一、数据库表设计
一对一
举个例子,比如这里有两张表,用户User表 和 身份信息Info表。

因为一个用户只能有一个身份信息,所以User表和Info表之间是一对一的关系。为了使这两张表关联起来,我们可以将User表作为父表,将Info表作为子表,在子表Info中增加一列关联父表的主键,称之为外键。
一对多
举个例子, 比如我们要设计一个电商系统,这里我们需要三张表:用户User、商品Product和订单Order。下面我们分析一下三张表之间的关系。
用户-商品:没有关系用户-订单:一对多商品-订单:多对多
一对多
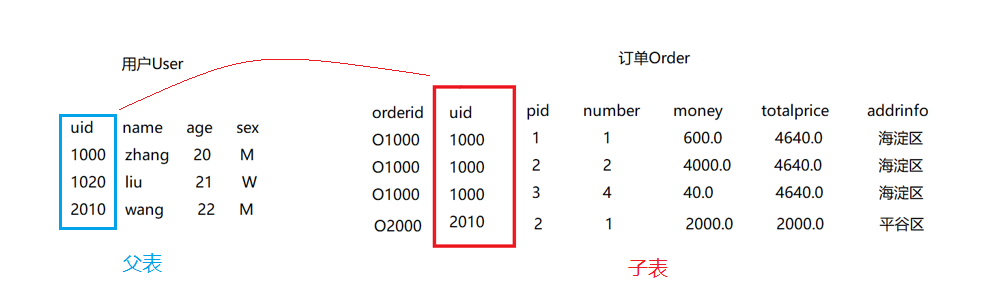
一对多的关系和一对一关系的处理方式类似, 都是在子表中增加一列关联主表的主键,他称之为外键。这里我们需要注意的是,子表的外键和父表的主键类型必须是相同的,尽量字段名也一样,方便找二者之间的关系。
多对多
基于上面的电商系统,我们再来通过例举 商品与订单之间的关系–多对多
如果我们像上面处理用户和订单之间的关系的方式类似,如果用户买了许多件商品,那么在订单表中就会存在大量的重复冗余的订单。
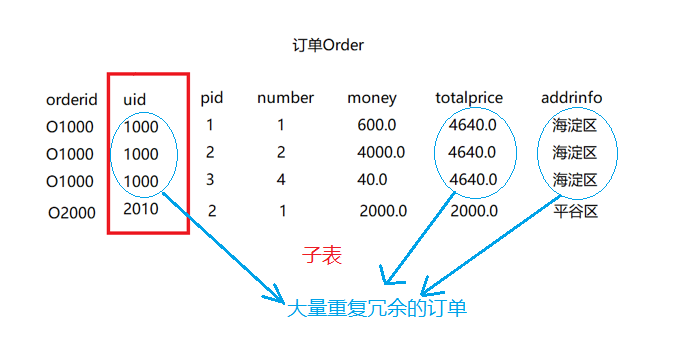
这会导致,当我们去修改一个订单时,比如增加一个商品或者减少一个商品时,我们就需要在订单表中进行大批量修改。关键所有订单修改的内容还是一样的。
因此我们在处理商品和订单之间的关系时,可以选者增加一个中间表来解决数据冗余存储的问题。
首先我们需要对订单表Order稍做修改,使得表中只保留不存在冗余的信息:
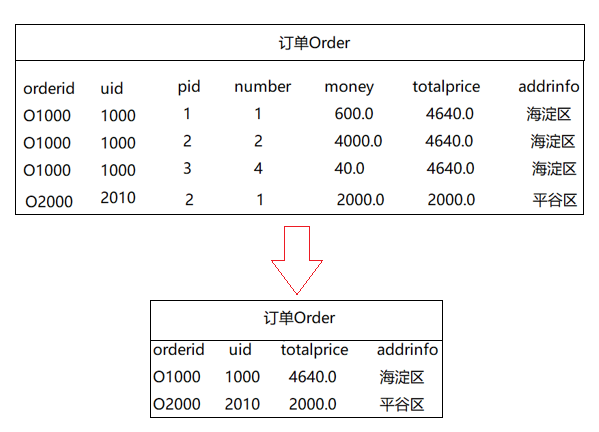
然后增加一个订单内容表OrderList,这样我们就可以通过在订单表Order中的订单号找到订单和商品之间的关系了。
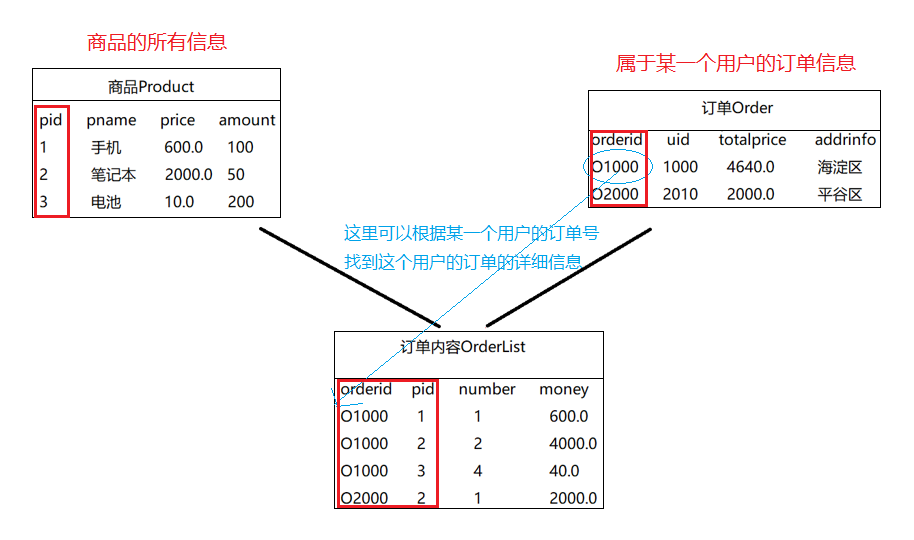
二、范式设计
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的 范式,各种范式呈递次规范,越高的范式数据库冗余越小。
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)消除异常(插入异常、更新异常、删除异常)让数据组织的更加和谐
第一范式
每一列保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。 例如表中的地址字段,可以再细分为省,市,区等不可再分割(即原子特性)的字段,如下:
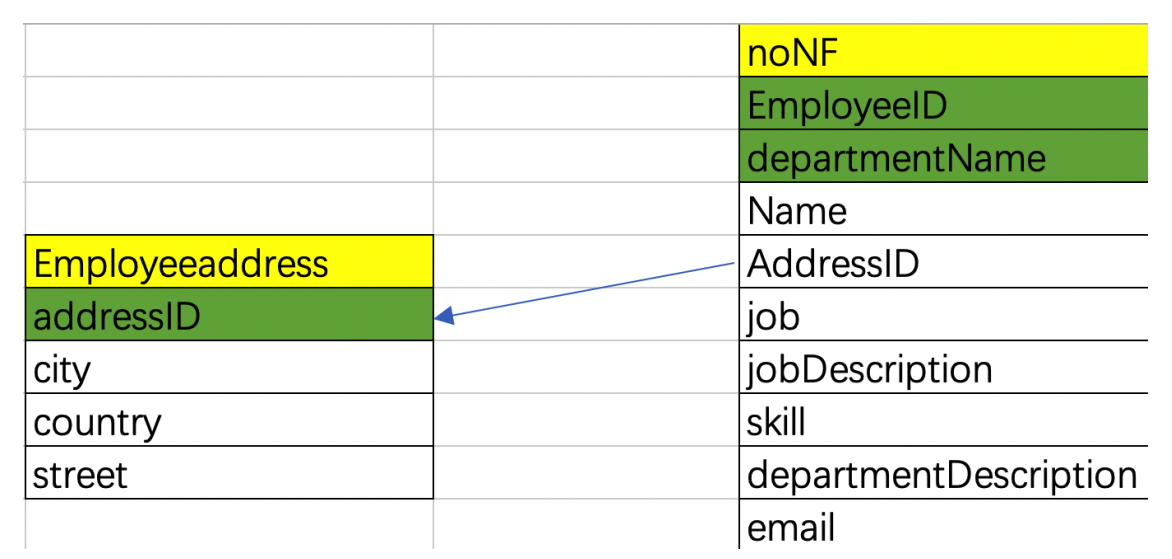
上图的表就是把地址字段分成更详细的city,country,street三个字段,注意,不符合第一范式不能称作关系型数据库。
第二范式
属性完全依赖于主键-主要针对联合主键
非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
例如:选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合第二范式。它们的依赖关系如下:

- 数据冗余: 如果一个学生选择了m门课程,那么学生的学号、姓名和年龄就重复了m-次,一门课程也可能会被n个学生选择,那么课程的课程名称和学分就重复了n-1次。
- 插入异常: 如果我们需要增加一门新的课程, 但这时还没确定选择这门课程的学生都有谁,那么就无法插入。
- 删除异常: 如果我们需要删除某个学生的学号,如果还没单独保存课程表的话,就会把该学生的选课信息也删除掉。
- 更新异常: 如果我们调整了某门课程的学分,那么该表中所有选择该课程同学的学分都需进行调整,否则就会出现不同的学生选择同一门课程但学分却不同的情况。
改进后:

第三范式
属性不依赖于其他非主属性
第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。该规则的意思是 所有非主键属性之间不能有依赖关系,必须相互独立。
示例:学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),学号是主键,但是学院电话只依赖于所在学院,并不依赖于主键学号,因此该设计不符合第三范式,应该把学院专门设计成一张表,学生表和学院表,两个是一对多的关系。
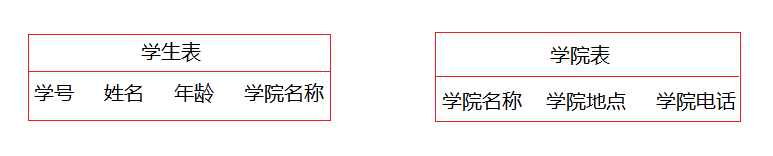
学生表通过学院名称字段与学院表进行关联。
BC范式
每个表中只有一个候选键
简单的说,BC范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键)。
举个例子:
仓库(仓库编号,货物编号,仓库管理员编号)
其中每一个仓库管理员只管理一个仓库。那么我们可以发现这里其实主码可以有两种,分别是:
- (仓库编号) 可唯一确定 (仓库管理员编号,货物编号)
- (仓库管理员编号) 可唯一确定 (仓库编号,货物编号)
必须要承认上述关系是符合第三范式的吧,但是有没有觉得这样仓库管理员编号会出现大量的没必要的冗余啊,因此BC范式就是解决这个问题的,需要将其改为两个表,顺便可以将货物的数量加进来。
至于为什么上面关系中我不将货物数量加进来,是因为一旦加进来后那个关系就不符合第二范式了,想想看,如果加入货物数量,那么主键就变成了(仓库编号,货物编号),可是仓库管理员只与仓库编号有关,不依赖于货物编号了呀,就不构成对主键的完全依赖关系了。
下面放上BC范式的修改版:
仓库与管理员表(仓库编号,仓库管理员编号)
仓库货物表(仓库编号,货物编号,货物数量)
第四范式
消除表中的多值依赖
简单来说,第四范式就是要消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。比如图4中的noNF表中的skill技能这个字段,有的人是“java,mysql”,有的人描述的是“Java,MySQL”,这样数据就不一致了,解决办法就是将多值属性放入一个新表。
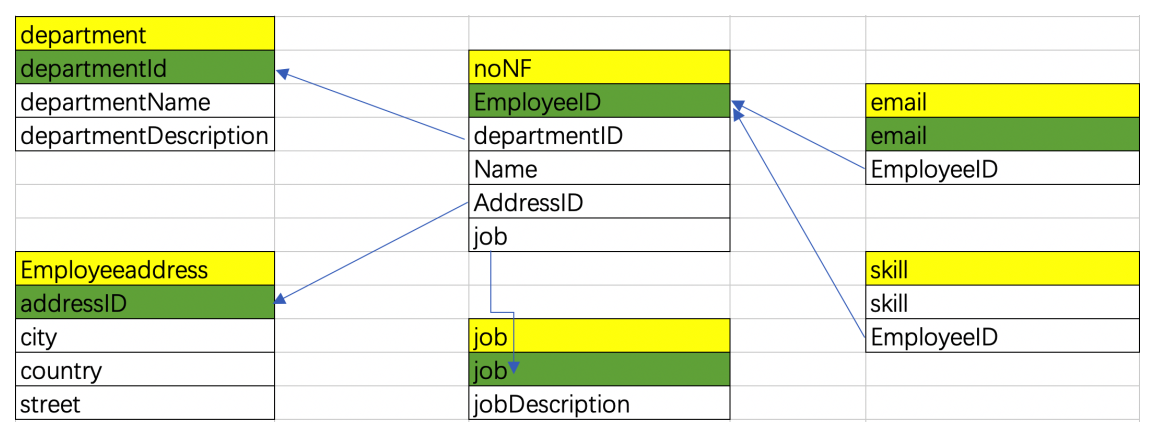
从上面对于数据库范式进行分解的过程中不难看出,应用的范式越高,表越多。表多会带来很多问题:
- 查询时需要连接多个表,增加了SQL查询的复杂度
- 查询时需要连接多个表,降低了数据库查询性能
因此,并不是应用的范式越高越好,视实际情况而定。第三范式 已经很大程度上减少了数据冗余,并且基本预防了数据插入异常,更新异常,和删除异常了。