背景与数据清洗可视化,请查看
https://blog.csdn.net/weixin_43502706/article/details/130777766?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22130777766%22%2C%22source%22%3A%22weixin_43502706%22%7D
直接开始,读取数据
spark = SparkSession.builder.\
master("local[*]").\
config('spark.sql.shuffle.partitions','4').\
enableHiveSupport().\
getOrCreate()
data = spark.read.format('csv').\
option('sep', ',').\
option('header', True).\
option('encoding', 'utf-8'). \
option("inferSchema", True).\
load('/tmp/pycharm_project_0508/data/train_V2.csv')
字段情况
print(data.printSchema()) #字段情况
print("原始数据条数:{}".format(data.count()))
剔除可能开挂的数据
data_m = data.na.drop().\
filter(data.kills<=20).\
filter(data.roadKills<=3).\
filter("not(walkDistance=0 and kills>0)").\
filter("not(kills>3 and headshotKills!=kills)").\
drop('Id', 'groupId', 'matchId', 'matchType'). \
withColumnRenamed('winPlacePerc', 'label')
print(data_m.count(),"删除数据{}".format(data.count()-data_m.count()))
向量化数据
assembler = VectorAssembler(inputCols=data_m.columns[:-1], outputCol="features")
df = assembler.transform(data_m)
model_df = df.select(['features','label'])
train, test = model_df.randomSplit([0.8, 0.2], seed=10)
创建随机森林模型
# 创建随机森林模型
rf = RandomForestRegressor(featuresCol='features', labelCol='label')
model = rf.fit(train)
predictions = model.transform(test)
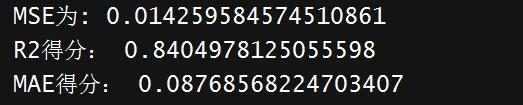
评估
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol="label")
mse = evaluator.evaluate(predictions, {evaluator.metricName: 'mse'})
r2 = evaluator.evaluate(predictions, {evaluator.metricName: 'r2'})
mae = evaluator.evaluate(predictions, {evaluator.metricName: 'mae'})
print("MSE为:", mse)
print("R2得分:", r2)
print("MAE得分:", mae)