对于RT1170来说,它有两个内核,那两个内核如何通信呢?我们可以通过MU消息单元详解来实现这些功能,但它一次只能传输32位的数据。我们知道CM7和CM4有一些公共的内存可以访问,那我们可不可以借助这些公共的内存来实现数据的交互呢?答案当然是可以的,但是双核访问这些内存就需要进行互斥。
FreeRTOS实现一个了消息缓冲区(Message Buffer),就是用来实现这个功能,这篇文章就来介绍一下。
文章目录
1 内存分配
前面我们说了,我们采用共享内存来实现消息缓冲区,那一定需要一块同时能被CM7和CM4访问的内存。所以先来看看CM7和CM4共有的内存:
| RAM | Access address for CM7 | Access address for CM4 | Size |
|---|---|---|---|
| OCRAM M4 | 0x2020_0000 | 0x1FFE_0000 | 128KB |
| OCRAM M4 | 0x2022_0000 | 0x2000_0000 | 128 KB |
| OCRAM M7 | 0x2038_0000 | Same as CM7 | 128KB |
| OCRAM M7 ECC | 0x2036_0000 | Same as CM7 | 128KB |
| OCRAM1 | 0x2024_0000 | Same as CM7 | 512 KB |
| OCRAM2 | 0x202C_0000 | Same as CM7 | 512 KB |
| OCRAM1_ECC | 0x2034_0000 | Same as CM7 | 64 KB |
| OCRAM2_ECC | 0x2035_0000 | Same as CM7 | 64 KB |
- 当然FlexSPI1和FlexSPI2接的Flash、SEMC接的SDRAM所映射的内存在双核间也是共享的。
这里我们使用的是OCRAM2作为我们的共享内存,我们需要在链接脚本中声明一个段(不同编译器实现不同,所以这里不做演示),然后这个段链接到OCRAM2中。
这样就可以在程序中使用__attribute__((section("")))将特定的变量定义到OCRAM2中。
2 消息缓冲区使用实例
- 参考例程:
evkmimxrt1170_freertos_message_buffers_cm7/cm4
这里就不把所有的函数介绍一遍了,仅仅把我们例程中使用到的函数介绍一遍,关于消息缓冲区所有函数的用法参考RTOS-message-buffer-API
2.1 创建消息缓冲区
首先我们需要创建一个消息缓冲区,下面来看一下如何实现。
2.1.1 xMessageBufferCreateStatic
我们可以调用xMessageBufferCreate或xMessageBufferCreateStatic来创建一个消息缓冲区,对于前者来说使用动态内存分配空间,一般就是从FreeRTOS的堆中分配空间,但我们不太可能将堆分配到一个双核都能访问的内存中,这样太浪费了。所以这里我们通过xMessageBufferCreateStatic使用静态的内存创建消息缓冲区。
消息缓冲区在完成发送和接收操作时可以执行一个回调函数。xMessageBufferCreateStatic()创建的消息缓冲区在发送/接收完成后会分别调用发送完成回调函数sbSEND_COMPLETED()和接收完成回调函数sbRECEIVE_COMPLETED(),用户可以重写这两个函数。
- 如果有多个消息缓冲区,也是调用同一个回调,如果想每个消息缓冲区有自己的回调函数,可以使用
xMessageBufferCreateStaticWithCallback创建消息缓冲区。
MessageBufferHandle_t xMessageBufferCreateStatic(
size_t xBufferSizeBytes,
uint8_t *pucMessageBufferStorageArea,
StaticMessageBuffer_t *pxStaticMessageBuffer );
xBufferSizeBytes:缓冲区的大小(字节)。当消息写入消息缓冲区时, 还会额外写入4字节(32位架构)存储消息的长度。实际上消息缓冲区是一个循环缓冲区,所以会浪费1字节的空间pucMessageBufferStorageArea:指向一个大小至少为xBufferSizeBytes + 1的数组pxStaticMessageBuffer:用于保存消息缓冲区的数据结构体- 返回值:成功将返回消息缓冲区的句柄,否则返回NULL
2.1.2 CM7创建消息缓冲区
现在来分析一下在SDK中,主核CM7是如何创建消息缓冲区的。
1、声明一块内存来存储相关的数据结构
这里使用OCRAM2来作为CM7和CM4共有的内存,.noinit.$rpmsg_sh_mem段在链接脚本中已经链接到了OCRAM2中,所以下面就用__attribute__((section(".noinit.$rpmsg_sh_mem")))将长度为6144的rpmsg_sh_mem数组定义到了OCRAM2中。
#define SH_MEM_TOTAL_SIZE (6144U)
unsigned char rpmsg_sh_mem[SH_MEM_TOTAL_SIZE] __attribute__((section(".noinit.$rpmsg_sh_mem")));
#define APP_SH_MEM_BASE (uint32_t) & rpmsg_sh_mem
2、声明用于消息缓冲区的变量的内存
#define APP_SH_MEM_PRIMARY_TO_SECONDARY_MB_OFFSET (0x0u)
#define APP_SH_MEM_PRIMARY_TO_SECONDARY_MB_STRUCT_OFFSET (0x50u)
#define APP_SH_MEM_PRIMARY_TO_SECONDARY_BUF_STORAGE_OFFSET (0x100u)
#define xPrimaryToSecondaryMessageBuffer \
(*(MessageBufferHandle_t *)(APP_SH_MEM_BASE + APP_SH_MEM_PRIMARY_TO_SECONDARY_MB_OFFSET))
#define xPrimaryToSecondaryMessageBufferStruct \
(*(StaticStreamBuffer_t *)(APP_SH_MEM_BASE + APP_SH_MEM_PRIMARY_TO_SECONDARY_MB_STRUCT_OFFSET))
#define ucPrimaryToSecondaryBufferStorage \
(*(uint8_t *)(APP_SH_MEM_BASE + APP_SH_MEM_PRIMARY_TO_SECONDARY_BUF_STORAGE_OFFSET))
上面实际上是声明了三个变量:
| 变量 | 相对rpmsg_sh_mem的偏移 |
|---|---|
| xPrimaryToSecondaryMessageBuffer | 0 |
| xPrimaryToSecondaryMessageBufferStruct | 0x50 |
| ucPrimaryToSecondaryBufferStorage | 0x100 |
这些变量在内存中的位置需要固定,因为CM4要知道它在哪才能与CM4进行通信。当然你完全可以使用MU发送这些地址给CM4,但这样就有点麻烦。
3、创建消息缓冲区
#define APP_MESSAGE_BUFFER_SIZE (24U)
xPrimaryToSecondaryMessageBuffer = xMessageBufferCreateStatic(
APP_MESSAGE_BUFFER_SIZE,
&ucPrimaryToSecondaryBufferStorage,
&xPrimaryToSecondaryMessageBufferStruct);
这里就创建了一个消息缓冲区,句柄为xPrimaryToSecondaryMessageBuffer,缓冲区为ucPrimaryToSecondaryBufferStorage,缓冲区大小为APP_MESSAGE_BUFFER_SIZE,消息缓冲区相关结构体为xPrimaryToSecondaryMessageBufferStruct。
2.1.3 CM4创建消息缓冲区
下面再来看一下CM4中的消息缓冲区的创建。和CM7一样,CM4也声明了同一块内存:
#define SH_MEM_TOTAL_SIZE (6144U)
unsigned char rpmsg_sh_mem[SH_MEM_TOTAL_SIZE] __attribute__((section(".noinit.$rpmsg_sh_mem")));
#define APP_SH_MEM_BASE (uint32_t) & rpmsg_sh_mem
注意,这里CM4和CM7都声明了rpmsg_sh_mem到OCRAM2中,但是实际上两个核各自都不知道对方的变量声明在这里了。如果没有其它变量链接到OCRAM2的话,rpmsg_sh_mem默认就链接到OCRAM2的起始处,所以CM4和CM7的这个rpmsg_sh_mem的内存是相对应的。
接下来则是定义消息缓冲区的变量:
#define APP_SH_MEM_SECONDARY_TO_PRIMARY_MB_OFFSET (0x4u)
#define APP_SH_MEM_SECONDARY_TO_PRIMARY_MB_STRUCT_OFFSET (0xA0u)
#define APP_SH_MEM_SECONDARY_TO_PRIMARY_BUF_STORAGE_OFFSET (0x200u)
#define xSecondaryToPrimaryMessageBuffer \
(*(MessageBufferHandle_t *)(APP_SH_MEM_BASE + APP_SH_MEM_SECONDARY_TO_PRIMARY_MB_OFFSET))
#define xSecondaryToPrimaryMessageBufferStruct \
(*(StaticStreamBuffer_t *)(APP_SH_MEM_BASE + APP_SH_MEM_SECONDARY_TO_PRIMARY_MB_STRUCT_OFFSET))
#define ucSecondaryToPrimaryBufferStorage \
(*(uint8_t *)(APP_SH_MEM_BASE + APP_SH_MEM_SECONDARY_TO_PRIMARY_BUF_STORAGE_OFFSET))
同样地用上面的变量来创建消息缓冲区:
#define APP_MESSAGE_BUFFER_SIZE (24U)
xSecondaryToPrimaryMessageBuffer = xMessageBufferCreateStatic(
APP_MESSAGE_BUFFER_SIZE,
&ucSecondaryToPrimaryBufferStorage,
&xSecondaryToPrimaryMessageBufferStruct);
句柄为xSecondaryToPrimaryMessageBuffer,缓冲区为ucSecondaryToPrimaryBufferStorage,缓冲区大小为APP_MESSAGE_BUFFER_SIZE,消息缓冲区相关结构体为xSecondaryToPrimaryMessageBufferStruct。
2.1.4 内存分配
我们要使用消息缓冲区实现双核的通信的话,核与核之间应该要知道对方的消息缓冲区的数据结构的位置。所以这里我们就手动来分配这些数据结构在内存中的位置。这里来总结一下这些变量的内存分配:

我们可以看到SDK中这样手动地分配内存有些麻烦,还要计算每个结构体、缓冲区的大小,中间还浪费了一些空间。所以我建议定义一个结构体,然后在结构体中定义上面这些变量,最后将结构体指针指向0x202C0000就行了。
2.2 双核启动同步
在上一节多核管理之MCMGR源码分析详解,详细分析了上电后双核的同步流程,在这个例程中也使用了一样的同步流程。除此之外,对于CM7来说,还注册了一个kMCMGR_RemoteApplicationEvent事件:
MCMGR_RegisterEvent(kMCMGR_RemoteApplicationEvent, RemoteAppReadyEventHandler, (void *)&RemoteAppReadyEventData);
其中:
static volatile uint16_t RemoteAppReadyEventData = 0U;
static void RemoteAppReadyEventHandler(uint16_t eventData, void *context)
{
uint16_t *data = (uint16_t *)context;
*data = eventData;
}
也就是说CM4可以通过kMCMGR_RemoteApplicationEvent事件来更改RemoteAppReadyEventData的值。在CM7调用MCMGR_StartCore启动M4核后就在等待RemoteAppReadyEventData更改为APP_READY_EVENT_DATA。
while (APP_READY_EVENT_DATA != RemoteAppReadyEventData){};
现在来看看CM4的代码,在上一节分析的MCMGR_GetStartupData后,注册了事件类型为kMCMGR_FreeRtosMessageBuffersEvent的事件,然后就向CM7发送了刚刚说的APP_READY_EVENT_DATA。
MCMGR_RegisterEvent(kMCMGR_FreeRtosMessageBuffersEvent, FreeRtosMessageBuffersEventHandler, ((void *)0));
(void)MCMGR_TriggerEvent(kMCMGR_RemoteApplicationEvent, APP_READY_EVENT_DATA);
回到CM7这边,在CM7等待到这个事件后,同样注册了事件类型为kMCMGR_FreeRtosMessageBuffersEvent的事件:
MCMGR_RegisterEvent(kMCMGR_FreeRtosMessageBuffersEvent, FreeRtosMessageBuffersEventHandler, ((void *)0));
CM7和CM4的FreeRtosMessageBuffersEventHandler回调实现也一样:
static void FreeRtosMessageBuffersEventHandler(uint16_t eventData, void *context)
{
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
if (APP_MESSAGE_BUFFER_EVENT_DATA == eventData)
{
(void)xMessageBufferSendCompletedFromISR(xSecondaryToPrimaryMessageBuffer, &xHigherPriorityTaskWoken);
}
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
等会再来研究一下这个回调函数的作用。代码执行到现在,双核之间就可以进行数据交互了。
2.3 双核数据交互
2.3.1 xMessageBufferSend
xMessageBufferSend用来将数据发送到消息缓冲区。数据将被并复制到消息缓冲区中,所以数据长度不能超过消息缓冲区的大小。
size_t xMessageBufferSend( MessageBufferHandle_t xMessageBuffer,
const void *pvTxData,
size_t xDataLengthBytes,
TickType_t xTicksToWait );
xMessageBuffer:数据发送到的消息缓冲区的句柄pvTxData:数据的指针xDataLengthBytes:数据长度。除了数据外,还会额外写入sizeof(size_t)字节(在32位机上是4字节)用来存储消息的长度xTicksToWait:如果调用消息缓冲区没有足够的空间,则xTicksToWait表示应阻塞等待消息缓冲区有足够空间的最长时间返回值:写入消息缓冲区的字节数。若超时则返回零
2.3.2 xMessageBufferReceive
用来从消息缓冲区接收数据,数据从缓冲区中复制出来。
size_t xMessageBufferReceive( MessageBufferHandle_t xMessageBuffer,
void *pvRxData,
size_t xBufferLengthBytes,
TickType_t xTicksToWait );
xMessageBuffer:接收数据的消息缓冲区的句柄pvRxData:接收数据的buffer,数据将从消息缓冲区中拷贝到buffer中xBufferLengthBytes:pvRxData的长度。如果空间不足,那么数据将保留在消息缓冲区中,并且将返回0xTicksToWait:任务保持在阻塞状态等待消息的最长时间返回值:从消息缓冲区读取数据的长度(字节)。如果数据长度大于xBufferLengthBytes,则消息将保留在消息缓冲区中,同时返回0
2.3.3 双核交互例子
下面双核就可以使用消息缓冲区进行数据交互了。这里我们一次发送一个THE_MESSAGE结构体,双核都声明一个THE_MESSAGE msg变量
typedef struct the_message
{
uint32_t DATA;
} THE_MESSAGE, *THE_MESSAGE_PTR;
volatile THE_MESSAGE msg = {0};
下面来看看双核的数据交互代码,实际上就是CM7发送一个结构体,结构体里的DATA初始值为0,在CM4收到后加一,然后回给CM7,CM7收到后再加一发给CM4,如此往复…
CM7
msg.DATA = 0U;
xMessageBufferSend(xPrimaryToSecondaryMessageBuffer, (void *)&msg, sizeof(THE_MESSAGE), 0);
while (msg.DATA <= 100U)
{
xReceivedBytes =
xMessageBufferReceive(xSecondaryToPrimaryMessageBuffer, (void *)&msg, sizeof(THE_MESSAGE), portMAX_DELAY);
PRINTF("Primary core received a msg\r\n");
PRINTF("Message: Size=%x, DATA = %i\r\n", xReceivedBytes, msg.DATA);
msg.DATA++;
xMessageBufferSend(xPrimaryToSecondaryMessageBuffer, (void *)&msg, sizeof(THE_MESSAGE), 0);
}
CM4
while (msg.DATA <= 100U)
{
PRINTF("Waiting for ping...\r\n");
xMessageBufferReceive(xPrimaryToSecondaryMessageBuffer, (void *)&msg, sizeof(THE_MESSAGE), portMAX_DELAY);
msg.DATA++;
PRINTF("Sending pong...\r\n");
xMessageBufferSend(xSecondaryToPrimaryMessageBuffer, (void *)&msg, sizeof(THE_MESSAGE), 0);
}
这里我们可以看出:xMessageBufferSend是发送到自己的缓冲区句柄中,而xMessageBufferReceive则是从对方的缓冲区句柄中接收。
2.4 发送完成回调函数
前面我们有提到,在发送/接收完成后会分别调用发送完成回调函数sbSEND_COMPLETED()和接收完成回调函数sbRECEIVE_COMPLETED()。另外还有前面双核都注册的kMCMGR_FreeRtosMessageBuffersEvent事件的FreeRtosMessageBuffersEventHandler回调函数也没有看到在哪里使用。
在xMessageBufferSend的最后,会调用发送完成函数sbSEND_COMPLETED。在本例中我们没有使用到接收回调函数。那这里以CM7给CM4发送消息为例(CM4发消息给CM7同理),来看看发送回调函数的实现,下面是CM7的发送完成回调:
#define sbSEND_COMPLETED( pxStreamBuffer ) vGeneratePrimaryToSecondaryInterrupt( pxStreamBuffer )
#define APP_MESSAGE_BUFFER_EVENT_DATA (1U)
void vGeneratePrimaryToSecondaryInterrupt(void *xUpdatedMessageBuffer)
{
/* Trigger the inter-core interrupt using the MCMGR component.
Pass the APP_MESSAGE_BUFFER_EVENT_DATA as data that accompany
the kMCMGR_FreeRtosMessageBuffersEvent event. */
(void)MCMGR_TriggerEventForce(kMCMGR_FreeRtosMessageBuffersEvent, APP_MESSAGE_BUFFER_EVENT_DATA);
}
也就是说,在发送完一个消息后,将向CM4发送一个kMCMGR_FreeRtosMessageBuffersEvent事件。
现在回到CM4的代码,由于CM4注册了这个事件的回调函数:
MCMGR_RegisterEvent(kMCMGR_FreeRtosMessageBuffersEvent, FreeRtosMessageBuffersEventHandler, ((void *)0));
所以在CM4在收到这个事件后,会进入FreeRtosMessageBuffersEventHandler中:
#define APP_MESSAGE_BUFFER_EVENT_DATA (1U)
static void FreeRtosMessageBuffersEventHandler(uint16_t eventData, void *context)
{
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
if (APP_MESSAGE_BUFFER_EVENT_DATA == eventData)
{
(void)xMessageBufferSendCompletedFromISR(xPrimaryToSecondaryMessageBuffer, &xHigherPriorityTaskWoken);
}
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
首先我们发现这里面用的函数是FreeRTOS的中断函数,这是因为注册的事件回调会在MU的接收满中断中调用,具体可以参考我的上一篇文章:MCMGR源码分析详解。对于portYIELD_FROM_ISR函数也不分析了,在中断中调用FreeRTOS相关函数最后都需要主动调度一下任务。
现在我们思考一下:在双核中,另一核的消息缓冲区如何知道对方发来了消息呢?总不能一直轮询消息缓冲区的内存
- 需要用户主动调用
xMessageBufferSendCompletedFromISR来实现。
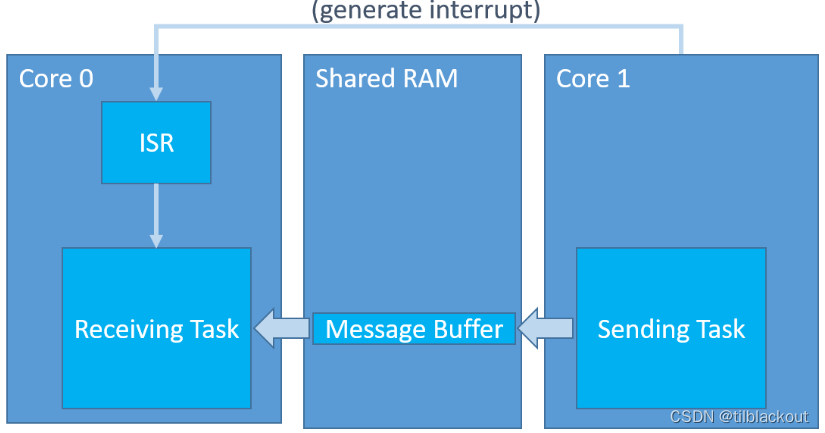
所以这里我们就明白了,在CM7发送给CM4消息后,使用MU通信单元向CM4发送了一个事件,参数为APP_MESSAGE_BUFFER_EVENT_DATA,在CM4收到这个事件后,则调用xMessageBufferSendCompletedFromISR通知对应的消息缓冲区来接收数据,这样阻塞等待的xMessageBufferReceive函数就会返回了。
而这里的eventData我们可以设置为不同的值,在有多个消息缓冲区的情况下,提醒不同的消息缓冲区(消费者)。
2.5 空闲任务、定时器和用户任务的内存分配
由于前面创建消息缓冲区的函数xMessageBufferCreateStatic需要使能静态内存分配的宏定义:
#define configSUPPORT_STATIC_ALLOCATION 1
假设我们还关闭了动态分配内存的宏定义:
#define configSUPPORT_DYNAMIC_ALLOCATION 0
这样对于程序中的所有任务都需要我们自行分配内存。那我们知道FreeRTOS中会创建一个空闲任务,所以空闲任务的内存需要我们手动分配,在FreeRTOS中,我们需要实现vApplicationGetIdleTaskMemory函数来给空闲任务分配内存,这里就直接在函数中声明一个static内存分配给空闲任务:
void vApplicationGetIdleTaskMemory(StaticTask_t **ppxIdleTaskTCBBuffer,
StackType_t **ppxIdleTaskStackBuffer,
uint32_t *pulIdleTaskStackSize)
{
/* If the buffers to be provided to the Idle task are declared inside this
function then they must be declared static - otherwise they will be allocated on
the stack and so not exists after this function exits. */
static StaticTask_t xIdleTaskTCB;
static StackType_t uxIdleTaskStack[configMINIMAL_STACK_SIZE];
/* configUSE_STATIC_ALLOCATION is set to 1, so the application must provide
an implementation of vApplicationGetIdleTaskMemory() to provide the memory
that is used by the Idle task.
www.freertos.org/a00110.html#configSUPPORT_STATIC_ALLOCATION */
/* Pass out a pointer to the StaticTask_t structure in which the Idle task's
state will be stored. */
*ppxIdleTaskTCBBuffer = &xIdleTaskTCB;
/* Pass out the array that will be used as the Idle task's stack. */
*ppxIdleTaskStackBuffer = uxIdleTaskStack;
/* Pass out the size of the array pointed to by *ppxIdleTaskStackBuffer.
Note that, as the array is necessarily of type StackType_t,
configMINIMAL_STACK_SIZE is specified in words, not bytes. */
*pulIdleTaskStackSize = configMINIMAL_STACK_SIZE;
}
同理,如果打开了定时器的话,也需要自行实现定时器的内存分配:
void vApplicationGetTimerTaskMemory(StaticTask_t **ppxTimerTaskTCBBuffer,
StackType_t **ppxTimerTaskStackBuffer,
uint32_t *pulTimerTaskStackSize)
{
/* If the buffers to be provided to the Timer task are declared inside this
function then they must be declared static - otherwise they will be allocated on
the stack and so not exists after this function exits. */
static StaticTask_t xTimerTaskTCB;
static StackType_t uxTimerTaskStack[configTIMER_TASK_STACK_DEPTH];
/* Pass out a pointer to the StaticTask_t structure in which the Timer
task's state will be stored. */
*ppxTimerTaskTCBBuffer = &xTimerTaskTCB;
/* Pass out the array that will be used as the Timer task's stack. */
*ppxTimerTaskStackBuffer = uxTimerTaskStack;
/* Pass out the size of the array pointed to by *ppxTimerTaskStackBuffer.
Note that, as the array is necessarily of type StackType_t,
configTIMER_TASK_STACK_DEPTH is specified in words, not bytes. */
*pulTimerTaskStackSize = configTIMER_TASK_STACK_DEPTH;
}
最后,用户创建的任务一样要静态分配内存,如下:
static StaticTask_t xTaskBuffer;
static StackType_t xStack[APP_TASK_STACK_SIZE];
xTaskCreateStatic(app_task, "APP_TASK", APP_TASK_STACK_SIZE, NULL, tskIDLE_PRIORITY + 1U, xStack, &xTaskBuffer);
当然,最后还是建议把两个宏定义都打开:
#define configSUPPORT_STATIC_ALLOCATION 1
#define configSUPPORT_DYNAMIC_ALLOCATION 1
毕竟我们程序中大概率还会用到pvPortMalloc和vPortFree函数。