1.前言
最近需要搭建一个推荐系统,由于只有一台服务器,Hadoop使用伪分布式。
2.安装伪分布式Hadoop
2.1.添加Hadoop用户
sudo useradd -m hadoop -s /bin/bash为hadoop设置密码
sudo passwd hadoop为hadoop增加管理员权限
sudo adduser hadoop sudo2.2.更新apt
sudo apt-get update更新的时候遇到了问题
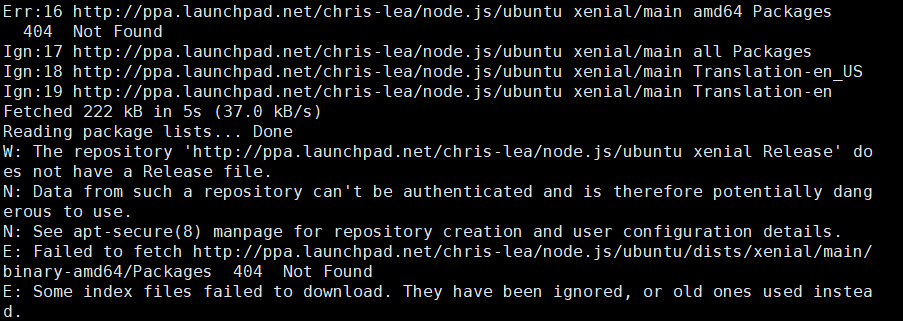
解决方案:使用
sudo add-apt-repository -y -r ppa:chris-lea/node.js
sudo rm -f /etc/apt/sources.list.d/chris-lea-node_js-*.list之后再次执行更新操作即可。
2.3.配置SSH无密码登录
首先使用ssh localhost登录机器,会让输入密码
使用exit退出,然后使用cd ~/.ssh/进入ssh目录
执行ssh-keygen -t rsa生成密钥,提示全部按回车
执行cat ./id_rsa.pub >> ./authorized_keys加入授权
再次执行ssh localhost就不需要密码了
2.4.安装Java
依次执行
sudo add-apt-repository ppa:webupd8team/java
sudo apt update
sudo apt install openjdk-9-jdk
sudo apt -f install配置JAVA_HOME
vim ~/.bashrc在文件中加入
export JAVA_HOME=/usr/lib/jvm/java-9-openjdk-amd64执行source ~/.bashrc
2.5安装Hadoop2.9.1
解压hadoop到/usr/local
sudo tar -zxf hadoop-2.9.1.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.9.1/ ./hadoop
sudo chown -R hadoop ./hadoop 检验Hadoop版本
cd /usr/local/hadoop
./bin/hadoop version2.6配置Hadoop伪分布式环境
cd /usr/local/hadoop/etc/hadoop/ 修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>进行NameNode格式化
进入/usr/local/hadoop
执行./bin/hdfs namenode -format
启动NameNode 和 DataNode
./sbin/start-dfs.sh
输入jps,会出现如下进程
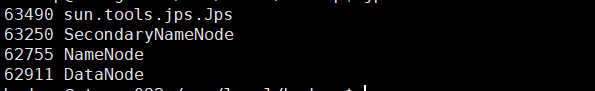
说明启动成功。
关闭Hadoop
./sbin/stop-dfs.sh2.7配置Yarn
cd /usr/local/hadoop/etc/hadoop配置mapred-site.xml
mv mapred-site.xml.template mapred-site.xml编辑
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>启动Yarn
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver 使用jps查看进程
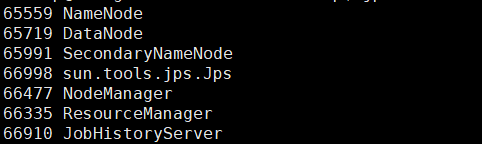
关闭Yarn
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver