一、ZooKeeper 的核心功能
ZooKeeper 是一个广泛使用的开源分布式协调服务框架,它在确保数据一致性方面表现出色,同时也可以作为一个轻量级的分布式存储系统。它特别适合用来存储那些需要多个系统共享的配置信息、集群的元数据等。ZooKeeper 提供了持久节点和临时节点两种类型,其中临时节点的功能在结合了 Watcher 机制后显得尤为强大。当一个客户端与 ZooKeeper 的连接断开,它所创建的临时节点将会自动删除,同时,那些订阅了节点状态变更通知的客户端将会及时接收到相关通知。这种机制使得 ZooKeeper 在处理分布式系统中的协调任务时非常高效。
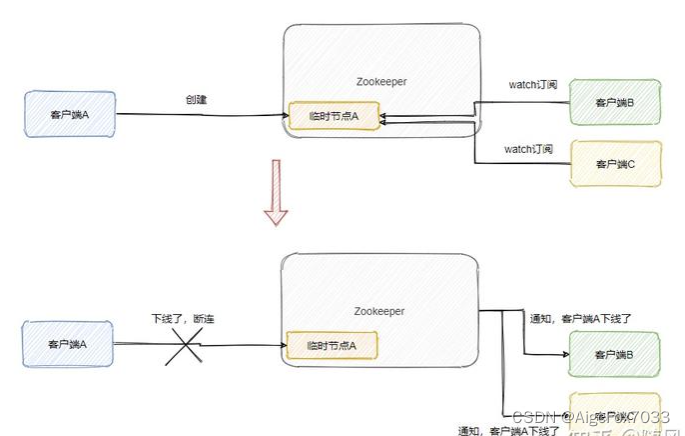
因此,ZooKeeper 能够侦测到集群中任何服务的启动或关闭,这使得它成为实现服务发现和故障转移监听机制的理想选择。Kafka 便是一个依赖于 ZooKeeper 的典型例子,没有 ZooKeeper 的支持,Kafka 将无法正常运作。ZooKeeper 为 Kafka 提供了元数据管理的功能,包括但不限于 Broker 的信息、主题数据、分区数据等。每当 Kafka 的 Broker 启动时,它都会与 ZooKeeper 进行通信,确保 ZooKeeper 能够维护集群中所有主题、配置和副本等关键信息。
ZooKeeper 还承担着诸如选举和扩容等重要机制的功能。例如,在控制器选举过程中,每个 Kafka Broker 启动时都会尝试在 ZooKeeper 中注册一个临时的 “/controller” 节点以参与竞选,首先成功创建该节点的 Broker 将被选为控制器。其他竞争失败的节点则会通过 Watcher 机制监控这个节点,一旦控制器发生故障,其他 Broker 将继续进行竞选,从而实现控制器的故障转移。这进一步凸显了 ZooKeeper 对 Kafka 的重要性。
二、为何要放弃 ZooKeeper
软件架构随着时间不断演进,当出现瓶颈时,变革便成为了必然。以下是一些放弃 ZooKeeper 的原因:
2.1、运维层面的问题
首先,作为一个中间件,Kafka 却需要依赖于另一个中间件 ZooKeeper,这种设计在某种程度上显得不太合理。虽然依赖如 Netty 这样的网络框架是可以理解的,但 Kafka 需要运行在 ZooKeeper 集群之上,这显得有些不协调。这就意味着,如果公司想要部署 Kafka,就必须同时部署 ZooKeeper,这无疑增加了运维的复杂性。因此,运维人员不仅要管理 Kafka 集群,还要管理 ZooKeeper 集群。
2.2、性能层面的问题
ZooKeeper 强调一致性,当一个节点上的数据发生变化时,其他节点必须等待通知并同步更新,这要求所有节点(超过半数)完成写入后才能继续,这种机制在写入性能上存在瓶颈。

如您所见,ZooKeeper 被描述为一个适用于存储简单配置或集群元数据的小量存储系统,它并不是一个传统意义上的存储系统。当处理大量写入数据时,ZooKeeper 的性能和稳定性可能会受到影响,导致 Watch 通知的延迟或丢失。特别是在 Kafka 集群规模较大、分区数量众多的情况下,ZooKeeper 存储的元数据量会增加,其性能就会显得不足。此外,ZooKeeper 作为分布式系统,也需要进行选举,而选举过程不仅缓慢,还会在选举期间导致服务不可用。
2.3、针对 ZooKeeper 的性能问题,Kafka 已经进行了一些改进。例如,以前消费者的位移数据存储在 ZooKeeper 上,提交位移或获取位移时都需要访问 ZooKeeper,这在数据量大时会导致 ZooKeeper 承受不住。为此,Kafka 引入了位移主题(如 “__consumer_offsets”),将位移的提交和获取作为消息处理,存储在日志中,从而避免了频繁访问 ZooKeeper 的性能问题。对于一些需要支持百万级别分区的大公司来说,当前 Kafka 单集群架构下无法稳定运行,即单集群支持的分区数量有限。因此,Kafka 需要摆脱对 ZooKeeper 的依赖。
2.4、那么,没有了 ZooKeeper 的 Kafka 会是什么样子呢?没有了 ZooKeeper 的 Kafka 将元数据存储移至内部,利用现有的日志存储机制来保存元数据。就像之前提到的位移主题一样,会有一个专门的元数据主题,元数据就像普通消息一样存储在日志中。因此,元数据的存储和之前的位移存储一样,通过现有的消息存储机制进行了一些改造,实现了所需功能,非常巧妙!此外,Kafka 还引入了 KRaft 模式来实现控制器的一致性。

这个协议是基于 Raft 算法的,具体的协议细节这里就不展开了,你只需要知道它能够有效地解决控制器领导者的选举问题,并确保集群内所有节点达成一致。
在以前依赖 ZooKeeper 实现的单控制器模式中,当分区数量巨大时,故障转移的过程往往非常缓慢。
这是因为当控制器发生变更时,需要将所有元数据重新加载到新的控制器上,并且将这些元数据同步给集群中的所有 Kafka Broker。
而在控制器集群(Controller Quorum)中,领导者的选举和切换过程就快得多,因为元数据已经在集群中同步,即集群中的所有 Broker 都已经拥有完整的元数据,无需重新加载。
此外,其他 Broker 已经基于日志存储了部分元数据,因此只需进行增量更新,而不需要全量更新。
通过这样的改进,就解决了之前由于元数据过多而无法支持更多分区的问题。
三、结语
可能会有读者思考,为什么一开始不直接采用这样的实现方式呢?
这是因为 ZooKeeper 是一个功能强大且经过实践验证的工具,早期使用它来实现某些功能是非常简单的,无需从头开始自己实现。
如果不是因为 ZooKeeper 的机制遇到了性能瓶颈,这样的改造可能永远不会发生。
软件开发就是这样,没有必要重复造轮子,找到合适的工具和解决方案才是关键。
AigcFox工具箱--主流自媒体平台视频、图文内容一键发布。视频、图片自动裂变n份并去重。多账号自动发布,模拟人工操作,无人值守。账户绑定上网卡或手机共享网络,可实现发布IP隔离。AI内容:可对文章、图片改写、润色、增强。