本课时的主题为数据结构与算法。行业里流行一种说法:程序 = 数据结构 + 算法。虽然有些夸张,但足以说明数据结构与算法的重要性。本课时重点讲解四个知识点:
-
从搜索树到 B+ 树,讲解与树有关的数据结构;
-
字符串匹配相关的题目;
-
算法面试经常考察的 TopK 问题;
-
算法题的几种常用解题方法。
数据结构知识点
首先看数据结构的知识点都有哪些,如下图所示。

-
队列和栈是经常使用的数据结构,需要了解它们的特点。队列是先进先出,栈是后进先出。
-
表,包括很多种,有占用连续空间的数组、用指针链接的单向和双向链表,首尾相接的循环链表、以及散列表,也叫哈希表。
-
图,在特定领域使用的比较多,例如路由算法中会经常使用到,图分为有向图、无向图及带权图,这部分需要掌握图的深度遍历和广度遍历算法,了解最短路径算法。
-
树的内容,树一般用作查找与排序的辅助结构,剩下两个部分都和树有关,一个是二叉树,一个是多叉树。
- 多叉树包括 B 树族,有 B 树、B+ 树、B* 树,比较适合用来做文件检索;另外一个是字典树,适合进行字符串的多模匹配。
- 二叉树包括平衡二叉树、红黑树、哈夫曼树,以及堆,适合用于进行数据查找和排序。这部分需要了解二叉树的构建、插入、删除操作的实现,需要掌握二叉树的前序、中序、后序遍历。
算法知识点
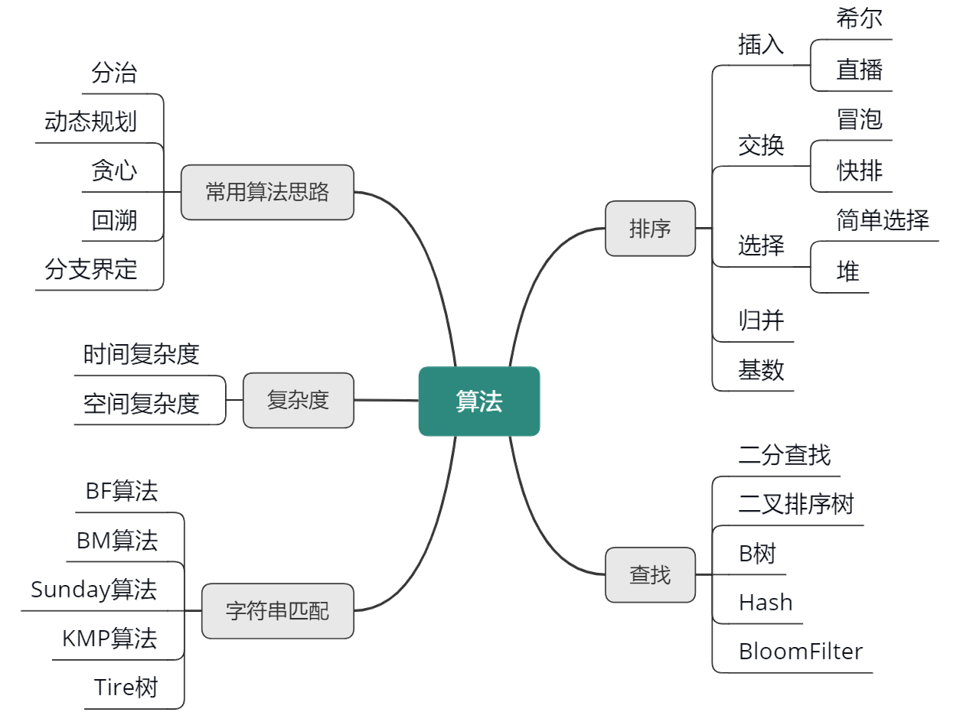
来看算法部分的知识点汇总,如下图所示。
-
算法题的常用解题方法。
-
复杂度是衡量算法好坏的标准之一,我们需要掌握计算算法时间复杂度和空间复杂度的方法。计算时间复杂度的方法一般是找到执行次数最多的语句,然后计算语句执行次数的数量级,最后用大写 O 来表示结果。
-
常用的字符串匹配算法,了解不同算法的匹配思路。
-
排序也是经常考察的知识点,排序算法分为插入、交换、选择、归并、基数五类,其中快速排序和堆排序考察的频率最高,要重点掌握,需要能够手写算法实现。
-
常用的查找算法,包括二分查找、二叉排序树、B 树、Hash、BloomFilter 等,需要了解它们的适用场景,例如二分查找适合小数量集内存查找,B 树适合文件索引,Hash 常数级的时间复杂度更适合对查找效率要求较高的场合,BloomFilter 适合对大数据集进行数据存在性过滤。
详解二叉搜索树
二叉搜索树
如下图所示,二叉搜索树满足这样的条件,每个节点包含一个值,每个节点至多有两个子树。每个节点左子树节点的值都小于自身的值,每个节点右子树节点的值都大于自身的值。

二叉树的查询时间复杂度是 log(N),但是随着不断的插入、删除节点,二叉树的树高可能会不断变大,当一个二叉搜索树所有节点都只有左子树或者都只有右子树时,其查找性能就退化成线性的了。
平衡二叉树
平衡二叉树可以解决上面这个问题,平衡二叉树保证每个节点左右子树的高度差的绝对值不超过 1,例如 AVL 树。AVL 树是严格的平衡二叉树,插入或删除数据时可能经常需要旋转来保持平衡,比较适合插入、删除比较少的场景。
红黑树
红黑树是一种更加实用的非严格的平衡二叉树。红黑树更关注局部平衡而非整体平衡,确保没有一条路径会比其他路径长出 2 倍,所以是接近平衡的,但减少了许多不必要的旋转操作,更加实用。前面提到过,Java 8 的 HashMap 中就应用了红黑树来解决散列冲突时的查找问题。TreeMap 也是通过红黑树来保证有序性的。
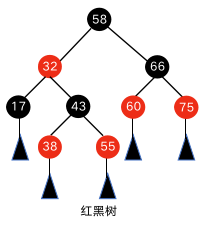
红黑树除了拥有二叉搜索树的特点外,还有以下规则,如下图所示。
-
每个节点不是红色就是黑色。
-
根节点是黑色。
-
每个叶子节点都是黑色的空节点,如图中的黑色三角。
-
红色节点的两个子节点都是黑色的。
-
任意节点到其叶节点的每条路径上,包含相同数量的黑色节点。
详解 B 树
B 树
B 树是一种多叉树,也叫多路搜索树。B 树中每个节点可以存储多个元素,非常适合用在文件索引上,可以有效减少磁盘 IO 次数。B 树中所有结点的最大子节点数称为 B 树的阶,如下图所示是一棵 3 阶 B 树,也叫 2-3 树。
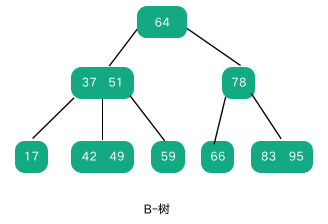
一个 m 阶 B 树有如下特点:
-
非叶节点最多有 m 棵子树;
-
根节点最少有两个子树,非根、非叶节点最少有 m/2 棵子树;
-
非叶子结点中保存的关键字个数,等于该节点子树个数−1,就是说一个节点如果有 3棵子树,那么其中必定包含 2 个关键字;
-
非叶子节点中的关键字大小有序,如上图中左边的节点中 37、51 两个元素就是有序的;
-
节点中每个关键字的左子树中的关键字都小于该关键字,右子树中的关键字都大于该关键字。如上图中关键字 51 的左子树有 42、49,都小于 51,右子树的节点有 59,大于51;
-
所有叶节点都在同一层。
B 树在查找时,从根结点开始,对结点内的有序的关键字序列进行二分查找,如果找到就结束,没有找到就进入查询关键字所属范围的子树进行查找,直到叶节点。
总结一下:
-
B 树的关键字分布在整颗树中,一个关键字只出现在一个节点中;
-
搜索可能在非叶节点停止;
-
B 树一般应用在文件系统。
B+ 树
下图是 B 树的一个变种,叫作 B+ 树。

B+ 树的定义与 B 树基本相同,除了下面这几个特点。
-
节点中的关键字与子树数目相同,比如节点中有 3 个关键字,那么就有 3 棵子树;
-
关键字对应的子树中的节点都大于或等于关键字,子树中包括关键字自身;
-
所有关键字都出现在叶子节点中;
-
所有叶子节点都有指向下一个叶子节点的指针。
与 B 树不同,B+ 树在搜索时不会在非叶子节点命中,一定会查询到叶子节点;另外一个,叶子节点相当于数据存储层,保存关键字对应的数据,而非叶子节点只保存关键字和指向叶节点的指针,不保存关键字对应的数据,所以同样数量关键字的非叶节点,B+ 树比 B 树要小很多。
B+ 树更适合索引系统,MySQL 数据库的索引就提供了 B+ 树实现。原因有三个:
-
由于叶节点之间有指针相连,B+ 树更适合范围检索;
-
由于非页节点只保存关键字和指针,同样大小非叶节点,B+ 树可以容纳更多的关键字,可以降低树高,查询时磁盘读写代价更低;
-
B+ 树的查询效率比较稳定。任何关键字的查找必须走一条从根结点到叶子结点的路,所有关键字查询的路径长度相同,效率相当。
最后可以简单了解,还有一种 B* 树的变种,在 B+ 树的非叶节点上,也增加了指向同一层下一个非叶节点的指针。
详解字符串匹配
字符串匹配问题
在面试时,字符串相关的问题经常作为算法考察题,下面来看字符串匹配的问题。先来了解一道常考的面试题:“判断给定字符串中的括号是否匹配”。
一般面试题目的描述都比较简单,在解答前,可以跟面试官进一步沟通一下题目要求和细节。以这道题为例,可以跟面试官确认括号的范围,是不是只考虑大中小括号就可以,包不包括尖括号;对函数的入参和返回值有没有什么样的要求;需不需要考虑针对大文件的操作等。
我们假定细化后本题的要求为:只考虑大中小括号;不考虑针对大文件的操作,以字符串作为入参,返回值为布尔类型;未出现括号也算作匹配的情况。那么,解题思路如下。
-
字符匹配问题可以考虑使用栈的特性来处理。
-
遇到左括号时入栈,遇到右括号时出栈对比,看是不是成对的括号。
-
当匹配完成时,如果栈内为空说明匹配,否则说明左括号多于右括号。
字符串代码
来看实际的实现代码,如下图所示。

按照上面的思路,需要对字符串进行遍历,所以首先要能确定栈操作的触发条件,就是定义好括号对,方便入栈和出栈匹配。这里要注意,编码实现时一定要注意编码风格与规范,例如变量命名必须要有明确意义,不要简单使用 a、b 这种没有明确意义的变量名。
我们首先定义了 brackets 的 map,key 是所有右括号,value 是对应的左括号,这样定义方便出栈时对比括号是否是成对。
再看一下匹配函数的逻辑。这里也要注意,作为工具类函数,要做好健壮性防御,首先要对输入参数进行验空。
然后我们定义一个保存字符类型的栈,开始对输入的字符串进行遍历。
如果当前字符是 brackets 中的值,也就是左括号,则入栈。这里要注意,map 的值查询方法是 O(N) 的,因为本题中括号种类很少,才使用这种方式让代码更简洁一些。如果当前字符不是左括号,在使用 containskey 来判断是不是右括号。如果是右括号,需要检验是否匹配,如果栈为空表示右括号多于左括号,如果栈不空,但出栈的左括号不匹配,这两种情况都说明字符串中的括号是不匹配的。
当遍历完成时,如果栈中没有多余的左括号,则匹配。
最后强调一下:编码题除了编程思路,一定要注意编程风格和细节点的处理。
字符串解题思路
接下来,总结一下字符串匹配类问题的解题技巧。
-
首先要认真审题,避免答偏。可以先确定是单模式匹配问题还是多模式匹配问题,命中条件是否有多个。
-
然后确定对算法时间复杂度或者内存占用是否有额外要求。
-
最后要明确期望的返回值是什么,比如存在有多个命中结果时,是返回第一个命中的,还是全部返回。
关于解题思路。
-
如果是单模式匹配问题,可以考虑使用 BM 或者 KMP 算法。
-
如果是多模匹配,可以考虑使用 Tire 树来解决。
-
在实现匹配算法时,可以考虑用前缀或者后缀匹配的方式来进行。
-
最后可以考虑是否能够通过栈、二叉树或者多叉树等数据结构来辅助解决。
建议了解一下常见的字符串单模、多模匹配算法的处理思路。
详解 TopK
TopK 问题
TopK 问题是在实际业务中经常出现的典型问题,例如微博的热门排行就属于 TopK 问题。
TopK 一般是要求在 N 个数的集合中找到最小或者最大的 K 个值,通常 N 都非常得大。TopK 可以通过排序的方式解决,但是时间复杂度较高,一般是 O(nk),这里我们来看看更加高效的方法。
如下图所示,首先取前 K 个元素建立一个大根堆,然后对剩下的 N-K 个元素进行遍历,如果小于堆顶的元素,则替换掉堆顶元素,然后调整堆。当全部遍历完成时,堆中的 K 个元素就是最小的 K 个值。

这个算法的时间复杂度是 N*logK。算法的优点是不用在内存中读入全部的元素,能够适用于非常大的数据集。
TopK 变种问题
TopK 变种的问题,就是从 N 个有序队列中,找到最小或者最大的 K 个值。这个问题的不同点在于,是对多个数据集进行排序。由于初始的数据集是有序的,因此不需要遍历完 N 个队列中所有的元素。因此,解题思路是如何减少要遍历的元素。
解题思路如下图所示。

-
第一步先用 N 个队列的队头元素,也就是每个队列的最小元素,组成一个有 K 个元素的小根堆。方式同 TopK 中的方法。
-
第二步获取堆顶值,也就是所有队列中最小的一个元素。
-
第三步用这个堆顶元素所在队列的下一个值放入堆顶,然后调整堆。
-
最后重复这个步骤直到获取够 K 个数。
这里还可以有个小优化就是第三步往堆顶放入新值时,跟堆的最大值进行一下比较,如果已经大于堆中最大值,就可以提前终止循环了。这个算法的时间复杂度是 (N+K-1)*logK,注意这里与队列的长度无关。
详解常用算法
算法的知识点比较多,提高算法解题能力需要适当刷题,但不能单纯依靠刷题来解决问题。需要掌握几种常用解题思路与方法,才能以不变应万变。这里讲一下:分治、动态规划、贪心、回溯和分支界定这五种常用的算法题解题方法,来看看它们分别适用于什么场景,如何应用。
分治法
分治法的思想是将一个难以直接解决的复杂问题或者大问题,分割成一些规模较小的相同问题,分而治之。比如快速排序、归并排序等都是应用了分治法。
适合使用分治法的场景需要满足三点要求:
-
可以分解为子问题;
-
子问题的解可以合并为原问题的解;
-
子问题之间没有关联。
使用分治法解决问题的一般步骤如下图表格所示。

-
第一步,要找到最小子问题的求解方法;
-
第二步,要找到合并子问题解的方法;
-
第三步,要找到递归终止条件。
动态规划法
动态规划法,与分治法类似,也是将问题分解为多个子问题。与分治法不同的是,子问题的解之间是有关联的。前一子问题的解,为后一子问题的求解提供了有用的信息。动态规划法依次解决各子问题,在求解每一个子问题时,列出所有局部解,通过决策保留那些有可能达到全局最优的局部解。最后一个子问题的解就是初始问题的解。
使用动态规划的场景需要也满足三点条件:
-
子问题的求解必须是按顺序进行的;
-
相邻的子问题之间有关联关系;
-
最后一个子问题的解就是初始问题的解。
使用动态规划解决问题时,如上图表格第二行。
-
第一步,先要分析最优解的性质;
-
第二步,递归的定义最优解;
-
第三步,记录不同阶段的最优值;
-
第四步,根据阶段最优解选择全局最优解
贪心算法
第三个贪心算法,因为它考虑的是局部的最优解,所以贪心算法不是对所有问题都能得到整体最优解。贪心算法的关键是贪心策略的选择。贪心策略必须具备无后效性,就是说某个状态以后的过程不会影响以前的状态,只与当前状态有关。
贪心算法使用的场景必须满足两点:
-
局部最优解能产生全局最优解;
-
就是刚才说的必须具备无后效性。
如下图所示,使用贪心算法解题的一般步骤为:
-
第一步,先分解为子问题;
-
第二步、按贪心策略计算每个子问题的局部最优解;
-
第三步,合并局部最优解。

回溯算法
回溯算法实际上是一种深度优先的搜索算法,按选优的条件向前搜索,当探索到某一步时,发现原先选择并不优或达不到目标,就退回上一步重新选择,这种走不通就退回再走的方法就是回溯法。
回溯法适用于能够深度优先搜索,并且需要获取解空间的所有解的场合,例如迷宫问题等。
如上图所示,回溯法一般的解题步骤为:
-
第一步先针对所给问题,确定问题的解空间;
-
第二步、确定结点的扩展搜索规则;
-
第三步,以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
分支界定法
最后是分支界定法,与回溯法的求解目标不同。回溯法的求解目标是找出满足约束条件的所有解,而分支界定法的求解目标则是找出满足约束条件的一个解。
分支界定法适用于广度优先搜索,并且获取解空间的任意解就可以的场合,例如求解整数规划问题。
如上图所示,分支界定法一般的解题步骤:
-
第一步先确定解的特征;
-
第二步在确定子节点搜索策略,例如是先入先出,还是先入后出;
-
第三步通过广度优先遍历寻找解。
考察点和加分项
考察点
以上是针对数据结构与算法内容划的重点。接下来,从面试官角度出发,总结相关的面试考察点:
-
了解基本数据结构及特点,例如数据结构中有哪些二叉树,这些树有哪些特点;
-
要熟练掌握表、栈、队列、树,深刻理解不同类型实现的使用场景,例如红黑树适合用来做搜索,B+ 树适合用来做索引;
-
要了解常用的搜索、排序算法,及复杂度和稳定性。特别是快速排序和堆排序的实现,要熟练掌握;
-
要了解常用的字符串处理算法,和处理的思路,例如BM算法使用后缀匹配进行字符串匹配;
-
要能够分析算法实现的复杂度,特别是时间复杂度,例如TopK问题的时间复杂度计算;
-
要了解五种常用的解题方法,解决问题的思路和解决哪类问题,以及解题的步骤。
加分项
要想在算法面试的相关题目获得面试官的加分,牢记下面几点:
-
能够将数据结构与实际使用场景结合,例如介绍红黑树时结合 TreeMap 的实现;介绍 B+ 树时结合 MySQL 中的索引实现等等;
-
能知道不同算法在业务场景中有哪些应用,例如 TopK 算法在热门排序中的应用;
-
面对模糊的题目能主动沟通确认条件和边界,例如前面介绍的括号匹配问题时列举的那些细节点,都可以跟面试官再次确认;
-
在书写算法代码前,先讲一下解题思路,不要一上来埋头就写。一般解题思路存在问题时,面试官都会适当进行引导;
-
能够发现解答中的一些问题,给出改进的思路。比如面试时由于时间关系,大家可能都会选择比较保守的解题思路,不一定就是最优解,这时可以在解答后,指出当前算法存在的一些问题,以及改进的思路。比如可以考虑使用多线程的方式来提高求解性能。
真题汇总
最后来看下常见的面试真题,第一部分总结如下。

-
第 1、2 题都是基础算法,必须要牢牢掌握,一些题目要记住递归与非递归的实现,例如树的遍历、快速排序等;
-
类似第 5 题这样的对使用内存进行限制的题目,要考虑使用分治思想进行分解处理;
-
第 6 题数组去重,可以有排序和 Hash 两种思路。
第二部分真题总结如下。

-
第 9 题成语接龙,可以考虑使用深度优先搜索解决;
-
第 10 题寻找两节点公共祖先,可以考虑通过递归与非递归两种方式实现。
本课时完成了基础知识的学习模块,下一课时会开始讲解应用知识模块,下一课时的主题常用工具集。
