一、基本输入输出函数
1、input函数
(1)所谓“输入”,就是用代码获取用户通过键盘输入的信息,在Python中,如果要获取用户在键盘上的输入信息,需要使用到input函数。
(2)程序运行到该函数时,它会等待用户输入内容(不管是字符串、整数还是浮点数都可以),然后将其获取并按照字符串类型返回。如果用户迟迟不输入内容,程序会卡死在该函数所在的语句。
(3)使用方式:<变量>=input(<提示字符串>)
(4)在.py文件中输入以下代码,并运行,接着在窗口内输入任一数据,按下回车,紧接着窗口就会输出刚刚输入的数据。
# 在窗口输入内容,该内容赋给变量a(窗口会显示提示字符串“请输入:”)
a = input("请输入:")
# 将变量a打印(输出)在窗口
print(a)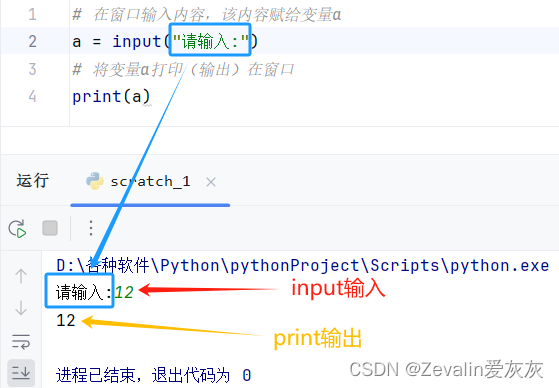
2、print函数
(1)该函数用于输出运算结果,根据输出内容的不同,有多种用法:
①仅用于输出字符串或单个变量:
print(<待输出的字符串或变量>)
print("输出的字符串") # 输出结果为“输出的字符串”
print(10) # 输出结果为“10”
a = 20
print(a) # 输出结果为“20”
print([1,2,3,4]) # 输出结果为“[1,2,3,4]”
print(["输出","字符串"]) # 输出结果为“['输出', '字符串']”
②仅用于输出一个或多个变量:
print(<变量1>,<变量2>,...,<变量n>)
b = 2005.0803
print(b,b,b)
print("输出",b,"字符串")
③用于混合输出字符串与变量值:
print(<>.format(<变量1>,<变量2>,...,<变量n>))
# 输出字符串模板中采用大括号{}表示一个槽位置,每个槽位置对应format()中的一个变量
a = 2005
b = 803
print("数字{}和数字{}的乘积是{}".format(a,b,a*b))
(2)print函数输出文本时会默认在最后增加一个换行,如果不希望在最后增加这个换行,或者希望输出文本后增加其他内容,可以对print函数的end参数进行赋值,使用方式如下:
print(<待输出内容>,end=”<增加的输出结尾>”)
a = 2005
b = 803
print("数字{}和数字{}的乘积是{}".format(a,b,a*b),end="。")
(3)想要混合输出字符串与变量值,还可以使用格式化操作符“%”。
①包含“%”的字符串,被称为格式化字符串。
②“%”和不同的字符连用,不同类型的数据需要使用不同的格式化字符。

③举例:
# %s是打印字符串的格式化字符
name="小明"
print("我的名字叫 %s,请多多关照!" % name)
# %d是打印整数的格式化字符,“06”表示最少要显示6位数字,少则用0填充
student_no=2212
print("我的学号是 %06d" % student_no)
# %f是打印浮点数的格式化字符,“.02”表示小数点后显示两位数,少则用0填充
price=12.5
weight=21.3
money=266.25
print("苹果单价 %.02f 元/斤,购买 %.02f 斤,需要支付 %.02f 元" % (price, weight, money))
# print("数据比例是 %.02f%%" % scale * 100)是错误的,“*100”将作用于整个字符串,而不是scale
# 要想打印百分号,""内要在打印%的位置前再加一个%
scale=0.1
print("数据比例是 %.02f%%" % (scale * 100))
3、eval函数
(1)eval函数的作用:将字符串转换为Python表达式(即去掉字符串最外侧的引号),按照Python语句方式执行去掉引号后的字符内容,并返回表达式的值。这个函数可以用来动态地执行Python代码,从而实现一些动态的功能,简单说,原本在Python终端中输入表达式才能产生的结果,借助该函数在参数中传入表达式就可以产生相同的结果。
(2)将字符串当成有效的表达式来求值并返回计算结果,在.py文件中输入以下代码,并运行,接着在窗口内输入任一数据,按下回车,紧接着窗口就会输出刚刚输入的数据。
input_str = input("请输入一个算术题:")
print(eval(input_str))
(3)在开发时千万不要使用eval直接转换input的结果,这样用户可以随意输入终端命令,从而引发不可预知的后果。

二、变量
1、变量的定义及使用
(1)在Python中,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
(2)等号“=”用来给变量赋值,“=”左边是一个变量名,“=”右边是存储在变量中的值。
(3)与C语言不同,Python创建变量时不需要声明类型,Python会自动识别“=”右侧的数据类型。
(4)举例:
①例1:
# 定义 qq_number 的变量用来保存 qq 号码
qq_number = "1234567"
# 输出 qq_number 中保存的内容
print(qq_number)
# 定义 qq_password 的变量用来保存 qq 密码
qq_password = "123"
# 输出 qq_password 中保存的内容
print(qq_password)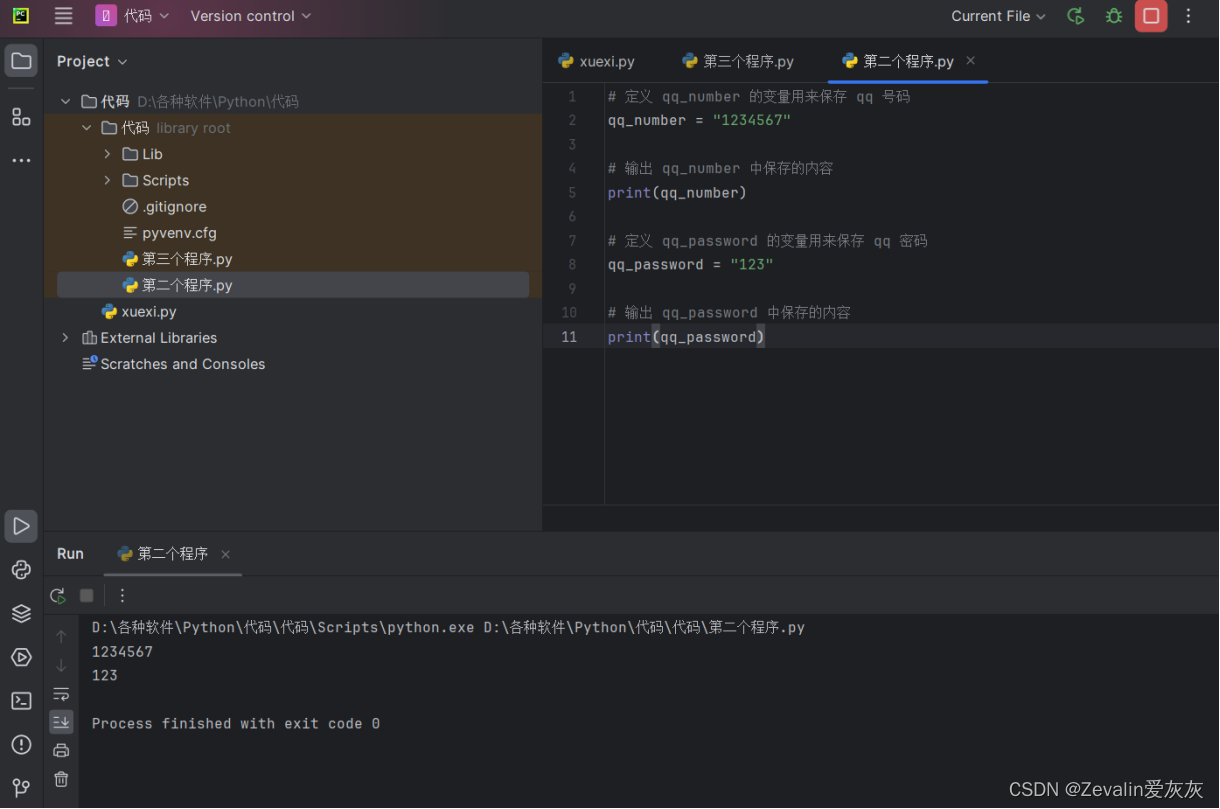
②例2:
# 定义单位重量的价格
price = 8.5
# 定义购买重量
weight = 7.5
# 计算总金额
money = price * weight
# 输出需要支付的总金额
print(money)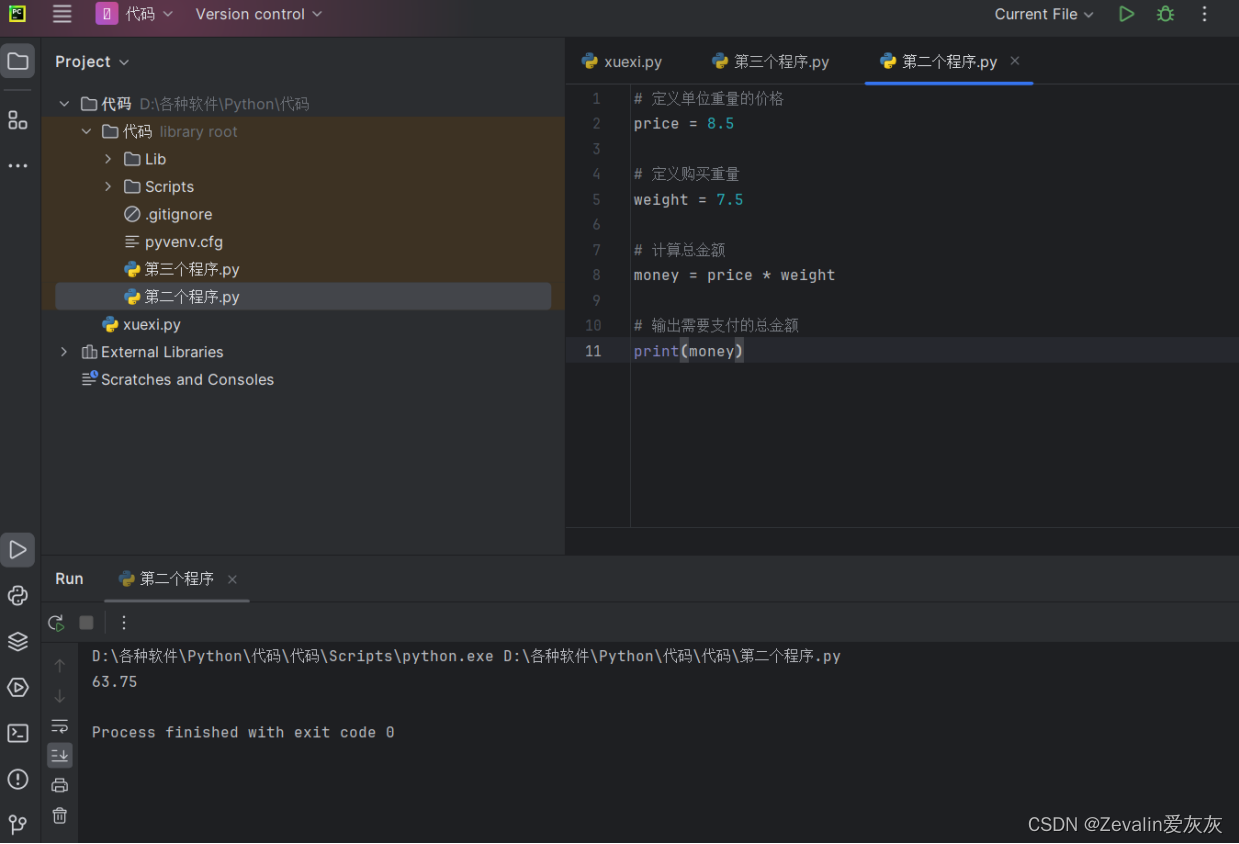
③例3:
# 定义单位重量的价格
price = 8.5
# 定义购买重量
weight = 7.5
# 计算总金额
money = price * weight
print("返现前需支付:%.2f元" % money)
# 只要有购买行为就返 5 元
money = money - 5
print("返现后需支付:%.2f元" % money)
[1]对于本例(例3),一共定义有3个变量,分别是price、weight、money。
[2]“money = money - 5” 是在直接使用之前已经定义的变量。变量名只有在第一次出现才是定义变量,变量名再次出现是直接使用之前定义过的变量。
[3]在程序开发中,可以修改之前定义变量中保存的值。
2、变量的类型
(1)在Python中定义变量不需要指定类型(在其他很多高级语言中都需要)。
(2)数据类型可以分为数字型和非数字型:
①数字型:整型(int)、浮点型(float)、布尔型(bool)、复数型(complex)。
②非数字型 :字符串、列表、元组、字典。
(3)type函数可以将变量类型输出,如下图所示。

3、变量的命名
(1)Python采用大写字母、小写字母、数字、下划线和汉字等字符及其组合进行命名,但名字的首字符不能是数字,标识符中间不能出现空格,长度没有限制。(Python中的标识符是区分大小写的)
(2)一般不采用中文等非英语语言字符对变量命名。
(3)变量名不能与关键字重名。
(4)命名规则可以被视为一种惯例,并无绝对与强制,目的是为了增加代码的识别和可读性。在 Python 中,如果变量名需要由二个或多个单词组成时,可以按照以下方式命名:
①每个单词都使用小写字母。
②单词与单词之间使用下划线连接。
③当变量名是由二个或多个单词组成时,还可以利用驼峰命名法来命名。
[1]小驼峰式命名法:第一个单词以小写字母开始,后续单词的首字母大写。
[2]大驼峰式命名法:每一个单词的首字母都采用大写字母。
(5)在定义变量时,为了保证代码格式,“=”的左右应该各保留一个空格。
三、保留字(关键字)
Python 3.x版本共35个保留字,与其它标识符一样,Python的保留字也是大小写敏感的,例如True是保留字,但是true不是,后者可以被当做普通变量使用。
| and |
as |
assert |
async |
await |
break |
class |
| continue |
def |
del |
elif |
else |
except |
Flase |
| finally |
for |
from |
global |
if |
import |
in |
| is |
lambda |
None |
nonlocal |
not |
or |
pass |
| raise |
return |
True |
try |
while |
with |
yield |
关键字pass的作用是空语句,和C语言中的“;”空语句一样。
四、程序的语句元素
1、表达式
(1)产生或计算新数据值的代码片段为表达式。
(2)表达式一般由数据和操作符等构成。
2、赋值语句
(1)对变量进行赋值的一行代码被称为赋值语句。
(2)等号“=”用来给变量赋值,“=”左边是一个变量名,“=”右边是存储在变量中的值。格式为:
<变量>=<表达式>
a = 2005 * 803
print(a)(3)在Python中,还可以同时给多个变量赋值(同步赋值语句),格式为:
<变量1>,<变量2>,...,<变量N>=<表达式1>,<表达式2>,...,<表达式N>
a = 1
b = 2
c,d = a,b
print(a,b,c,d)
a,b = b,a # 使用同步赋值语句还可以直接进行值交换
print(a,b,c,d)
3、引用(模块/库的导入)
(1)Python程序会经常使用当前程序之外已有的功能代码,这个方法叫“引用”。
(2)模块的概念:
①每一个以扩展名py结尾的Python源代码文件都是一个模块。
②模块名同样也是一个标识符,需要符合标识符的命名规则。
③在模块中定义的全局变量、函数、类都是提供给外界直接使用的工具。
④模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块。
(3)模块的三种导入方式:
①import导入:

[1]导入之后通过“模块名. ”使用模块提供的工具(全局变量、函数、类)。
[2]如果模块的名字太长,可以使用as指定模块的名称,以方便在代码中的使用。
import 模块名1 as 模块别名
import hm_01_测试模块1 as DogModule
import hm_02_测试模块2 as CatModule
DogModule.say_hello()
CatModule.say_hello()
dog = DogModule.Dog()
print(dog)
cat = CatModule.Cat()
print(cat)②from...import导入:
[1]如果希望从某一个模块中,导入部分工具,就可以使用from ... import的方式。
from 模块名 import 工具名
[2]“import 模块名”是一次性把模块中所有工具全部导入,并且该导入方式需要通过模块名/别名才能访问其中的工具;“from...import”不需要通过“模块名.”访问工具,可以直接使用模块提供的工具。
from hm_01_测试模块1 import say_hello
say_hello()③from...import *导入:
[1]从模块导入所有工具。
from 模块名 import *
[2]这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查。
(4)如果两个模块存在同名的函数,那么后导入模块的函数会覆盖掉先导入的函数。
①开发时import代码应该统一写在代码的顶部,更容易及时发现冲突。
②一旦发现冲突,可以使用as关键字给其中一个工具起一个别名。
# from hm_01_测试模块1 import say_hello
from hm_02_测试模块2 import say_hello as module2_say_hello
from hm_01_测试模块1 import say_hello
say_hello()
module2_say_hello()(5)模块的搜索顺序:搜索当前目录指定模块名的文件,如果有就直接导入,如果没有再搜索系统目录。
①给文件起名时不要和系统的模块文件重名。
②Python中每一个模块都有一个内置属性“__file__”可以查看模块的完整路径。
(6)原则上每一个文件都应该是可以被导入的,一个独立的Python文件就是一个模块。
(7)在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍。在实际开发中,每一个模块都是独立开发的,大多都有专人负责,开发人员通常会在模块下方增加一些测试代码,测试代码仅在模块内使用,被导入到其它文件中时不需要执行,实现测试代码功能需要借助“__name__”属性。
①“__name__”属性可以做到,测试模块的代码只在测试情况下被运行,而在被导入时不会被执行。
②“__name__”是Python的一个内置属性,记录着一个字符串:如果是被其它文件导入的,“__name__”就是模块名;如果是处于当前执行的程序的话,“__name__”就是“__main__”。
③在很多Python文件中都会看到以下格式的代码:
# 注意:直接执行的代码不是向外界提供的工具!
def say_hello():
print("你好你好,我是 say hello")
# 如果直接执行模块,__name__ == __main__
if __name__ == "__main__":
print(__name__)
# 文件被导入时,能够直接执行的代码不需要被执行!
print("小明开发的模块")
say_hello()(8)包:
①包是一个包含多个模块的特殊目录,目录下有一个特殊的文件__init__.py。
②包名的命名方式和变量名一致。
③使用“import 包名”可以一次性导入包中的所有模块。
④案例演练:
[1]新建一个 hm_message 的包。

注:图中测试文件的位置有误,测试文件应该和“hm_message”目录在同一个(同一级)文件夹。
[2]在目录下,新建两个文件send_message和receive_message。

[3]在send_message文件中定义一个send函数。

[4]在receive_message文件中定义一个receive函数。

[5]要在外界使用包中的模块,需要在__init__.py中指定对外界提供的模块列表。(“.”代表当前目录)

[6]在外部直接导入hm_message的包,使用其中的工具。

4、分支语句
(1)判断的定义:如果条件满足,才能做某件事情;如果条件不满足,就做另外一件事情,或者什么也不做。
(2)判断语句又被称为“分支语句”,正是因为有了判断,才让程序有了很多的分支。
(3)单分支语句:
if <条件>:
<语句块>
①代码的缩进为一个tab键,或者4个空格。
②任何能够产生True或False的语句都可以作为判断条件,当条件为True(真)时,执行语句块中的内容。

③例:
# 定义年龄变量
age = 18
# 判断是否满18岁
# if 语句以及缩进部分的代码是一个完整的代码块
if age >=18:
print("已成年!")
# 这条语句无论是否满足成年条件都会执行
print("年龄为%d" % age)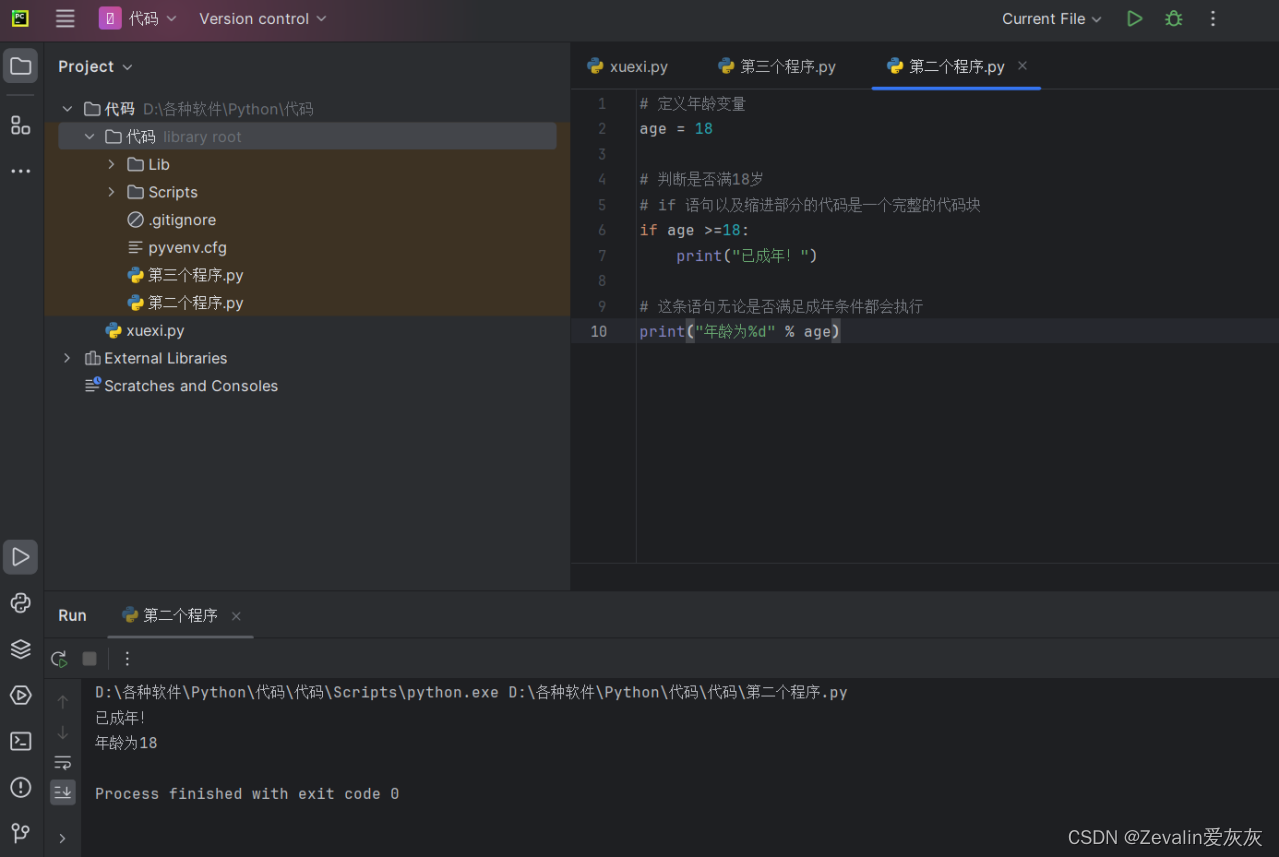
(4)二分支语句:
if <条件>:
<语句块>
else:
<语句块>

# 定义年龄变量
age = 18
# 判断是否满18岁
# if 语句以及缩进部分的代码是一个完整的代码块
if age >=18:
print("已成年!")
else:
print("未成年")
# 这条语句无论是否满足成年条件都会执行
print("年龄为%d" % age)
5、循环语句
(1)与分支语句控制程序执行类似,循环语句的作用是根据判断条件确定一段代码是否需要再执行一次或多次。
(2)循环语句包括遍历循环和条件循环。
(3)条件循环:
while(<条件>):
<语句块1>
<语句块2>
①当条件为True(真)时,执行语句块1,然后再次判断条件,当条件为False(假)时,退出循环执行语句块2。
②一般都是这样使用条件循环的:(while语句以及缩进部分是一个完整的代码块)
初始条件设置 —— 通常是重复执行的计数器
while 条件(判断计数器是否达到目标次数):
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
处理条件(计数器 + 1)
注:循环结束后,之前定义的计数器条件的数值是依旧存在的。
③例:
# 1. 定义重复次数计数器
i = 1
# 2. 使用 while 判断条件
while i <= 5:
# 要重复执行的代码
print("Hello Python")
# 处理计数器 i
i = i + 1
print("循环结束后的 i = %d" % i)