

数据3.0时代,通过大模型+数据,使得企业/开发者用更少的代码,或通过自然语言构建应用与交付业务的趋势已成必然。通过大语言模型的对话能力,直接挖掘、释放数据的价值,可以极大的降低数据使用者的门槛,爆发出更多的可能。
11 月以《大模型时代下的数据新视界》为主题的线下社区 meetup,邀请产、学、研的领域专家围绕大模型和数据衍生出的几大探索方向:向量数据库、LLM+Data、LLM+SQL、LLM+Tools 分享各自的技术探索和实践经验,共同探讨关键问题和发展趋势。接下来的几期内容将以文字版的形式分享给 DB-GPT 社区的同学,共同学习和探讨。


本文主要跟大家分享面向大模型时代的数据库 Milvus,Milvus 项目从 2019 年开始就开源了,做了四年时间,也分成了两个阶段。从 2021 年开始一直是有个标签叫 Cloud Native,2022 年开始也有了一个新的标签 AI Native。
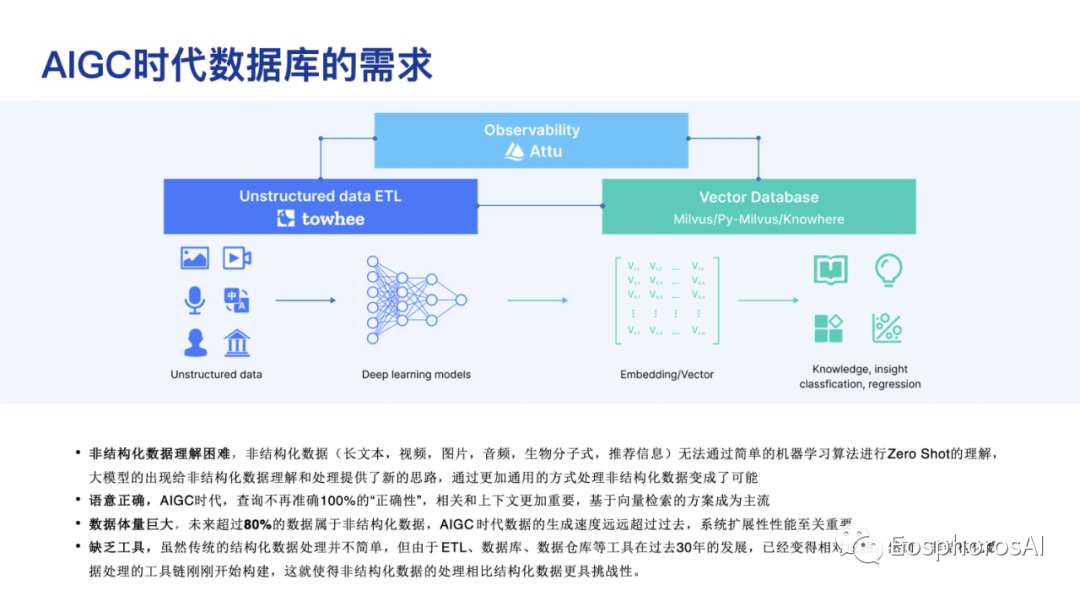
向量数据库的诞生,其实就是去解决非结构化数据处理困难的一个问题。因为非结构化数据不仅仅包含今天在聊的一些长文本的信息,还包括视频、图片、音频等多模态信息,多模态大模型现在也是一个很火的话题。
大概从 2019 年开始,向量数据库第一个切入的场景是图搜和文图互搜的场景,所以最开始的 target 就是解决 “非结构化数据如何进行检索,如何去做语义检索“ 的一个问题。当然,这里面其实存在了很多的问题,有模型侧的、有 infra 侧的。
大家可以看到随着动态模型的发展,包括大模型发展,问题其实已经有了比较初步的一些解决方案。但在 Infra 侧,如果面向非常海量的数据,怎么能从十亿级别、百亿级别的这些图片里面、文本里面很快地召回所需数据,去给大模型提供更好的能力。无论是做 RAG 或 Agent 里面所谓的 Long-term memory ,或者说在大模型训练推理的过程中,其实都有类似的诉求,这也是向量数据库诞生的最开始的一个初心。
为什么向量检索这件事会跟数据库结合起来?大家如果提到如何去处理数据,一定会想到用 OB、ODPS 以及各种各样的数据库去做。但是在非结构化数据领域,从 AI 开始 popular,或者从 AI 变得 news network popular 开始,大家做的类似是一种烟囱式的应用。就是说一个 AI 的团队,自己负责上面训练模型下面洗数据,所有的数据治理,所有的 Infra 这一侧,甚至是 pouch 都是算法团队自己维护。当然可能大厂会好一些,但是我觉得在未来 AI 再往后发展 5 到 10 年的话,一定会有一个分层的过程,所以希望能够给大家提供的是一个非常好的 AI 数据侧的 Infra。
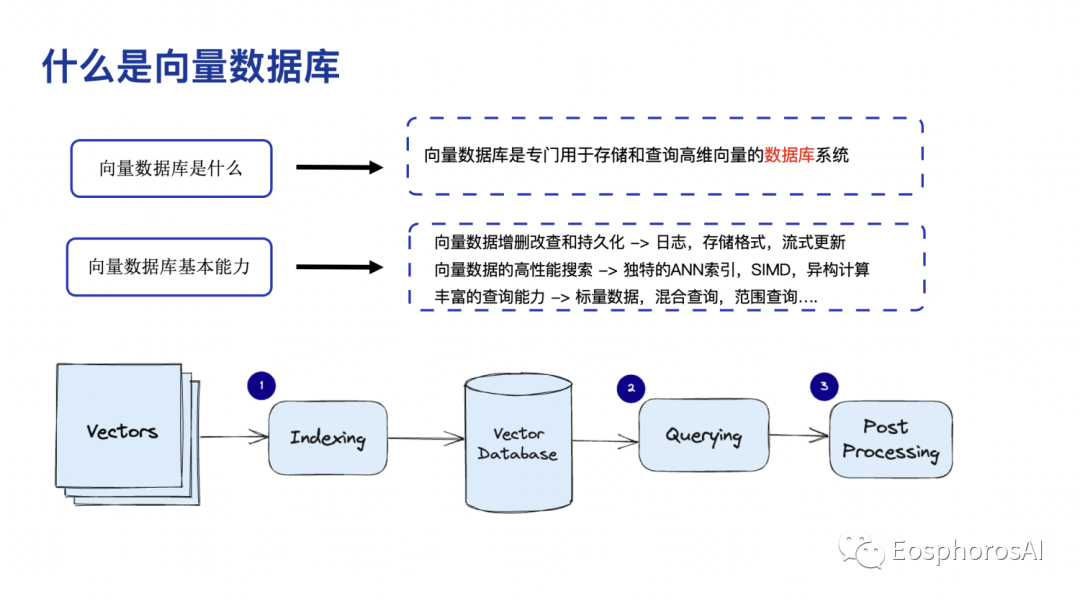
什么是向量数据库?简单来理解向量数据库就是管理和查询高维向量的一个系统,它有几个显著特点:
第一,既然是一个数据库,要具备基本的增删改查的能力。现在很多的向量数据库,或者说上一代的向量检索系统,它的更新能力、删除能力是非常弱的。还是类似传统搜索的这种离线导入的模式,每天搞一批数据,训完以后一把导进去。这样来看,它不是一个向量数据库,既然是一个数据库,基本的 CRUD 是要支持的很好的,要有一个基本的schema 的定义,明确支持的数据类型,当然可以是一个 dynamic scheme,但是既然作为数据库,它应该符合数据库的一些基本的要求。
第二,很显然向量数据库的一定要具备很强的向量检索能力。
最后,向量数据库的语义一定要足够的丰富,只做 ANN 是不是向量数据库呢?我认为是的,向量数据库最基本的操作就是最近零匹配,但实际上向量数据库在发展的过程中,演化出了非常多新的语义,其实是一个非常有意思一个 topic 。所有的传统的数据库里面能够实现的操作,比如说 join、groupby、count,在向量数据库里都有对应的实现。
整个向量数据库使用的过程可以分为三个阶段。第一个阶段怎么搞到向量?搞到向量当然就是靠 embedding 模型,OpenAI 的 Ada,国内也有非常好的开源模型,包括BGE、阿里的GTE,其实都是非常好的 embedding 的模型,embedding 生成以后,插入到向量数据库当中来。中间会存在一个传统搜索里面大家都在做的一个事情,也就是第二阶段索引构建。索引它是偏离线的,算力消耗很高,所以向量数据库的一个核心挑战就是如何能把索引的开销给降低。另一个核心开销就是说怎么在索引的过程中尽可能的去挖掘数据之内的一些联系和语义,来降低 online serving的时候查询负载。第三阶段就是构建好索引后 Query,Query里面也有很多核心挑战。比如说如何应对 streaming version,如何应对delete,如何应对各种各样复杂的语义,性能也是一个很重要的挑战。
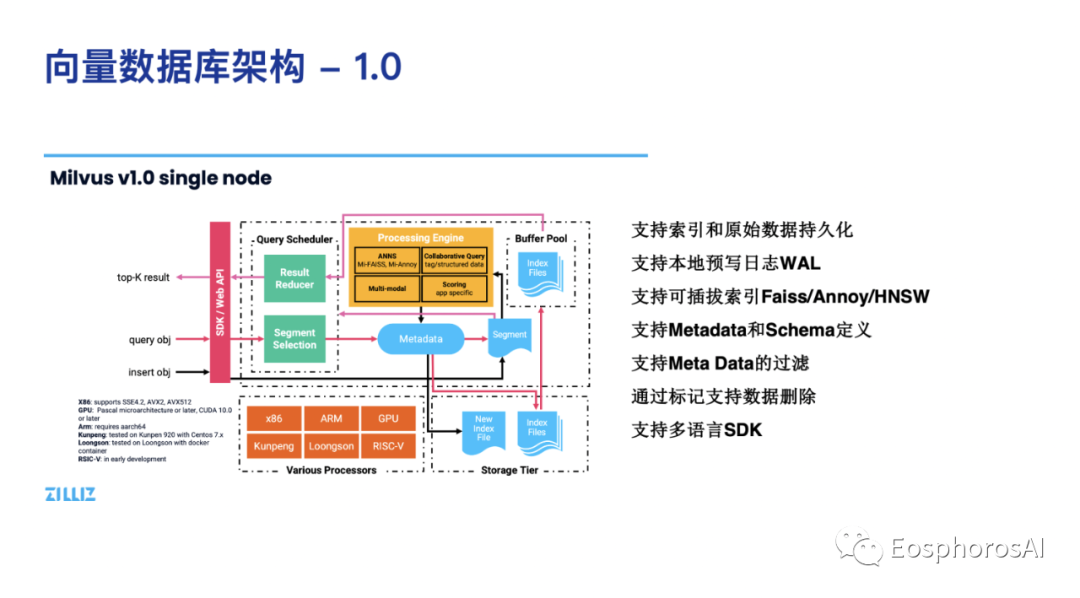
上图是 Milvus 1.0 的架构图,是最开始 2019 年的时候,定义向量数据库应该长的样子。简单的理解就是有一个预写日志,有一个文件系统去存文件,有一个引擎如向量索引 Faiss/Annoy/HNSW, 有一些 meta 和 schema 的定义,可以去做一些基本的过滤操作,能够支持简单的删除,但是性能不好,能够支持多元的 SDK。这是最早的关于向量数据库的一个定义,可以说在全世界也是第一个定义向量数据库的。我们曾经发过一篇 SIGMOD 21,讲的就是向量数据库究竟是什么。
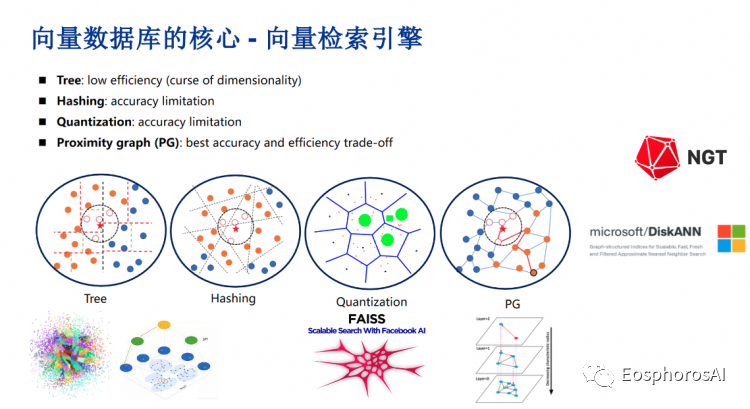
由浅入深,向量数据库的核心是什么?其实就是向量索引,向量索引也是向量数据库能够高性能地进行索引数据、查询数据的一个关键所在。
向量索引有非常多不同种类的实现,上图列了 4 种比较主流的,比如基于数最典型的是 Annoy,还有基于哈希等。因为性能、精确度问题,现在已经不是业界非常主流的查询模式了,最主流的是基于Quantization 的 FAISS 。FAISS 是一个很好的实现,但在 Quantitation 的这条链路里面,现在又有了一个比较有竞争力的 competitor 是 google 的 scan,这也是在开源里面性能比较好的一个框架。最后一个就是精灵图,那么在精灵图领域最广为人知的是 HNSW,它其实是类似于跳表的一个设计。最底层是一个完整图,上层建了一些索引图。这样子大家在搜索的时候可能跟一个跳表一样,先从上面找到一些邻居节点,一层层往下找,找到最底下最终的一个查询结果。图也有非常多的变种,比如说雅虎开源的 NGT、Microsoft 开源的基于磁盘的图方案。感兴趣的话大家可以去读相关的 paper,基本上每个项目背后都有相应的 paper,也可以看看向量检索的一个链路。

我们需要一个数据库,也需要向量检索,那为什么不是 PGvector 或者 Elasticsearch 呢?这就是一个特斯拉和老爷车之间的关系,这么类比,最主要的原因是如同所示的这几个点:
第一,向量数据和标准数据之间数据的分布是存在很大的差异的。举一个例子,所有的传统数据库,基本上是基于哈希去做路由,或者说基于 range 去做分片的,这样在查询的时候才能比较高效地利用主键索引、二级索引。但在向量数据库中,无法用向量去做分片,这是一个最基本的逻辑,因此对于绝大多数的向量数据库而言,搜索是需要去查所有分片的,这更像是一个 OLAP 的使用场景。就是有点类似于 MPP 的架构,但是又不完全是 MPP 的架构,所以很多 OLTP 数据库天然就已经不适合去做向量检索这些事情了。
第二,Not hundred percent accurate matters。什么叫不完全正确很重要?是因为大模型本身就不是一个很镇定性的一个系统,它并不能给确定性的答案。而大模型的搜索需要的也不是一个百分之百正确的一个答案,它需要的是相似匹配的一个答案,这就是大家所谓的语义。那这种语义带来的作用是什么?大家都知道 OB 系统它能应用在 transaction 的用场景里面,靠的就是稳定性,靠的就是正确性,任何一笔 transaction 都是不能错的。而在向量检索领域里面,约束条件可以把它去掉了,它根本不关键,只要能拿到一个相对来讲 reasonable 的一个答案就 ok 了。因此背后会有一个非常大的 optimize 的空间。如果所有的数据库不需要保证百分之百正确,大家可以想象数据库可以优化 10 倍,可以优化 100 倍,空间是非常大的。过去提的 AI for DB 的概念,在传统数据库里面会发现应用起来会非常难,但是在向量数据库就可以 work,并且 work 得非常好。用模型去做 Auto Tune,效果非常好,并且损失非常低。
第三,算力的要求。传统的数据库瓶颈可能会在 IO 上面,也可能会在网络上面,部分数据库可能会在 CPU 上面,绝大多数数据库,尤其是 OLTP 数据库,它的瓶颈一般都不会在 CPU 上面。但对于向量数据库,它的瓶颈就在 CPU 上面,或者更精确一点就在内存带宽上面,这就意味着其所面临的挑战跟传统的数据库是完全不一样的。因此需要尝试用很多方法,要优化带宽,要优化 Cache、异构算力,这也是为什么向量数据库可以跟 GPU 很好结合的一个原因。
最后一个点,语义的复杂度会变得越来越高。过去向量数据库是做 ANN 的,Elasticsearch/PG 也能做 ANN,但是向量数据库不止于此。
可以看到有很多查询的 pattern 出现,比如基于聚类去做过滤。举个例子,现在搜索狗的照片,但是表达为 “不想要猫的照片”,这类查询如果如果放在一个 fast 里面,应该去怎么做?我觉得很难去做,只能再给猫打个标签,这又回到了传统数据库的老路上面去。但能不能把猫的聚类完全给过滤掉,或者说能不能做一个更有意思,叫做 KNN join 的一个场景。就是给两个表,一个表里面放男嘉宾,一个表里面放女嘉宾,通过向量的近似度的方式去把男嘉宾和女嘉宾 match 在一起去,这些其实是一些非常有意思的一些场景。也就是说传统数据库能做的东西,很多事情向量数据库都可以做,关键是怎么做。
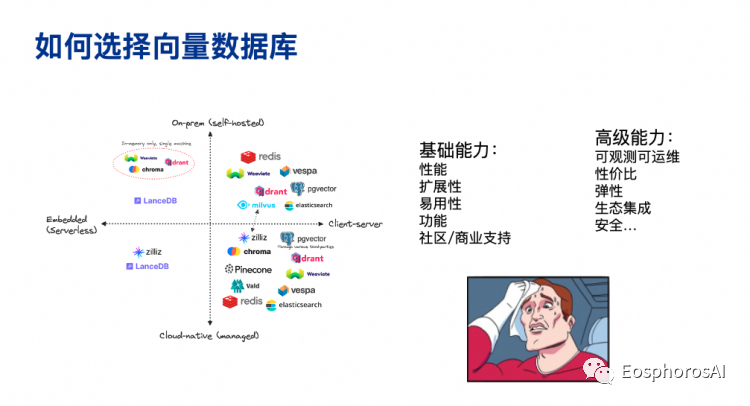

我们为什么要做 2.0 产品?对于上面描述的 Milvus 1.0 的产品架构,是一个非常 naive 的一个数据库实现。从 2021年开始,我们决定要把数据库重做一遍,一个标签就是云原生和 scalability 。
当然要做云原生的话,肯定有些关键点是跑不了的。第一,如何跟云基础设施结合?做了存算分离,流式数据是存在一个 distribute WL 里面的。第二个很重要的点就是随着数据量的增大,用户的数据确实放不下了,这也是促使我们必须做分布式系统的重要原因。第三,如何与公共云结合。2021年,K8S 已经非常成熟的一个系统了,所以团队就一直在思考怎么能用 K8S 更好的去跑一个无状态的数据库。最后第四点,对 AIGC 的使用场景中,Serverless 是非常重要的一个点。因为绝大多数的大模型都是 API 的 service,所以对于广大的开发者来讲,他们不希望自己去维护底层的基础设施。最后,情怀。抛开商业因素,Zilliz 希望做一款顶尖的数据库产品,希望可以做成一款分布式的向量数据库,结果也确实做出来了。
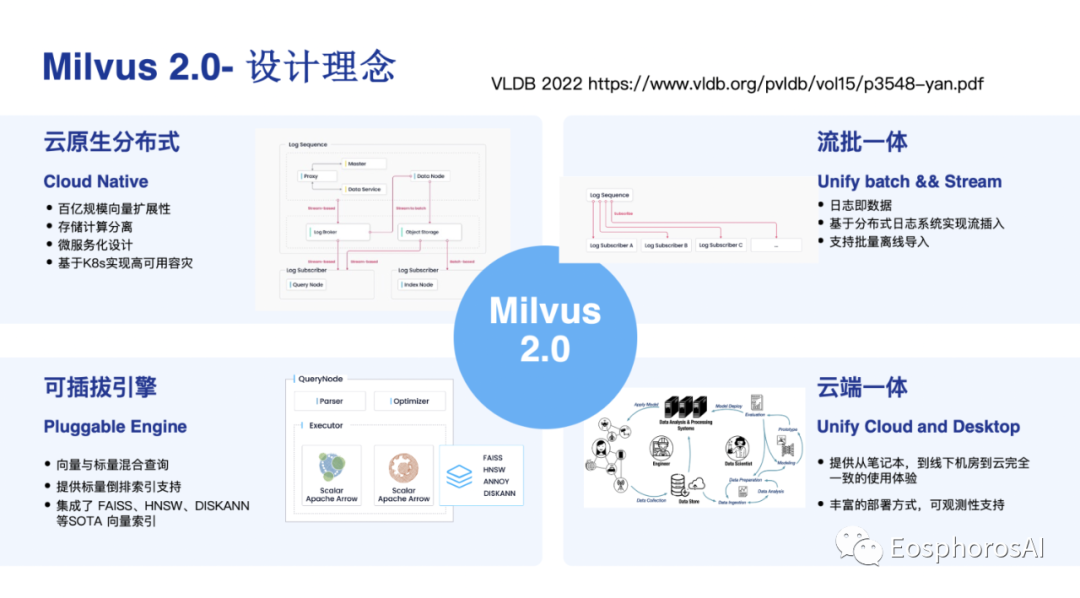
如上图,这是 Milvus2.0 为用户提供的一些核心的能力。
第一,云原生分布式,我们希望能支持百亿规模的向量扩展,具备足够好的弹性存算分离。所有的数据全部都是存在底层的存储里面的,对象存储、消息队列等。
第二,流批一体,这并不是所谓的这种传统的 lambda 里面的流式,而是希望真正在一套系统里面能够很好的去解决用户的流式插入,并且能够实时查询的这种能力。
第三,引擎可插拔。大家可以看到整个 record index 有非常多的选择,不同的选择之间是有不同 trade-off。有的性能更好,有的内存占用更低,没有办法说出一个完美的索引,满足所有人的需求。现在来看,可能对于大公司来讲,性能是一个很重要的 concern。但对小公司来讲,可能成本或者内存的占用,这些其实变成非常重要的指标,因此希望引擎本身是可以可插拔的。
最后,云端一体,大家可以非常容易的在自己的笔记本上去做部署,也可以在自己公司的 K8S 里面去跑,更为重要的是可以在云上去跑。
未来在大模型的生态中,API 会成为最重要的一个武器。大家已经看到了OpenAI 的 assistant,包括它的 GPTS,本质上其实就是 functional call。虽然也提供了很多 retrieve 的能力,但至少 function calling 是最重要的。它可以把所有很多东西串在一起,能够帮助开发者最快速的去构建。因此API可能会变成未来数据库产品的一个飞轮。有 SQL 的支持固然很好,但如果没有 SQL 支持,API 足够的 popular,大模型学会了如何去写 API 的话,开发者的门槛一样是很低的。
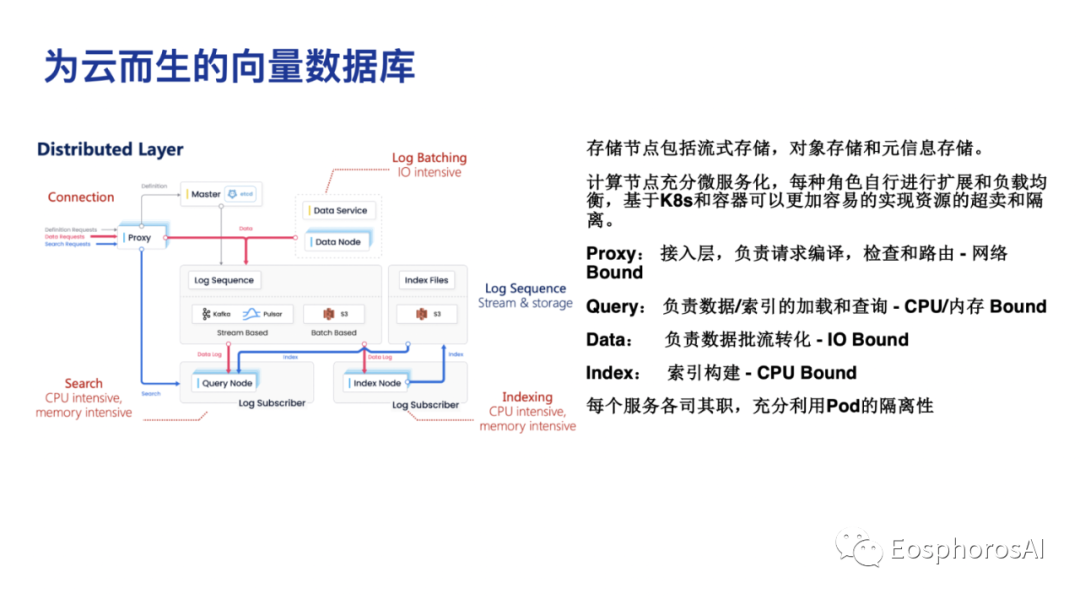 如上图,这是 Milvus2.0 的最终架构,整个的设计理念其实就两点,第一存算分离,第二所有的计算节点微服务化。所有索引节点,所有的 query 节点,所有的数据节点,包括前面的代理全部都是 K8S 的 pod,全部都是微服务化。所有的数据全部都存在中间这一层,基于 Kafka 和 S3 去存,系统可以跟着 K8S 非常快的去做 scale,只需要去做一些内存的变化,一旦 scale 以后,数据直接从 S3 里面拉起来。
如上图,这是 Milvus2.0 的最终架构,整个的设计理念其实就两点,第一存算分离,第二所有的计算节点微服务化。所有索引节点,所有的 query 节点,所有的数据节点,包括前面的代理全部都是 K8S 的 pod,全部都是微服务化。所有的数据全部都存在中间这一层,基于 Kafka 和 S3 去存,系统可以跟着 K8S 非常快的去做 scale,只需要去做一些内存的变化,一旦 scale 以后,数据直接从 S3 里面拉起来。
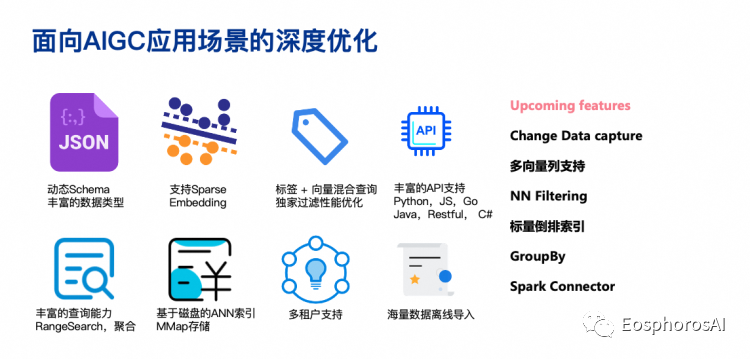
Milvus 还提供了面向 AIGC 场景的一些丰富能力。这些是在上一代的向量检索中所缺失的。
Sparse embedding,就是大家非常熟悉的 TF-IDF(Term Frequency-Inverse Document Frequency)和 BM25(Best Match 25)。但今天的稀疏向量有基于 AI 的提取方式,它可以更好地去帮大家做关键词的匹配,标量和向量的混合查询能力以及丰富的 API 支持。
支持多租户,如果今天要构建一个 knowledge base,可能有 100万个用户,在数据库里面它的 schema 到底应该如何设计?如果使用传统的一个表一个用户的方式,可能的表的数目会爆炸。如何能在一个向量数据库里面很好的去支持多租户是一个挑战,不过 Milvus 已经具备了这种能力。
海量数据离线导入的能力,类似于 hbase 里面的 Bulk Insert、Bulk Load。有这种非常快速可以把亿级甚至 10亿级别的数据导入到向量数据库里面并立即提供查询的一个能力。
另外,Dynamic Schema;Range search;磁盘索引,基于 MMAP 的把数据放在磁盘上的能力,这是绝大多数向量数据库不具备的能力。
除此之外还有很多其他能力,比如说 CDC、多向量的支持、标量索引的倒排等,这些都是在的设计的计划里,预计会在今年陆续上线。
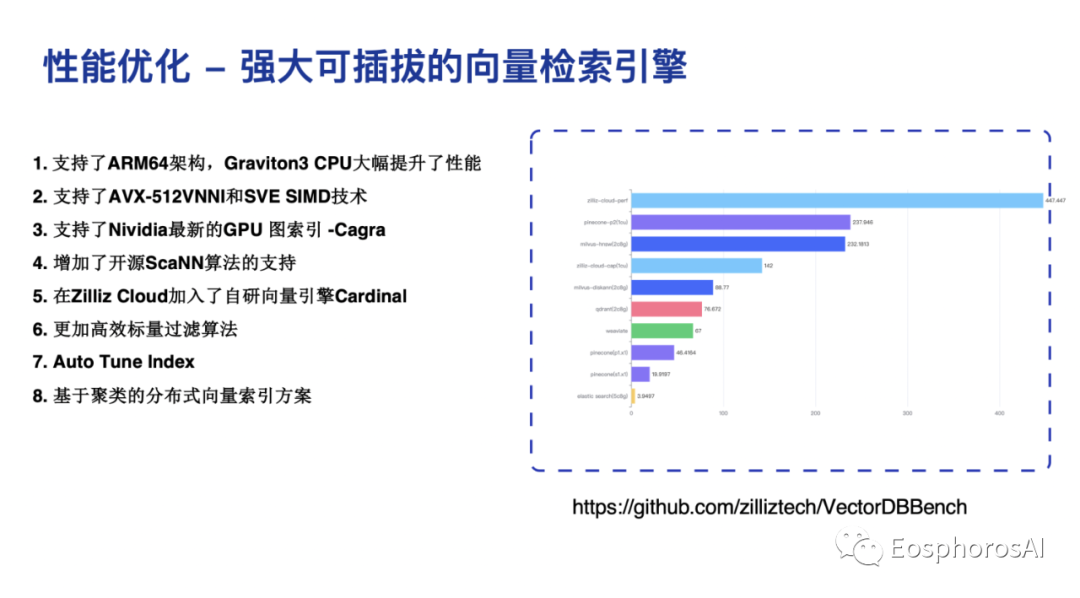 最后说一下性能。提起向量数据库,用户最关心的一定就是性能。如果大家感兴趣或者是做向量数据库,可以跑一下的 VectorDB Benchmark,它是完全开源的,有比较丰富的测试集,包括过滤的测试集、各种各样不同参数的搜索、不同大小的数据集。
最后说一下性能。提起向量数据库,用户最关心的一定就是性能。如果大家感兴趣或者是做向量数据库,可以跑一下的 VectorDB Benchmark,它是完全开源的,有比较丰富的测试集,包括过滤的测试集、各种各样不同参数的搜索、不同大小的数据集。
那么如何去优化数据集呢?其实主要就三件事情。第一是算力,如何找到最便宜最高效的算力,除了 GPU 以外,ARM 是可以去深度挖的一个点,包括所有 Intel CPU 新的指令集,现在用 AVX-512 VNNI 以及最新一代的 amx 指令集,其实对性能有非常好的提升。目前,支持的 ARM SVE 的厂商比较少,我们是在 amx 上面去做的。另外,支持NVIDIA 最新的 GPU 图索引,我们也把它贡献给了社区,性能比传统的 GPU index 要好很多。
第二个其实是算法侧,算法包括怎么去优化图,怎么去提升图的质量,怎么在搜索的过程中尽可能去剪枝,是优化性能一个很重要的方式。
最后,是查询的调度,包括 dynamic batching,如何做请求的合并,如何让集群的负载变得更加的均衡,回到传统数据库的领域。所以向量检索事情本质上是一个高性能计算加数据库,这是大家要去做的一个事情。

这些传统的场景大家可以看下,不再过多去展开了,大家如果是做这些相关业务的话,可以具体去聊。
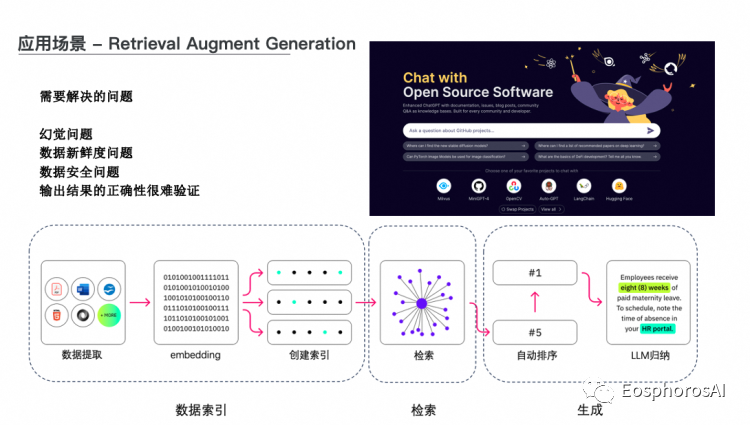
第一个应用比较多的场景是 RAG ,主要解决了四个问题。第一个是大模型的幻觉问题,第二个是数据的新鲜度问题,第三个是数据的安全问题,最后一个是用大模型去输出结果如何验证的一个问题。因为 RAG 是会给一个 reference link,无论大家用图数据库来做,还是向量数据库来做,两者之间并不冲突,是一个很好的补充。
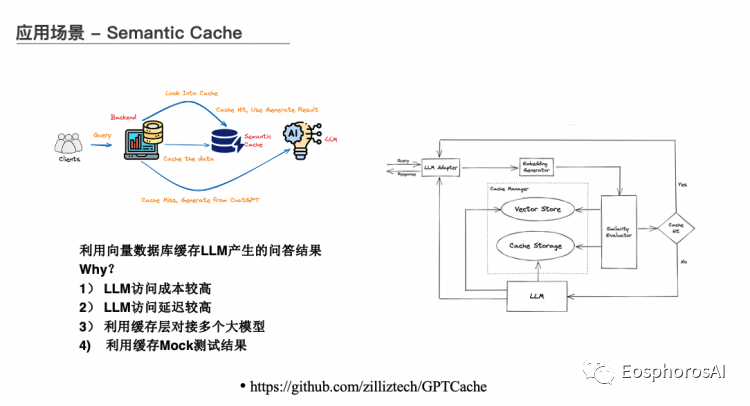
第二个有意思的场景叫 Semantic Cache。在 github 上面有一个蛮火项目叫 GPT Cache。最简单的一个思路是用 redis 去缓存 mysql 的数数据,有没有可能去缓存一下大模型的输出的结果,所以就做了这么一个项目。
其实整个的思路没有很复杂,用向量数据库做了语义的检索,如果问题语义匹配的话,就认为答案可能是相似的。目前可能还不完全是一个非常 production ready 的场景。但是确实给了很好的思路,并且在大模型的推理阶段,大家也会用这种类似的思路,基于召回,再去给大模型做加工,可以省掉很多 token,也是蛮常见的一个思路。

最后给大家分享一个比较新的话题,对于 openapi dev day 怎么看?大家也都知道 11月6日新开的发布会,推了几个比较重要的功能。第一个就是构建自己的 GPT,第二个就是关于 GPT-4 turbo支持非常长的 token,第三就是支持召回,支持function call。比较关注的是多模态 API,我们做了很多测试,结果可以给大家简单分享一下。我觉得 openapi 做召回还是在处于非常简单的一个阶段,大家解决不好的事情,它也没有解决的很好,比如说长文本的 summarize,就是给一本书,告诉书是做什么的,其实用 RAG 来解决是非常难的,包括很具体的问题,比如说有 100个 document,每个 document 有个 ID,问 document 的 ID50 讲什么事情?ChatGPT 会告诉搜不出来。我觉得搜索和大模型之间的深度结合,是一个非常好的 topic,本质上基于概率,因此搜索和和生成这两个问题一定是要一起去解决的。但是现在其实无论对谁来讲,都是非常早期的一个阶段。自己更希望大模型的公司,能去构建更好的一个生态,通过这种 function calling,以 agent 作为一个中心,所有的周边厂商提供更好的 API。比如说的图数据库可以提供一套 API,向量数据库提供一套 API,以 agent 为中心去把业务逻辑给串起来,是对未来的一个期望。

https://github.com/eosphoros-ai/DB-GPT
https://github.com/eosphoros-ai/DB-GPT-Hub
https://github.com/eosphoros-ai/DB-GPT-Web


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。