1. MySQL触发器
1.1 触发器概念
触发器:指事先为某张表绑定一段代码,当表中的某些内容发生改变(增删改)的时候,系统会自动触发代码并执行。
触发器特性:
- (1)有begin、end体
- (2)触发条件:insert 、delete、update
- (3)触发时机:在增删改前或者后 (一个表最多支持六个触发器:增删改*前后)
- (4)触发频率:针对每一次执行。比较低级(也是缺点)
- (5)触发器定义在表上,附着在表上。不能定义在临时表、视图上
比较消耗资源,一般不使用
1.2 语法
delimiter $
create trigger trigger_name
[definer = {
user | current_user}] # 触发器定义者,可省略
trigger_time trigger_event
on table_name for each row
[trigger_order]
begin
trigger_body
end $
# 说明
trigger_name: {before | after}
trigger_event:{
insert | update | delete}
trigger_order:{follows | precedes} other_trigger_name # 在某个触发器触发 之后| 之前 触发 MySQL5.7版本以后才有的功能
注意:
- replace 也会触发insert ,先把原来数据删除,然后再重新插入
- 从外部加载数据也会触发insert
1.3 执行单行触发器
单行触发器,begin end可以省略
create trigger 触发器名称
before|after insert|update|delete
on 表名 for each row
执行语句;
案例:当新员工入职时,记录员工入职时间
第一步:创建员工表
create table work(
id int auto_increment primary key,
name varchar(64)
);
第二步:创建员工打卡时间表
create table insert_table(
insert_time time
);
第三步:创建触发器
create trigger insert_worker_time
after insert
on work for each row
insert into insert_table (insert_time) value(now());
第四步:增加员工,触发触发器执行
insert into work(name) value('boss');

1.4 执行多行触发器
delimiter $
create trigger 触发器名称
before|after insert|update|delete
on 表名 for each row
begin
执行语句;
end $
1.5 触发器使用
1.5.1 查看触发器
show triggers\G
select * from information_schema.TRIGGERS\G
1.5.2 删除触发器
触发器不使用时就把它删除了,以免出现事故
drop trigger 触发器名;
1.6 触发器中的new & old
- insert事件:new表示将要插入的数据,或者已经插入的数据;没有old
- update事件:old表示将要或者已经修改的数据,new表示将于或已经被插入的数据
- delete事件:old表示已经或者将要被删除的数据;,没有new
1.7 案例
案例:完成订单表与1商品表的关联操作
需求:
(1)订单在每插入一条数据,商品表在的库存就要减少对应的数量
(2)最小商品数为0
(3)订单内商品数量,不能超过商品库存总和
第一步:创建商品表
create table goods(
id int auto_increment primary key,
name varchar(64),
num int
);
第二步:创建订单表
create table orders(
id int auto_increment primary key,
goods_id int,
order_num int
);
第三步:创建触发器
需求1
delimiter $
create trigger create_order
after insert on orders for each row
begin
# 创建订单后,修改商品表库存容量
update goods set num = num - new.order_num where id = new.goods_id;
end $
需求2:保证库存最小值为0
create trigger check_goods before update
on goods for each row
begin
if old.num <= 0 then # 当前库存量小于0
set new.num = 0;
elseif old.num - new.num <= 0 then # 若更新库存后小于0
set new.num = 0;
end if;
end $
需求3:卖超问题
create trigger before_create_order before insert
on orders for each row
begin
select num from goods where id = new.goods_id into @count;
if @count < new.order_num then
insert into xxx(id) value ('xxx'); # 执行此句会报错,用来提醒库存不足
end if;
end $
第四步:插入测试数据
# 商品表
insert into goods(name,num) value('iphone',20);
insert into goods(name,num) value('xiaomi',30);
# 订单表
insert into orders(goods_id,order_num) value(1,8);
2. MySQL分区分表
2.1 概述
数据库的数据量达到了一定长度之后,为避免带来系统性能上的瓶颈。采用的手段时分区、分片、分库、分表。
- 分表:把一张表分成多个小表
- 分区:把一张表的数据分成多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上
2.2 分区
MySQL数据库中的数据是以文件的形式存放在磁盘上,一张表主要对应着三个文件(MyISAM):
- frm:存放表结构
- MYD:存放表数据
- MYI:存表索引
2.2.1 分区优点
- 可以存在多个磁盘上
- 根据查找条件,也就是根据where后面的条件,查找只查找相应的分区,不用全部查找
- 进行大数据搜索时可以进行并行处理
- 跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
2.2.2 分区方式
- 横向分区:取出一条数据的时候,这条数据包含了表结构中的所有字段,也就是说横向分区,并没有改变表结构。
- 比如:假如有100W条数据,分成十份,前10W条放到第一个分区,以此类推,也就是把表分成了十份
- 纵向分区:按列进行分区
- 比如,在设计用户表中,把个人所有的信息都放到了一张表中,这个表中可能有比较大的字段,如个人简介,这时候可以把个人简历分到另一个区,等需要的时候再去查看。
2.2.3 range分区
应用:日志,按时间增长的字段,根据
2.2.3.1 语法
create table 表名(
字段1 类型 约束,
字段2 类型 约束,
...
字段n 类型 约束,
)partition by range(字段)(
partition 分区名1 values less than (值1),
partition 分区名2 values less than (值2),
...
partition 分区名3 values less than (值n) [maxvalue],
);
2.2.3.2 查看分区
select * from information_schema.PARTITIONS where TABLE_NAME = '表名';
2.2.3.3 按分区查询
select 查询列表 from 表名 partition(分区名);
2.2.3.4 案例
案例:图书馆新进了一批书籍,把这些书籍按出版时间分区保存
创建书籍信息表,并按照相应规则分区
create table book_info(
id int,
title varchar(64),
create_time date
)partition by range (year(create_time))(
partition p2019 values less than (2020),
partition p2020 values less than (2021),
partition p2021 values less than maxvalue
);
查看分区信息
select * from information_schema.PARTITIONS where TABLE_NAME = 'book_info';
select TABLE_NAME,PARTITION_NAME from information_schema.PARTITIONS where TABLE_NAME = 'book_info';

插入书籍信息
insert into book_info (id,title,create_time) values(1,'C++','2019-09-01');
insert into book_info (id,title,create_time) values(2,'MySQL','2020-09-01');
insert into book_info (id,title,create_time) values(3,'Java','2021-09-01');
insert into book_info (id,title,create_time) values(4,'python','2020-08-21');
按分区查询
select * from bool_info partition(p2020);

2.2.4 list 分区
create table 表名(
字段1 类型 约束,
字段2 类型 约束,
...
字段n 类型 约束,
)partition by list(字段)(
partition 分区名1 in (...),
partition 分区名2 in (...),
...
partition 分区名n in (...),
);
- 其他操作同上range
2.2.5 hash 分区
可以按类型进行分区,比如超市里面的各种类型商品,员工表中的部门
create table 表名(
字段1 类型 约束,
字段2 类型 约束,
...
字段m 类型 约束,
)partition by hash(字段,另一个表的主键)
partition n; # n为要分为多少类(部门个数,商品种类)
2.2.6 key 分区
create table 表名(
字段1 类型 约束,
字段2 类型 约束,
...
字段m 类型 约束,
)partition by linear key(字段,自身主键)
partition n;
2.2.7 子分区
子分区:创建分区的分区
- 如果一个分区里面创建了子分区,那么其他分区里面也要有子分区,且个数一样
- 分区的子分区名字不能相同
2.2.8 分区管理
2.2.8.1 删除分区
alter table 表名 drop partition 分区名;
2.2.8.2 新增分区
alter table 表名 add partition (partition 分区名 values less than (值));
2.3 分表操作
- 利用merge存储引擎来实现分表
- merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中的
案例
把work1和work2合并一起
create table work1(
id int primary key auto_increment,
name varchar(32),
gender varchar(10)
) engine=MyISAM;
create table work2(
id int primary key auto_increment,
name varchar(32),
gender varchar(10)
) engine=MyISAM;
create table work(
id int primary key auto_increment,
name varchar(32),
gender varchar(10)
) engine=merge union=(work1,work2)
insert_method=last auto_increment=1;
插入数据
insert into work1 values(1,'jack','man');
insert into work2 values(1,'Bob','woman');
在work1和work2中分别插入一条数据后,查询work_sum中会出现总的数据

如果在work_sum中插入一条数据,会插入到work2中(insert_method=last)

2.4 分区分表对比
| 类型 | 分表 | 分区 |
|---|---|---|
| 数据处理逻辑 | 数据存放在分表中,总表是一个外壳,存取数据发生在一个个分表中 | 不存在分表概念,分区只不过把存储数据的文件分成了小块。分区后的表还是一张表,数据处理由自己完成 |
| 性能提高方面 | 分表重点是存储数据时,如何提高MySQL并发能力上 | 如何突破磁盘的读写能力,从而达到提高MySQL性能的目的 |
| 实现难易程度 | 用merge来分表比较简单,其他方式比较麻烦 | 实现简单,与建立平常的表没有什么区别 |
3. MySQL数据备份还原
3.1 数据备份(mysqldump)
3.1.1 备份某个数据库
语法:
mysqldump [-h 主机地址(127.0.0.1) -P 端口号(3306)] -u 用户名 -p 数据库名称 > 文件名.sql
# 回车后会提示你输入密码
举例
mysqldump -h 127.0.0.1 -P 3306 -u root -p girls > /home/dubx/Desktop/MySQL/db_girls.sql
3.1.2 mysqldump --add-drop-table
默认情况下,mysqldump的add-drop-table是开启的。
在创建这个数据库之前把所有的表删除
mysqldump --add-drop-table -u 用户名 -p 数据库名称 > 文件名.sql
# 回车后会提示你输入密码
3.1.3 压缩 gzip
语法:
mysqldump [-h 主机地址(127.0.0.1) -P 端口号(3306)] -u 用户名 -p 数据库名称 | gzip > 文件名.sql
3.1.4 备份所有数据库
mysqldump -u 用户名 -p 数据库名称 -A [或者--all-database] > 文件名.sql
3.1.4 备份部分数据库表
mysqldump -u 用户名 -p 数据库名称 表1 表2 ... > 文件名.sql
3.2 数据还原
3.2.1 可视化工具直接执行sql
3.2.2 通过mysqldump
# 导入sql
mysqldump -h 127.0.0.1 -u root -p < 文件名.sql
# 压缩文件
gunzip < 压缩文件.sql.gz | mysqldump -h 127.0.0.1 -u root -p
# 从另一个服务器导入
mysqldump -u root -p 数据库名称 | mysql -host=192.168.1.2 -C 数据库名称
3.2.3 source
source 文件.sql
3.2.4 通过bin-log还原数据
应用于MySQL集群。主从同步,读写分离
bin-log:记录MySQL变化的日志
查看bin-log存放路径
show variables like "%log_bin%";

log_bin_basename存放的是log_bin的存放路径
通过bin-log还原数据到某个服务器(命令行中)
mysqlbinlog binlog.000011(bin_log文件) | mysql -h IP地址 -u root -p
4. 数据库设计三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
4.1 第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示

上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
4.2 第二范式(确保表中的每列都和主键相关,而不能只与主键的某一部分相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
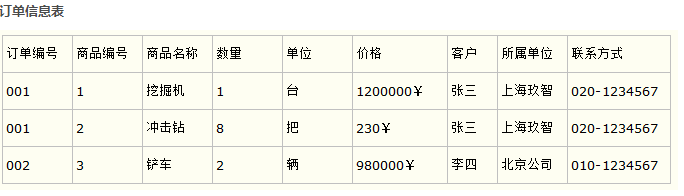
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。

这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
4.3 第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
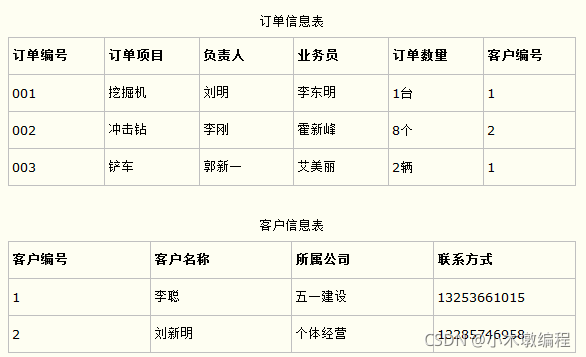
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余
参考
Ruthless: https://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html