2 都能提供灵活的配置选项,满足不同用户的需求。
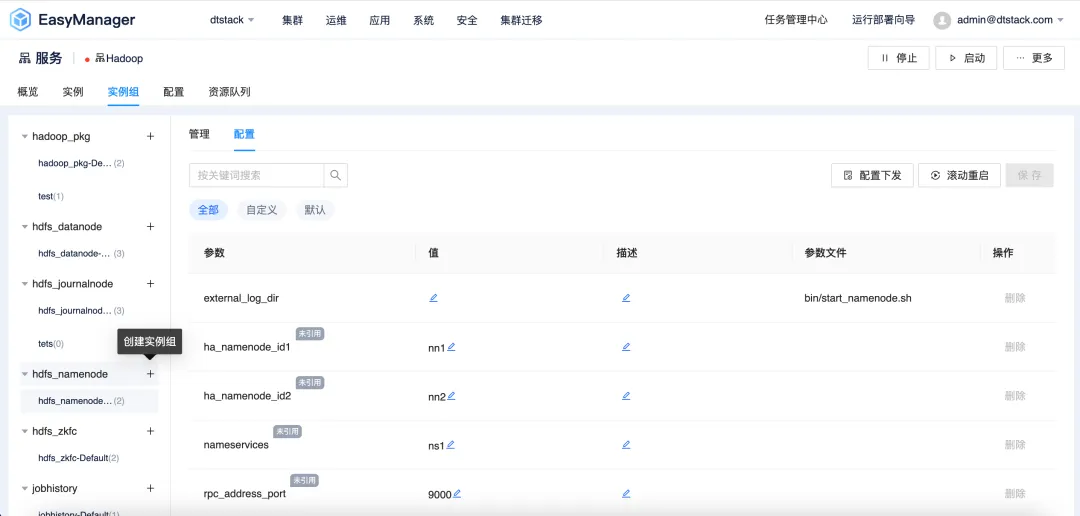
针对实例组实行差异化配置策略,其具体优势包括但不限于以下几点:
● 资源分配
差异化配置能有效针对各类任务的独特需求进行精细化资源配置,涵盖计算、存储和网络资源等多个层面。避免资源浪费,同时提高资源利用率,确保集群的各项任务都能得到合适的资源支持。
● 任务调度优化
针对不同类型的任务或作业,可以根据其特点设定不同的配置参数,以优化任务调度和执行效率。
● 容错与稳定性
通过差异化配置,可以提高集群的容错能力和稳定性。根据节点或实例组的重要性和负载情况,可以设置不同的容错机制和故障处理策略,确保集群在面对异常情况时能够保持稳定运行。
● 成本管理
差异化配置还可以帮助管理成本,根据业务需求和预算限制,对集群中的不同实例组进行合理配置,避免资源浪费,降低运维成本,并在性能和成本之间找到平衡点。
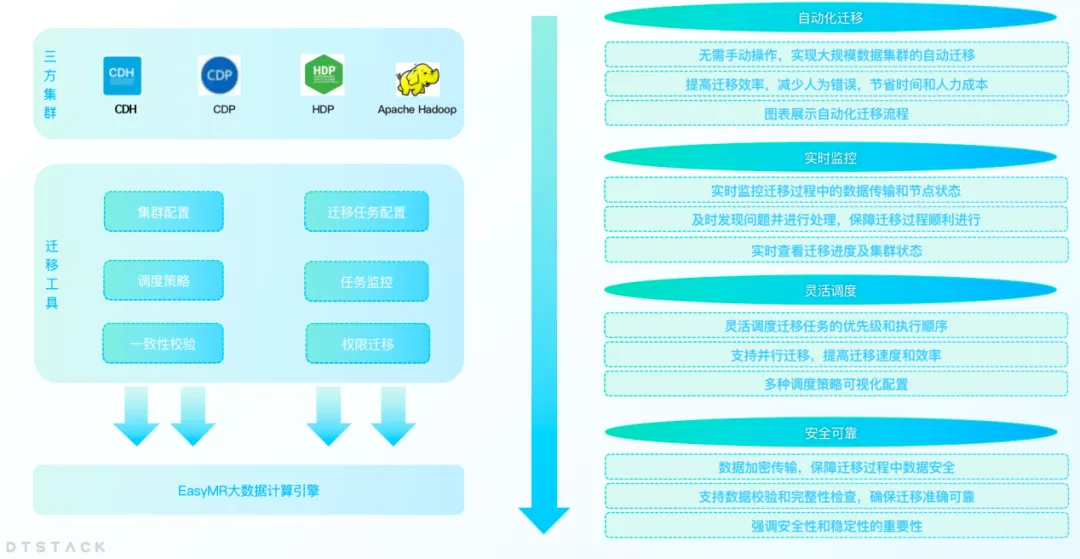
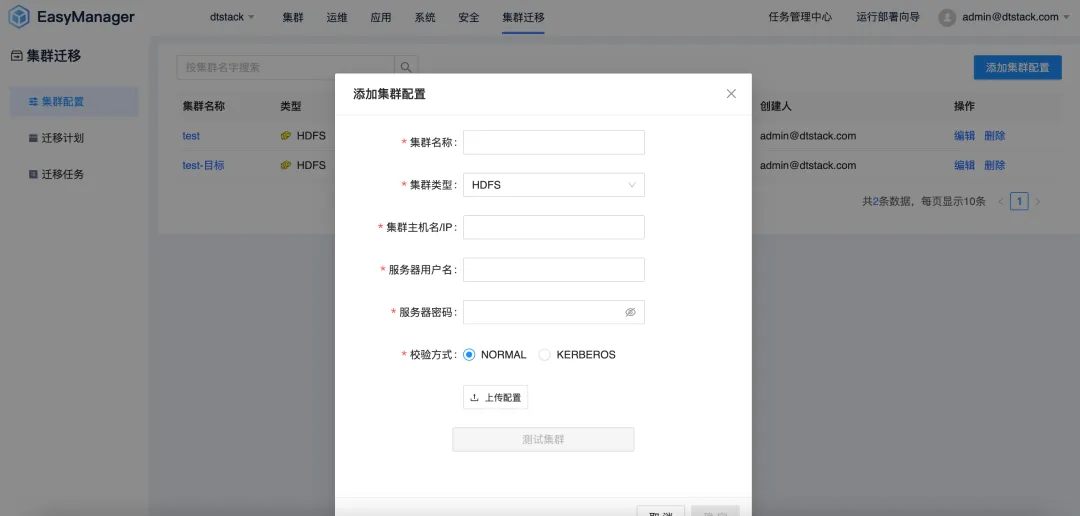
集群迁移:无缝过渡,业务不中断
随着企业的业务发展,不断增长的数据量往往会导致数据中心的容量不足或者数据中心变更等问题,企业需要将数据从一个数据中心迁移到另一个数据中心。同时在国产化平替背景下,越来越多的企业将 CDH、HDP、CDP 等非信创平台迁移到国产化大数据平台。因此 EMR 推出了大数据集群迁移功能,可以帮助企业高效地完成数据中心的迁移。
集群迁移功能支持用户在不同的数据中心或云服务之间无缝迁移他们的大数据集群,而无需担心数据丢失或业务中断。通过这一功能,企业可以更加灵活地调整其IT基础设施,以适应不断变化的市场需求。
引擎升级大揭秘:性能飞跃,全新体验
最令人激动的是,EMR6.2 版本在计算引擎性能上实现了重大突破。我们不仅对现有的 Spark、Flink 计算引擎进行了问题优化,还引入了新的算法和技术,以提高数据处理速度和计算效率。这意味着用户可以在更短的时间内完成更复杂的数据分析任务,从而加快决策过程,提升企业竞争力。
● Spark3 支持 Z-oreder 索引优化
Z-Order 是一种可以将多维数据压缩到一维的技术,对于一条数据来说,我们可以将其多个要排序的字段看作是数据的多个维度,Z-Order 可以通过一定的规则将多维数据映射到一维数据上。
具体表现为通过一定的规则构建 z-value 值,该 z-value 值可以理解为上文所提到的一维数据,此时我们就可以基于该一维数据进行排序。如下图所示:
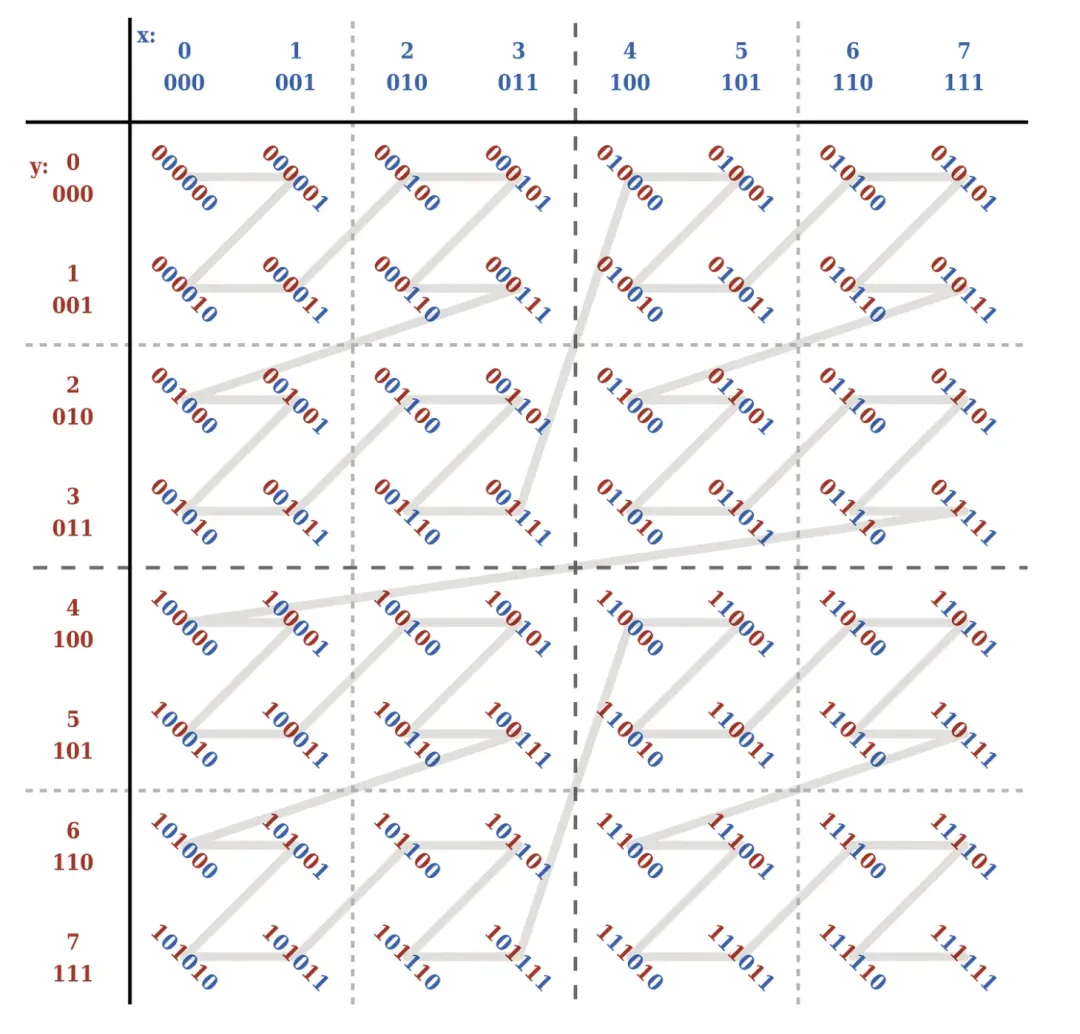
在 Spark SQL 中,袋鼠云新增 OPTIMIZE XX ZORDER BY 语法来支持 Z-Order 索引,实现了 INSERT INTO table 、INSERT OVERWRITE table、CREATE TABLE table AS SELECT、DISTINCT 等 SQL 的 Z-Order 索引优化。
Spark3 支持 Z-order 优化后极大提高了数据处理和查询的效率,减少 IO 开销,加速作业的执行速度。特别是在需要处理大规模数据集和复杂查询操作的场景下,Z-order 优化可以发挥重要作用。在解决文件压缩率的问题上,使用 Z-order 优化后,文件压缩率相比手动优化提升了近 20%,相比原始任务提升了近10倍, 对比开源 Spark3 的任务也有近 30% 的性能提升,极大提升了离线作业的性能和效率。
● Flink Per-job 任务热更新
实际的生产作业中,往往会出现实时任务参数变更或者算子、函数调优等情况,通常只能先取消当前任务,再选择 CheckPoint 恢复或者重新运行,整个过程大概需要3-5分钟等待,极大浪费任务开发时间。
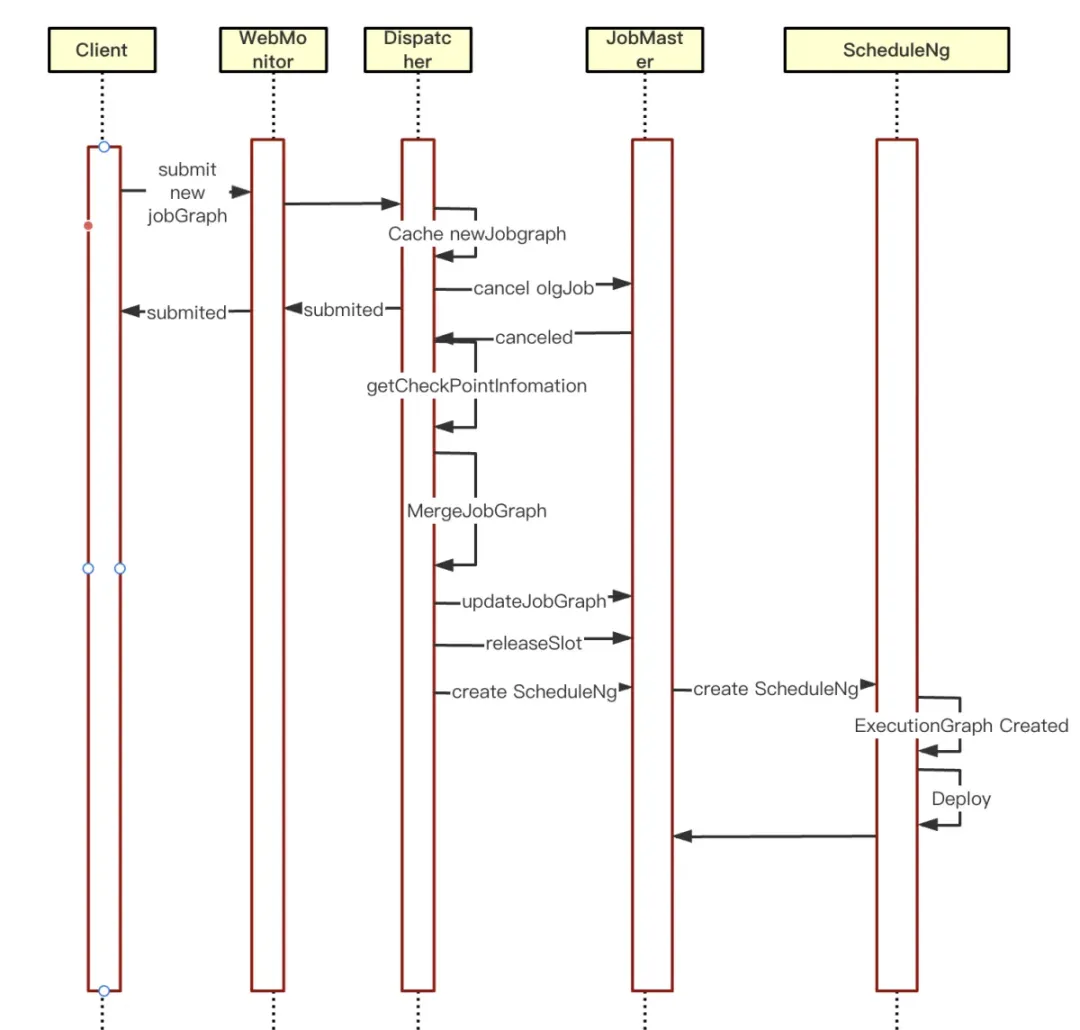
为了解决传统 Per-Job 模式下任务更新导致的服务中断问题,提高任务的稳定性和系统的可用性,满足生产环境中对业务连续性和高可用性的要求。袋鼠云引擎团队进行了相关探索及源码的改进,在 Per-Job 任务取消的异步回调里进行任务的热重启优化:
①首先判断当前是否存在新的 JobGraph 缓存,存在缓存时进入热重启逻辑
②获取取消任务的 CheckPoint 信息,填充到新的 JobGraph
③将 JobGrap 更新到 JobMaster,清理 JobGraph 的缓存信息
④清除 JobMaster 里 SloyPool 管理的资源
⑤JobMaster 重新创建 ScheduleNg 并调度运行,至此开启新的 JobGraph 调度运行
Flink Per-job 任务热更新优化之后显著提高了开发效率,减少停机时间并提升了应用程序的灵活性和可靠性。对于需要快速迭代和动态调整的实时应用程序,带来极致的效率体验。
· 提高开发效率: 开发人员可以快速测试和迭代代码,而无需经历繁琐的停止和重启过程,这加快了开发周期,并允许更频繁的发布
· 减少停机时间: 热更新可以最大限度地减少应用程序的停机时间,从而提高服务的可用性,对于关键任务和实时应用程序,尤为重要
· 动态调整参数: 可以动态调整作业配置参数,例如并行度或算子参数,而无需重启作业,允许根据实时数据流或负载情况进行灵活调整
● 其他功能开发
此外,在引擎侧我们还进行了 Spark Ranger 对接、Spark 物化视图优化、Flink Session 模式类加载隔离等功能开发,提升引擎计算性能的同时增强引擎的任务安全性和可扩展性。
总结
总结而言,EMR6.2 版本的发布,标志着袋鼠云在大数据服务领域的又一重要里程碑。通过UI全面焕新升级、差异化配置、集群迁移以及引擎升级等四大功能的优化,EMR6.2 为用户提供了一个更加强大、灵活和高效的大数据计算引擎平台,助力企业在数据管理和分析方面实现质的飞跃。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
Linus 亲自动手,阻止内核开发者用空格替换制表符 父亲是少数会写代码的领导人、次子是开源科技部主管、幼子是开源核心贡献者 李彦宏:自然语言将成为新的通用编程语言、开源模型会越来越落后 华为:用 1 年时间将 5000 个常用手机应用全面迁移至鸿蒙 Java 是最容易出现第三方漏洞的语言 富文本编辑器 Quill 2.0 重磅发布,特性、可靠性与开发者体验大幅提升 马化腾周鸿祎握手“泯恩仇” Meta Llama 3 正式发布 虽然老乡鸡开源的不是代码,但背后的原因却让人很暖心 谷歌宣布进行大规模重组