Dubbo3 可观测能力速览
Apache Dubbo3 在云原生可观测性方面完成重磅升级,使用 Dubbo3 最新版本,你只需要引入 dubbo-spring-boot-observability-starter 依赖,微服务集群即原生具备以下能力:
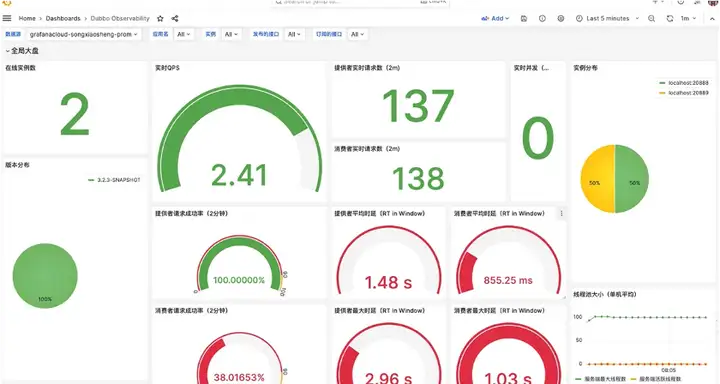
能力一:可视化查看集群、单机流量指标与健康状态
Dubbo 3.2 最新版本支持以应用、单机、单条服务等多种不同粒度观测运行状态,包括 qps、rt、线程池、错误分类统计等。
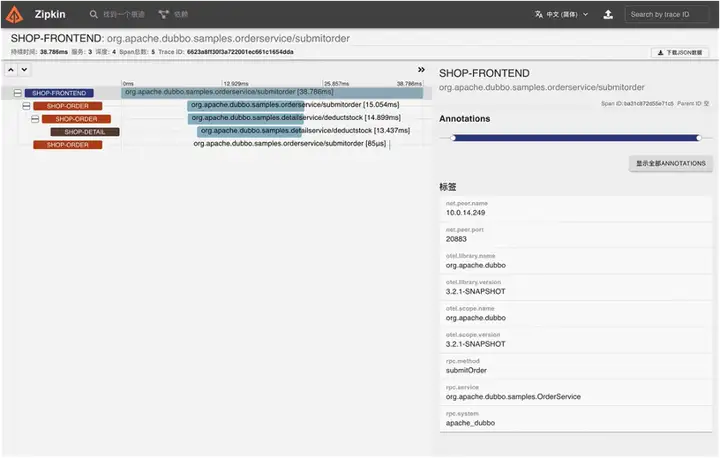
能力二:全链路追踪
Dubbo 3.2 最新版本通过内置链路过滤器在 RPC 请求中对链路数据进行采集,采集之后通过导出器将链路数据导出到各大厂商。
https://cn.dubbo.apache.org/zh-cn/overview/tasks/observability/
云原生可观测性的探索
云原生升级的挑战
高质量交付的前一部分有 DevOps 保证开发与测试的质量与效率,后有云原生保证运维部署效率与质量,但是大规模快速迭代意味着频繁变更,变更与系统运行带来的稳定性问题不能被忽视,比如宕机,网络与系统异常等,很多未知的问题难以避免,借助可观测系统来及时感知问题、高效分析异常、快速恢复系统,提前规避已知问题,深度挖掘未知问题,高效提升运维质量,可以看到建设一个完善的可观测平台对于发现已知和未知异常,提升系统的稳定性是非常必要的。
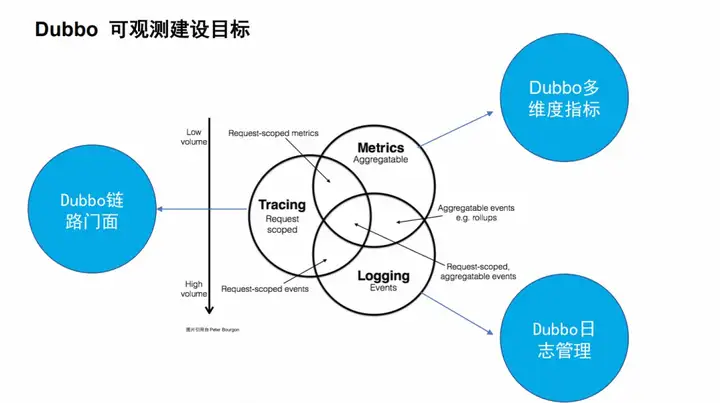
Dubbo 可观测建设目标
Dubbo 作为微服务 RPC 基础框架直接建设大而全的可观测系统与定位不符合也不是很现实,但是可以从自身出发提供更多的基础监控数据来为企业建立可观测系统提供助力,可观测性与传统单维度监控不同,更关注的是数据的关联性,通过单维度和多维度角度整体观测和分析问题,首先从流行的三大支柱指标出发,在此基础之上,Dubbo 提供多维度聚合与非聚合指标帮助用户快速发现问题与诊断问题,多维指标中进而可以通过应用、主机等标签信息关联到链路系统,链路系统提供了服务请求级别的链路性能与异常问题分析功能,Dubbo 通过提供链路门面对接各大全链路厂商,链路分析之后可以通过链路数据例如:TraceId,SpanId 自定义数据等来追踪到详细日志,详情日志中 Dubbo 侧提供了丰富的专家建议与错误码供开发与运维同学快速诊断与定位问题。
Dubbo 多维度指标体系
Dubbo 多维度指标体系建设中从纵向和横向两个角度来看,纵向 Dubbo 侧提供简易接入的门面外观,然后将系统中采集到的指标存储在内存指标容器中,接着根据指标类型决定是否进行聚合计算,最后将指标导出到不同的指标系统。从横向角度来看采集维度也覆盖到容易出问题的 RPC 请求链路,三大中心交互与线程资源使用情况等场景。
Dubbo 多维度指标体系采集哪些指标?
前面介绍了大面上的指标采集,但是 Dubbo 应该采集哪些详细的指标呢?接下来可以看到 Dubob 采集指标时参考的一些方法论。

根据谷歌 SRE 书:Google 针对大量分布式监控的经验总结提出 4 个黄金指标(延迟、流量、错误以及饱和度)可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。

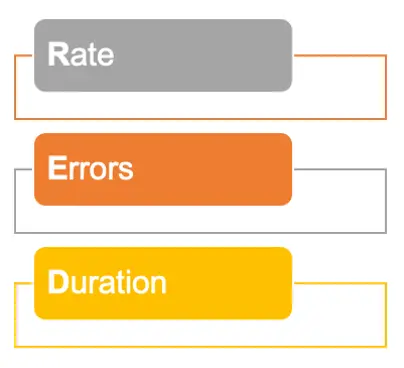
RED 方法(来自 Tom Wilkie),RED 方法则关注请求、实际工作以及外部视角(即来自服务消费方的视角)包含:速率、错误与持续时间。
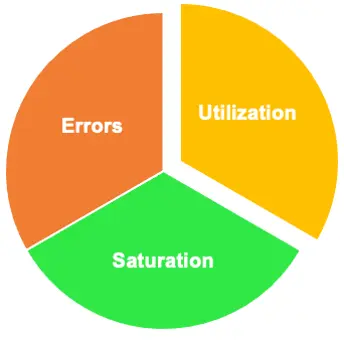
USE 方法(来自 Brendan Gregg):USE 方法主要着眼于资源内部,包含:利用率、饱和度与错误。
Dubbo 多维度指标体系接入-导出到 QOS
多维度指标体系在 3.2 之后的版本已经发布与持续迭代中,对用户来说只需要引入一个依赖即可:
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-observability-starter</artifactId>
<version>3.2.x</version>
</dependency>
依赖引入之后默认情况下一些关键指标会默认被打开,只需要在命令行访问当前服务 22222 服务端口和 metrics 路径即可获取到指标数据,其中 22222 端口是 Dubbo 提供的服务质量,健康管理端口可以用过 QOS 配置进行修改。

查询到的 Dubbo 指标以命名:dubbo_type_action_unit_otherfun 的格式进行展现。
当然也会有用户直接使用 SpringBoot 管理端口的情况,针对这种场景 Dubbo 侧已经做了自动适配直接使用 SpringBoot 导出普罗米修斯格式的指标数据即可,如下配置所示:

在访问 SpringBoot 管理端口查询指标数据时就可以看到 SpringBoot 内置的一些指标和 Dubbo 提供的一些指标一起展示给用户了。
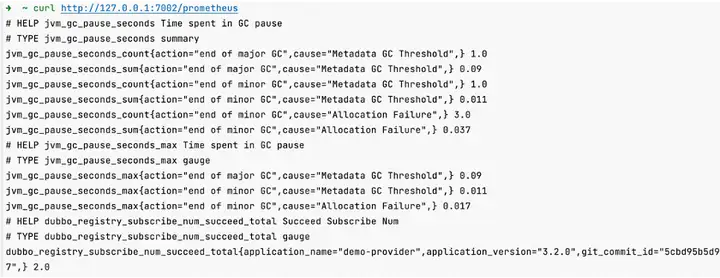
Dubbo 多维度指标体系 Prometheus 查询
前面直接通过 curl 命令访问指标服务获取到的只是瞬时的指标数据,对于指标数据我们往往更需要的是时序化的向量数据,这时候就要借助普罗米修斯来进行在外部采集,存储 Dubbo 指标,对于传统应用部署在物理机和虚拟机的服务可以使用静态,基于文件或者基于自有 CMDB 系统建设的指标发现服务,当然后续也可以使用 Dubbo Admin 为指标系统提供的服务发现服务,对于部署在 K8s 中的系统来说可以直接借助 K8s 支持的服务发现,接入 Prometheus 自动采集配置如下:

普罗米修斯中查询指标如下所示:
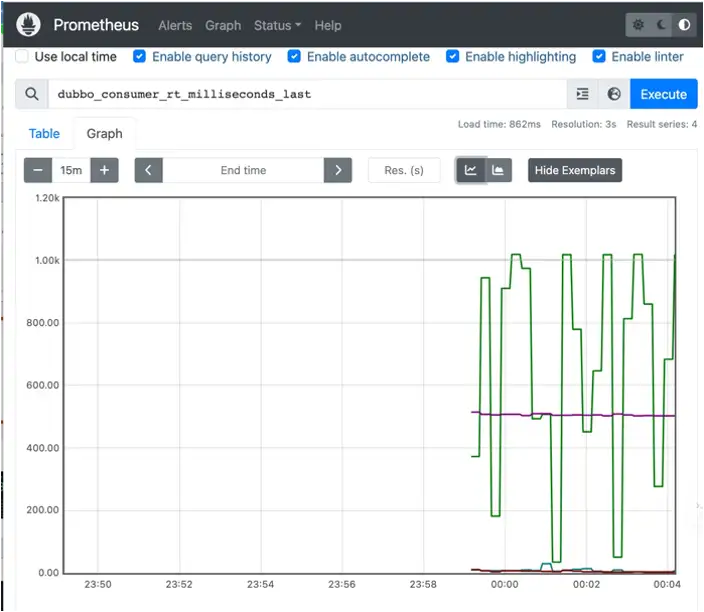
Dubbo 多维度指标体系 Grafana 展示
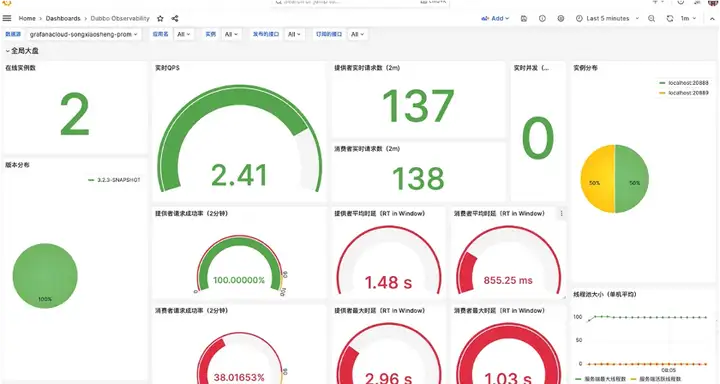
普罗米修斯侧重于采集指标和存储指标等场景,在展示指标这里相对简陋,Grafana 提供了丰富的指标面板,使用 Grafana 来建立指标大盘更直观,也更容易,可以看到下面的图片中提供了多维度的筛选如应用级、实例级,接口级等场景对服务数据进行查询。在指标监控大盘中也可以看到基于前面指标方法论的一些维度指标,比如流量、请求数、延迟、错误,饱和度等。另外也可以看到一些应用于实例信息比如 Dubbo 版本分布,实例分布等。
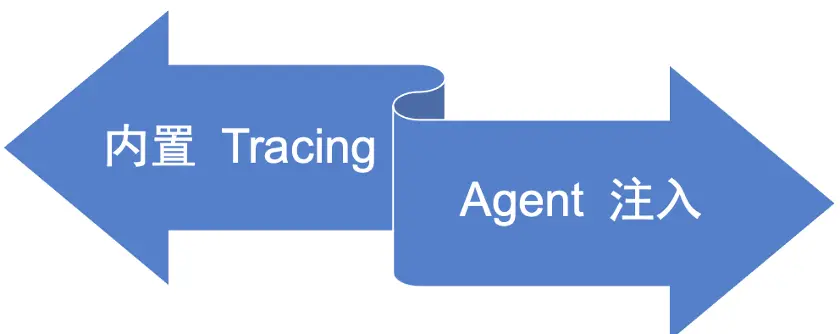
Dubbo 链路追踪门面建设
Agent 用户接入简单,但是动态修改字节码的形式来提供支持,风险较大,一个代理层 agent 只做一个 Dubbo 层的链路功能似乎有点大材小用,Dubbo 定位为微服务 RPC 框架,做通用的链路门面相对更好一些,专业的事情交给专业的人做,Dubbo 通过适配各大全链路系统来让用户接入更简单。
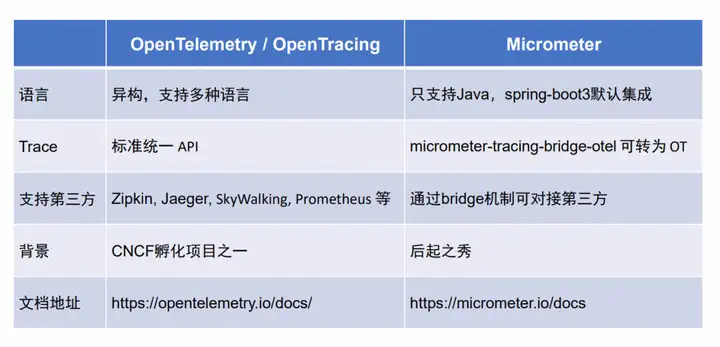
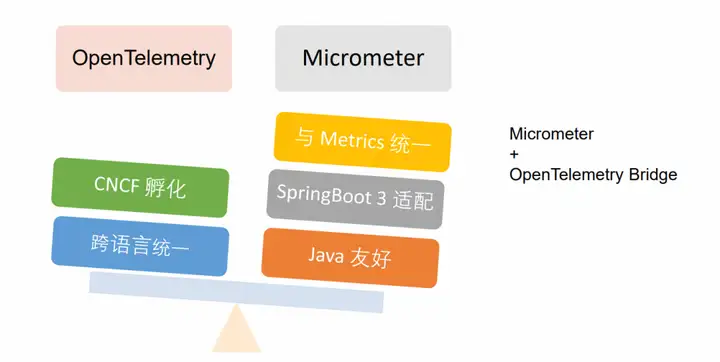
Dubbo 链路追踪门面选型
业界比较通用的 OpenTelemetry 链路追踪门面更倾向于标准统一的规范,支持各大厂商,同时也是与 CNCF 孵化的项目,Micrometer 的优势在于与指标埋点所用依赖来源相同,并且在 SpringBoot3 中也默认集成用户接入更为方便,另外 Micrometer 定位为可观测门面与 Dubbo 链路系统建设的定位相符,其中也可以通过桥接的形式来桥接 OpenTelemetry。
Micrometer + OpenTelemetry Bridge:
Dubbo 链路追踪结构
Dubbo 通过内置链路过滤器在 RPC 请求中对链路数据进行采集,采集之后通过导出器将链路数据导出到各大厂商。

Dubbo 链路追踪接入
Dubob 链路追踪门面已经发布,需要接入链路追踪系统只需要简单的引入对应链路追踪的 starter 集成包然后进行单件的配置即可,更详细的接入手册可以参考文档和案例。[1]

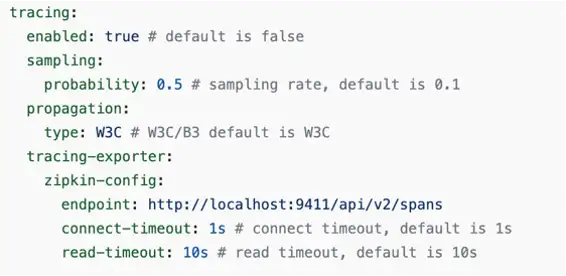
在链路追踪配置中可以配置开关,采样率,导出器等配置。
最后链路追踪系统往往也需要通过链路 id 与日志进行关联来分析更详细的根因,这个时候就需要提前在日志配置中增加日志 MDC 打印的配置了,如下 traceId 和 spanId 的获取。

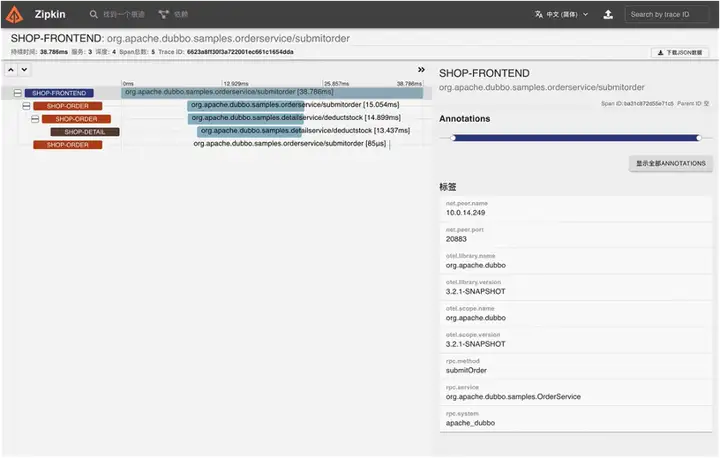
Dubbo 链路追踪 Zipkin
这里是 Dubbo 接入链路追踪 Zipkin 的展示,可以看到一些接口的性能与元数据。
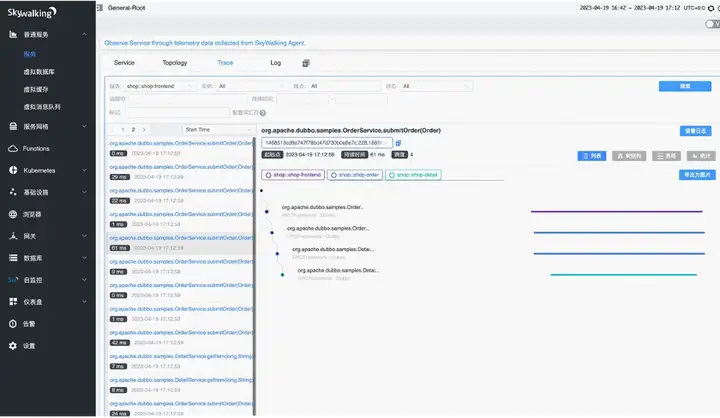
Dubbo 链路追踪 Skywalking
这里是 Dubbo 接入链路追踪 Skywalking 的展示,通过链路 id 检索到的请求级别的链路分析。
Dubbo 日志管理
Dubbo 日志管理异常
Dubbo 框架发展多年,功能越来越丰富, 其中包含了与三大中心的交互,客户端服务端的交互,这种内外部交互的场景更容易出现一些异常,如果遇到问题通过通过观察日志经常摸不着头脑,最后通过分析代码来定位根因又是相对头疼的事情。
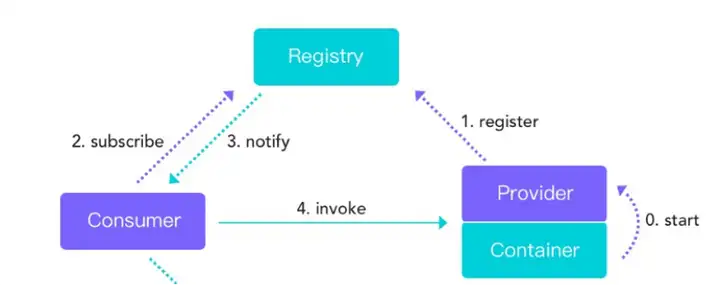
遇到问题不知道原因:

Dubbo 日志管理专家建议
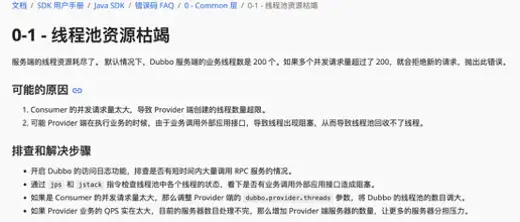
如果仔细观察 Dubbo3.x 新版本打印出的日志就可以看到日志中会打印一个问题帮助手册,当发现问题时候复制此链接在浏览器中打开就可以看到出现异常日志时候的专家建议,比如下图所示的问题原因排查步骤,随着 Dubbo 的发展专家建议也会越来越详细,当让这个过程要建设的更为完善就需要用户、开发者一起参与进来,Dubbo 社区非常 Open,鼓励用户、开发者一起参与进来进行建设。
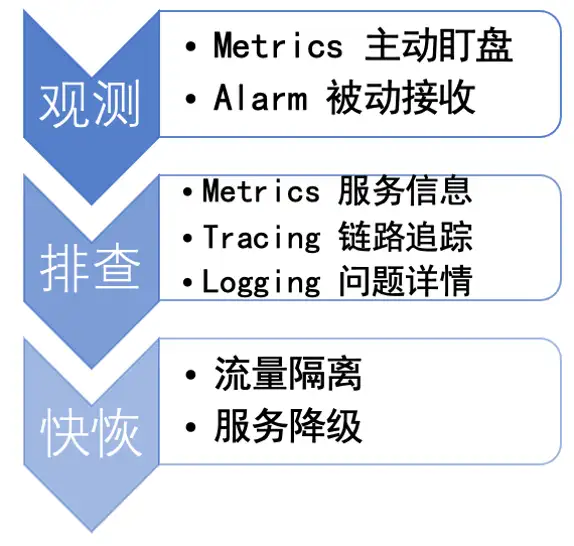
Dubbo 可观测性-稳定性实践
最后就是围绕整个可观测平台来做稳定性实践了,稳定性实践中通过观测服务健康状况、排查分析系统问题、最后快速恢复系统。其中观测系统异常的情况可以通过值班人员主动观测监控大盘,也可以将异常分析告警,被动接收到告警邮件、IM、短信、电话等来及时发现问题,发现异常时可以借助指标来分析聚合与非聚合的服务信息来定位异常位置,然后通过链路追踪系统找到服务级别的异常进行分析,最后也可以根据链路信息找到详细的日志来分析异常上下文排除根因,排查的过程要借助整个观测平台以快速恢复系统为目标通过流量隔离,服务降级等策略恢复系统减少损失,事后可以借助可观测平台提供的这些持久化的信息来详细分析异常与规律来定位根因。
[1] 文档和案例
https://cn.dubbo.apache.org/zh-cn/overview/tasks/observability/tracing/
作者:宋小生 - 平安壹钱包中间件资深工程师
点击立即免费试用云产品 开启云上实践之旅!
本文为阿里云原创内容,未经允许不得转载。
工信部:不得为未备案 App 提供网络接入服务 Go 1.21 正式发布 阮一峰发布《TypeScript 教程》 Vim 之父 Bram Moolenaar 因病逝世 某国产电商被提名 Pwnie Awards“最差厂商奖” HarmonyOS NEXT:使用全自研内核 Linus 亲自 review 代码,希望平息关于 Bcachefs 文件系统驱动的“内斗” 字节跳动推出公共 DNS 服务 香橙派新产品 Orange Pi 3B 发布,售价 199 元起 谷歌称 TCP 拥塞控制算法 BBRv3 表现出色,本月提交到 Linux 内核主线