四、卷积网络的数据
上个系列我们详细讲解了pytorch框架下的全连接层神经网络DNN。本系列我们开始讲卷积神经网络CNN,Convolutional Neural Networks。
上一章我截取了鲁鹏老师课件里面的一张图,详细展示了和计算机视觉相关的领域,显而易见,这门学科是一门交叉学科,所以尽管扩展你的知识域吧,比如,摄像设备性能,成像原理,图像数据的生成与获取,视频特效,3D,图像复原、图像分割、识别、几何、光学、信号处理等技术,你都要多多少少了解一些。
1、卷积网络的数据结构
我们还是从数据开始聊起。前面讲DNN的时候,一直强调,你得把你的数据转化为二维表格数据,就是有行有列有标签,行表示样本,列表示特征。就是一条样本就是一行数据,多条样本就是多行数据。这样的数据你才能打包、分小批次喂入DNN网络进行学习和训练。也就是DNN适合一维和二维数据。一维就是一条样本,二维就是多条样本。
我们现在讲的CNN,和它匹配的数据结构则是三维和四维数据结构。就是说不管你是什么数据,你首先得把你的数据转化为三维或者四维才能用卷积神经网络。而图像数据天生就是三维数据,而且CNN天生也是为处理图像而诞生的,这点我们在讲架构时会再讲。所以说CNN的数据一般是图像数据。或者说CNN的一条样本就是一张图片数据。
如果你想喂入CNN一张图片,让数据在网络中正向传播一次,看看网络数据流是否调通,那你喂入的这条样本的数据结构就应该是三维的:(channels, height, width)这样的数据结构。
如果你想一次喂入CNN一个小批次的样本,也就是一次喂入好几张图片查看结果时,那你输入的数据结构就是四维的:(samples, channels, height, width)这样的数据结构。
如果你想一个个小批次的喂入CNN来训练网络,一般情况下我们还得进行数据预处理、数据增强,然后打包样本和标签,然后再分小批次,才能喂入CNN网络进行学习和训练。其中数据预处理和数据增强又涉及到非常非常多的细节点,后面会专门开启一个章节讲述。
如果你的数据压根就不是图像数据,你也想用卷积神经网络跑跑,也是可以滴。不管你通过什么手段,只要你最终把数据变形成三维或者四维,就可以用卷积网络。这部分内容涉及到的知识点也非常多,后面会单独写一个小标题来演示。
2、图像的相关概念
卷积网络主要处理的是图像数据,所以我们从图像聊起:
(1)图像是什么?
图:是物体反射或透射光的分布,是物体本身的固有的特征。
像:是人的视觉系统所接受的图在人脑中形成的印象或认识。
(2)模拟图像和数字图像
模拟图像是连续存储的数据,易受噪声干扰,人眼看起来不是很清晰。
数字图像是分级存储的数据,一般是分256级,即8位。
目前模拟图像基本全部都已经被数字图像替代了。
(3)图像的表示方法
二值图像: 每个像素点不是白色就是黑色;一个像素点只要一个bit位就能表示;用0或1表示每个像素点。
灰度图像: 图像只有一种颜色,比如图像可以是红色,可以是灰色,可以蓝色,可以是绿色等等,但不管什么颜色都是只有一种颜色。但是这一种颜色我们给它分成了256个等级,就是256个灰度级,可以理解成256个不同程度的明暗度。比如一张红色的灰度图像,像素值=0就是最暗,黑色,像素值=255就是最亮,就是最亮的红色。255中明暗度正好可以用8位也就是1字节byte表示。
彩色图像: 图像是彩色的,图像的每个像素点都是由三种颜色混合而成。这三种颜色是R G B, 每种颜色的取值都在0-255之间。每种颜色是一个通道,所以彩图一般都是3通道。少数图像是4通道,因为还有一个0-1之间的透明度。
图像的这种表示方法,就可以让我们进行图像处理。比如改变像素的值,就是改变图像的显示。比如改变通道,就是改变图像的色彩空间。比如切片,就是截取图像的特定区域。比如进行加减乘除、按位运算等,就是对图像进行数值运算。
3、图像数据的结构
二值图像的数据结构是一个二维数据结构(行,列),就是没有通道维度。其中行表示图像的高度,列表示图像的宽度。而且所有数字不是0就是1。当然如果你想喂入CNN,你就得升维到三维:(1, 行, 列)这样的结构。
灰度图像的数据结构也是一个二维数据结构,也是没有通道维度,其中行也是表示高度,列表示宽度,但是所有的数字是从0到255之间。同理,如果你想把这种类型的图片数据喂入DNN,你也是得升到三维。
彩色图像的数据结构一般是一个三维数据结构。三个维度分别是(高度height, 宽度width, 通道channels),前两个数值决定了图片的大小尺寸,后面的通道决定了图像的色彩效果。
img.shape, 返回:(667, 1000, 3), 说明表示这张图片的数据结构是,667行1000列3通道。就是有3个667行1000列数字。也就是每个通道在竖直方向上有667个像素点,水平方向上有1000个像素点。就是这张图片的尺寸大小。
第3个维度的3表示通道的意思,通道这个维度有时会放在高度和宽度之前。图像显示成什么颜色是由通道数决定的。单通道就是一张灰度图片,三通道和四通道就是一张彩色图片,而我们图像数据的通道一般就只有1通道、3通道和4通道这3种取值。而每个通道里面的数字则决定了图像的轮廓、线条、色彩、边缘等信息,基本就是决定了图像的显示内容。
img.dtype返回的'uint8'表示对象img的数据类型是uint8类型。这种类型数据的取值范围是0-255之间,不会小于0,也不会大于255。比如某个像素点的值是100,如果你给它加了200,那这个像素点就变成了300-255=45,就是这个像素点从100变成了45。就是这种数据结构有自己的一套运算规则,当然这样的运算规则主要是为了适应对图像进行处理的需求。
4、色彩空间
通道为什么只有3种取值?这就得说说色彩空间这个概念了:
世界本是无颜色的,我们人类看到的各种有色光只是特定波长的电磁波能够刺激人眼的锥体细胞,进而在人脑中形成颜色信号而已,实际上电磁波的波长域是非常广的,而我们人类只能感知很小一块区域,并且我们眼睛的光感细胞把特定波长的电磁波刺激信号传递给大脑,大脑反馈出不同的颜色。所以对于人类来 讲人类的色彩空间就是一个特定的空间。
但是如果对于打印机来讲,它的色彩空间和人类的就完全不一样,比如,在黑暗中,光越强,人类就看到越清晰的色彩,但是对于打印机来说某种颜色的墨汁越多,如果有多种颜色,那么它显示出来的色彩就是黑色的。
同理,对于显示器来说,不同显示器由于发光物理原理不同,比如液晶显示器显示屏上的色彩是通过控制电压的高低来控制每个像素的颜色的,而CRT显示器是靠发射电子束来打击荧幕上面的荧光粉来达到显示的,所以不同显示器,即使你输入的相同信号的数据,它显示出来的效果都是不一样的。
同理,很多不同摄像机,通过不同的原理捕捉出来的图像的色彩即使数据一样,但呈现给我们人眼的色彩都是不一样的。比如军事上的图片、气象上的图片、我们日常用的普通相机的图片,用我们人类肉眼看都是不一样的。
所以,为了让人眼看到的图片和打印机打印出来的图片、不同显示器显示出来的图片、不同相机拍摄出来的图片、不同图片显示软件显示出来的图片,人类看着是统一的,就是对人类来说,同一张照片的色准是一致的,这样我们人类看到的风景就和打印机里打印出来的风景是一样的、和显示器显示出来的风景是一致的、和看图软件比如微信传输后显示的图片是一致的,我们就需要定义不同的色彩空间。相反,比如一张图片里面有只猫,如果在某个色彩空间人类看这张照片是只白猫,假如经过微信这张照片传输到另一个人手机上,这张图片还是这张图片,即使这张图片的数据没有变化,但是另一个人的手机的图片显示是在另外一个色彩空间上,比如那个人把手机色彩空间调成护眼模式、夜间模式等等,就是不同的色彩空间,那这只猫很可能那个人的眼睛看到的就是一个别的颜色的猫,这样图片信息在人与人之间的传递中,由于介质————微信的彩色空间不一致而导致两个人收到不一致的信息,就是色准发生了变化。所以我们要定义色彩空间。也所以不同色彩空间需要能够进行相互转化。
下面介绍几种常见的色彩空间:
(1)RGB色彩空间是计算机中常见的基本颜色通道。RGB分别表示red, green,blue红绿蓝三种基本颜色。
(2)RGBA色彩空间是个四维通道:(红色,绿色,蓝色,透明度alpha)。透明度alpha的取值范围在0-1之间。当一个RGB像素加上透明度之后,色彩就会变得“透明”。所以RGBA可以提供更丰富的色彩样式,让图像的色彩变得更加绚丽,更加符合人类眼睛的审美维度。
(3)CMYK色彩空间是彩色打印机的色彩空间,是打印机认识的颜色。是由青色(Cyan)、品红(Magenta)、黄色(Yellow)和黑色(Black)构成,所以是四维通道,在图像数据结构中表示为(高度,宽度,4)这种形式。这是打印机的色彩世界,和我们人类不一样,我们人类看到的色彩更浓就更绚丽,但打印机是色彩更浓就是黑黑的一片,所以色彩空间就是一种标准而已。
(4)HSV(或HSL)色彩空间:H代表色相,S代表饱和度,V代表亮度。HSV颜色模式是除了RGB颜色模式之外的另一种流行的颜色模式。
以上几种色彩空间可以自由切换,都有对应的转化公式,但是会产生数据的轻微损失。
5、再次理解通道概念
在计算机世界里,用于构成其他颜色的基础色彩叫做'通道'。灰度通道是只有一种颜色的通道,而不是灰色的意思。灰度在计算机视觉中指的是明暗程度。
一般情况下,计算机世界中的五颜六色是由RGB ,red, green,blue红绿蓝三种基本颜色不同程度混合形成的颜色世界。这三种基本颜色的取值是[0, 255],0表示这种颜色的光的强度几乎为0,那就是黑色,就是没有光线,255表示这种颜色的光的强度最大,就是颜色最重。如果三种基本颜色的取值都相同那显示出来的颜色就是白色,取值越大白得越刺眼。当某个像素的值为(0,0,0)这个像素点就是黑色。当某个像素的值为(255,255,255)这个像素点就是白色。当某个像素的值为(255,0,0)这个像素点就是红色。当某个像素的值为(0,255,0)这个像素点就是绿色。当某个像素的值为(0,0,255)这个像素点就是蓝色。
6、图像数据可以用DNN跑嘛?
当然可以。DNN适合二维表格数据,行表示样本,列表示特征。所以你只要把你的图像数据转化成二维数据就能喂入DNN来跑跑试试效果。
如果你的图像是二值图像或者是灰度图像,那你只要把每张图像数据拉平变成一维数据,每张图像当作一个样本,就可以用DNN试效果了。
如果你的图像是三维彩色图像,那你也是得,按通道维度方向,先把图像数据拉平,然后按通道顺序拼接变成一维数据。就是一张图片是一个一维结构,多张图片就是二维结构,其中行表示一条样本。这样就可以用DNN跑了。后面讲架构时,我会单独写一个完整的小案例,展示线性分类器如何分类图片,那就是一个DNN处理图片数据的例子,到时大家可以再细细体会。
7、图像识别领域的常见数据集
全连接神经网络DNN在应对图像数据时,就会显得捉襟见肘,因为现在平平常常的一张图像也得1000x1000的尺寸,就是得有100万个像素点,而且再是三通道图像,就是300万个数字,如果我们之间把300万维的数据喂入神经网络,那神经网络立马就崩掉了,根本无法处理这个数据量。所以只要是图像数据集就必须用卷积网络,卷积网络模型才是真正的开始了用海量数据训练巨大的模型。
我们知道深度学习的三驾马车是数据、算法、算力。数据指的就是训练一个网络的数据,比如训练集验证集测试集;算法就是你的架构、模型、网络、优化算法等的统称;算力就是计算资源GPU等硬件资源。这里我们聊的是卷积网络的数据。
前面讲过计算机视觉任务,不同的任务要对应不同的标签。当你明确你的任务时,你就要开始着手建立你的数据集,而整理数据集是一件非常复杂、非常耗时、耗钱的一项工作。这个工作看似简单但其实是非常复杂和繁琐的。一个视觉项目从开始到交付,整理数据集有时耗时三分之二的时间和金钱都是正常现象。不管多么强大的模型,garbage in garbage out, 所以整理数据是一项非常非常重要的工作。你看计算机视觉领域的红人李飞飞教授,其他它出圈的不是她发明了多么强大的算法,而是她整理了鼎鼎大名的imagenet数据集,这个工作就足够她闪亮和荣耀了。这里之所以这么说是因为有一次,一个人让我给他整理视频数据集,他说他要训练一个电子人,但是一听啥数据都没有,要我现从网上找视频给他剪辑做,而且细节什么都没有,我都懵了。后来他们的技术和我沟通,也是不考虑获取数据集的难度和途径,只简单说了要什么什么样的数据,然后来一句,至于怎么获取就是你自己的事情了,他是训练模型的,没有义务去搜集数据集。我也一时无语。我想说作为模型训练的人,一定是那个最了解数据的人,如果你对你的数据都不是非常了解,你能训练出什么模型呢?任何一个优秀的模型或者效果好的模型,一定是在数据上做了非常非常多的处理和特征工程,甚至一些trick,样本的均衡性、样本的特点、有没有异常的样本、有没有特殊的样本、要识别的对象在图像中位置、尺寸大小、清晰度、光照、形变、角度、遮挡等等,各个细微处都要了然于胸,才能对症去调整模型,而不是不管三七二十一,觉得只要找到一个强大的模型,就可以闭着眼睛一股脑输出,至于输出就听天由命了,如果输出不好,就反过来把责任扣到标注人员身上。这种人就特别讨厌。
扯得有点远了,我只是想说你想用海量数据训练一个巨大的模型,你自己搜集数据集几乎是不可能的,搜集数据和给数据打标的成本是非常昂贵的。这里我们是学习,所以我们不可能花很多精力去整理一个数据集,我们一般都是自己生成一些toy data,或者使用一些pytorch框架中内置的一些数据集。这些数据集比较简单和经典。而且我们现在讲分类算法,所以也不太牵扯更复杂标签的数据集。下面给大家罗列几个常见的数据集。
(1)MNIST、FashionMNIST、SVHN、Omniglot、CIFAR10数据集
这五个数据集是可以从pytorch提供的相关接口下载的数据集,是最容易获取的数据集,所以先介绍这五个数据集:
MNIST:黑底白字的手写数字数据集。用来做识别任务,不能用于检测和分割,有10种标签类别,图像尺寸是28x28。
FashionMNIST:衣物用品数据集,用来做识别任务,不能用于检测和分割,也是有10种标签类别,图像尺寸是28x28。
SVHN:实拍街景数字数据集street view house number。是一个基于谷歌地球 (Google Earth)实拍的街景图中的门牌号图片,而制作而成的数字识别数据集,是数字识别和检测中比较困难的一个数据集,因为比较模糊。数据集支持识别、检测、无监督三种任务,不能用于分割。因为也是数字嘛,所以也是有10种标签类别,图像尺寸是32x32。
Omniglot:全语种手写字母数据集。数据集包含来⾃50个不同字⺟的1623个不同⼿写字符。共1623个类别,每个类别有20个样本,每个样本⼤⼩为28X28。这个数据集是专用于'一次性学习'one-shot learning。比如人脸识别的策略就是一次性学习。在‘一次性学习’策略中训练数据是一组组照片,标签只要是'是'或者'不是',就是标签只要是 标出这组照片是不是同一个人就可以,这种策略是一种二分类策略。在训练样本中是给算法两张照片,通过计算距离或计算相似性,判断两张照片是否是同一个人,输出的标签为“是/否、相似/不相似”,在这种策略中,测试集的样本也是两张照片,并且测试集的样本不需要出现在训练集中。现在实际落地的人脸识别项目都是基于一次性学习完成的。先扫描一下你的身份证得到一张身份证的图片,然后再用摄像头拍一张你的脸的照片,然后判断摄像头拍的照片和身份证照片是否是同一个人即可,至于这个人叫啥,是男是女,模型就不关心啦。Omniglot数据集就是专门训练一次性学习的数据集,只能用来做识别任务,不能用于检测和分割。
CIFAR10:十分类通用数据集。涵盖十类动物与交通工具。是最常用的教学图像,非常适合做识别任务。是彩色图片,每张图片的大小为32x32x3。
(2)展示一下FashionMNIST的获取过程:

同理,MNIST、SVHN、Omniglot、CIFAR10也是上面的方式就可以获取: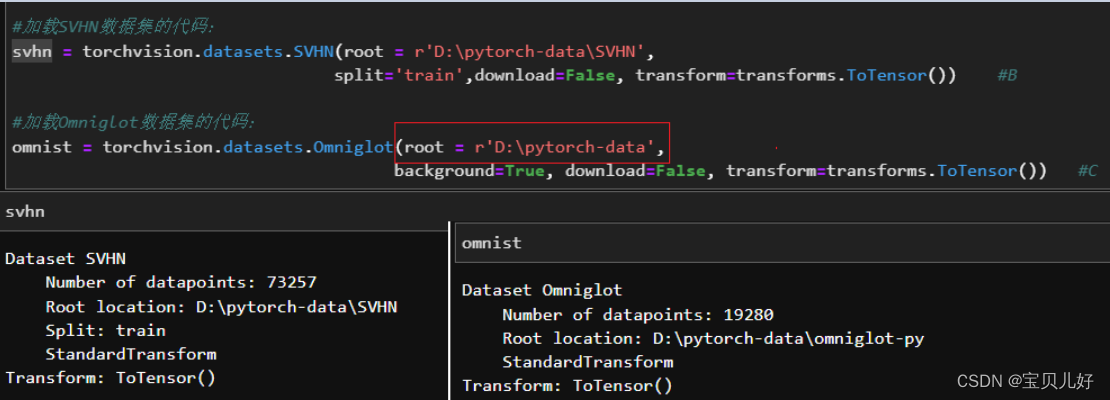
只是有些细节不太一样:
B:参数split='train'/'test'/'val', 表示你要加载的数据是训练集还是测试集还是验证集validation set
C:因为omnist数据集的发源地论文中是将训练集命名为background的,所以这里的参数background=True,就表示要加载的数据是训练集数据。background=False表示要加载的是测试集。
可见,不同数据集有不同的接口,而且不同的数据集它们各自的属性和方法也不同,如果你想知道这个数据集都有哪些属性可以调用,就必须要进入到数据集的源码进行查看。如果不想看源码,你就只能尝试用索引和循环去查看看行不行。
如何有效地阅读PyTorch的源代码? - 知乎
上面的数据集都是识别任务中的最基本、最简单的数据集,这些数据集只能用来测试一下我们模型的基准线,就是看看模型的效果。深度学习中的SOTA架构在这些数据集上一般都是99%以上的高分。如果你嫌这些数据集数据量太小、数据太简单,想使用一些更复杂的数据集上GPU上跑跑,那成本最低的就是竞赛数据集。比如ImageNet、VOC、LSUN等数据集。
(3)ImageNet、VOC、LSUN数据集的获取渠道
ILSVRC在2017年shutdown了识别任务, 将比赛转移到Kaggle上举办。据说ImageNet2019的数据集可以在Kaggle上可以免费下载,主要是用于检测任务。但是2017年之前的数据集现在是找不到了。而且据说下载时必须有个edu邮箱才可以,就是不允许商业应用,只能做研究使用。
VOC数据集是在PASCAL(pattern analysis, statistical modeling and computation learning 模式分析,统计建模和计算学习大赛)大赛中视觉对象分类中的数据集VOCSegmentation&Detection。
VOCSegmentation用于分割任务,2012年版本中,训练数据5717,测试数据5823,对象标签27450。
VOCDetection用于检测和分割任务,2012年版本中,训练数据1464,测试聚聚1449,分割标签6929。
在pytorch中支持从2007到2015年的5个版本的下载,因为它比较小,只有3.6G左右,但是非常不稳定。
LSUN数据集也是出于大规模场景理解挑战赛中的数据集,它是专门专注于景观的。数据集是用于识别任务的。不同景观场景的数据集大小不同,有的场景数据集大,比如超过40G,有的小,比如2G左右。全部的数据集有200G左右,下面给大家展示一个类别的下载流程: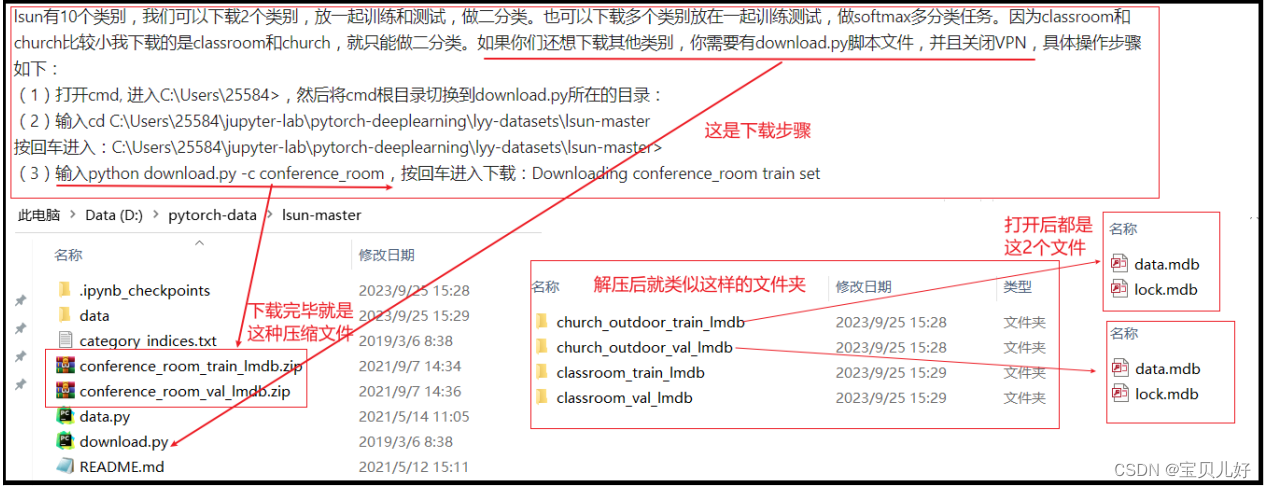
坑很多啊,即使你已经获取了这个数据集,想顺利读取也是非常费劲的,后面演示的的代码也是这个数据集。
上面的数据集除了LSUN勉强可以在cpu上跑一下,其他必须要有GPU,没有GPU计算资源的话,这些数据很难进行适当的训练proper training,你必须使用非常小的batch_size,但batch_size过小又会延长训练时间。如果训练一个ImageNet需要20个小时,那后面的调参、网格搜索等操作你就耗不起这个时间。如果非要使用ImageNet数据集,建议使用Colab等线上平台的大型GPU。
8、读取数据的相关函数和类
你想低成本获取深度学习中的数据集就已经非常不容易了。而当你不管从何种途径获取到数据后,一般获得的都是一个压缩文件,解压后你会看到它可能是:pt文件、mat文件、lmdb文件、excel、csv、txt文件,或者就直接是文件夹,文件夹里面都是一张张jpg或者png图片,而标签在另外一个文件里。这些不同的情况没有通用的读取方法,只能不同情况不同处理:
(1)如果你获得的是.mat文件。那是matlab的数据存储的标准格式,mat文件是标准的二进制文件,如果你用的C环境,那你可以直接读。但我们学深度学习一般都是python环境,你得用scipy库的loadmat函数来读取mat文件:
(2)如果获得的是.pt格式的文件。pt文件是PyTorch中保存模型和数据的文件格式。所以你可以使用PyTorch库中的torch.load()函数来加载.pt文件。
(3)如果你获得的是.mdb格式的文件。LMDB即Lightning Memory-Mapped Database Manager闪电内存映射数据库管理器,是一个基于btree的内存映射数据库。所以.mdb是一个数据库文件。
此时你要先: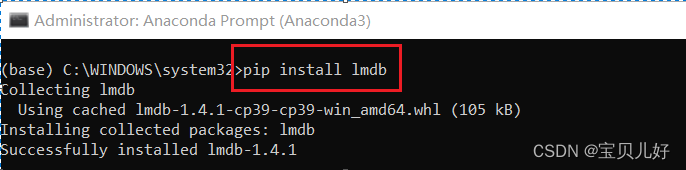
安装完毕后,你还得写一个专门用于读取mdb格式的类:

上面我自己写的一个读取lmdb文件的类。其实这个类我们在讲DNN的时候写过一个样例,思路都是一样的,继承Datasets部分和架构部分照葫芦画瓢即可。除此之外就是,你要非常了解如何用python处理lmdb文件,代码比较偏工程,但是如果看懂了也不难,都是固定流程。下面看看效果:
此外,前面我们讲过LSUN数据集是lmdb格式的数据集,pytorch中有专门针对这个数据集的接口,下面我演示下如何用pytorch中的接口读取: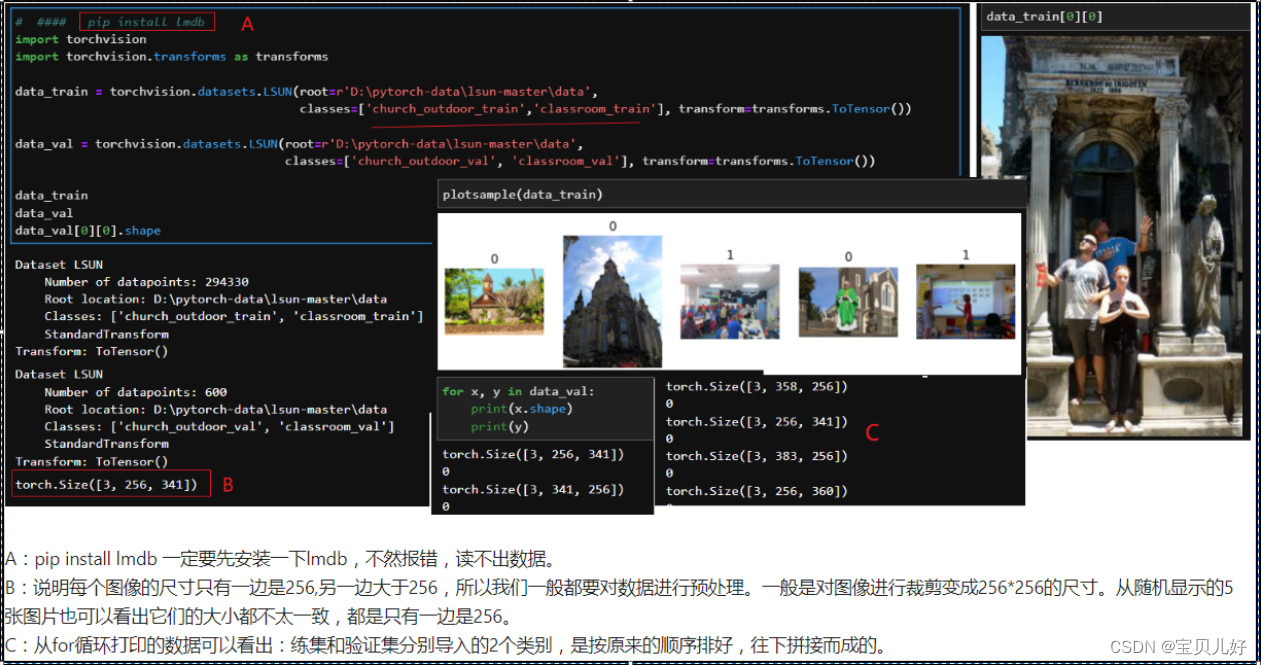
(4)
9、pytorch中分测试集和训练集、打包数据和标签、分小批次相关的类
待续。。。。