摘要:
DMPR-PS是一种基于深度学习的停车位检测系统,旨在实时监测和识别停车场中的停车位。该系统利用图像处理和分析技术,通过摄像头获取停车场的实时图像,并自动检测停车位的位置和状态。本文详细介绍了DMPR-PS系统的算法原理、创新点和实验结果,并对其性能进行了评估。

算法创新:
DMPR-PS系统的算法创新主要体现在以下几个方面:
-
深度学习模型:DMPR-PS系统采用了深度学习模型来进行停车位的检测。通过大规模数据集的训练,该模型可以自动学习停车位的特征,并准确地进行检测和分类。
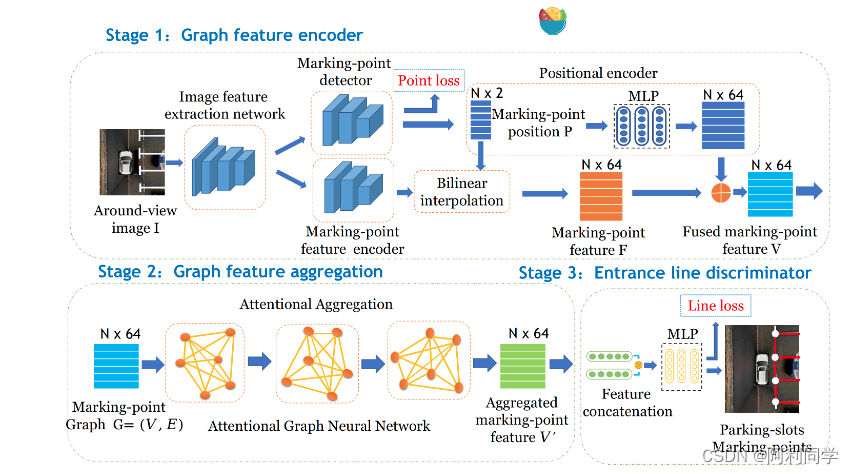
-
多尺度检测:为了应对不同大小的停车位,DMPR-PS系统使用了多尺度检测策略。通过在不同尺度下进行检测,可以提高系统对各种大小停车位的检测准确率。
-
实时性能:DMPR-PS系统具有较高的实时性能。它能够快速处理实时视频流,并在短时间内完成停车位的检测和识别,满足实时监测的需求。

实验结果与结论:
通过对多个停车场场景的实验测试,DMPR-PS系统展现了良好的性能。实验结果表明,该系统在检测准确率和实时性能方面都具有较高的水平。
、
代码运行
要求:
python版本3.6
pytorch版本1.4+
其他要求:
pip install -r requirements.txt
gcn-parking-slot
预训练模型
可以通过以下链接下载两个预训练模型。
链接 代码 描述
Model0 bc0a 使用ps2.0子集进行训练,如[1]所述。
Model1 pgig 使用完整的ps2.0数据集进行训练。
准备数据
可以在此处找到原始的ps2.0数据和标签。提取并组织如下:
├── datasets
│ └── parking_slot
│ ├── annotations
│ ├── ps_json_label
│ ├── testing
│ └── training
训练和测试
将当前目录导出到PYTHONPATH:
export PYTHONPATH=`pwd`
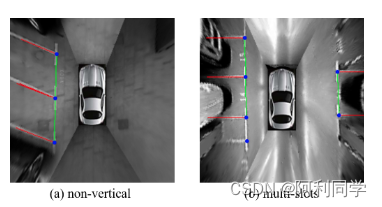
演示
python3 tools/demo.py -c config/ps_gat.yaml -m cache/ps_gat/100/models/checkpoint_epoch_200.pth
训练
python3 tools/train.py -c config/ps_gat.yaml
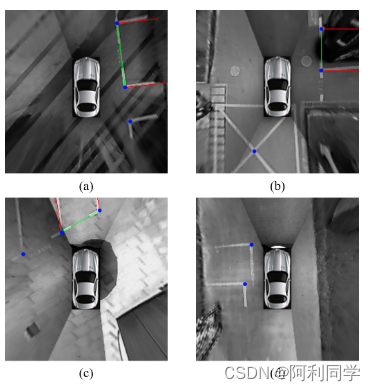
测试
python3 tools/test.py -c config/ps_gat.yaml -m cache/ps_gat/100/models/checkpoint_epoch_200.pth
代码
import cv2
import time
import torch
import pprint
import numpy as np
from pathlib import Path
from psdet.utils.config import get_config
from psdet.utils.common import get_logger
from psdet.models.builder import build_model
def draw_parking_slot(image, pred_dicts):
slots_pred = pred_dicts['slots_pred']
width = 512
height = 512
VSLOT_MIN_DIST = 0.044771278151623496
VSLOT_MAX_DIST = 0.1099427457599304
HSLOT_MIN_DIST = 0.15057789144568634
HSLOT_MAX_DIST = 0.44449496544202816
SHORT_SEPARATOR_LENGTH = 0.199519231
LONG_SEPARATOR_LENGTH = 0.46875
junctions = []
for j in range(len(slots_pred[0])):
position = slots_pred[0][j][1]
p0_x = width * position[0] - 0.5
p0_y = height * position[1] - 0.5
p1_x = width * position[2] - 0.5
p1_y = height * position[3] - 0.5
vec = np.array([p1_x - p0_x, p1_y - p0_y])
vec = vec / np.linalg.norm(vec)
distance =( position[0] - position[2] )**2 + ( position[1] - position[3] )**2
if VSLOT_MIN_DIST <= distance <= VSLOT_MAX_DIST:
separating_length = LONG_SEPARATOR_LENGTH
else:
separating_length = SHORT_SEPARATOR_LENGTH
p2_x = p0_x + height * separating_length * vec[1]
p2_y = p0_y - width * separating_length * vec[0]
p3_x = p1_x + height * separating_length * vec[1]
p3_y = p1_y - width * separating_length * vec[0]
p0_x = int(round(p0_x))
p0_y = int(round(p0_y))
p1_x = int(round(p1_x))
p1_y = int(round(p1_y))
p2_x = int(round(p2_x))
p2_y = int(round(p2_y))
p3_x = int(round(p3_x))
p3_y = int(round(p3_y))
cv2.line(image, (p0_x, p0_y), (p1_x, p1_y), (255, 0, 0), 2)
cv2.line(image, (p0_x, p0_y), (p2_x, p2_y), (255, 0, 0), 2)
cv2.line(image, (p1_x, p1_y), (p3_x, p3_y), (255, 0, 0), 2)
#cv2.circle(image, (p0_x, p0_y), 3, (0, 0, 255), 4)
junctions.append((p0_x, p0_y))
junctions.append((p1_x, p1_y))
for junction in junctions:
cv2.circle(image, junction, 3, (0, 0, 255), 4)
return image
def main():
cfg = get_config()
logger = get_logger(cfg.log_dir, cfg.tag)
logger.info(pprint.pformat(cfg))
model = build_model(cfg.model)
logger.info(model)
image_dir = Path(cfg.data_root) / 'testing' / 'outdoor-normal daylight'
display = False
# load checkpoint
model.load_params_from_file(filename=cfg.ckpt, logger=logger, to_cpu=False)
model.cuda()
model.eval()
if display:
car = cv2.imread('images/car.png')
car = cv2.resize(car, (512, 512))
with torch.no_grad():
for img_path in image_dir.glob('*.jpg'):
img_name = img_path.stem
data_dict = {}
image = cv2.imread(str(img_path))
image0 = cv2.resize(image, (512, 512))
image = image0/255.
data_dict['image'] = torch.from_numpy(image).float().permute(2, 0, 1).unsqueeze(0).cuda()
start_time = time.time()
pred_dicts, ret_dict = model(data_dict)
sec_per_example = (time.time() - start_time)
print('Info speed: %.4f second per example.' % sec_per_example)
if display:
image = draw_parking_slot(image0, pred_dicts)
image[145:365, 210:300] = 0
image += car
cv2.imshow('image',image.astype(np.uint8))
cv2.waitKey(50)
save_dir = Path(cfg.output_dir) / 'predictions'
save_dir.mkdir(parents=True, exist_ok=True)
save_path = save_dir / ('%s.jpg' % img_name)
cv2.imwrite(str(save_path), image)
if display:
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
结论
DMPR-PS系统是一种基于深度学习的停车位检测系统,通过创新的算法设计和实时性能优化,可以有效地监测和识别停车场中的停车位。该系统在提高停车场资源利用率和管理效率方面具有重要的应用价值。