
分享嘉宾:
Lu Qiu, Shawn Sun
本文将讨论数据本地性对于在云上进行高效机器学习的重要性。首先对比现有解决方案的利弊,并综合考虑如何通过数据本地性来降低成本和实现性能最大化。其次会介绍新一代的Alluxio设计与实现,详细说明其在模型训练和部署中的价值。最后会分享从基准测试和实际案例研究中得出的结论。
一、为什么需要数据本地性
数据本地性指的是让计算任务靠近需要访问的数据,在云环境中优化数据本地性主要带来两大益处 —— 提升性能和降低成本。
1.1 提升性能
将数据存放在计算引擎附近时,数据访问速度要比从远端存储访问快的多。这对于数据密集型应用(如机器学习和AI任务)的影响尤为重大。数据本地性会减少数据传输时间,进而缩短完成任务所需的总时间。
具体的性能收益包括与远端存储相比,数据访问速度更快; 以及在诸如机器学习和AI等数据密集型应用上的耗时更少。通过就近存放并访问所需数据,减少了数据移动上的耗时,可将更多的时间用于高效计算。
1.2 节约成本
数据本地性除了能帮助更快地完成任务外,也降低了云环境成本。
让计算引擎靠近数据存储,可减少与外部云存储服务之间通过API调用(LIST、GET操作)来重复访问或移动数据,因此能节约高昂的API调用成本。通过减少对云存储的数据和元数据操作,云成本及流量成本也得以降低。数据本地性还可以提高GPU硬件的利用率,从而减少总的GPU租用时间。
总而言之,数据本地性可提高云任务的整体效率并降低操作成本。
二、现有解决方案和局限性
目前市场上有一些用于提升云上机器学习任务数据本地性的方案,每种方案都有其优点和局限性。
2.1 在运行时直接从远端存储读取数据
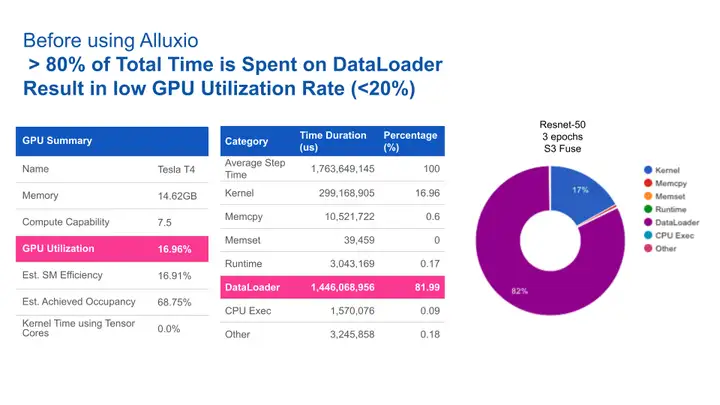
最简单的方案是根据需要直接从远端云存储读取数据。该方案无需本地性配置,易于实现。缺点就是每个训练周期(epoch)都需要从远端存储重新读取完整的数据集。对于模型训练而言,为提高模型准确性,通常需要进行多个epoch训练,因此数据读取所花费的时间可能比实际用于模型训练计算所花费的时间要长得多。
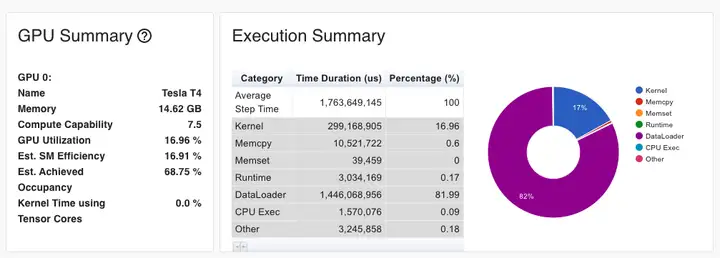
测试显示,80%的时间都花费在把数据从存储加载到训练集群上,请参见下图中的DataLoader占比。
2.2 训练前将数据从远端拷贝到本地
另一种方案是在训练开始之前手动将数据集从远端云存储拷贝到本地磁盘/存储中。这样可以让数据位于本地,从而具备数据本地性的所有性能和成本优势。该方案的挑战主要在于数据管理。用户必须在作业完成后手动删除已拷贝的数据,为下一个作业腾出有限的本地存储空间,因此会增加操作成本。
2.3 本地缓存层用于数据重用
某些存储系统(如S3)提供内置的缓存优化。此外,也有更高阶的开箱即用解决方案,如使用Alluxio FUSE SDK,作为本地缓存层来缓存远端的数据。缓存的数据可以在作业之间重复使用,确保重用数据的本地性。缓存层自动处理数据驱逐和生命周期管理,无需人工监督。但是,其存储容量仍然受限于本地磁盘,无法缓存巨大的数据集。
2.4 分布式缓存系统
分布式缓存系统可以跨多个节点,创建可存储大量热数据的共享缓存层,此外,它会自动处理数据管理任务,如数据分层和驱逐。
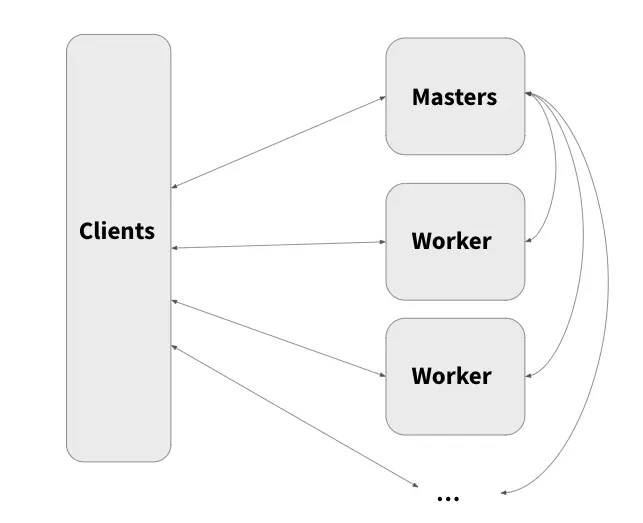
但是,传统的分布式缓存解决方案仍然在master节点可用性方面存在一些局限。海量小文件也会产生瓶颈。此外,可扩展性、可靠性以及满足不断增长的数据需求方面的挑战持续存在。
三、新设计:Alluxio DORA架构
为了克服现有分布式缓存解决方案在可扩展性、可靠性和性能方面的局限,我们提出了一种使用一致性哈希和软亲和调度的新设计—— Alluxio DORA(Decentralized Object Repository Architecture去中心化对象存储架构)。
3.1 用于缓存的一致性哈希
Alluxio DORA主要是利用一致性哈希来确定worker节点上的数据和元数据缓存位置, 让缓存数据操作和数据缓存查找分布到各个worker节点上进行,而不是集中在单个master节点上。
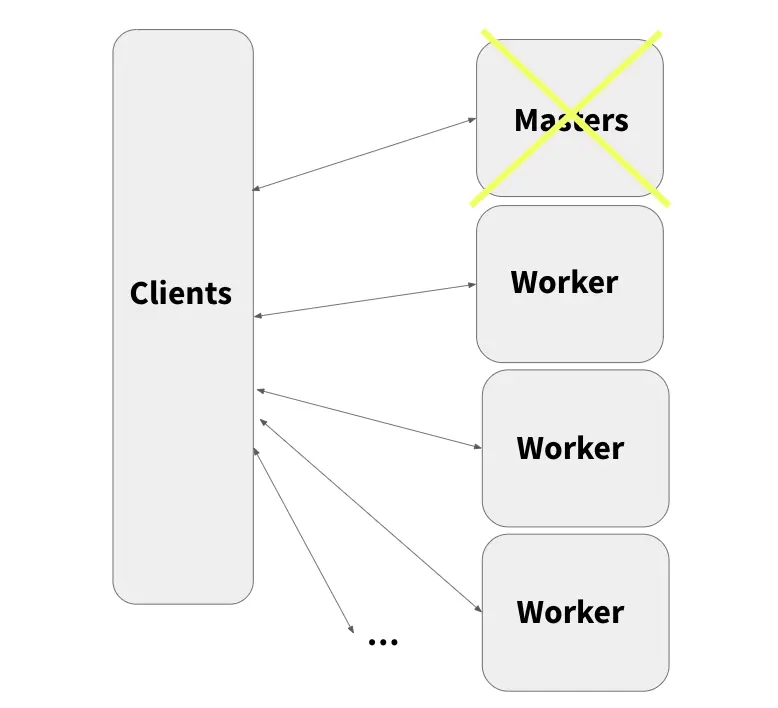
该方案的优势包括:
√ Worker节点有充足的可用于缓存的本地存储空间;
√ 不存在单点故障风险;
√ Master节点不会出现性能瓶颈;
√ 增减节点时自动再平衡和再分配。
3.2 软亲和缓存方案
在一致性哈希基础上采用软亲和缓存算法可进一步优化数据本地性。该算法的步骤如下:
√ 第1步:为每个数据对象配置所需缓存副本数;
√ 第2步:使用一致性哈希确定存放每个缓存副本的首选目标节点;
√ 第3步:根据首选节点重新运行一致性哈希,计算出次选的替代节点;
√ 第4步:重复以上步骤,为每个副本分配多个基于亲和的缓存位置。
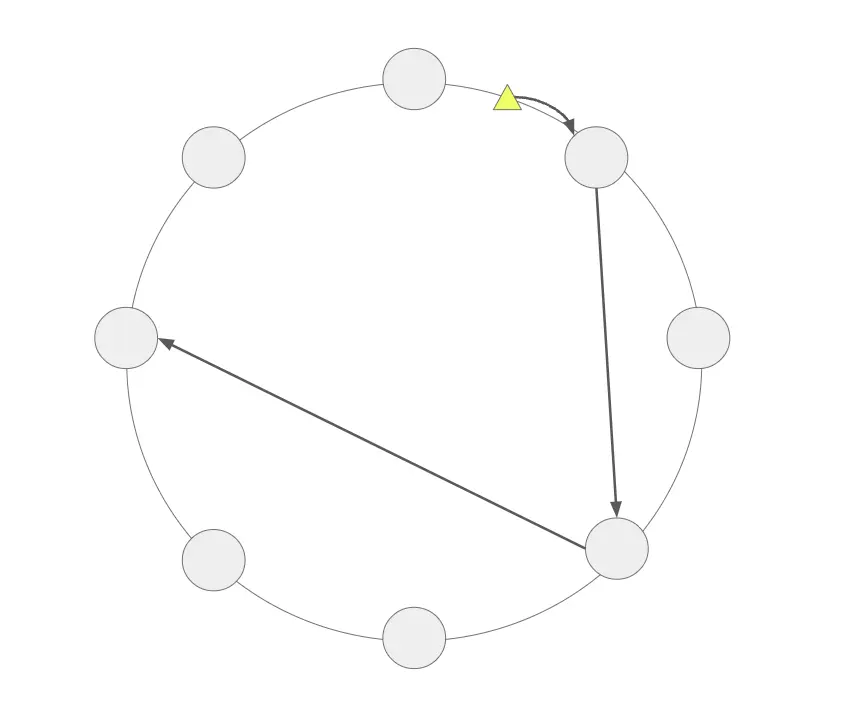
这样就为数据缓存目标创建了分级亲和性偏好。再加上去中心化的一致性哈希,软亲和缓存不仅优化了数据本地性能, 也能确保可扩展性和可靠性。
四、实现
这里提到的分布式缓存设计已经在Alluxio最新的企业版产品Alluxio AI中实现。
4.1 实现
Alluxio的新一代架构实现了将软亲和调度算法用于分布式数据缓存。实现的主要亮点包括:
实现了高可扩展性——单个Alluxio worker可处理3000万到5000万个缓存文件。另外,Alluxio新一代架构也包含高可用性设计,旨在实现99.99%的正常运行时间,不出现单点故障。此外,一个云原生的Kubernetes operator就能处理诸如部署、扩展和生命周期管理等任务。
4.2 针对训练的CSI和FUSE
新一代的Alluxio通过CSI和FUSE接口与Kubernetes集成,从而实现从训练Pod对缓存层的直接访问。
FUSE将远程缓存数据暴露为本地文件夹,极大地简化了挂载和使用。CSI集成仅在实际访问数据集时才按需启动工作Pod,因而提高了效率。
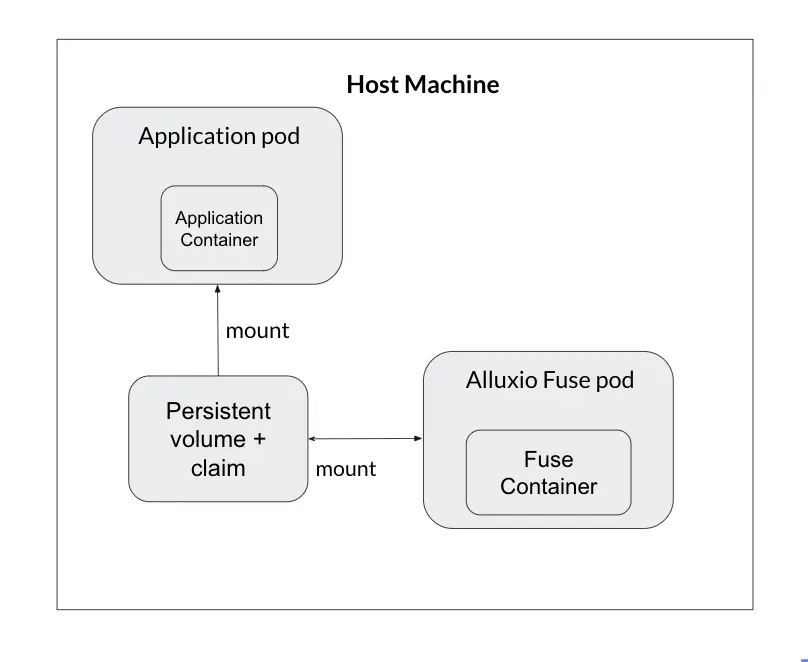
上述形成了三级缓存——内核(kernel)、磁盘SSD和Alluxio分布式缓存, 从而优化了数据本地性。
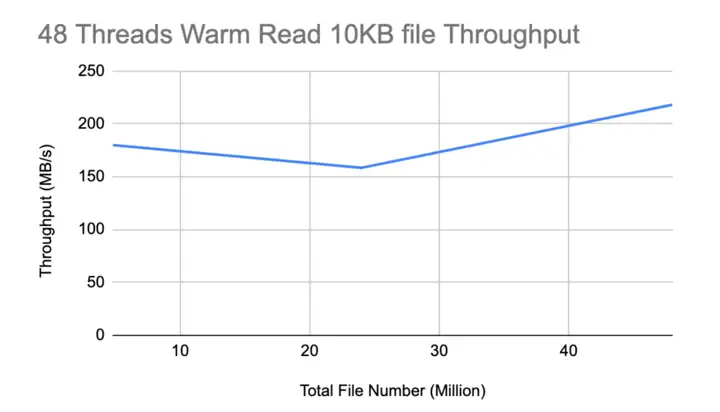
4.3 性能基准测试
在单个worker节点的性能基准测试中,使用了三个不同文件数量参数——480万个文件、2400万个文件和4800万个文件。worker节点能够在不出现任何显著性能下降的情况下读、写4800万个文件。
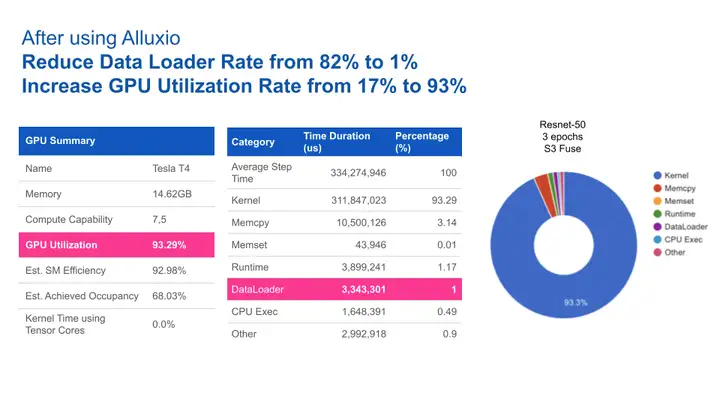
在数据加载性能测试中,使用imagenet的子集进行计算机视觉测试,并使用yelp学术数据集进行NLP(自然语言处理)测试。测试结果显示,就IOPS和吞吐量而言,Alluxio FUSE比S3FS-FUSE快2~4倍。
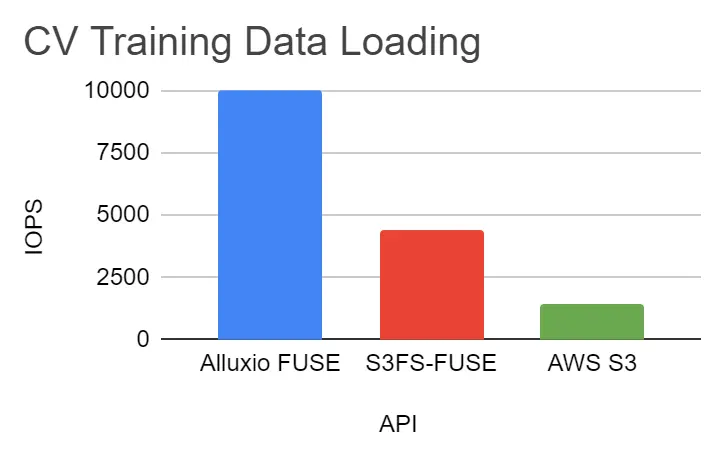
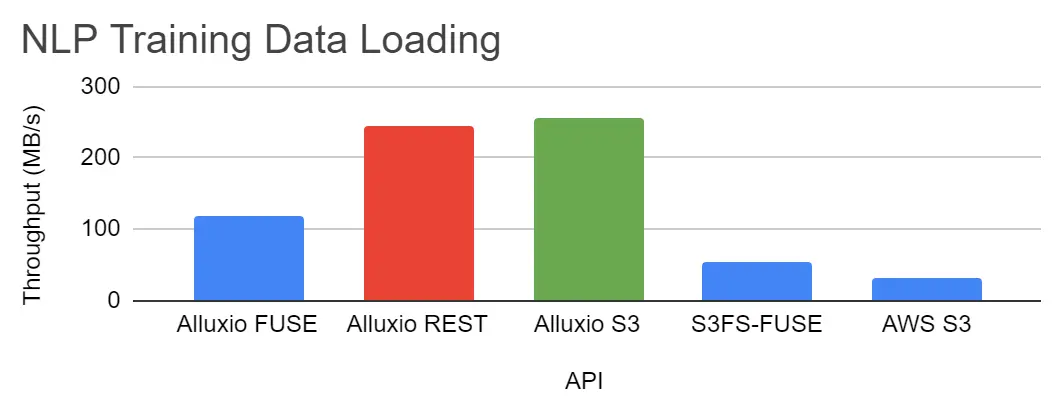
就计算机视觉训练而言,由于数据加载时间缩短,GPU利用率从17%提高到93%。
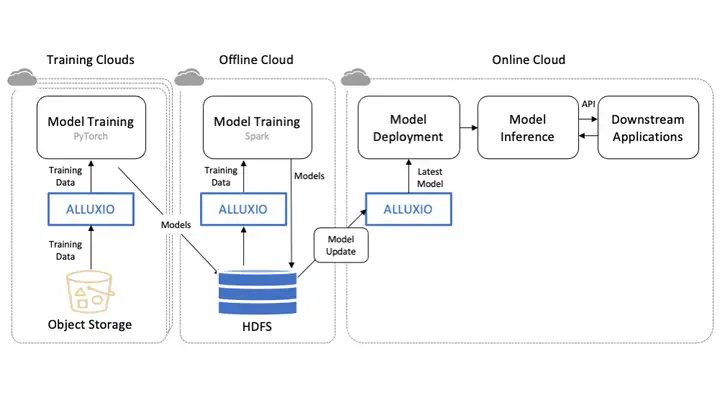
五、生产案例研究:知乎
作为一家头部的在线问答平台,知乎将Alluxio部署为LLM训练和服务的高性能数据访问层。Alluxio将模型训练速度提高2~3倍,GPU利用率提高2倍,并将模型部署时间从几小时或几天缩短到分钟数量级。
六、总结
本文要点总结如下:
√ 数据本地性对于优化云上机器学习任务的性能和成本至关重要。将数据存放在计算引擎附近不仅可降低数据访问延迟,也可节省云存储成本;
√ 包括直接访问远端数据、拷贝数据和使用本地缓存层在内的现有解决方案各有利弊,但都难以将提供的数据本地性提升到更大或者超大的规模;
√ 新的解决方案——Alluxio DORA,采用分布式缓存架构,利用去中心化的一致性哈希以及软亲和调度算法来优化数据存放,既能保持高可用性也能提高本地性;
√ 基准测试和真实的生产案例研究显示,Alluxio DORA能够为处理巨大数据集的AI任务提供近似本地处理的性能,并且将成本最小化。
Redis 不再“开源”,未来采用 SSPLv1 和 RSALv2 许可证 Java 22 GA 发布 马斯克开源 Grok Oracle 正式发布 Java 22 C++ 之父反驳白宫观点 Ubuntu 24.04 LTS 官方壁纸揭晓 微软推出 Sudo for Windows 并开源 金山办公推出鸿蒙星河版 WPS 苹果“有毒”——甲骨文警告新版 macOS 导致 Java 意外终止 Node.js 新版官网正式上线