
来源|ByConity 开源社区
各位的社区小伙伴们大家好,ByConity 0.3.0 版本于 12 月 18 日正式发布了,此版本提供了倒排索引,基于共享存储的选主方式等多项新特性,对冷读性能进行了进一步的优化,对 ELT 能力也进行了进一步的迭代,同时修复了若干已知问题,进一步提升了系统的性能和稳定性,欢迎大家下载体验。
GitHub 地址:https://github.com/ByConity/ByConity 下载体验:https://github.com/ByConity/ByConity/releases/tag/0.3.0
01 倒排索引
|背景
在 ByConity 使用过程中,很多业务对文本检索相关能力(如 StringLike)提出了非常高的需求,希望社区能够优化相关查询性能,同时兼容 ClickHouse 在今年支持的倒排索引的能力。为满足业务诉求,保持生态兼容,同时提升 ByConity 的文本检索能力,ByConity 在 0.3.0 版本加入了对文本检索的支持,为日志数据分析等场景提供高性能查询。
ByConity 对文本检索的规划分成两个阶段——
第一阶段,ByConity 在 ClickHouse 社区版本的基础上进行功能增强;
第二阶段,ByConity 计划支持更多的文本检索能力,包括词组查询 / 模糊查询等能力,让 ByConity 也成为一个文本分析工具。
目前在 12 月 18 日发布的 0.3.0 版本中,第一阶段目标已经完成,ByConity 在支持 ClickHouse 倒排索引能力的基础上,额外支持了中文分词,并进行了 IO 相关的优化。
|实现
倒排索引是从值到行号的映射,因此引擎可以根据倒排索引来快速地定位到符合条件的数据,避免大量数据的扫描开销,并且可以减少一些过滤条件的计算开销。
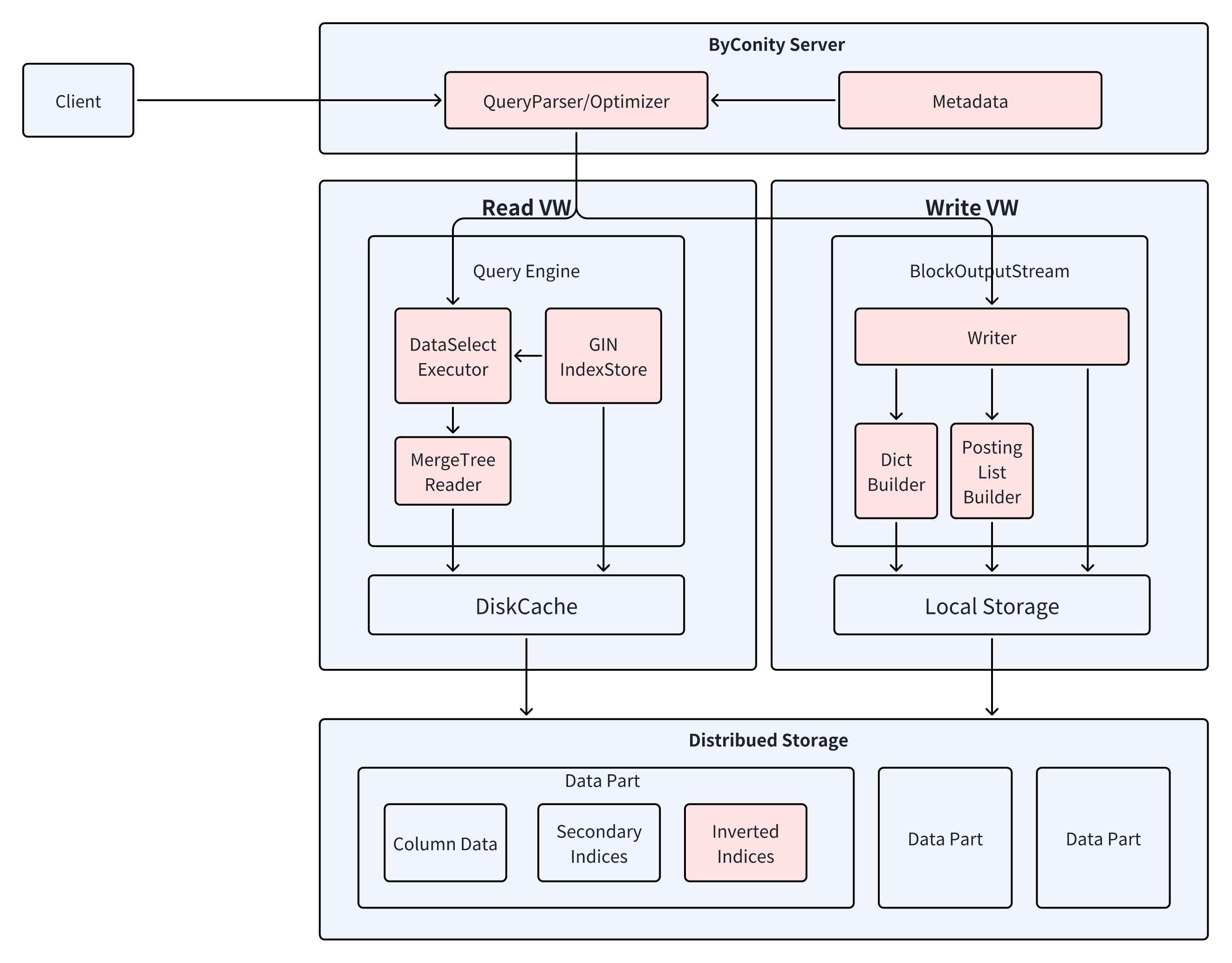
为 ByConity 增加倒排索引的支持主要包括写入 / 读取链路的修改——
写入链路的修改主要包括写入时根据列数据生成倒排索引,并写到远端存储;
读取链路的修改主要包括查询时依据过滤条件构建表达式来对查询的数据范围进行过滤。
增加倒排索引后,引擎的具体写入流程和读取流程如下图所示。
|使用方式
ByConity 支持使用 Token 分词,使用 Ngram 分词,以及使用中文分词。以下是使用中文分词的示例。
CREATE TABLE chinese_token_split
(
`key` UInt64,
`doc` String,
-- token_chinese_default 代表使用token_chinese_default分词器
-- default 代表使用default配置
INDEX inv_idx doc TYPE inverted('token_chinese_default', 'default',1.0) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY key
使用中文分词需要在配置文件中额外配置词典和模型。
|下一步规划
下一阶段主要目标是支持更多的文本检索能力,并进行性能上的优化。 从功能上而言会增加例如对词组查询、模糊匹配、文本相关性判断这些能力的支持,并为倒排索引添加对 JSON 类型的支持。
同时也会进行一些性能的优化,例如目前倒排索引只是用来做 Granule 的过滤,我们依旧需要将整个 Granule 读出来再进行过滤,但实际上我们可以从倒排索引中直接获取数据的行号,来直接读取对应的行;以及现在 Merge 过程中我们依旧是重新构建倒排索引,但是实际上我们完全可以复用之前的分词结果,来提升 Merge 的效率。
02 基于共享存储的选主方案
| 背景
在 ByConity 架构中存在多种控制节点,它们需要各自通过多副本 + 选主来提供高可用的服务能力,例如 Resource Manager,TSO 等。实际中的多个计算 server,也需要选出一个单节点来执行特定的读写任务。之前 ByConity 使用了 clickhouse-keeper 组件来进行选主,该组件基于 Raft 实现,提供兼容 zookeeper 的选主接口。但是在实际的使用中遇到了很多运维问题,例如需要部署 3 个以上节点才能提供容灾,增加运维负担;节点增删和服务发现流程复杂;容器重启后如果服务变换 ip 和服务端口,keeper 组件难以快速恢复,等等。
考虑 ByConity 作为一个新的云原生服务,并不需要兼容 ClickHouse 对 zookeeper 的访问,我们选择了基于存算分离的云原生架构实现一种新的选主方式来优化以上问题。
| 设计与实现
选主的竞争和结果的发布可以看成是一个多线程同步问题。受 Linux mutex 锁实现的启发,如果我们把 ByConity 多个试图选主的节点看成不同的线程,把支持事务提交、可见性顺序等于事务提交顺序的元数据 KV 存储看成支持 CAS 写入、保证可见性顺序的本地内存,用节点的定期 Get 轮询去模拟 Linux 内核的线程唤醒通知机制,我们就可以用 ByConity 所使用的高可用 KV 存储,通过模拟 CAS 操作去同步多节点之间对“谁是 leader”这个问题答案的竞争:谁 CAS 成功谁就是 leader。
解决了相互竞争的写者之间的同步,我们还需要把写者竞争的结果发布给读者。Linux 的锁的数据结构会记录谁是 mutex owner,这里也可以把 leader 的监听地址写入竞争的结果:CAS 的 key 写入内容 value 需要包括自己的监听地址。所以读者访问这个 key 就可以完成服务发现(读者不需要知道非 leader 的地址)。
leader 选举的实现包括制定选举基本规则,实现备选、竞选、胜选、就职、续任、主动离职,被动离职等流程,同时解决新旧 2 任 leader 的时间共识,对任期过期的判断等问题。
下图介绍了一个新 leader 的产生是如何在 follower 之间竞争产生分布式共识,并和旧任 leader 以及未来可能出现的新 leader 对这个共识的有效期的安全性产生共识,再让客户端感知到这个共识的全过程。

| 实际使用
如果使用 K8s 部署 ByConity 集群,只需要调整 replicas 属性就能简单地增减服务 Pod 副本。
如果采用物理部署 ByConity 集群并且手动配置,这套方案无需配置内部微服务之间以及副本之间的服务发现,增加的副本只要能启动即能被发现,并自动参与选主竞争,从而可以从 ByConity 集群中去除对 clickhouse-keeper 组件配置的依赖。
03 冷读性能的进一步提升
在 ByConity 0.2.0 中,我们通过引入 IOScheduler 等方式提高了冷读查询的性能,尤其是在 S3 上的冷读性能。0.3.0 版本通过引入 ReadBuffer 的 Preload 等优化,进一步提高了冷读性能。
主要有以下的优化策略:
| Prefetch
优化了执行侧 Mark Ranges 下推的调用栈,引入了 Prefetch,如下图所示:
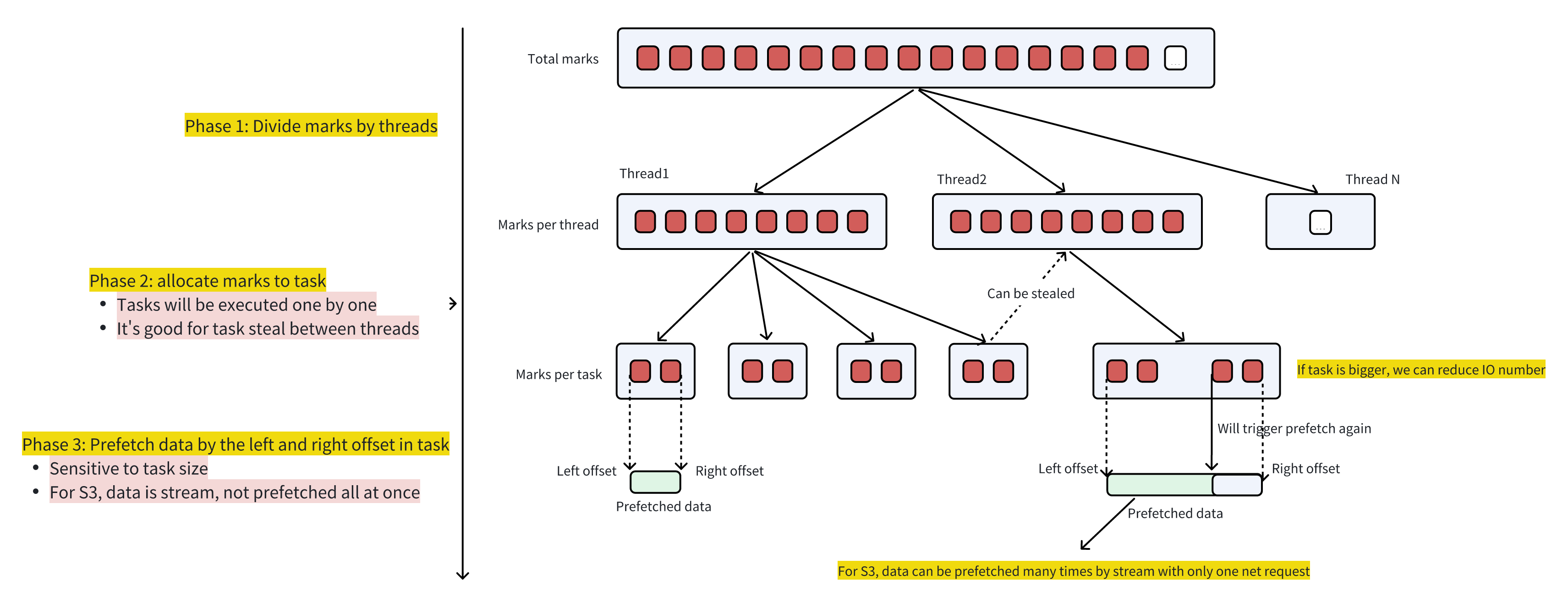
其中:
-
阶段 1:将所有需要查询的 mark 按 Thread 平均划分
-
阶段 2:每个 Thread 的所有 Mark 被进一步细分为多个 Task,方便 Threads 之间 Steal work
-
阶段 3:以单个 Task 为单位进行 Prefetch
-
Task 越大,则发送的网络请求次数越少,但是可能会对 work steal 有影响
-
不需要担心 Task 太大对 Prefetch 耗时的影响,因为 PocoHttpClient S3 返回的 Stream 是流式的,从发送请求到返回并不需要读取全部数据,在请求返回后可以再按需读取
| 自适应 mark per task
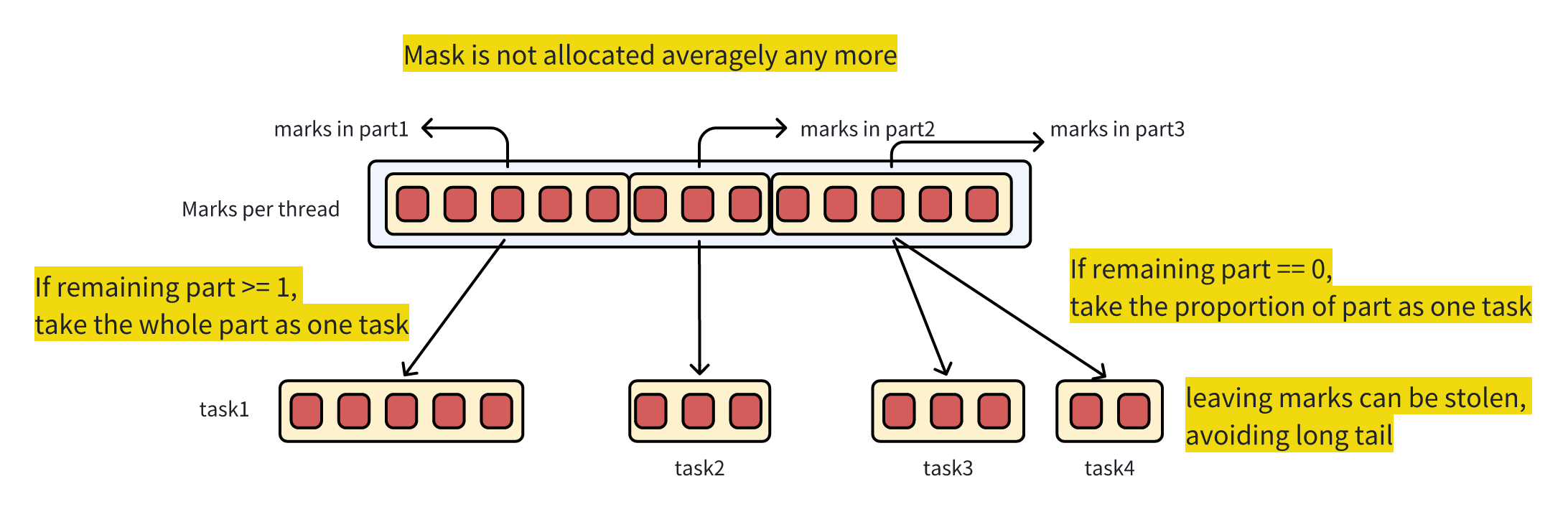
由于 Prefetch 的优化效果受单个 Task 包含的 Mark 数影响显著,尤其是大查询和小查询最优方案采取的 Mark 数可能不同,因此对 mark per task 采取自适应优化。
-
全局 mark pool 在 thread 之间的第一次分配,仍然采取平均分配的策略,保证每个 thread 初始任务大小相同;
-
在每个 thread 下的 task,不再采取平均分配的策略。
-
如果除了正在读取的 part,剩余 part 数 >= 1,则这次选择该 part 内的所有 mask 执行,剩余 part 可以满足 steal 的需要
-
如果剩余 part 数 = 0,则根据 part 的大小进行切分
此外,我们对第一次 Prefetch 同步等待时间较长的问题,即 long start,也有专门的优化,这里不再详述。
| 效果
Prefetch 以及相关的优化可以将 S3 冷读性能提升一倍以上,HDFS 冷读性能提升 20% 左右。
04 ELT 能力增强
在 ByConity 0.2.0 发布的时候我们介绍了 ByConity 在 ELT 方面的规划,以及在 0.2.0 中提供的能力异步执行,队列和 disk based shuffle。
在 0.3.0 中,我们引入新的 BSP 模式,通过 stage by stage 的执行以及增强 disk based shuffle,满足有限条件下的计算,提高吞吐。在 ByConity 中复杂查询对 query plan 的 stage 进行了切分并进行了 stage by stage 的调度,但在语义上仍然是 all at once 的调度。ELT 在执行时需要对查询进行分阶段运行,需要进一步达到 stage by stage 执行的效果。
| 设计与实现
执行计划(物理 / 逻辑)自下而上根据 shuffle 拆分成多个 stage,以 plan segment 或者 plan fragment 的形式具体体现,也称一个 phase。stage 中存在多个 task,每个 task 的计算逻辑相同,但执行的数据分片不同。前后依赖的 stage 的 task 之间有数据交换。
Stage 执行的实现包括调度器的分层重构,引入 StagedSegmentScheduler(DAGScheduler)负责 stage 的状态管理和调度,TaskScheduler 负责拆分 stage,形成 task set。并为每个 task 选择调度节点,发送给相应节点;同时我们需要把构建 io 的过程也放到异步执行中,引入 BSP 模式的调度过程,具体过程与我们在 0.2.0 实现的 insert query 中的异步执行的处理逻辑类似,但鉴于 select 和 insert 可能存在某些处理过程的不确定性,后续根据情况做相应方案调整。在后续版本中,我们会对异步处理模式和调度器的实现做进一步的增强。
更多 0.3.0 相关特性及优化的内容可查看:https://github.com/ByConity/ByConity/releases/tag/0.3.0
Rust 编写的 Zed 编辑器正式开源 原魅族副总嘲讽华为花上万亿建设鸿蒙生态 Oracle 的 2024 年 Java 工作规划 逆天神机 —— 17 寸的 64 核 AMD EPYC 工作站 ioGame17 文档或将强制收费,netty java 游戏服务器 网易云音乐第三方开源 API 因侵权被要求删除 ChatGPT 官方中文页面上线 FreeBSD 也要“锈化”?团队称考虑在基础系统采用 Rust AI 工具正在导致代码质量的下降 贾扬清最新开源项目 —— 500 行代码构建的 AI 搜索工具