在AIGC领域频繁出现着一个特殊名词“LoRA”,这是一种模型训练的方法。LoRA全称Low-Rank Adaptation of Large Language Models,中文叫做大语言模型的低阶适应。如今在stable diffusion中用地非常频繁.
现在大多数模型训练都是采用梯度下降算法。梯度下降算法可以分为下面4个步骤:
- 正向传播计算损失值
- 反向传播计算梯度
- 利用梯度更新参数
- 重复1、2、3的步骤,直到获取较小的损失
以线性模型为例,模型参数为W,输入输出为x、y,损失函数以均方误差为例。那么各个步骤的计算如下,首先是正向传播,对于线性模型来说就是做一个矩阵乘法:
在求出损失后,可以计算L对W的梯度,得到dW:
dW是一个矩阵,它会指向L上升最快的方向,但是我们的目的是让L下降,因此让W减去dW。为了调整更新的步伐,还会乘上一个学习率η,计算如下:
最后一直重复即可。上述三个步骤的伪代码如下:
# 重复1、2、3
for i in range(10000):
# 1、正向传播计算损失
L = MSE(Wx, y)
# 2、反向传播计算梯度
dW = gradient(L, W)
# 3、利用梯度更新参数
W -= lr * dW在更新完成后,得到新的参数W'。此时我们使用模型预测时,计算如下:
引入LoRA
思考一下W和W'之间的关系。W通常指基础模型的参数,而W'是在基础模型的基础上,经过几次矩阵加减得到的。假设在训练的过程中更新了10次,每次的dW分别为dW1、dW2、....、dW10,那么完整的更新过程可以写为一次运算:
令:
其中dW是一个形状与W'一致的矩阵。我们把-ηdW写成矩阵R,那么更新后的参数就是:
此时训练的过程就被简化为原矩阵加上另一个矩阵R。但是求解矩阵R并没有更简单,而且也没有节约资源,此时就引出LoRA了这一思想。
一个训练充分的矩阵,通常是满秩或者基本满足秩的,即矩阵中没有一列是多余的。在论文《Scaling Laws for Neural Language Model》中提出了数据集与参数大小之间的关系,满足该关系且训练良好,得到的模型是基本满秩的。在微调模型时,我们会选取一个底模,该底模就是基本满秩的。而更新矩阵R秩的情况是如何的呢?
我们假定R矩阵是一个低秩矩阵,低秩矩阵有许多重复的列,因此可以分解为两个更小的矩阵。假如W的形状为m×n,那么A的形状也是m×n,我们把矩阵R分解为AB(其中A形状为m×r,B形状为r×N),r通常会选取一个远小于m、n的值,如图所示:
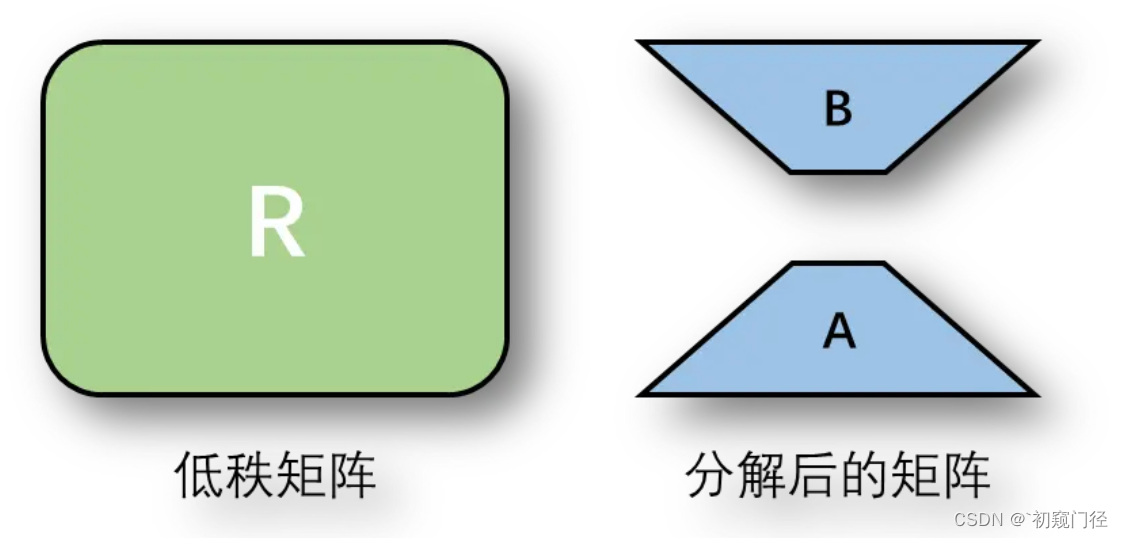
将低秩矩阵分解为两个矩阵几点好处,首先是参数量明显减少。假设R矩阵的形状为100×100,那么R的参数量为10000。当我们选取秩为10时,此时矩阵A的形状为100×10,矩阵B的形状为10×100,此时参数量为2000,比R矩阵少了80%。
而且由于R是低秩矩阵,所以在训练充分的情况下,A和B矩阵可以达到R的效果。这里的矩阵AB就是我们常说的LoRA模型。
在引入LoRA后,我们的预测需要将x分别输入W和AB,此时预测的计算为:
在预测时会比原始模型稍慢,但是在大模型中基本感觉不到差异。