本文整理自政采云的高级运维开发工程师云影(张帆),在 DeepFlow 可观测性 Meetup·杭州站 中的分享实录,从政采云可观测平台的背景与规划、建设面临的问题与挑战,到 DeepFlow 在政采云的实践,以及总结与展望。云影同学详细的介绍了政采云可观测性建设过程中的痛点、挑战与解决方案,以及建设的成果和未来的计划。
PPT下载:
http://yunshan-guangzhou.oss-cn-beijing.aliyuncs.com/yunshan-ticket/pdf/7698944121a1ce331c35428be49c2975_20230921103323.pdf
今天分享的主题就是聊聊我们政采云在去构建可观测平台时碰到的一些问题和我们的一些实践方案。

主要围绕的几个主题,第一个是我们可观测平台的背景,为什么我们要去做可观测平台,以及我们是怎么规划的。另外一个就是我们在去构建可观测平台的时候,我们面临的一些问题和挑战,我们是怎么解决的?以及我们为什么要去引入 DeepFlow,那 DeepFlow 和政采云又是怎么去结合的?
01、政采云可观测平台背景与规划
首先第一个就是我们构建平台的一个背景。

我们之前是为了去观测业务的运行状态,或者说帮助我们去做故障排查的时候,其实是引入了三个工具的,比如 Prometheus 帮助我们去告诉我们有没有出现问题, Pinpoint 是做链路追踪的,他就是去告诉我们问题在哪。日志的 ELK SLS 是我们直接去定位问题是什么,但是有一个问题是什么呢?这三个工具对于我们去观测业务状态,或者说故障排查的话越来越吃力了。那为什么说越来越吃力了?这个其实基本上也是我们传统监控方案去往可观测去转的时候,基本上都会面临的一些问题。
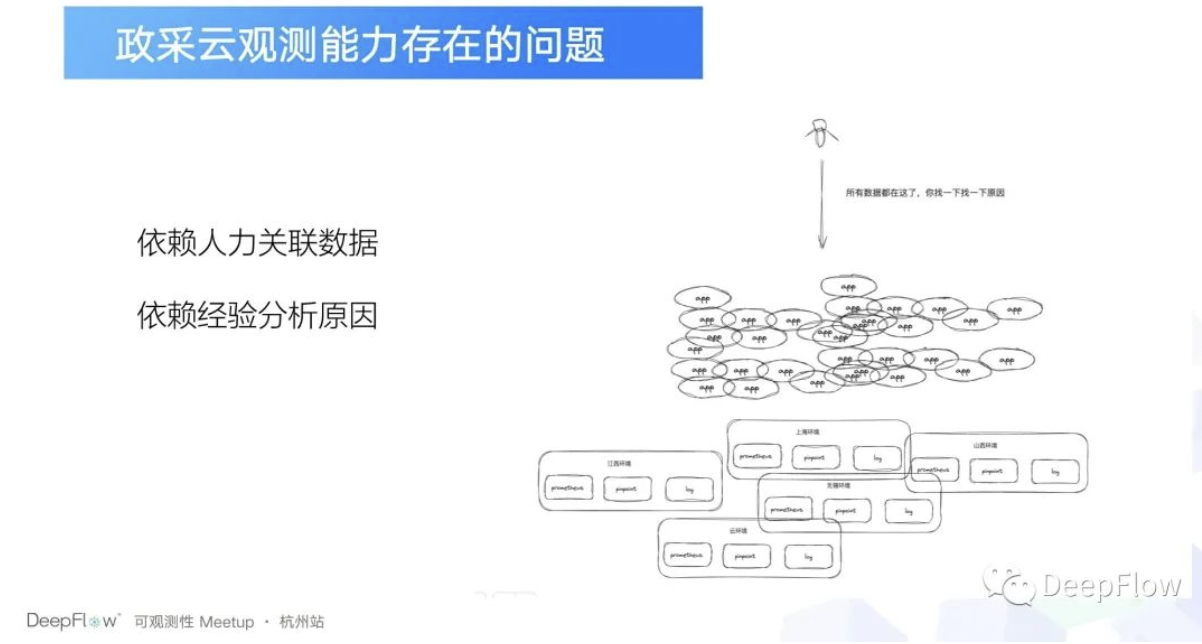
比如说我们非常依赖人力去关联数据,因为我们这些工具引入的时候其实是垂直引入的。怎么理解垂直引入呢?也就是说我用什么工具,我就看什么数据,这些数据之间没有关联,那怎么去做关联?这个时候就依赖人去把数据给关联起来了。那比如说我们如果说出现了故障的话,我们能够给到使用者的东西,就是我所有的环境所能提供各个维度的数据都在这里了,你去查一下。
这个对人的负担其实挺大的,因为我这么多数据我要从何去查起?另外一个就是依赖经验去分析原因,这个怎么理解呢?就是我们目前能够给到用户的能力,都是我们之前故障处理的沉淀的经验。事实上我们针对于这些数据没有任何的处理,只是数据的堆彻,所以这个时候我们越来越觉得我们传统的观测方式或者说监控方式已经不足以帮助我们去更好地观察业务的运行状态了,这也是基本上各家公司去往可观测性去转的话,都会都想解决的一个痛点。
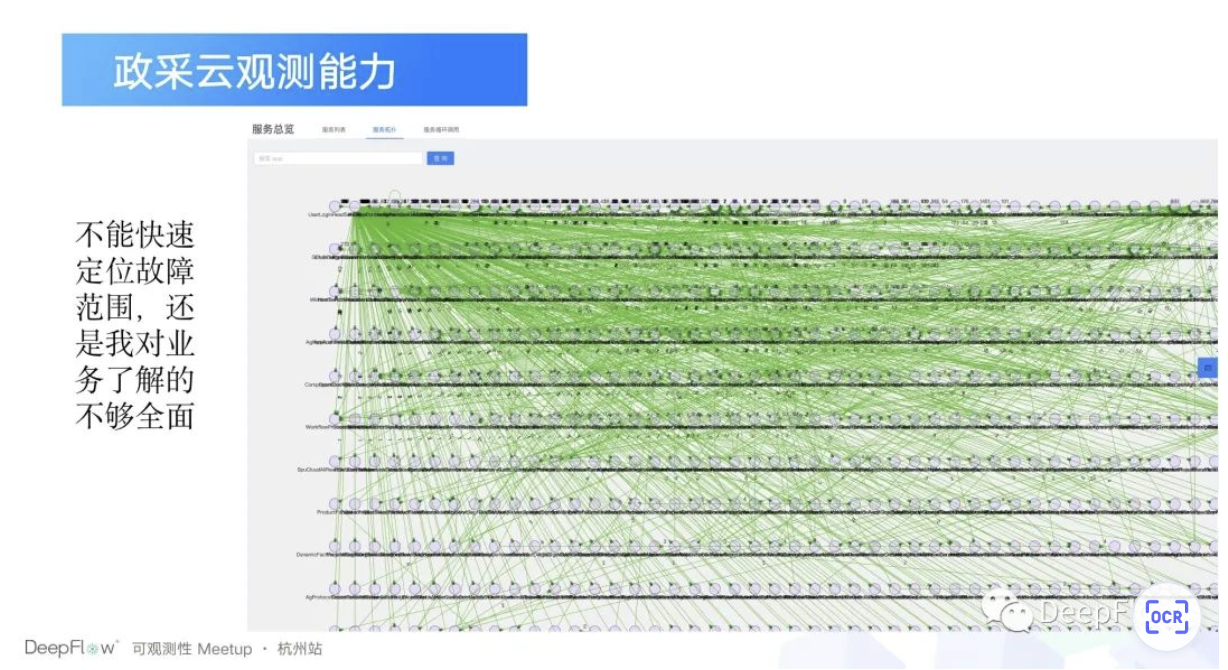
那另外一个问题是什么呢?还是人的问题,我们的业务越来越复杂,比如说某一个链路的话,它可能涉及到应用特别的多。当我们有一个业务故障的时候,谁能够告诉我这个业务故障影响的范围?在我们场景下观测到的一个现象,比如说我们出了一个故障,我们一般会拉一个群,然后看到的这个现象就是这个群的人数会越来越多,直到这个故障解决。
本质上的原因是什么呢?就是我们为了去降低我们个故障的排查时间,就只能去靠人海战术了。这样的话我们付出的成本其实就是比较大的。所以我们在这个背景下,我们在想我们之前的观测方式是不是有问题了?或者说基本上是没有办法产生更大的价值了?
建设符合 OpenTelemetry 标准的可观测平台
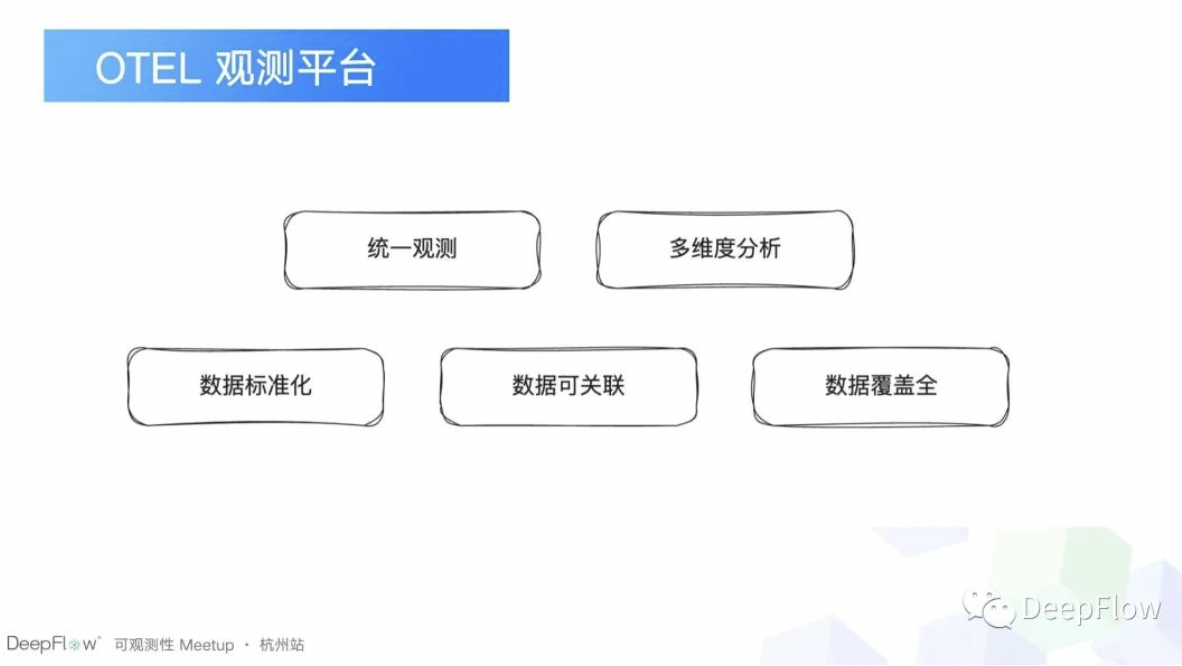
在这个背景下我们想着是时候拿出一套完整的解决方案了。主要的短期目标就是这五点。首先我们要去构建一个标准化的数据,另外一个就是关联可以关联的数据,还有一点就是我们的数据的覆盖面一定要全,在这个基础之上我们去做统一观测和多维度分析。
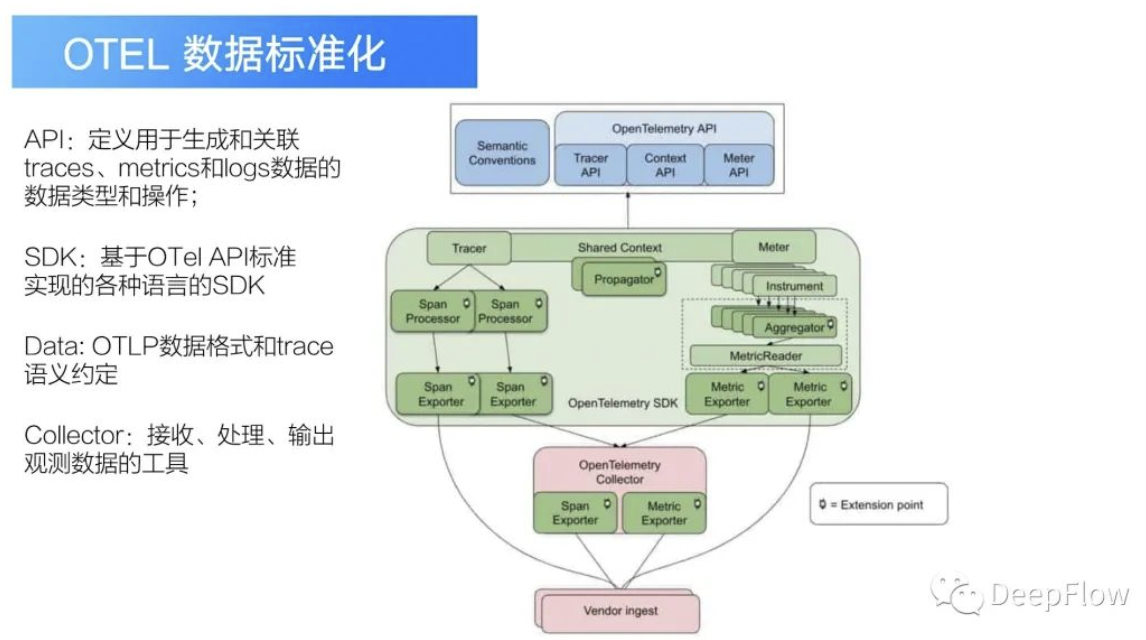
首先就是标准化,目前可观测性存在的标准其实挺多的,比如说有的用 Skywalking、 Zipkin 之类的。在我们去调研的时候,我们应该去选怎样的标准呢?我们选择了 OpenTelemetry,为什么选择这个标准(OpenTelemetry)呢?主要原因是我们去调研的时候发现在可观测性生态里面,大家都支持将 OTEL 的数据导入进来,或者说导出或者说处理,那这样的话我们就能够享受可观测性生态的便捷,就比如说我们已经享受到了 DeepFlow 给我们带来的便捷。另外一点就是 OTEL 在我们的场景里面它可以支持多个语言的SDK,同时而且是同一套 OTEL 的 API 标准,所以我们选择了OpenTelemetry。
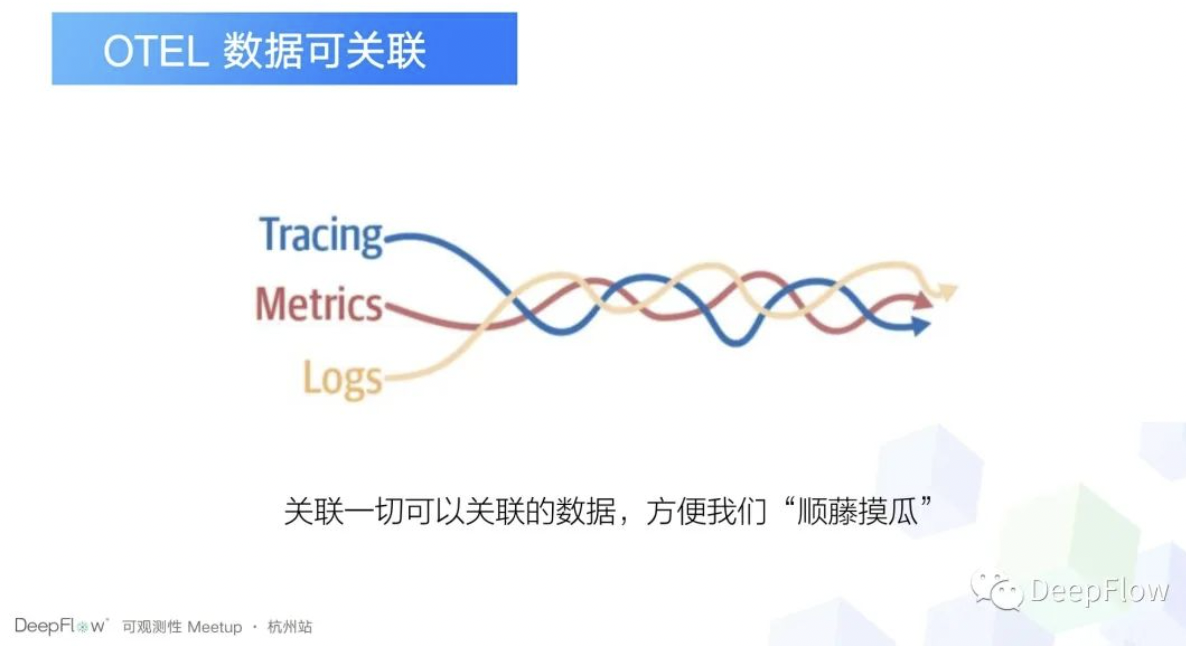
另外一个就是数据可关联,这个可能有一点奇怪的是什么呢?我们如果说我们遵守可观测性的标准的话,数据其实已经关联上了,那为什么还要强调一下数据可关联呢?因为其实我们在去排查故障的时候,如果说纯靠 Trace Metrics Log 的话,其实还不一定能够找到问题,我们可以关联一些更多的数据,比如说我们可以关联我们 Paas 平台的数据,当前这个链路关联的应用近期有没有做过发布?
因为 80% 的故障基本上都是业务变更导致的嘛,然后还有一点就是我们可以去关联一下指标相关的数据,因为我们如果纯粹通过 TraceID 去找指标数据的话,其实是不太全的。比如说某一个链路慢的话,我们可能要关注某个节点、某个环境、某个应用的线程池的负载情况。总之一点就是我们关联一切可以关联的数据,然后目的的话就是方便我们顺藤摸瓜找根因。

然后还有一个就是数据覆盖全,其实刚一开始我是没想过覆盖全这个问题的,是接触到 DeepFlow 以后,我们才发现我们的观测好像有盲区,然后这个时候我又打开了 OTEL 的官网,我发现它喊出的口号是高质量无处不在的便携式遥测技术。我这里提的一个关键字就是无处不在。为什么要强调一下无处不在呢?因为事实上如果说你的观测没有覆盖全的话,用 DeepFlow 的话讲就是你的观测存在盲区,所以我们尽可能的就是想我们对于观测的对象做到全面的覆盖,也就是全栈追踪。

这里引用一个经典的老图,大家如果参加可观测性的会的话,基本上都可以看到这个图。这里想提的一点是什么呢?就是我们首先关注的是业务,然后关注业务,关注承载业务的应用,但是想要让这个应用正常稳定的运行的话,其实它有一些底层的一些依赖,比如说它依赖的上下游,以及上下游之间的网络通信、数据库中间件等等之类的。这些也都是我们可观测性需要覆盖的维度。
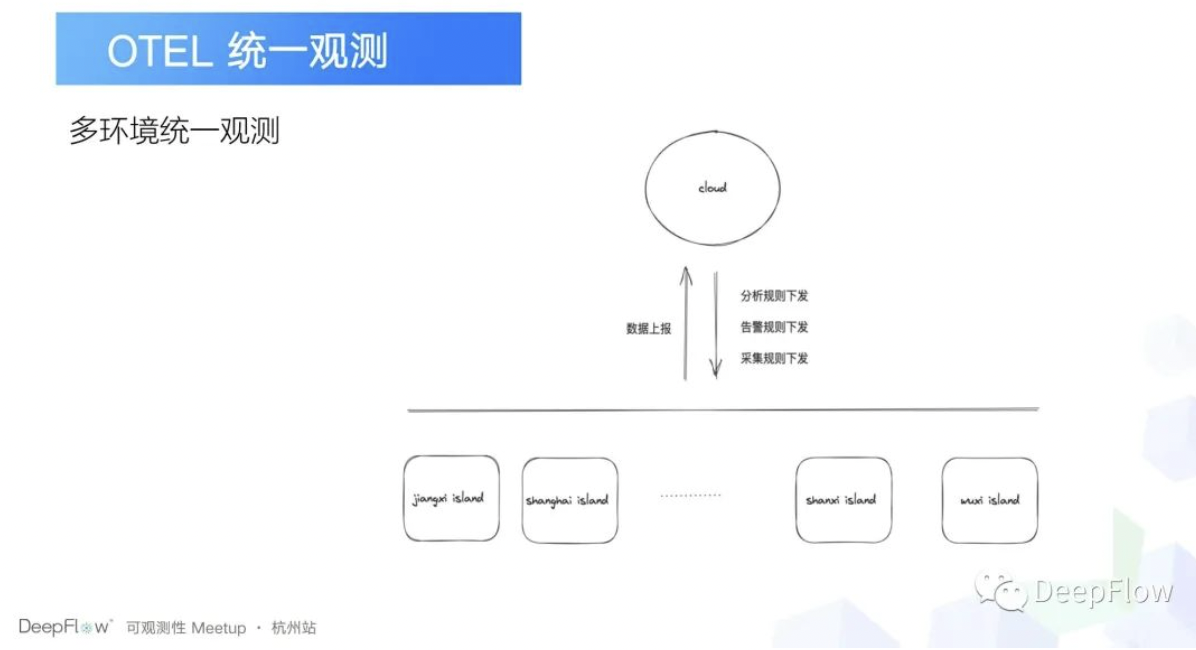
另外一个其实是针对我们公司的一个场景专门去弄的,因为在我们的场景里面其实是有很多个环境,我们有一个云端的环境,以及我们在各个省份,比如说有江西环境、上海环境、山西环境等等之类的。我们之前碰到的一个问题是什么呢?就是我们想要去找数据,还需要先确定它在哪个环境,以及每个环境可能因为人的原因,它配置的采集规则不一样,告警规则不一样,分析规则也不一样。所以我们在构建可观测性平台的时候,第一个就是我们要做一个统一的入口,所有的观测行为、观测操作、观测分析都可以通过一个入口来去解决。

另外想要达到统一观测的目的是什么呢?就是我们想要通过一种方式去观测多个维度的数据,像比如说我们去查指标的时候,一般是通过PromQL,那如果说去查日志的话,就是通过 LogQL,或者说就直接搜关键字,那在这种情况下,如果交给研发的话,其实是还有一点学习成本,那我们希望能够通过一种统一的查询方式,比如说 SQL 为什么说选择 SQL?因为其实在数据分析的场景的话, SQL 是一个很通用的语言。另外一点的话,我们通过 SQL 来去查询数据的话,还可以去实现一个实时的统计和分析的能力,也就说实现一个 ETL 的功能,那具体怎么做的呢?
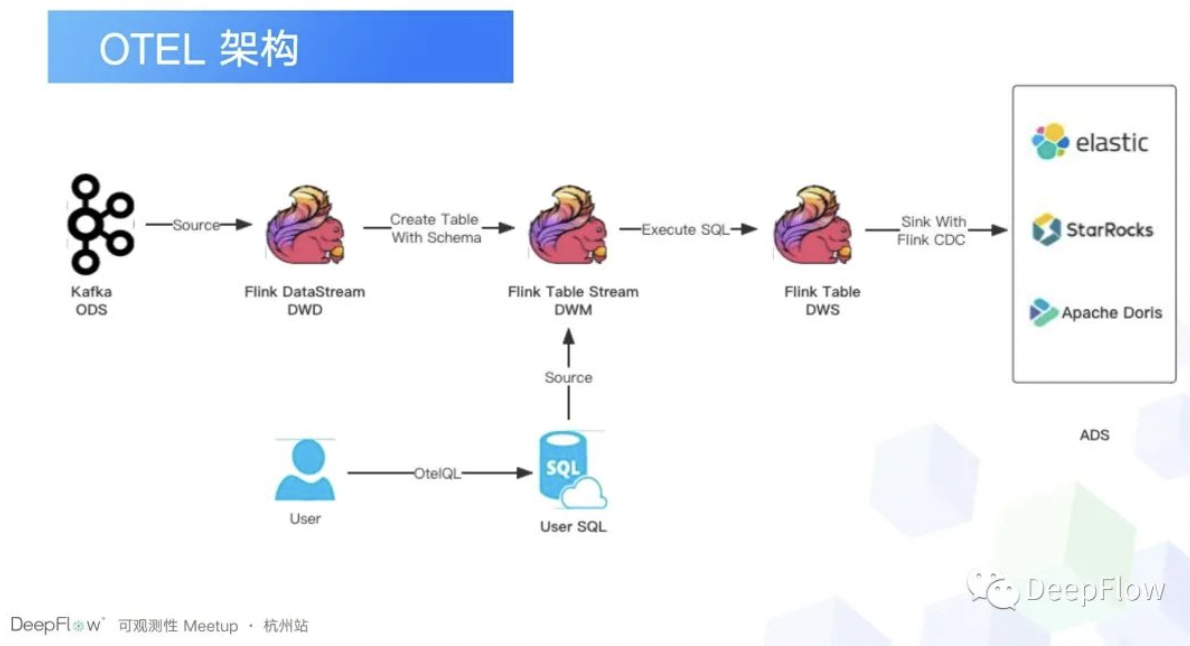
其实这个主要是依赖 Flink 的功能,那通过 Flink 将我们从 Kafka 拿到的观测数据把它转成一个表格,那这样的话我们之前预定义好的一些 SQL,在这个过程当中可以去执行,然后拿到分析结果,我们直接写到数仓里面去,那后面的逻辑我们就可以直接交给我们的业务研发,去分析一下我们业务目前是一个什么样的情况。或者说交给我们的大数据平台去统计一下报表,看一下当前业务某一段时间的情况。
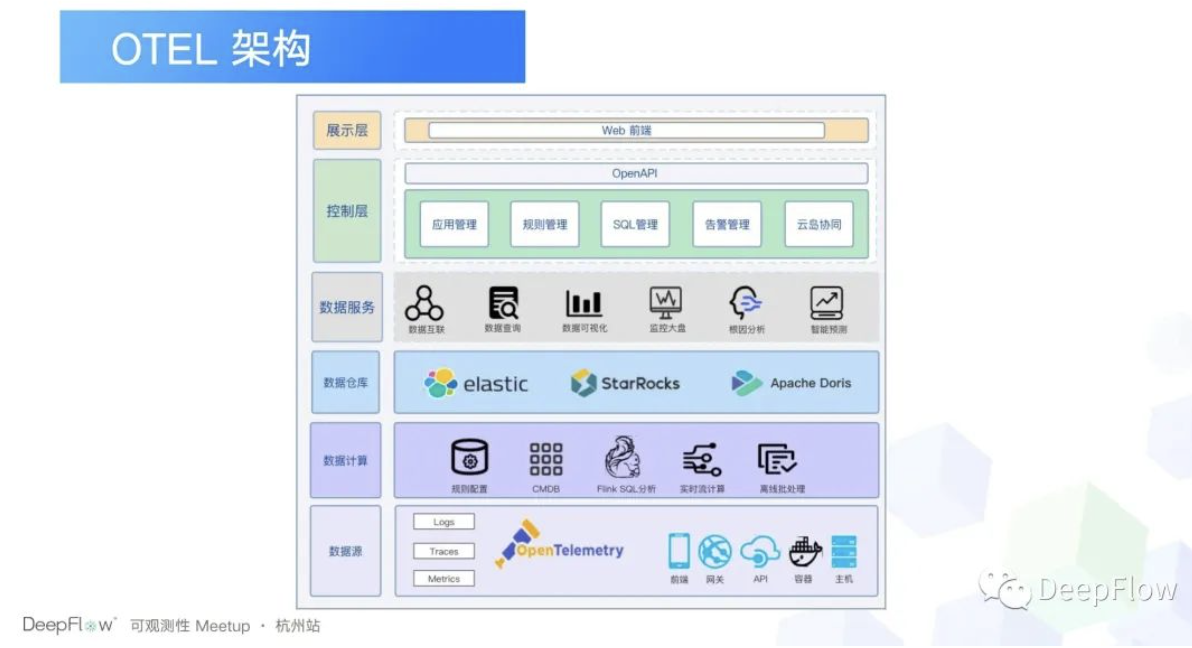
然后按照我们之前的需求,我们是构建了这么一套架构。主要下面三层的话,主要就是数据采集和数据计算的能力了。在这个能力的基础之上我们去提供数据服务。因为我们在数据计算阶段通过对 Trace Log Metrics,我们又做了进一步的加工处理,提出我们认为更有价值的数据。这个时候在数据服务阶段的话我们就很好做了,比如说我们可以很简单的去构建一个可视化,去实现可视化以及监控大盘。然后这个时候我们还可以去做根因分析、智能预测。那再更上一层的话,其实就是我们观测平台的管控面了。像前面提到的应用管理主要是面向用户的。
比如说在应用管理里面,我们可以去做比如说应用的诊断、应用的拓扑管理等等之类的。然后后面的规则管理、 SQL 管理、告警管理,主要就是在数据计算阶段去注入计算的逻辑,然后告警就不多说了。然后云岛协同也是我刚刚提到的一个痛点,就是统一观测。
02、建设过程中面临的问题与挑战
我们现在相当于一个房子的基础架构去构建好了以后,然后想在公司内部去做推广。但是我们刚一开始想着,如果说我们遵守了 OTEL 的标准的话,是不是我们的推广其实是一个很丝滑的一件事情,但是现实给了我们狠狠的一巴掌。

主要的原因是什么呢?就是更换探针的成本高和链路不全。首先说一下更换探针的成本高,事实上如果说我们直接用 OTEL 的探针,其实是可以做到自动注入的,但是有一个问题是什么呢?就是我们之前是用了 Pinpoint Agent 的,然后的话我们还对 Pinpoint Agent 做了一些改造,如果说我们想直接换成 OTEL 的 Agent 的话,这个时候还需要手动插桩才能说我们现在拿到的数据可以覆盖之前 Pinpoint 的数据,那如果说涉及到手动插桩的话,这个时候其实让研发去做适配,这个周期会拉得比较长,因为研发可能更关注就是我业务相关的需求要准时上线。
那还有一点的原因是什么呢?就是我们之前已经注入了 Pinpoint Agent 的,也就是说如果说我们要换探针的话,要么就全换,要么就不换,否则的话我们如果只换一部分的话,就会导致我 Pinpoint 里面数据不是全的,我们自己的观测平台数据也不是全的,整体是一种不可用的状态,又要继续靠人去拿到全部数据。还有一种情况就是有一些应用它承载的业务已经进入了一个稳定的状态,其实它不怎么迭代的,这个时候如果说你要去换探针的话,可能还需要再重新走一遍测试的流程而且如果不是业务需求驱动的应用更新的话,想要去重新发版的话,其实是很难去推的。再有一点就是链路不全,这个也就是我之前提到的,就是我们之前的观测是存在盲区的,存在什么盲区呢?
我们在 Pinpoint 上面,如果说观测到了某一个 Span 的耗时比较长,但是我们不知道它的耗时主要是花在哪里的,因为事实上当请求从应用 A 到应用 B 之间还有一个很长的网络链路,而这个链路在云原生的环境下往往是比较复杂的,在这种情况下的话我们现有的观测能力其实是不能告诉我到底卡在哪个点上的。针对这两个问题的话,我们刚一开始就是想的就是能不能通过 DeepFlow 直接全部解决这两个问题。我不换探针了,我直接用 DeepFlow 的数据,链路不全的话,这个也是 DeepFlow 的看家本领。但是我们实际测下来有一个问题是什么呢?就是不是所有的链路 DeepFlow 都能全部的构建出来,这个时候它可能还需要我们手动去找业务相关的一些字段,去构建一个完整的链路。而且与此同时就是我们刚刚开始想着就是如果说 DeepFlow 的数据能不能直接踢掉 APM 的数据,后面发现下来其实也很难。
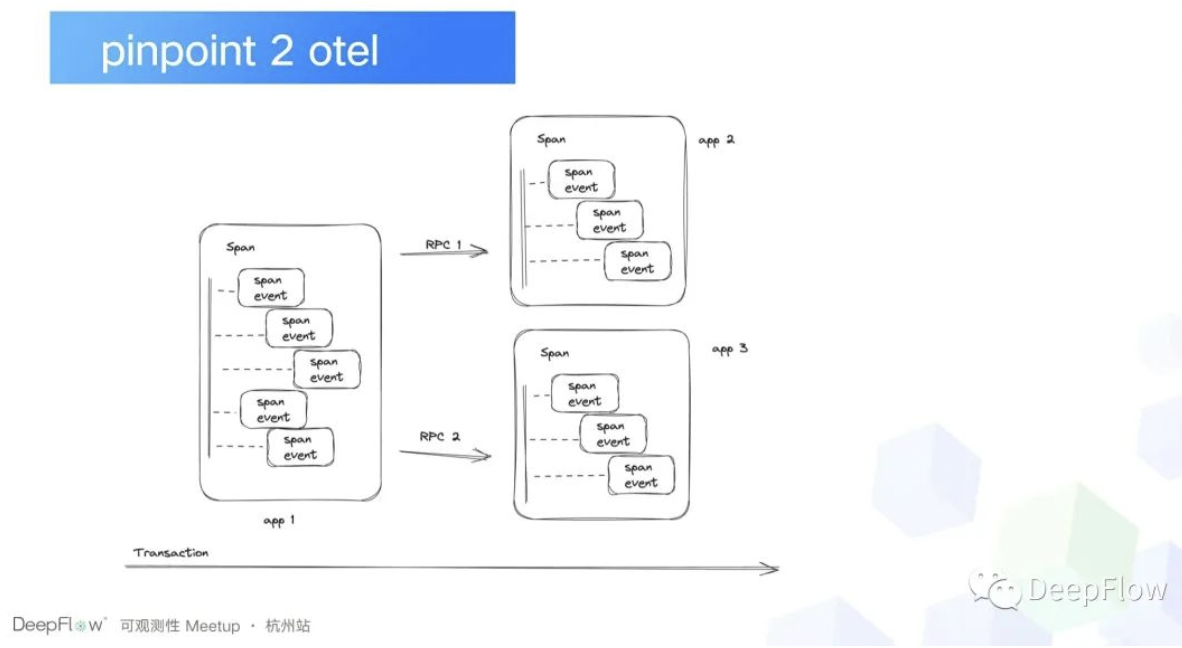
这种方式最好的结合方式其实是 DeepFlow 和 APM 一起结合,这样的话我们 APM 层面的数据也有了,然后存在的一些盲区 DeepFlow 也帮我们补全了。然后当时的话我们和 DeepFlow 其实是有一个讨论的,就是说我们该去怎么解决这个问题,然后 DeepFlow 同学给了我们一个思路,什么思路呢?就是既然我们现在已经有了 Pinpoint 接入了,那其实就相当于是我们可以拿到 APM 层面的数据了,只是说它不符合你们之前预想的数据标准,那把它转成你们想要的数据标准不就可以了吗?然后当时讨论下来,发现确实可行。为什么说确实可行?因为 DeepFlow 他之前干过这事,他是过来人,之前 DeepFlow 的同学就将 Skywalking 的链路信息转成 OTEL 标准的。那我们在想我们按照这个思路去实践的话,其实也是可行的。
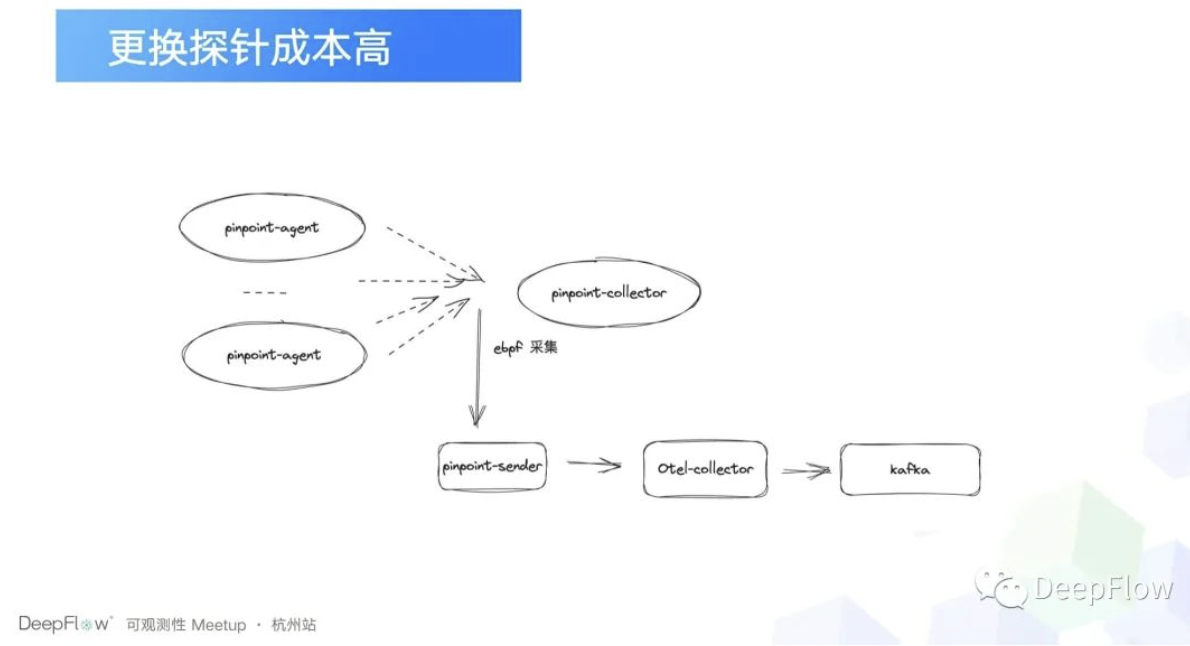
所以我们一个我们构建的一个想法就是我们直接去把 Pinpoint 的数据转成 OTEL 标准的就可以了。但是接下来碰到的另一个问题是什么呢?就是 Pinpoint 的数据不支持导出,也就是说它对我们来说它就是一个信息孤岛,那我们怎么样才能把这部分数据给拿下来,并转换成我们想要的数据标准呢?那我们想到的第一个方案就是我们直接在 pinpoint-gent 和 pinpoint-collector 通信的时候,我们直接拦一道,我们通过 eBPF 采集,把 Pinpoint 的数据拿过来,然后去做一下转换,再发给 OTEL 的 collector 就可以了。
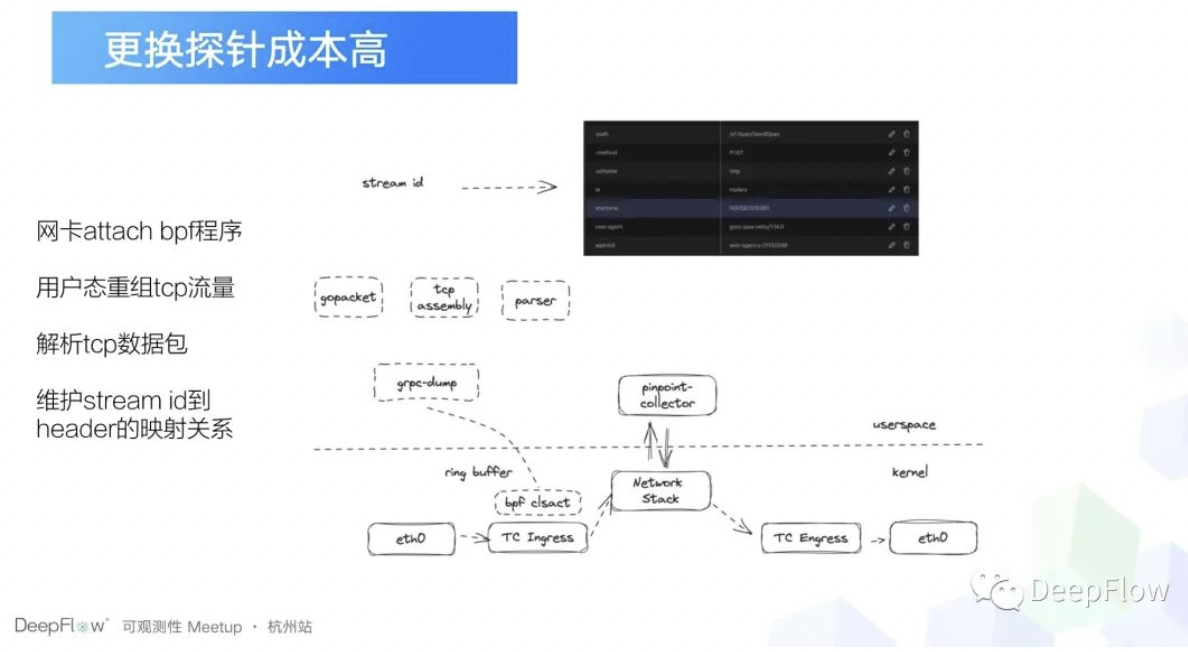
OK, 那具体怎么实现?就是 pinpoint-agent 的和 pinpoint-collector 之间的通信是通过 GRPC 来去通信的,那 GRPC 它又是基于 HTTP2 协议来去通信的,而 HTTP2 协议它有一个特性,就是请求头压缩特性。这就导致如果说我们直接去抓 pinpoint 的数据存在一个问题,就是我不知道这个数据是哪个应用的,也不知道这个数据它的数据结构是怎样的,这些东西都是存在请求头里面的,然后看了一下 DeepFlow 他们是怎么抓 GRPC 流量的?然后我们在想我们需要怎样去弄?
后面调研了一下发现就是一般来说我们去抓 GRPC 流量的话,都是通过 uprobe 去实现的,那我们是不是也可以按照 uprobe 来实现呢?后面发现其实可以更简单,就是我们直接在网卡里面去注入 eBPF 程序,那如果说, pinpoint-agent 和 collector 之间已经建立了通信,没有请求头怎么办?重启一下 pinpoint-collector,其实就会让 pinpoint-agent 的触发 GRPC 的重新连接,这个时候我们就可以拿到请求头里面的数据了。所以最终我们的解决方案是这样子的,第一个就是我们构建一个 eBPF 程序注入到网卡上,然后我们会做一个简单的 IP 加端口的过滤,拿到数据,然后识别一下它是请求头的数据,还是data 帧的数据。如果是请求头数据的话,那我们就持续去维护 stream ID 到请求头的关联关系。
比如说在这个请求头里面,我们主要关注的是三部分数据,第一个就是 path,就是这个 GRPC 请求到底是什么请求?另外一个就是 Agent 的信息,比如说这里的有 Agent 的 ID 和 Agent 的 start time,那通过这种方式我们可以解析 Pinpoint 的数据以后,这个时候我们就把它转成 go packet,然后经过 TCP 的流量重组,再去把它解析成完整的 Pinpoint 的数据。那还有一个问题就是我们现在已经拿到了 Pinpoint 的数据了,那还有一个问题就是 Pinpoint 的数据它怎么转成 OTEL 标准?这里展示的一个流程图其实就是 pinpoint trace 下它的 span 详情。在 Pinpoint 的逻辑里面, span 表示的是一个应用维度,而应用下面又有 span event ,span event 在 Pinpoint 里面是最小的跨度单位,那我们怎么去把它转呢?思路其实也很简单,既然 span event 是最小单位,那我们就直接把 span event 转成 span 就可以了。
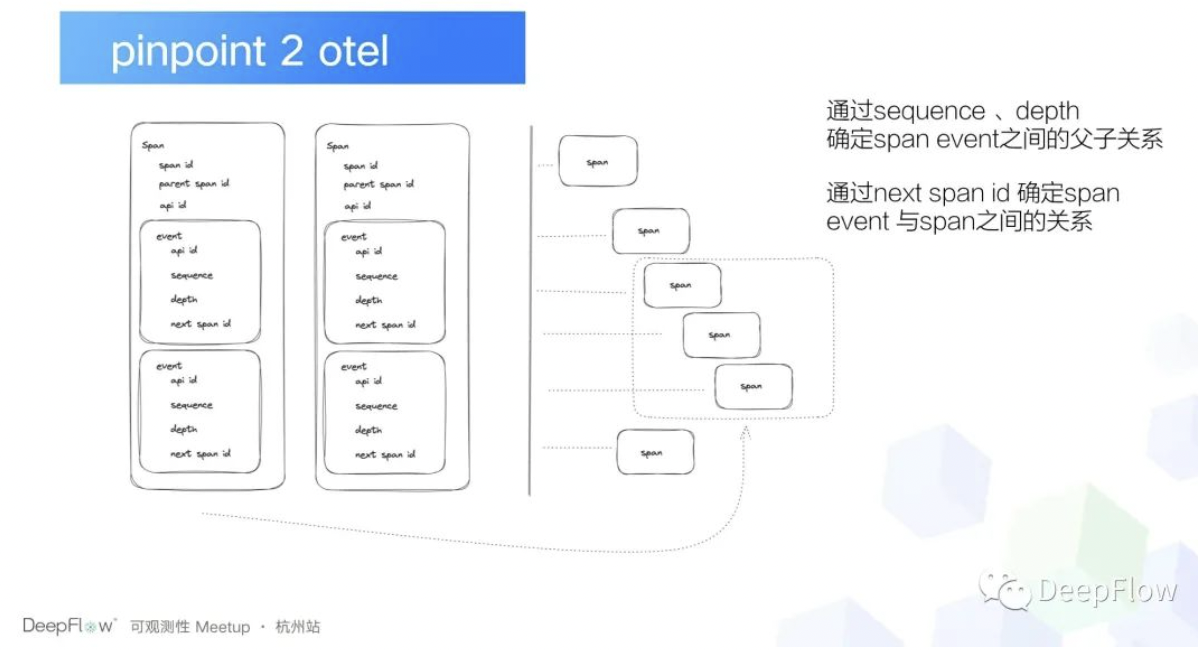
但是需要关注的一个问题是什么呢?就是这个关系应该怎么构建,在 Pinpoint 里面 span 关系描述的是两个应用的父子关系,比如说应用 a 是应用 b 的父应用。但是如果我们转成 OTEL 概念的 span 的话,我们就需要确定的知道当前这个 OTEL span 对应的 parent span 是 pinpoint span 下面的哪个 span event。这个逻辑可能有点绕,就大概核心就是我这个 span 到底对应我当前这个 span 哪个 span event?那怎么关联呢?其实也很简单,就是在 span event 里面它有一个 next 的 span ID,来去告诉我下一个 pinpoint 的 span 到底是谁?OK, 这样的话我们就构建了 pinpoint span 和 span event 之间的之间的关联关系,那还有一个关系我们需要处理一下,就是 span event 和 span event 父子关系应该怎么去确定?这个的话有可以通过两个字段来去决定。
第一个就是 event 里面的 sequence 和depth, sequence 的话就表示这个 event 在这个 span 下的顺序, depth 就表示这个 span event 的深度,那如果说两个 event 它的深度相同的话,其实就表示它们处于同一层级,那我 depth 不相同,而且相邻的话就表示了父子关系。这样的话我们就可以直接去构建出一个 OTEL 的 span 出来了。
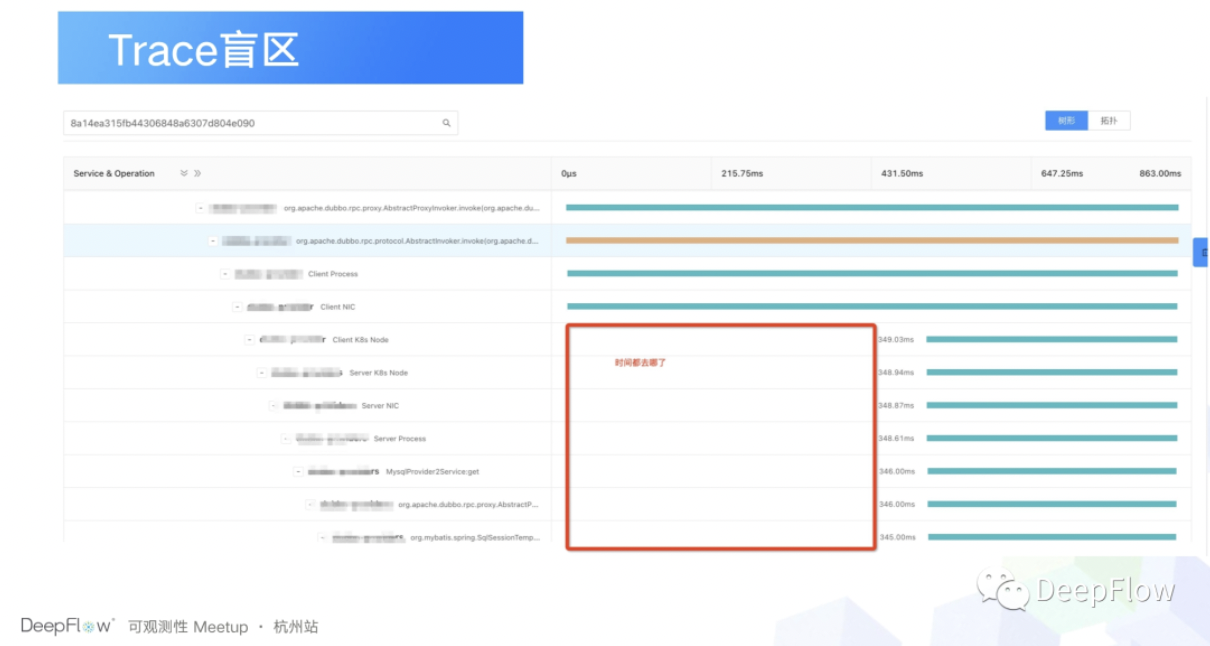
然后另外一个就是我去解决我们盲区问题。在这张图里面我的有一个问题是什么?就是这里面一大片都是留白的,那时间这部分的时间都花到哪去了?那如果说熟悉 DeepFlow 的同学,其实看前面的 Client Process, Client NIC, Client K8S NODE 就能知道这部分其实是 DeepFlow 提供的数据。在这种场景下的话,我们可以立刻就定位到容器网卡到节点之间的通信存在了问题。好,那这个是怎么去把 DeepFlow 的数据和 pinpoint 的数据去做结合的?这就要聊一下 DeepFlow 在政采云是怎么去实践的了。
03、DeepFlow 在政采云的实践

那首先说一下我们为什么要去采用 DeepFlow?其实核心关键的三个点主要来说就这三个。第一个零侵入自动化的追踪,我们不需要业务侧去帮我们去做适配了,因为一旦如果需要业务侧去适配的话,我们产品的推广的周期会拉得特别长。然后还有一个是我们环境所决定了,就是我们会有一些网关服务器,它还是 3. 10 的内核。然后 DeepFlow 它支持 AF_PACKET 和 eBPF 两种采集方式,并且 AF_PACKET 采集到的数据依然有,依然能够补全我们的盲区。
另外一个就是消除数据孤岛,这个可能听上去有一点奇怪,为什么说 DeepFlow 能够帮助我们消除数据孤岛呢?就是在前面我们提到了我们把 Pinpoint 数据拿到了,也转好了,但是没有解决核心的问题,关联关系没有去构建出来,这个关联关系不是说 trace 下面 span 的关联关系,而是 trace 和 log 和 metrics 没有关联上。
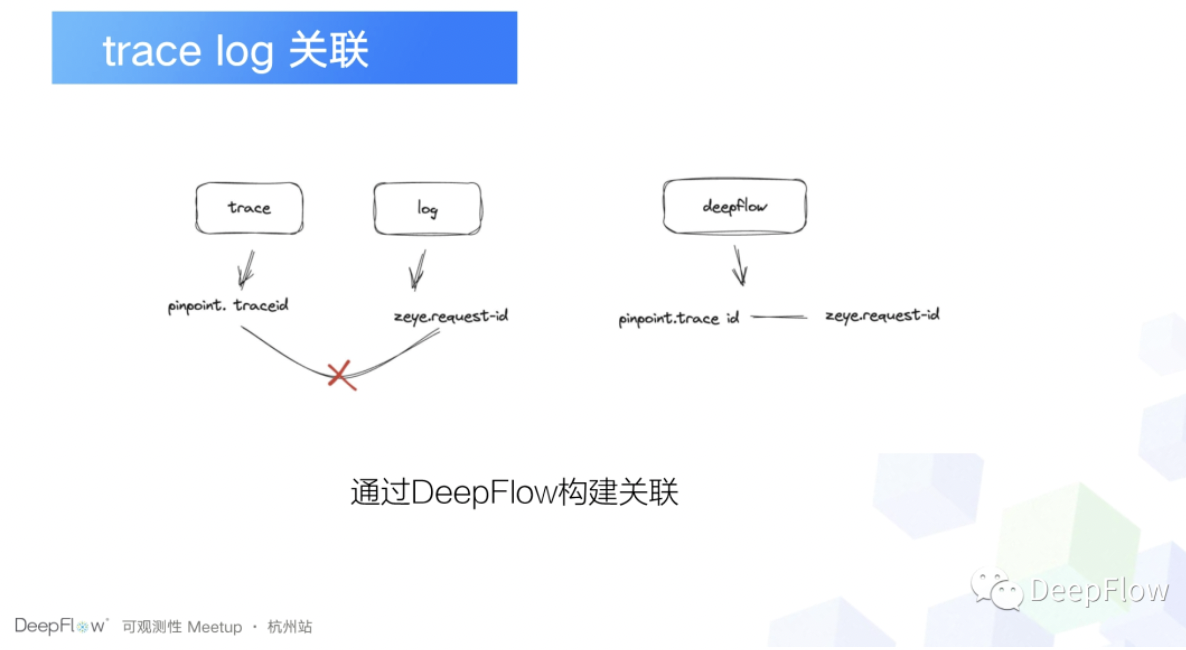
这个其实是我们业务目前存在的一个问题,就是我们在 pinpoint 里面我们只能看到 pinpoint 的 trace ID,在日志里面我们只能看到 RequestID 这两者之间的关联关系,对用户来说他是不知道的,那谁知道呢?DeepFlow 可以知道, DeepFlow 为什么可以知道?主要原因是我们的应用有通用的一些SDK,然后它会往各个协议,比如说 Double 协议, HTTP 协议, RabbitMQ 协议,他们的协议头里面去塞 Request ID 而 pinpoint-agent 他也会往这些协议的协议头里面去塞 pinpoint 的 TraceID。这样的话,我们通过 DeepFlow 我们就可以拿到这两者之间的关系,所以这就相当于我们帮助我们去解决了 pinpoint 的数据孤岛的问题。
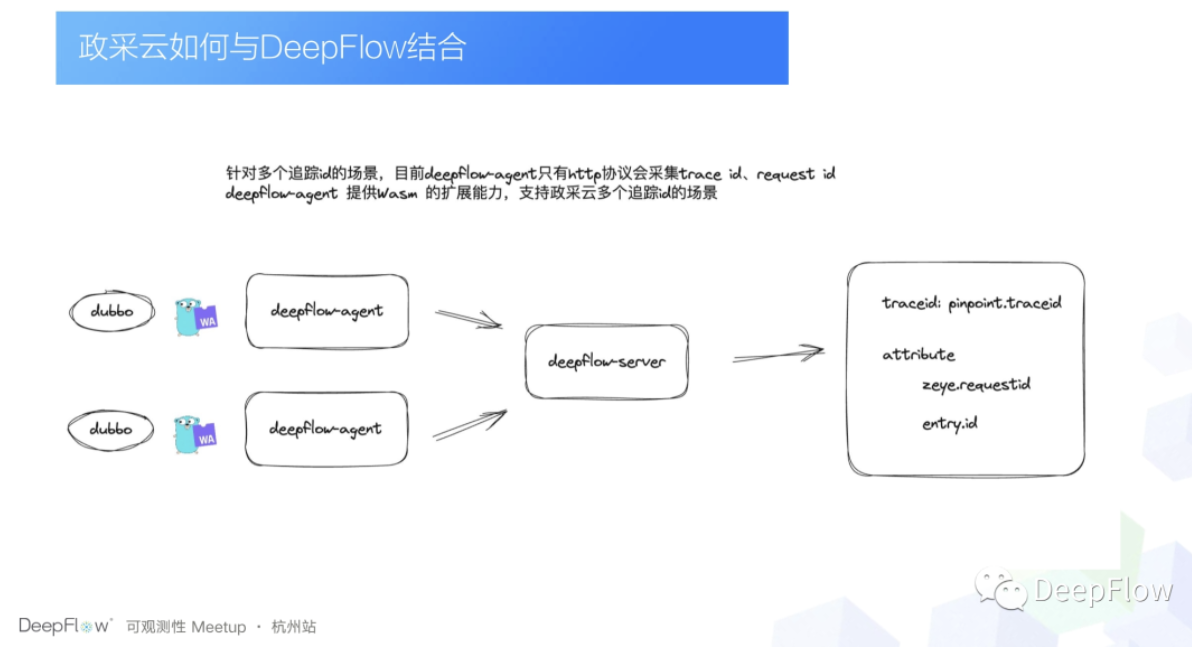
那具体实践下来有一个问题是什么呢?就是 DeepFlow Agent ,它对于 Double 协议的解析,它只能采集到一个 Trace ID,它只有在 HTTP 协议的时候,它会去采集 Request ID 和 Pinpoint 的 Trace ID。所以针对这种问题的话,我们刚一开始的想法就是我们直接去改一下 DeepFlow 的 Agent,然后拓展一下在 Double 协议上的解析。
那后来到后来发现 DeepFlow 它本身是支持 Webassembly 的扩展能力,也就是说我们可以直接写一个插件,直接介入到 DeepFlow Agent 的数据解析的流程当中,然后我们目前的话是专门去写了 Double 协议的解析,这样的话我们可以直接去拿到 Pinpoint Trace ID 以及在日志里面存放的 Request ID,然后还有一些这个 Entry ID,这个就是 SDK 放的一些另外一个维度的 ID 了,这个主要是做统计用的。
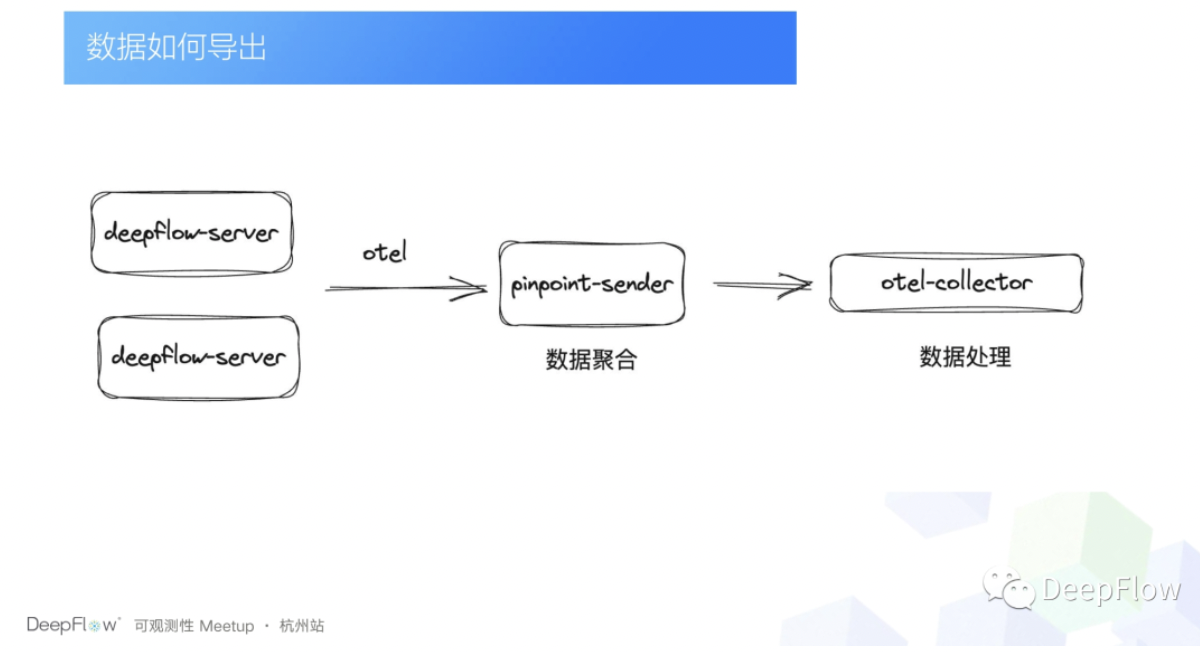
那另外一个问题就是我们现在通过 DeepFlow 去打通了数据的关联关系以后,那数据应该怎么去聚合起来?那 DeepFlow 它其实是支持这种方式的,就是我们直接把数据吐给 DeepFlow,然后在 DeepFlow 上去看,但这样的话其实不方便我们去构建我们自己的观测平台,所以我们想的就是让 DeepFlow 把数据导出来。DeepFlow 的数据里面一方面帮我们补全了链路,另外一方面是把 trace 和 log 的关联关系也带给我们了,然后我们再拿到 pinpoint 数据,再加上 DeepFlow 数据做一个聚合,再交给 otel-collector。
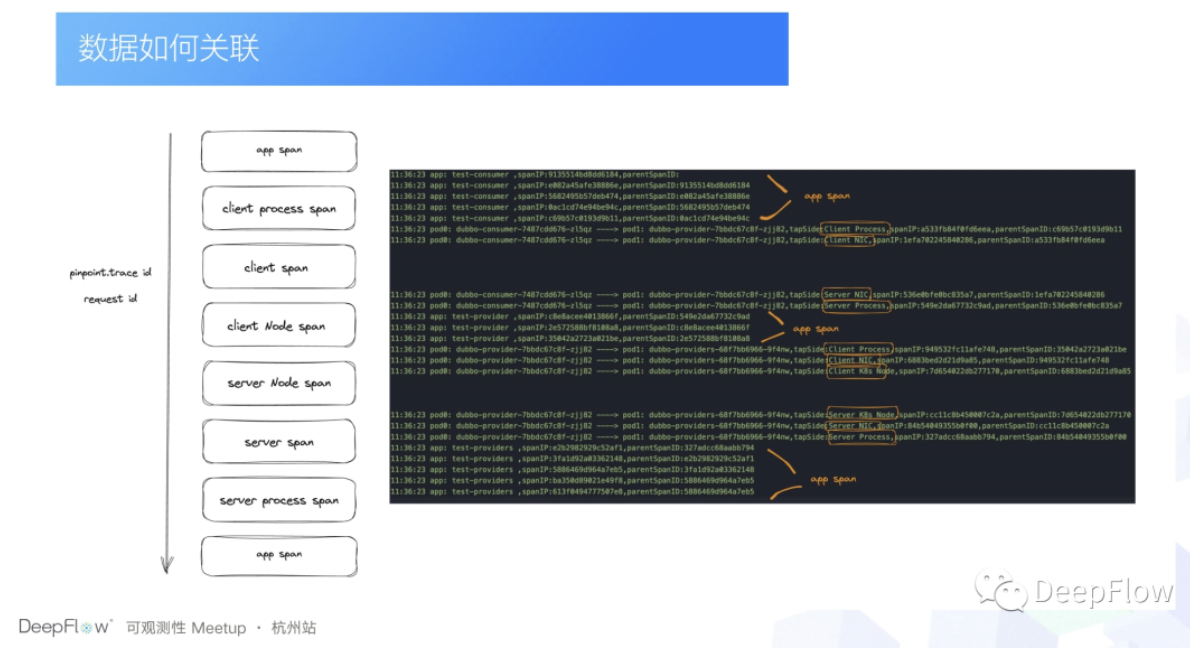
那做聚合的话存在一个问题,就是这个数据到底怎么关联?首先一个就是 DeepFlow 把 span 的话是做了几个划分的,APM 层面的 span 的话都叫 APP span,其他维度的话就按照数据采集点来去划分。比如说在容器网卡上采集的就叫 Client span,在 NODE 上采集的话就是 Client Node span,我们只需要按照 DeepFlow 采集数据的顺序,去把 APM span 的的数据和 DeepFlow 数据做下关联就可以了。但是有一个前提条件就是在有 trace ID 的场景下才能实现。
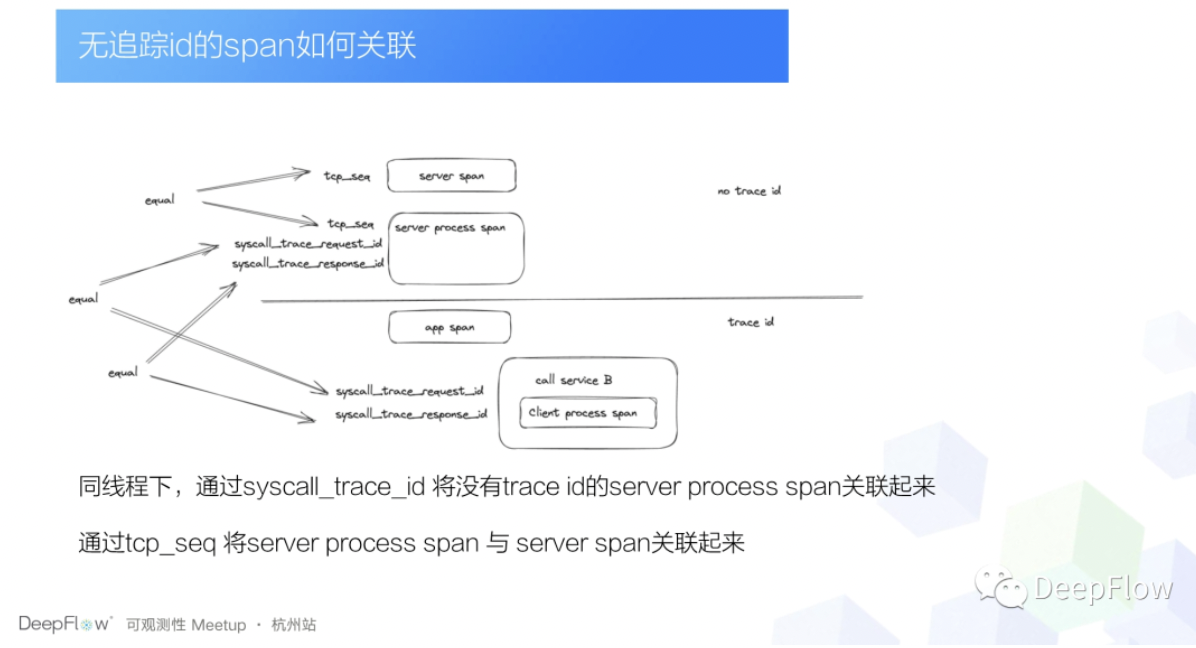
但是还有一种情况是什么呢?就是我们这个 trace 下,不是所有的 span 都有 trace ID 的。比如说当我某个应用我收到一个请求的时候,这个时候 pinpoint 的 trace ID,或者说网关的 Request ID 都还没有生成,这个时候 DeepFlow 的 span 数据是怎么关联的呢?这个就提到 DeepFlow 有一个特殊的追踪 ID 了,就是 syscall_trace_id 。它表示的是两个相邻的系统调用,可以通过 syscall_trace_id 把它关联起来,那我们再去关联没有 trace ID 的 span 的时候,我们只需要先往下去找到这个 APP span 的第一个 span,比如说这里的 client process span,然后再通过这个 client process span 去找 Server process span。而 Server process span 它和 Server span 之间的关联又可以通过 tcp 的序列号给它关联上。

这样的话我们就在很多场景里面,我们就可以把有 trace ID 的,没有 trace ID 的 span 给关联起来了,但是当我们吭哧吭哧做好了以后,我们发现 DeepFlow 它又出了一个我觉得会更方便的一个功能,就是它直接提供了一个 trace completion API,也就是说你不需要去做聚合了,你可以直接在前端页面上,你比如说你想要去查看 DeepFlow 的数据,直接去调用 DeepFlow 的API,直接把所有没有插桩的网关服务以及一些不能塞追踪 ID 的一些协议,比如说DNS、 Redis 等之类的 span 全部都给你关联上了。
所以我们现在目前也是在想着直接通过 trace completion API 直接去拿这个关联关系,不用我们去自己去做聚合了。这样的话有一个好处就是我们如果说不是在排查故障的话,其实不太需要看更详细一点的 span 信息,往往是在故障处理的时候才需要,这样的话我们只需要通过一个开关调一下 DeepFlow 的 API 就可以直接去拿到了。
04、总结与未来计划

然后我们目前的能力主要就是将 pinpoint 的数据转成了 OTEL 的标准,以及把 DeepFlow 的数据给聚合进来了。但是这个事情还没有完,还需要做的事情主要是分两点,第一个就是加强数据关联,前面提到的就是我们的应用程序的一些通用的SDK,可以会往各个协议里面去塞一些他们认为比较重要的一些数据,而这些数据其实 DeepFlow 本身它是不会采集的。
这个时候我们还可以通过 Webassembly 去拓展协议解析,拿到更多的数据。当然这些具体能拿到哪些数据,这个可能要去和业务的研发去对一下。比如说我们还可以去拿 RabbitMQ 里面塞的 message ID,以及 Kafka 的消息里面传的消息ID,最终的目的主要是什么呢?就是关联一切我们可以关联的数据,方便我们去做顺藤摸瓜找根因。
然后还有一个就是基于 eBPF 方案的 Profiling,这个是我们目前完全不具备的能力,为什么需要要去做这个呢?一方面就是我们去做故障排查的时候,事实上通过堆栈信息的话,可以立刻看到一些问题,然后刚好 DeepFlow 也在做这个事情,当然我当时只看到了代码,没有在页面上看到功能,我想着他们应该是默默藏大招。然后刚刚看看向阳老师的分享,果然,所以后面我们也是会结合 DeepFlow 的 Profiling 能力去做一个集成。好,我今天的分享就到这了。
女高管开除员工事件后续:公司董事长称员工“惯犯”并质疑“学历简历造假” 开源神器 LSPosed 宣布停更,作者称遭受大量恶意攻击 盘点 2023 “很刑”的 IT 民生事件:视频软件白嫖带宽、程序员改 ETC 余额…… 被女高管违法开除员工发声,因反对用盗版 EDA 工具设计芯片遭针对 罗永浩称“荣耀任意门”抄袭锤子开源软件 One Step 2024 年,Linux 内核的开发语言是否要从 C 转换为 C++ 中文 JDK 教程网站正式上线,助力开发者掌握 Java 编程语言 Linus 在 Linux 6.8 内核发现性能倒退问题 Unity 将裁员 25%,涉及 1800 人 北京司法鉴定所破解 AirDrop 匿名溯源