conda的一些命令以及创建环境的基本命令可参考:Conda环境搭建以及激活
以及 conda 本地环境常用操作
- 前言
这里是梳理linux上在docker中使用conda,以配置MLD-TResNet-L-AAM模型为例。论文笔记参考:多标签分类论文笔记 | Combining Metric Learning and Attention Heads…MLD-TResNet-L-AAM/GAT+AAM)
文章目录
一、conda配置
1. 安装anaconda
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Linux-x86_64.sh
或
curl -O https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Linux-x86_64.sh
bash Anaconda3-2021.11-Linux-x86_64.sh
- 配置环境
export PATH="/root/anaconda3/bin:$PATH"
或者写入系统命令中,开启即可启动
输入gedit ~/.bashrc命令打开文件,在文件结尾输入以下语句,保存。
export PATH="/root/anaconda3/bin:$PATH"
然后:
source ~/.bashrc
2. 升级conda(可选)
conda update conda
3. 安装cuda(在宿主机上安装)
apt-get update
apt-get install gcc g++
sh cuda_10.2.89_440.33.01_linux.run
- 配置环境
输入gedit ~/.bashrc命令打开文件,在文件结尾输入以下语句,保存。
export PATH=/usr/local/cuda/bin${
PATH:+:${
PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后:
source ~/.bashrc
- 验证安装的cuda
nvcc -V
- 安装cudnn
tar zxvf cudnn-10.2-linux-x64-v7.6.5.32.tgz
chmod 666 /usr/local/cuda/include
cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
cp cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
- 旧版验证(这里是旧版)
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
- 新版验证
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
4. 在conda中切换cuda的版本
conda search cudatoolkit --info
conda install cudatoolkit==XXXXX
5. 在conda中切换python版本
conda search --full --name python
conda install python=3.8.18
6. 收集运行环境
pip freeze > requirements.txt
7. 回退conda里面包的版本
conda list --revision
查看历史版本,然后运行接数字就好了,比如:
conda install --rev 1
二、以下是配置MLD-TResNet-L-AAM论文代码
1. 创建conda环境(以下均在conda中进行)
conda create --name torchreid python=3.7
- 进入conda
conda activate torchreid
或者
source activate torchreid
2. 拉取代码
- 拉取
git clone https://github.com/openvinotoolkit/deep-object-reid.git
- 切换分支
git checkout multilabel
3. 安装环境
- 安装cudatoolkit(一定要先安装cuda)
conda install cudatoolkit=10.2
- 安装cudnn(这里直接安装即可,会安装配套cuda的cudnn)
conda install cudnn
- 配置环境
pip install -r requirements.txt
- 遇到问题1
Collecting inplace_abn
Using cached inplace-abn-1.1.0.tar.gz (137 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [6 lines of output]
Traceback (most recent call last):
File "<string>", line 36, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-div2jd3n/inplace-abn_810be5ed00194c44a5bcc754bf5501e0/setup.py", line 4, in <module>
import torch
ModuleNotFoundError: No module named 'torch'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
- 解决方案
pip install --upgrade setuptools
python -m pip install --upgrade pip
- 遇到问题2
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
- 解决方案
apt install libgl1-mesa-glx
4. 训练命令
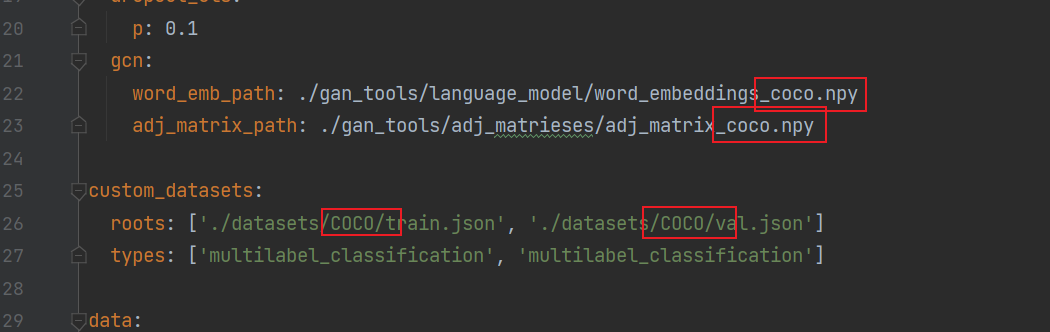
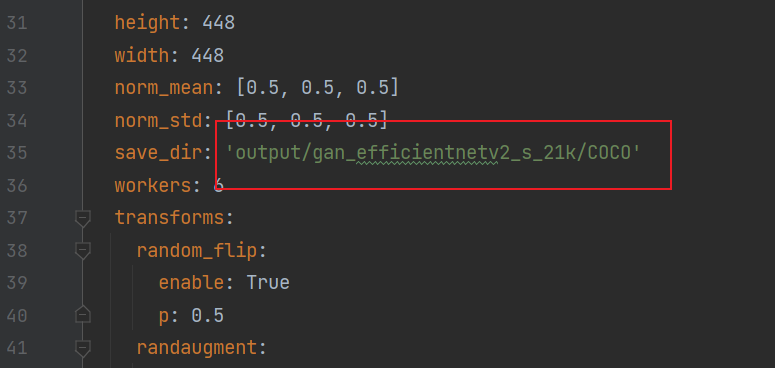
python tools/main.py --config-file configs/EfficientNetV2_small_gcn.yml --gpu-num 1 custom_datasets.roots "['datasets/COCO/train.json', 'datasets/COCO/val.json']" data.save_dir ./out/
- 遇到问题3
网络问题,两个文件无法下载,分别是model.safetensors和pytorch_model.bin。(需要科学上网)
- 解决方案
在本地下好:
https://huggingface.co/timm/tf_efficientnetv2_s.in21k/resolve/main/model.safetensors
https://cdn-lfs.huggingface.co/repos/1a/54/1a5499191575630110693f1105f43e325ae7f696b9f8d34db19ab1309ce0aa15/09dc7ef3e90ec4570d22ae1af1c12cbc1aff590b2c68dec1cbd781340e5a8ccc?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27pytorch_model.bin%3B+filename%3D%22pytorch_model.bin%22%3B&response-content-type=application%2Foctet-stream&Expires=1697800394&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY5NzgwMDM5NH19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5odWdnaW5nZmFjZS5jby9yZXBvcy8xYS81NC8xYTU0OTkxOTE1NzU2MzAxMTA2OTNmMTEwNWY0M2UzMjVhZTdmNjk2YjlmOGQzNGRiMTlhYjEzMDljZTBhYTE1LzA5ZGM3ZWYzZTkwZWM0NTcwZDIyYWUxYWYxYzEyY2JjMWFmZjU5MGIyYzY4ZGVjMWNiZDc4MTM0MGU1YThjY2M%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=rdjIofPONLg5roVfXki%7EycLUzpfL0VQWI4RaT6-1mTyh5gJoXxHZna1Z97YbSuU9t-KFi2Q5iGguyjKsHhZzSlRv-zVd0lPhPGmuMGcE7npRrZnPNFB2V5XFYtho8fWzKVwreGujYmaFE7Ge-zkTivnO7YkqmNs%7EeH69FRmbp5xAqW0LbsEspr0aOkaxqCCVoFXgPyJBra4dVaITeremwJSD0OcW2F2zNCdbo0nGcCDzrYsRijiUIAXweXpESL10uLt776efgzGhrDtuKKdVD68Q-3voq5PdTWTQaVP2VCDjkb66QECoAoUDtRjGJtK41zNfBs-1N6RGMDUWMNRM4A__&Key-Pair-Id=KVTP0A1DKRTAX
然后放在/root/.cache/huggingface/hub/models--timm--tf_efficientnetv2_s.in21k下。
- 遇到问题4
Couldn't apply path mapping to the remote file.
- 解决方案
我碰到是因为远程没同步,等待一会儿就好了。
(其中还有网络不佳的问题, 我手动下载,强行改了路径,先跑着)


- 遇到问题5
AttributeError: module 'torch' has no attribute 'frombuffer'
- 解决方案
发现readme中写pytorch版本要1.8.2而根据requiremets.txt装的是1.8.1的,坑得很!但是没找到,但发现没装cudatoolkit,现在进行安装。未果。还是先装1.8.2看看,参考:
https://pytorch.org/get-started/previous-versions/
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
没用,要装torch2.0
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
然后docker中的cuda也要换成11.8,cudnn要换成相应的;conda中的cudatoolkit也要换成11.8
然后还要修改:
vim /path/to/deep-object-reid-multilabel/torchreid/models/gcn.py
vim /root/anaconda3/envs/torchreid/lib/python3.8/site-packages/randaugment/randaugment.py
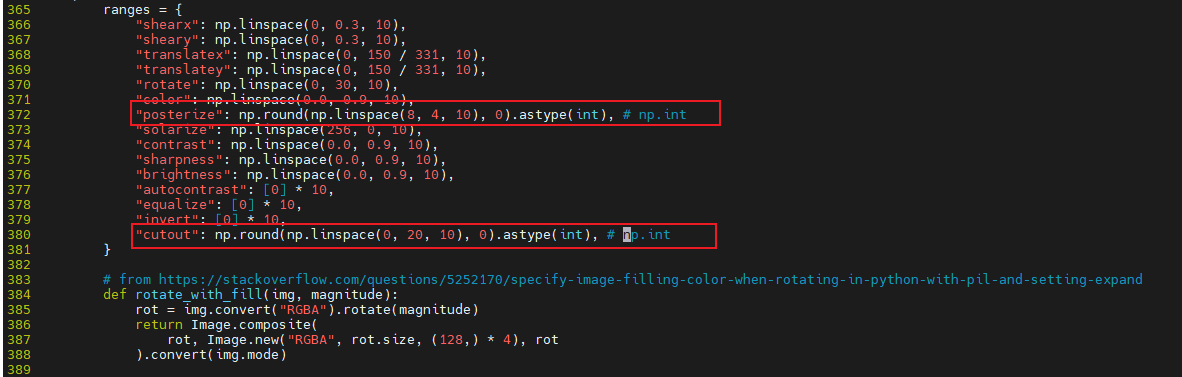
- 遇到问题6
pth要下载,网络不佳报错了。(需要科学上网)
- 解决方案:
手动下载:https://drive.google.com/uc?export=download&id=1N0t0eShJS3L1cDiY8HTweKfPKJ55h141
然后放入并改名:/root/.cache/torch/checkpoints/uc?export=download&id=1N0t0eShJS3L1cDiY8HTweKfPKJ55h141.pth
- 遇到问题7
RuntimeError: DataLoader worker (pid 3273) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
- 解决方案
shared memory不够,把环境打包,重启docker,设置shm=2G
- 遇到问题6
然后报cuda内存不够
- 解决方案:
调整batch size:
vim configs/EfficientNetV2_small_gcn.yml
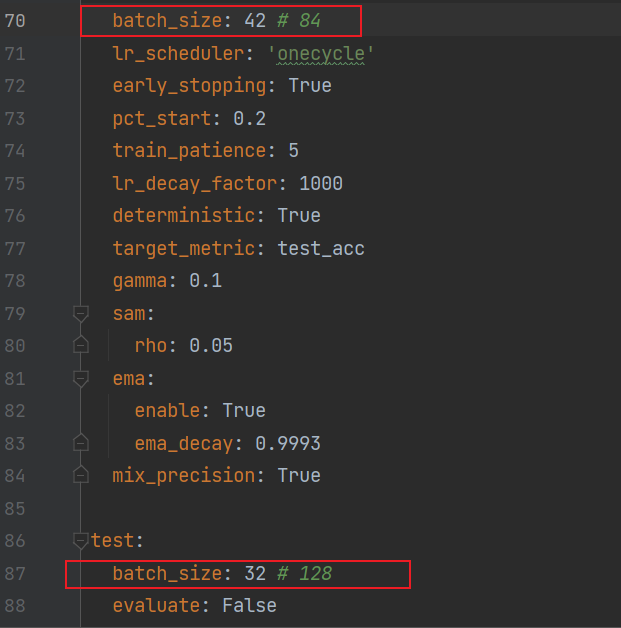
终于跑起来了,脑壳嗡嗡的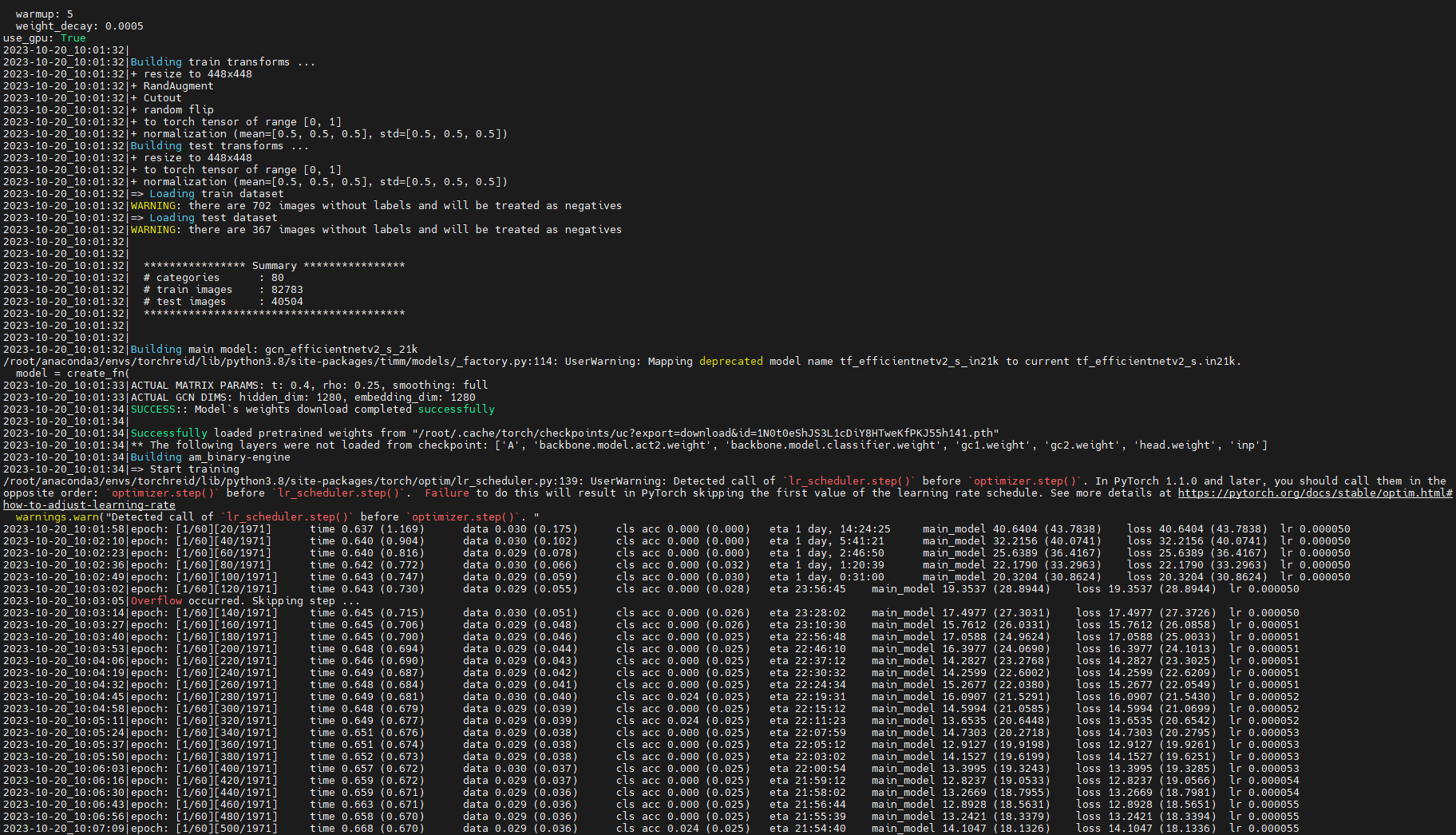
注意:
我这边跑的是COCO数据集,要把coco2014的训练和验证数据集里的图片,放到项目目录/datasets/COCO/images中
然后还有配置文件configs/EfficientNetV2_small_gcn.yml的voc都改成coco,注意对应的大小写。