目录
1.Get和Post的请求的区别
Post和Get是HTTP请求的两种方法,其区别如下:
- 应用场景:GET请求是一个幂等的请求,一般Get请求用于对服务器资源不会产生影响的场景,比如说请求一个网页的资源。而Post不是一个幂等的请求,一般用于对服务器资源产生影响的情景,比如注册用户这一类的操作。
- 是否缓存:因为两者应用场景不同,浏览器一般会对Get请求缓存,但很少对Post请求缓存。
- 发送的报文格式:Get请求的报文中实体部分为空,Post请求的报文中实体部分一般为向服务器发送的数据
- 安全性:Get请求可以将请求的参数放入url中向服务器发送,这样的做法相对于Post请求来说是不太安全的,因为请求的url会被保留在历史记录中
- 请求长度:浏览器由于对url长度的限制,所以会影响get请求发送数据时的长度。这个限制的浏览器规定的,并不是RFC规定的
- 参数类型:post的参数传递支持更多的数据类型、
2.常见的HTTP请求头和响应头
HTTP Request Header常见的请求头:
- Accept:浏览器能够处理的内容类型
- Accept-Charset:浏览器能够显示的字符集
- Accept-Encoding:浏览器能够处理的压缩编码
- Accept-Language:浏览器当前设置的语言
- Connection:浏览器与服务器之间连接的类型
- Cookie:当前页面设置的任何Cookie
- Host:发出请求的页面所在域
- Referer:发出请求的页面的URL
- User-Agent:浏览器的用户代理字符串
HTTP Response Header常见的响应头:
- Date:表示消息发送的时间,时间的描述格式由rfc822定义
- server:服务器名称
- Connection:浏览器与服务器之间连接的类型
- Cache-Control:控制HTTP缓存
- content-type:表示后面的文档属于什么MIME类型
常见的Content-type 属性值有以下四种:
(1)application/x-www-form-urlencoded:浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。该种方式提交的数据放在 body 里面,数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL转码。
(2)multipart/form-data:该种方式也是一个常见的 POST 提交方式,通常表单上传文件时使用该种方式。
(3)application/json:服务器消息主体是序列化后的 JSON 字符串。
(4)text/xml:该种方式主要用来提交 XML 格式的数据。
3.常见的HTTP请求方法
- GET:向服务器获取数据
- POST:将实体提交到指定的资源,通常会造成服务器资源的修改
- PUT:上传文件,更新数据
- DELETE:删除服务器上的对象
- HEAD:获取报文首部,与GET相比,不返回报文主体部分
- OPTIONS:询问支持的请求方法,用来跨域请求
- CONNECT:要求与代理服务器通信时建立隧道,使用隧道进行TCP通信
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
4.HTTP与HTTPS协议的区别
HTTP和HTTPS协议的主要区别如下:
- HTTPS协议需要CA证书,费用较高,而HTTP协议不需要
- HTTP协议是超文本传输协议,信息是明文传输的,HTTPS则具有安全性的SSL加密传输协议
- 使用不同的连接方式,端口也不同,HTTP协议端口是80,HTTPS协议端口是443
- HTTP协议连接很简单,是无状态的;HTTPS协议是有SSL和HTTP协议构建的可进行加密传输,身份认证的网络协议,比HTTP更加安全。
5.对keep-alive的理解
HTTP1.0中默认是在每次请求/应答,客户端和服务器都要新建一个连接,完成之后立即断开连接
,完成之后立即断开连接,这就是短连接。当使用keep-alive模式时,keep-alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,keep-alive功能避免了建立或者重新建立连接,这就是长连接。其使用方法如下:
- HTTP1.0版本是默认没有Keep-alive的(也就是默认会发送keep-alive),所以要想连接得到保持,必须手动配置发送
Connection: keep-alive字段。若想断开keep-alive连接,需发送Connection:close字段; - HTTP1.1规定了默认保持长连接,数据传输完成了保持TCP连接不断开,等待在同域名下继续用这个通道传输数据。如果需要关闭,需要客户端发送
Connection:close首部字段。
keep-alive建立的过程:
- 客户端向服务器在发送请求报文同时在首部添加发送Connection字段
- 服务器收到请求并处理Connection字段
- 服务器回送Connection:Keep-Alive字段给客户端
- 客户端接收到Connection字段
- Keep-Alive连接建立成功
服务器自动断开过程(也就是没有keep-alive):
- 客户端向服务器只是发送内容报文(不含Connection字段)
- 服务器收到请求并处理
- 服务器返回客户端请求的资源并关闭连接
- 客户端接收到资源,发现没有Connection字段,断开连接
客户端请求断开连接过程:
- 客户端向服务器发送Connection:close字段
- 服务器收到请求并处理Connection字段
- 服务器回送响应资源并断开连接
- 客户端接收资源并断开连接
开启Keep-Alive的优点:
- 较少的CPU和内存的使用(由于同时打开的连接的减少了)
- 允许请求和应答的HTTP管线化
- 降低拥塞控制(TCP连接减少)
- 减少了后续请求的延迟(无需再进行握手)
- 报告错误无需TCP连接
开启Keep-Alive的缺点:
长时间的TCP连接容易导致系统资源无效占用,浪费系统资源。
6.页面有多张图片,HTTP是怎样的加载表现?
- 在HTTP 1下,浏览器对一个域名下最大TCP连接数为6,所以会请求多次。可以用多域名部署来解决。这样可以提高同时请求的数目,加快页面图片的获取速度。
- 在HTTP 2下,可以一瞬间加载出来很多资源,因为HTTP2支持多路复用,可以在一个TCP连接中发送多个HTTP请求。
7.HTTP请求报文是什么样的?
请求报文有4部分组成:
- 请求行
- 请求头部
- 空行
- 请求体
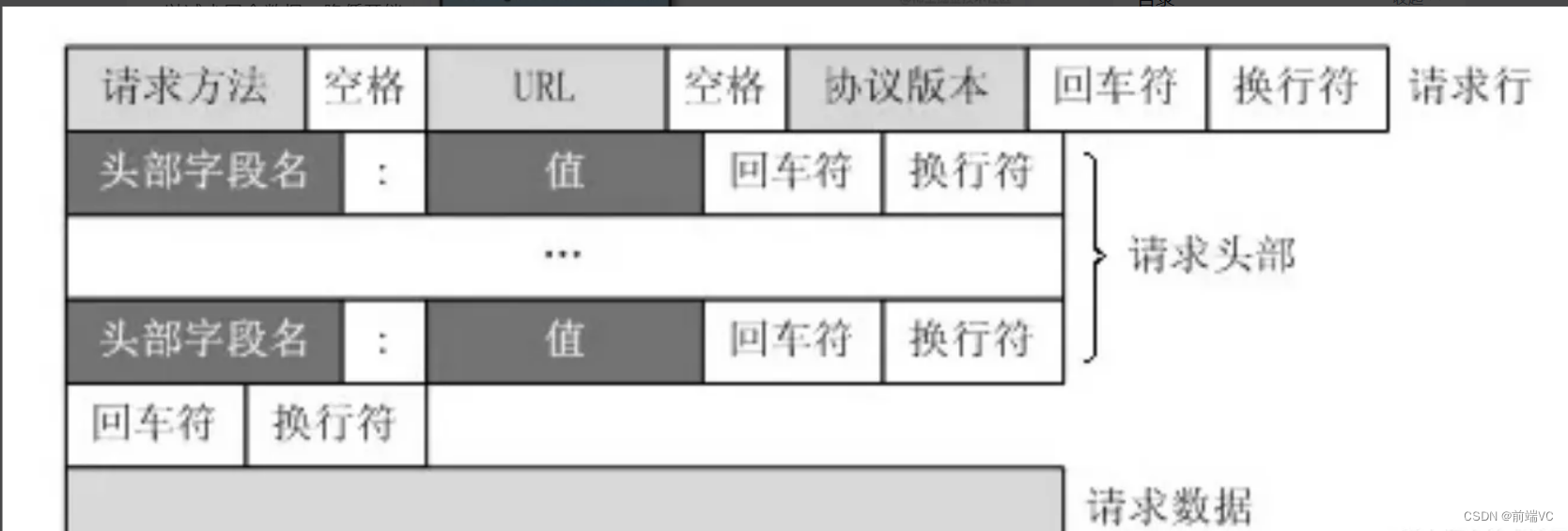
其中:
(1)请求行包括:请求方法字段,URL字段,HTTP协议版本字段。它们用空格分割。例如:GET/index.html HTTP/1.1。
(2)请求头部:请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分割
- User-Agent:产生请求的浏览器类型
- Accept:客户端可识别的内容类型列表
- Host:请求的主机名,允许多个域名同一个IP地址,即虚拟主机。
(3)请求体:post,put等请求携带的数据

8.HTTP响应报文是什么样?
响应报文有4部分组成:
- 响应行
- 响应头
- 空行
- 响应体
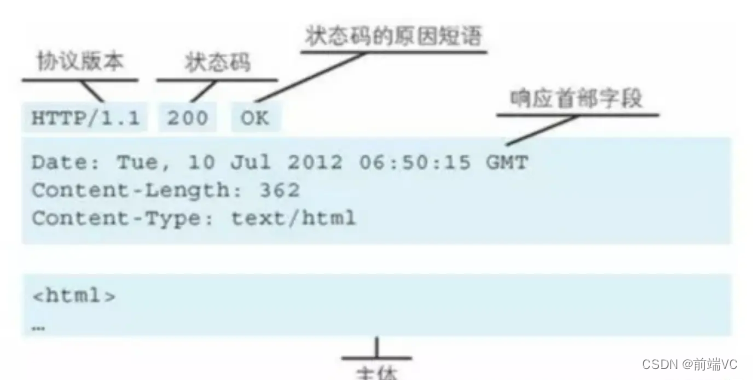
- 响应行:由网络协议版本,状态码和状态码的原因短语组成,例如:HTTP/1.1 200 OK
- 响应头:响应头部由响应首部组成
- 响应体:服务器响应的数据
9.HTTP协议的优点和缺点
HTTP是超文本传输协议,它定义了客户端和服务器之间交换报文的格式和方式,默认使用80端口。它使用TCP作为传输层协议,保证了数据传输的可靠性。
HTTP协议具有以下优点:
- 支持客户端/服务器模式
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于 HTTP 协议简单,使得 HTTP 服务器的程序规模小,因而通信速度很快。
- 无连接:无连接就是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接,采用这种方式可以节省传输时间。
- 无状态:HTTP 协议是无状态协议,这里的状态是指通信过程的上下文信息。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能会导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就比较快。
- 灵活:HTTP 允许传输任意类型的数据对象。正在传输的类型由 Content-Type 加以标记。
HTTP协议的缺点:
- 无状态: HTTP 是一个无状态的协议,HTTP 服务器不会保存关于客户的任何信息。
- 明文传输: 协议中的报文使用的是文本形式,这就直接暴露给外界,不安全。
- 不安全
(1)通信使用明文(不加密),内容可能会被窃听; (2)不验证通信方的身份,因此有可能遭遇伪装; (3)无法证明报文的完整性,所以有可能已遭篡改;
10.URL有哪些组成部分
以下面的URL为例:www.aspxfans.com:8080/news/index.…
从上面的URL可以看出,一个完整的URL包括以下几部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符;
- 域名部分:该URL的域名部分为“www.aspxfans.com” 一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口(HTTP协议默认端口是80,HTTPS协议默认端口是443);
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”;
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名;
-
锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
-
参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。