# 1. 分块思想
author: Ir1d, HeRaNO, Xeonacid
## 简介
其实,分块是一种思想,而不是一种数据结构。
从 NOIP 到 NOI 到 IOI,各种难度的分块思想都有出现。
分块的基本思想是,通过对原数据的适当划分,并在划分后的每一个块上预处理部分信息,从而较一般的暴力算法取得更优的时间复杂度。
分块的时间复杂度主要取决于分块的块长,一般可以通过均值不等式求出某个问题下的最优块长,以及相应的时间复杂度。
分块是一种很灵活的思想,相较于树状数组和线段树,分块的优点是通用性更好,可以维护很多树状数组和线段树无法维护的信息。
当然,分块的缺点是渐进意义的复杂度,相较于线段树和树状数组不够好。
不过在大多数问题上,分块仍然是解决这些问题的一个不错选择。
下面是几个例子。
## 区间和
??? " 例题 [LibreOJ 6280 数列分块入门 4](https://loj.ac/problem/6280)"
给定一个长度为 $n$ 的序列 $\{a_i\}$,需要执行 $n$ 次操作。操作分为两种:
1. 给 $a_l \sim a_r$ 之间的所有数加上 $x$;
2. 求 $\sum_{i=l}^r a_i$。
$1 \leq n \leq 5 \times 10^4$
我们将序列按每 $s$ 个元素一块进行分块,并记录每块的区间和 $b_i$。
$$
\underbrace{a_1, a_2, \ldots, a_s}_{b_1}, \underbrace{a_{s+1}, \ldots, a_{2s}}_{b_2}, \dots, \underbrace{a_{(s-1) \times s+1}, \dots, a_n}_{b_{\frac{n}{s}}}
$$
最后一个块可能是不完整的(因为 $n$ 很可能不是 $s$ 的倍数),但是这对于我们的讨论来说并没有太大影响。
首先看查询操作:
- 若 $l$ 和 $r$ 在同一个块内,直接暴力求和即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
- 若 $l$ 和 $r$ 不在同一个块内,则答案由三部分组成:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然采用上面暴力计算的方法,对于完整块,则直接利用已经求出的 $b_i$ 求和即可。这种情况下,最坏复杂度为 $O(\dfrac{n}{s}+s)$。
接下来是修改操作:
- 若 $l$ 和 $r$ 在同一个块内,直接暴力修改即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
- 若 $l$ 和 $r$ 不在同一个块内,则需要修改三部分:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然是暴力修改每个元素的值(别忘了更新区间和 $b_i$),对于完整块,则直接修改 $b_i$ 即可。这种情况下,最坏复杂度和仍然为 $O(\dfrac{n}{s}+s)$。
利用均值不等式可知,当 $\dfrac{n}{s}=s$,即 $s=\sqrt n$ 时,单次操作的时间复杂度最优,为 $O(\sqrt n)$。
??? note "参考代码"
```cpp
--8<-- "docs/ds/code/decompose/decompose_1.cpp"
```
## 区间和 2
上一个做法的复杂度是 $\Omega(1) , O(\sqrt{n})$。
我们在这里介绍一种 $O(\sqrt{n}) - O(1)$ 的算法。
为了 $O(1)$ 询问,我们可以维护各种前缀和。
然而在有修改的情况下,不方便维护,只能维护单个块内的前缀和。
以及整块作为一个单位的前缀和。
每次修改 $O(T+\frac{n}{T})$。
询问:涉及三部分,每部分都可以直接通过前缀和得到,时间复杂度 $O(1)$。
## 对询问分块
同样的问题,现在序列长度为 $n$,有 $m$ 个操作。
如果操作数量比较少,我们可以把操作记下来,在询问的时候加上这些操作的影响。
假设最多记录 $T$ 个操作,则修改 $O(1)$,询问 $O(T)$。
$T$ 个操作之后,重新计算前缀和,$O(n)$。
总复杂度:$O(mT+n\frac{m}{T})$。
$T=\sqrt{n}$ 时,总复杂度 $O(m \sqrt{n})$。
### 其他问题
分块思想也可以应用于其他整数相关问题:寻找零元素的数量、寻找第一个非零元素、计算满足某个性质的元素个数等等。
还有一些问题可以通过分块来解决,例如维护一组允许添加或删除数字的集合,检查一个数是否属于这个集合,以及查找第 $k$ 大的数。要解决这个问题,必须将数字按递增顺序存储,并分割成多个块,每个块中包含 $\sqrt{n}$ 个数字。每次添加或删除一个数字时,必须通过在相邻块的边界移动数字来重新分块。
一种很有名的离线算法 [莫队算法](../misc/mo-algo.md),也是基于分块思想实现的。
## 练习题
- [UVA - 12003 - Array Transformer](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3154)
- [UVA - 11990 Dynamic Inversion](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3141)
- [SPOJ - Give Away](http://www.spoj.com/problems/GIVEAWAY/)
- [Codeforces - Till I Collapse](http://codeforces.com/contest/786/problem/C)
- [Codeforces - Destiny](http://codeforces.com/contest/840/problem/D)
- [Codeforces - Holes](http://codeforces.com/contest/13/problem/E)
- [Codeforces - XOR and Favorite Number](https://codeforces.com/problemset/problem/617/E)
- [Codeforces - Powerful array](http://codeforces.com/problemset/problem/86/D)
- [SPOJ - DQUERY](https://www.spoj.com/problems/DQUERY)
**本页面主要译自博文 [Sqrt-декомпозиция](http://e-maxx.ru/algo/sqrt_decomposition) 与其英文翻译版 [Sqrt Decomposition](https://cp-algorithms.com/data_structures/sqrt_decomposition.html)。其中俄文版版权协议为 Public Domain + Leave a Link;英文版版权协议为 CC-BY-SA 4.0。**
### 2. 块状数组
## 建立块状数组
块状数组,即把一个数组分为几个块,块内信息整体保存,若查询时遇到两边不完整的块直接暴力查询。一般情况下,块的长度为 $O(\sqrt{n})$。详细分析可以阅读 2017 年国家集训队论文中徐明宽的《非常规大小分块算法初探》。
下面直接给出一种建立块状数组的代码。
???+ note "实现"
```cpp
num = sqrt(n);
for (int i = 1; i <= num; i++)
st[i] = n / num * (i - 1) + 1, ed[i] = n / num * i;
ed[num] = n;
for (int i = 1; i <= num; i++) {
for (int j = st[i]; j <= ed[i]; j++) {
belong[j] = i;
}
size[i] = ed[i] - st[i] + 1;
}
```
其中 `st[i]` 和 `ed[i]` 为块的起点和终点,`size[i]` 为块的大小。
## 保存与修改块内信息
### 例题 1:[教主的魔法](https://www.luogu.com.cn/problem/P2801)
两种操作:
1. 区间 $[x,y]$ 每个数都加上 $z$;
2. 查询区间 $[x,y]$ 内大于等于 $z$ 的数的个数。
我们要询问一个块内大于等于一个数的数的个数,所以需要一个 `t` 数组对块内排序,`a` 为原来的(未被排序的)数组。对于整块的修改,使用类似于标记永久化的方式,用 `delta` 数组记录现在块内整体加上的值。设 $q$ 为查询和修改的操作次数总和,则时间复杂度 $O(q\sqrt{n}\log n)$。
用 `delta` 数组记录每个块的整体赋值情况。
???+ note "实现"
```cpp
void Sort(int k) {
for (int i = st[k]; i <= ed[k]; i++) t[i] = a[i];
sort(t + st[k], t + ed[k] + 1);
}
void Modify(int l, int r, int c) {
int x = belong[l], y = belong[r];
if (x == y) // 区间在一个块内就直接修改
{
for (int i = l; i <= r; i++) a[i] += c;
Sort(x);
return;
}
for (int i = l; i <= ed[x]; i++) a[i] += c; // 直接修改起始段
for (int i = st[y]; i <= r; i++) a[i] += c; // 直接修改结束段
for (int i = x + 1; i < y; i++) delta[i] += c; // 中间的块整体打上标记
Sort(x);
Sort(y);
}
int Answer(int l, int r, int c) {
int ans = 0, x = belong[l], y = belong[r];
if (x == y) {
for (int i = l; i <= r; i++)
if (a[i] + delta[x] >= c) ans++;
return ans;
}
for (int i = l; i <= ed[x]; i++)
if (a[i] + delta[x] >= c) ans++;
for (int i = st[y]; i <= r; i++)
if (a[i] + delta[y] >= c) ans++;
for (int i = x + 1; i <= y - 1; i++)
ans +=
ed[i] - (lower_bound(t + st[i], t + ed[i] + 1, c - delta[i]) - t) + 1;
// 用 lower_bound 找出中间每一个整块中第一个大于等于 c 的数的位置
return ans;
}
```
### 例题 2:寒夜方舟
两种操作:
1. 区间 $[x,y]$ 每个数都变成 $z$;
2. 查询区间 $[x,y]$ 内小于等于 $z$ 的数的个数。
用 `delta` 数组记录现在块内被整体赋值为何值。当该块未被整体赋值时,用一个特殊值(如 `0x3f3f3f3f3f3f3f3fll`)加以表示。对于边角块,查询前要 `pushdown`,把块内存的信息下放到每一个数上。赋值之后记得重新 `sort` 一遍。其他方面同上题。
???+ note "实现"
```cpp
void Sort(int k) {
for (int i = st[k]; i <= ed[k]; i++) t[i] = a[i];
sort(t + st[k], t + ed[k] + 1);
}
void PushDown(int x) {
if (delta[x] != 0x3f3f3f3f3f3f3f3fll) // 用该值标记块内没有被整体赋值
for (int i = st[x]; i <= ed[x]; i++) a[i] = t[i] = delta[x];
delta[x] = 0x3f3f3f3f3f3f3f3fll;
}
void Modify(int l, int r, int c) {
int x = belong[l], y = belong[r];
PushDown(x);
if (x == y) {
for (int i = l; i <= r; i++) a[i] = c;
Sort(x);
return;
}
PushDown(y);
for (int i = l; i <= ed[x]; i++) a[i] = c;
for (int i = st[y]; i <= r; i++) a[i] = c;
Sort(x);
Sort(y);
for (int i = x + 1; i < y; i++) delta[i] = c;
}
int Binary_Search(int l, int r, int c) {
int ans = l - 1, mid;
while (l <= r) {
mid = (l + r) / 2;
if (t[mid] <= c)
ans = mid, l = mid + 1;
else
r = mid - 1;
}
return ans;
}
int Answer(int l, int r, int c) {
int ans = 0, x = belong[l], y = belong[r];
PushDown(x);
if (x == y) {
for (int i = l; i <= r; i++)
if (a[i] <= c) ans++;
return ans;
}
PushDown(y);
for (int i = l; i <= ed[x]; i++)
if (a[i] <= c) ans++;
for (int i = st[y]; i <= r; i++)
if (a[i] <= c) ans++;
for (int i = x + 1; i <= y - 1; i++) {
if (0x3f3f3f3f3f3f3f3fll == delta[i])
ans += Binary_Search(st[i], ed[i], c) - st[i] + 1;
else if (delta[i] <= c)
ans += size[i];
}
return ans;
}
```
## 练习
1. [单点修改,区间查询](https://loj.ac/problem/130)
2. [区间修改,区间查询](https://loj.ac/problem/132)
3. [【模板】线段树 2](https://www.luogu.com.cn/problem/P3373)
4. [「Ynoi2019 模拟赛」Yuno loves sqrt technology III](https://www.luogu.com.cn/problem/P5048)
5. [「Violet」蒲公英](https://www.luogu.com.cn/problem/P4168)
6. [作诗](https://www.luogu.com.cn/problem/P4135)
### 3. 块状链表
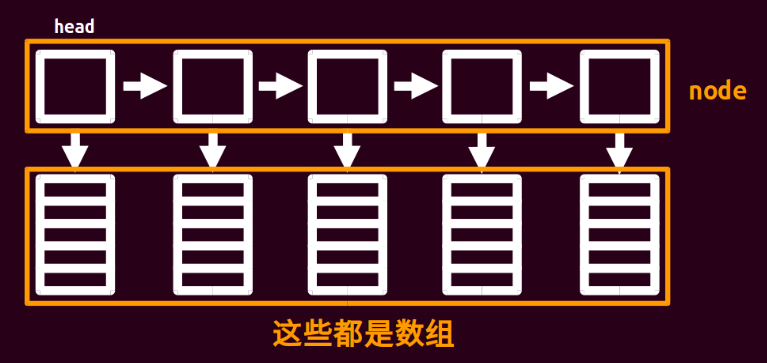
author: HeRaNO, konnyakuxzy, littlefrog
[](./images/kuaizhuanglianbiao.png "./images/kuaizhuanglianbiao.png")
块状链表大概就长这样……
不难发现块状链表就是一个链表,每个节点指向一个数组。
我们把原来长度为 n 的数组分为 $\sqrt{n}$ 个节点,每个节点对应的数组大小为 $\sqrt{n}$。
所以我们这么定义结构体,代码见下。
其中 `sqn` 表示 `sqrt(n)` 即 $\sqrt{n}$,`pb` 表示 `push_back`,即在这个 `node` 中加入一个元素。
???+ note "实现"
```cpp
struct node {
node* nxt;
int size;
char d[(sqn << 1) + 5];
node() { size = 0, nxt = NULL, memset(d, 0, sizeof(d)); }
void pb(char c) { d[size++] = c; }
};
```
块状链表应该至少支持:分裂、插入、查找。
什么是分裂?分裂就是分裂一个 `node`,变成两个小的 `node`,以保证每个 `node` 的大小都接近 $\sqrt{n}$(否则可能退化成普通数组)。当一个 `node` 的大小超过 $2\times \sqrt{n}$ 时执行分裂操作。
分裂操作怎么做呢?先新建一个节点,再把被分裂的节点的后 $\sqrt{n}$ 个值 `copy` 到新节点,然后把被分裂的节点的后 $\sqrt{n}$ 个值删掉(`size--`),最后把新节点插入到被分裂节点的后面即可。
块状链表的所有操作的复杂度都是 $\sqrt{n}$ 的。
还有一个要说的。
随着元素的插入(或删除),$n$ 会变,$\sqrt{n}$ 也会变。这样块的大小就会变化,我们难道还要每次维护块的大小?
其实不然,把 $\sqrt{n}$ 设置为一个定值即可。比如题目给的范围是 $10^6$,那么 $\sqrt{n}$ 就设置为大小为 $10^3$ 的常量,不用更改它。
```cpp
list<vector<char> > orz_list;
```
## STL 中的 `rope`
### 导入
STL 中的 `rope` 也起到块状链表的作用,它采用可持久化平衡树实现,可完成随机访问和插入、删除元素的操作。
由于 `rope` 并不是真正的用块状链表来实现,所以它的时间复杂度并不等同于块状链表,而是相当于可持久化平衡树的复杂度(即 $O(\log n)$)。
可以使用如下方法来引入:
```cpp
#include <ext/rope>
using namespace __gnu_cxx;
```
???+ warning "关于双下划线开头的库函数"
OI 中,关于能否使用双下划线开头的库函数曾经一直不确定,2021 年 CCF 发布的 [关于 NOI 系列活动中编程语言使用限制的补充说明](https://www.noi.cn/xw/2021-09-01/735729.shtml) 中提到「允许使用以下划线开头的库函数或宏,但具有明确禁止操作的库函数和宏除外」。故 `rope` 目前可以在 OI 中正常使用。
### 基本操作
| 操作 | 作用 |
| :-----------------------: | :---------------------------: |
| `rope <int > a` | 初始化 `rope`(与 `vector` 等容器很相似) |
| `a.push_back(x)` | 在 `a` 的末尾添加元素 `x` |
| `a.insert(pos, x)` | 在 `a` 的 `pos` 个位置添加元素 `x` |
| `a.erase(pos, x)` | 在 `a` 的 `pos` 个位置删除 `x` 个元素 |
| `a.at(x)` 或 `a[x]` | 访问 `a` 的第 `x` 个元素 |
| `a.length()` 或 `a.size()` | 获取 `a` 的大小 |
## 例题
[POJ2887 Big String](http://poj.org/problem?id=2887)
题解:
很简单的模板题。代码如下:
```cpp
--8<-- "docs/ds/code/block-list/block-list_1.cpp"
```
### 4. 树分块
author: ouuan, Ir1d, Marcythm, Xeonacid
## 树分块的方式
可以参考 [真 - 树上莫队](../misc/mo-algo-on-tree.md)。
也可以参考 [ouuan 的博客/莫队、带修莫队、树上莫队详解/树上莫队](https://ouuan.github.io/莫队、带修莫队、树上莫队详解/#树上莫队)。
树上莫队同样可以参考以上两篇文章。
## 树分块的应用
树分块除了应用于莫队,还可以灵活地运用到某些树上问题中。但可以用树分块解决的题目往往都有更优秀的做法,所以相关的题目较少。
顺带提一句,「gty 的妹子树」的树分块做法可以被菊花图卡掉。
### [BZOJ4763 雪辉](https://www.luogu.com.cn/problem/P3603)
先进行树分块,然后对每个块的关键点,预处理出它到祖先中每个关键点的路径上颜色的 bitset,以及每个关键点的最近关键点祖先,复杂度是 $O(n\sqrt n+\frac{nc}{32})$,其中 $n\sqrt n$ 是暴力从每个关键点向上跳的复杂度,$\frac{nc}{32}$ 是把 $O(n)$ 个 `bitset` 存下来的复杂度。
回答询问的时候,先从路径的端点暴力跳到所在块的关键点,再从所在块的关键点一块一块地向上跳,直到 $lca$ 所在块,然后再暴力跳到 $lca$。关键点之间的 `bitset` 已经预处理了,剩下的在暴力跳的过程中计算。单次询问复杂度是 $O(\sqrt n+\frac c{32})$,其中 $\sqrt n$ 是块内暴力跳以及块直接向上跳的复杂度,$O(\frac c{32})$ 是将预处理的结果与暴力跳的结果合并的复杂度。数颜色个数可以用 `bitset` 的 `count()`,求 $\operatorname{mex}$ 可以用 `bitset` 的 `_Find_first()`。
所以,总复杂度为 $O((n+m)(\sqrt n+\frac c{32}))$。
??? "参考代码"
```cpp
--8<-- "docs/ds/code/tree-decompose/tree-decompose_1.cpp"
```
### [BZOJ4812 由乃打扑克](https://www.luogu.com.cn/problem/P5356)
这题和上一题基本一样,唯一的区别是得到 `bitset` 后如何计算答案。
~~由于 BZOJ 是计算所有测试点总时限,不好卡,所以可以用 `_Find_next()` 水过去。~~
正解是每 $16$ 位一起算,先预处理出 $2^{16}$ 种可能的情况高位连续 $1$ 的个数、低位连续 $1$ 的个数以及中间的贡献。只不过这样要手写 `bitset`,因为标准库的 `bitset` 不能取某 $16$ 位……
代码可以参考 [这篇博客](https://www.cnblogs.com/FallDream/p/bzoj4763.html)。
### 5. Sqrt Tree
## 引入
给你一个长度为 n 的序列 ${\left\langle a_i\right\rangle}_{i=1}^n$,再给你一个满足结合律的运算 $\circ$(比如 $\gcd,\min,\max,+,\operatorname{and},\operatorname{or},\operatorname{xor}$ 均满足结合律),然后对于每一次区间询问 $[l,r]$,我们需要计算 $a_l\circ a_{l+1}\circ\dotsb\circ a_{r}$。
Sqrt Tree 可以在 $O(n\log\log n)$ 的时间内预处理,并在 $O(1)$ 的时间内回答询问。
## 解释
### 序列分块
首先我们把整个序列分成 $O(\sqrt{n})$ 个块,每一块的大小为 $O(\sqrt{n})$。对于每个块,我们计算:
1. $P_i$ 块内的前缀区间询问
2. $S_i$ 块内的后缀区间询问
3. 维护一个额外的数组 $\left\langle B_{i,j}\right\rangle$ 表示第 $i$ 个块到第 $j$ 个块的区间答案。
举个例子,假设 $\circ$ 代表加法运算 $+$,序列为 $\{1,2,3,4,5,6,7,8,9\}$。
首先我们将序列分成三块,变成了 $\{1,2,3\},\{4,5,6\},\{7,8,9\}$。
那么每一块的前缀区间答案和后缀区间答案分别为
$$
\begin{aligned}
&P_1=\{1,3,6\},S_1=\{6,5,3\}\\
&P_2=\{4,9,15\},S_2=\{15,11,6\}\\
&P_3=\{7,15,24\},S_3=\{24,17,9\}\\
\end{aligned}
$$
$B$ 数组为:
$$
B=\begin{bmatrix}
6 & 21 & 45\\
0 & 15 & 39\\
0 & 0 & 24\\
\end{bmatrix}
$$
(对于 $i>j$ 的不合法的情况我们假设答案为 0)
显然我们可以在 $O(n)$ 的时间内预处理这些值,空间复杂度同样是 $O(n)$ 的。处理好之后,我们可以利用它们在 $O(1)$ 的时间内回答一些跨块的询问。但对于那些整个区间都在一个块内的询问我们仍不能处理,因此我们还需要处理一些东西。
### 构建一棵树
容易想到我们在每个块内递归地构造上述结构以支持块内的查询。对于大小为 $1$ 的块我们可以 $O(1)$ 地回答询问。这样我们就建出了一棵树,每一个结点代表序列的一个区间。叶子结点的区间长度为 $1$ 或 $2$。一个大小为 $k$ 的结点有 $O(\sqrt{k})$ 个子节点,于是整棵树的高度是 $O(\log\log n)$ 的,每一层的区间总长是 $O(n)$ 的,因此我们构建这棵树的复杂度是 $O(n\log\log n)$ 的。
现在我们可以在 $O(\log\log n)$ 的时间内回答询问。对于询问 $[l,r]$,我们只需要快速找到一个区间长度最小的结点 $u$ 使得 $u$ 能包含 $[l,r]$,这样 $[l,r]$ 在 $u$ 的分块区间中一定是跨块的,就可以 $O(1)$ 地计算答案了。查询一次的总体复杂度是 $O(\log\log n)$,因为树高是 $O(\log\log n)$ 的。不过我们仍可以优化这个过程。
### 优化询问复杂度
容易想到二分高度,然后可以 $O(1)$ 判断是否合法。这样复杂度就变成了 $O(\log\log\log n)$。不过我们仍可以进一步加速这一过程。
我们假设
1. 每一块的大小都是 $2$ 的整数幂次;
2. 每一层上的块大小是相同的。
为此我们需要在序列的末位补充一些 $0$ 元素,使得它的长度变成 $2$ 的整数次幂。尽管有些块可能会变成原来的两倍大小,但这样仍是 $O(\sqrt{k})$ 的,于是预处理分块的复杂度仍是 $O(n)$ 的。
现在我们可以轻松地确定一个询问区间是否被整个地包含在一个块中。对于区间 $[l,r]$(以 0 为起点),我们把端点写为二进制形式。举一个例子,对于 $k=4, l=39, r=46$,二进制表示为
$$
l = 39_{10} = 100111_2,
r = 46_{10} = 101110_2
$$
我们知道每一层的区间长度是相同的,而分块的大小也是相同的(在上述示例中 $2^k=2^4=16$)。这些块完全覆盖了整个序列,因此第一块代表的元素为 $[0,15]$(二进制表示为 $[000000_2,001111_2]$),第二个块代表的元素区间为 $[16,31]$(二进制表示为 $[010000_2,011111_2]$),以此类推。我们发现这些在同一个块内的元素的位置在二进制上只有后 $k$ 位不同(上述示例中 $k=4$)。而示例的 $l,r$ 也只有后 $k$ 位不同,因此他们在同一个块中。
因此我们需要检查区间两个端点是否只有后 $k$ 位不同,即 $l\oplus r\le 2^k-1$。因此我们可以快速找到答案区间所在的层:
1. 对于每个 $i\in [1,n]$,我们找到找到 $i$ 最高位上的 $1$;
2. 现在对于一个询问 $[l,r]$,我们计算 $l\oplus r$ 的最高位,这样就可以快速确定答案区间所在的层。
这样我们就可以在 $O(1)$ 的时间内回答询问啦。
## 更新元素的过程
我们可以在 Sqrt Tree 上更新元素,单点修改和区间修改都是支持的。
### 单点修改
考虑一次单点赋值操作 $a_x=val$,我们希望高效更新这个操作的信息。
#### 朴素实现
首先我们来看看在做了一次单点修改后 Sqrt Tree 会变成什么样子。
考虑一个长度为 $l$ 的结点以及对应的序列:$\left\langle P_i\right\rangle,\left\langle S_i\right\rangle,\left\langle B_{i,j}\right\rangle$。容易发现在 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i \right\rangle$ 中都只有 $O(\sqrt{l})$ 个元素改变。而在 $\left\langle B_{i,j}\right\rangle$ 中则有 $O(l)$ 个元素被改变。因此有 $O(l)$ 个元素在树上被更新。因此在 Sqrt Tree 上单点修改的复杂度是 $O(n+\sqrt{n}+\sqrt{\sqrt{n}}+\dotsb)=O(n)$。
#### 使用 Sqrt Tree 替代 B 数组
注意到单点更新的瓶颈在于更新根结点的 $\left\langle B_{i,j}\right\rangle$。因此我们尝试用另一个 Sqrt Tree 代替根结点的 $\left\langle B_{i,j}\right\rangle$,称其为 $index$。它的作用和原来的二维数组一样,维护整段询问的答案。其他非根结点仍然使用 $\left\langle B_{i,j}\right\rangle$ 维护。注意,如果一个 Sqrt Tree 根结点有 $index$ 结构,称其 Sqrt Tree 是 **含有索引** 的;如果一个 Sqrt Tree 的根结点有 $\left\langle B_{i,j}\right\rangle$ 结构,称其是 **没有索引** 的。而 $index$ 这棵树本身是没有索引的。
因此我们可以这样更新 $index$ 树:
1. 在 $O(\sqrt{n})$ 的时间内更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$。
2. 更新 $index$,它的长度是 $O(n)$ 的,但我们只需要更新其中的一个元素(这个元素代表了被改变的块),这一步的时间复杂度是 $O(\sqrt{n})$ 的(使用朴素实现的算法)。
3. 进入产生变化的子节点并使用朴素实现的算法在 $O(\sqrt{n})$ 的时间内更新信息。
注意,查询的复杂度仍是 $O(1)$ 的,因为我们最多使用 $index$ 树一次。于是单点修改的复杂度就是 $O(\sqrt{n})$ 的。
### 更新一个区间
Sqrt Tree 也支持区间覆盖操作 $\operatorname{Update}(l,r,x)$,即把区间 $[l,r]$ 的数全部变成 $x$。对此我们有两种实现方式,其中一种会花费 $O(\sqrt{n}\log\log n)$ 的复杂度更新信息,$O(1)$ 的时间查询;另一种则是 $O(\sqrt{n})$ 更新信息,但查询的时间会增加到 $O(\log\log n)$。
我们可以像线段树一样在 Sqrt Tree 上打懒标记。但是在 Sqrt Tree 上有一点不同。因为下传一个结点的懒标记,复杂度可能达到 $O(\sqrt{n})$,因此我们不是在询问的时侯下传标记,而是看父节点是否有标记,如果有标记就把它下传。
#### 第一种实现
在第一种实现中,我们只会给第 $1$ 层的结点(结点区间长度为 $O(\sqrt{n})$)打懒标记,在下传标记的时侯直接更新整个子树,复杂度为 $O(\sqrt{n}\log\log n)$。操作过程如下:
1. 考虑第 $1$ 层上的结点,对于那些被修改区间完全包含的结点,给他们打一个懒标记;
2. 有两个块只有部分区间被覆盖,我们直接在 $O(\sqrt{n}\log\log n)$ 的时间内 **重建** 这两个块。如果它本身带有之前修改的懒标记,就在重建的时侯顺便下传标记;
3. 更新根结点的 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,时间复杂度 $O(\sqrt{n})$;
4. 重建 $index$ 树,时间复杂度 $O(\sqrt{n}\log\log n)$。
现在我们可以高效完成区间修改了。那么如何利用懒标记回答询问?操作如下:
1. 如果我们的询问被包含在一个有懒标记的块内,可以利用懒标记计算答案;
2. 如果我们的询问包含多个块,那么我们只需要关心最左边和最右边不完整块的答案。中间的块的答案可以在 $index$ 树中查询(因为 $index$ 树在每次修改完后会重建),复杂度是 $O(1)$。
因此询问的复杂度仍为 $O(1)$。
#### 第二种实现
在这种实现中,每一个结点都可以被打上懒标记。因此在处理一个询问的时侯,我们需要考虑祖先中的懒标记,那么查询的复杂度将变成 $O(\log\log n)$。不过更新信息的复杂度就会变得更快。操作如下:
1. 被修改区间完全包含的块,我们把懒标记添加到这些块上,复杂度 $O(\sqrt{n})$;
2. 被修改区间部分覆盖的块,更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,复杂度 $O(\sqrt{n})$(因为只有两个被修改的块);
3. 更新 $index$ 树,复杂度 $O(\sqrt{n})$(使用同样的更新算法);
4. 对于没有索引的子树更新他们的 $\left\langle B_{i,j}\right\rangle$;
5. 递归地更新两个没有被完全覆盖的区间。
时间复杂度是 $O(\sqrt{n}+\sqrt{\sqrt{n}}+\dotsb)=O(\sqrt{n})$。
## 实现
下面的实现在 $O(n\log\log n)$ 的时间内建树,在 $O(1)$ 的时间内回答询问,在 $O(\sqrt{n})$ 的时间内单点修改。
```cpp
SqrtTreeItem op(const SqrtTreeItem &a, const SqrtTreeItem &b);
int log2Up(int n) {
int res = 0;
while ((1 << res) < n) {
res++;
}
return res;
}
class SqrtTree {
private:
int n, lg, indexSz;
vector<SqrtTreeItem> v;
vector<int> clz, layers, onLayer;
vector<vector<SqrtTreeItem> > pref, suf, between;
void buildBlock(int layer, int l, int r) {
pref[layer][l] = v[l];
for (int i = l + 1; i < r; i++) {
pref[layer][i] = op(pref[layer][i - 1], v[i]);
}
suf[layer][r - 1] = v[r - 1];
for (int i = r - 2; i >= l; i--) {
suf[layer][i] = op(v[i], suf[layer][i + 1]);
}
}
void buildBetween(int layer, int lBound, int rBound, int betweenOffs) {
int bSzLog = (layers[layer] + 1) >> 1;
int bCntLog = layers[layer] >> 1;
int bSz = 1 << bSzLog;
int bCnt = (rBound - lBound + bSz - 1) >> bSzLog;
for (int i = 0; i < bCnt; i++) {
SqrtTreeItem ans;
for (int j = i; j < bCnt; j++) {
SqrtTreeItem add = suf[layer][lBound + (j << bSzLog)];
ans = (i == j) ? add : op(ans, add);
between[layer - 1][betweenOffs + lBound + (i << bCntLog) + j] = ans;
}
}
}
void buildBetweenZero() {
int bSzLog = (lg + 1) >> 1;
for (int i = 0; i < indexSz; i++) {
v[n + i] = suf[0][i << bSzLog];
}
build(1, n, n + indexSz, (1 << lg) - n);
}
void updateBetweenZero(int bid) {
int bSzLog = (lg + 1) >> 1;
v[n + bid] = suf[0][bid << bSzLog];
update(1, n, n + indexSz, (1 << lg) - n, n + bid);
}
void build(int layer, int lBound, int rBound, int betweenOffs) {
if (layer >= (int)layers.size()) {
return;
}
int bSz = 1 << ((layers[layer] + 1) >> 1);
for (int l = lBound; l < rBound; l += bSz) {
int r = min(l + bSz, rBound);
buildBlock(layer, l, r);
build(layer + 1, l, r, betweenOffs);
}
if (layer == 0) {
buildBetweenZero();
} else {
buildBetween(layer, lBound, rBound, betweenOffs);
}
}
void update(int layer, int lBound, int rBound, int betweenOffs, int x) {
if (layer >= (int)layers.size()) {
return;
}
int bSzLog = (layers[layer] + 1) >> 1;
int bSz = 1 << bSzLog;
int blockIdx = (x - lBound) >> bSzLog;
int l = lBound + (blockIdx << bSzLog);
int r = min(l + bSz, rBound);
buildBlock(layer, l, r);
if (layer == 0) {
updateBetweenZero(blockIdx);
} else {
buildBetween(layer, lBound, rBound, betweenOffs);
}
update(layer + 1, l, r, betweenOffs, x);
}
SqrtTreeItem query(int l, int r, int betweenOffs, int base) {
if (l == r) {
return v[l];
}
if (l + 1 == r) {
return op(v[l], v[r]);
}
int layer = onLayer[clz[(l - base) ^ (r - base)]];
int bSzLog = (layers[layer] + 1) >> 1;
int bCntLog = layers[layer] >> 1;
int lBound = (((l - base) >> layers[layer]) << layers[layer]) + base;
int lBlock = ((l - lBound) >> bSzLog) + 1;
int rBlock = ((r - lBound) >> bSzLog) - 1;
SqrtTreeItem ans = suf[layer][l];
if (lBlock <= rBlock) {
SqrtTreeItem add =
(layer == 0) ? (query(n + lBlock, n + rBlock, (1 << lg) - n, n))
: (between[layer - 1][betweenOffs + lBound +
(lBlock << bCntLog) + rBlock]);
ans = op(ans, add);
}
ans = op(ans, pref[layer][r]);
return ans;
}
public:
SqrtTreeItem query(int l, int r) { return query(l, r, 0, 0); }
void update(int x, const SqrtTreeItem &item) {
v[x] = item;
update(0, 0, n, 0, x);
}
SqrtTree(const vector<SqrtTreeItem> &a)
: n((int)a.size()), lg(log2Up(n)), v(a), clz(1 << lg), onLayer(lg + 1) {
clz[0] = 0;
for (int i = 1; i < (int)clz.size(); i++) {
clz[i] = clz[i >> 1] + 1;
}
int tlg = lg;
while (tlg > 1) {
onLayer[tlg] = (int)layers.size();
layers.push_back(tlg);
tlg = (tlg + 1) >> 1;
}
for (int i = lg - 1; i >= 0; i--) {
onLayer[i] = max(onLayer[i], onLayer[i + 1]);
}
int betweenLayers = max(0, (int)layers.size() - 1);
int bSzLog = (lg + 1) >> 1;
int bSz = 1 << bSzLog;
indexSz = (n + bSz - 1) >> bSzLog;
v.resize(n + indexSz);
pref.assign(layers.size(), vector<SqrtTreeItem>(n + indexSz));
suf.assign(layers.size(), vector<SqrtTreeItem>(n + indexSz));
between.assign(betweenLayers, vector<SqrtTreeItem>((1 << lg) + bSz));
build(0, 0, n, 0);
}
};
```
## 习题
[CodeChef - SEGPROD](https://www.codechef.com/NOV17/problems/SEGPROD)
**本页面主要译自 [Sqrt Tree - Algorithms for Competitive Programming](https://cp-algorithms.com/data_structures/sqrt-tree.html),版权协议为 CC-BY-SA 4.0。**
---
朴素的打表,指的是在比赛时把所有可能的输入对应的答案都计算出来并保存下来,然后在代码里开个数组把答案放里面,直接输出即可。
注意这个技巧只适用于输入的值域不大(如,输入只有一个数,而且范围很小)的问题,否则可能会导致代码过长、MLE、打表需要的时间过长等问题。
### 例题s
规定 $f(x)$ 为整数 $x$ 的二进制表示中 $1$ 的个数。输入一个正整数 $n$($n\leq 10^9$),输出 $\sum_{i=1}^n f^2(i)$。
### 解答
如果对于每一个 $n$,都输出 $f(n)$ 的话,除了可能会 MLE 外,还有可能代码超过最大代码长度限制,导致编译不通过。
我们考虑优化这个答案表。采用 [分块](../ds/decompose.md) 的思想,我们设置一个合理的步长 $m$(这个步长一般视代码长度而定),对于第 $i$ 块,计算出:
$$
\sum_{k=\frac{n}{m}(i-1)+1}^{\frac{ni}{m}} f^2(k)
$$
的值。
然后输出答案时采用分块思想处理即可。即,整块的答案用预处理的值计算,非整块的答案暴力计算。
---
一般来说,这样的问题对于处理单个函数值 $f(x)$ 很快,但需要大量函数值求和(求积或某些可以快速合并的操作),枚举会超出时间限制,**在找不到标准做法的情况下,分段打表是一个不错的选择**。
> 注意事项:当上题中指数不是定值,但**范围较小**,也可以考虑**打表**。
### 练习
[「BZOJ 3798」特殊的质数](https://hydro.ac/d/bzoj/p/3798):求 $[l,r]$ 区间内有多少个质数可以分解为两个正整数的平方和。
[「Luogu P1822」魔法指纹](https://www.luogu.com.cn/problem/show?pid=P1822)