前言
最近做项目,需要考虑双活设计,实际上笔者以前也简单介绍过双活架构的设计:
但是很多细节没有考虑,只是大致有哪些做法,而且考虑的问题也不够深入,详细说说双活设计的核心思想。
设计理念
实际上核心设计理念是存算分离,参考apache pulsar,这种设计实际上存储和运算在日常应用中就是分离的,How does Pulsar work:
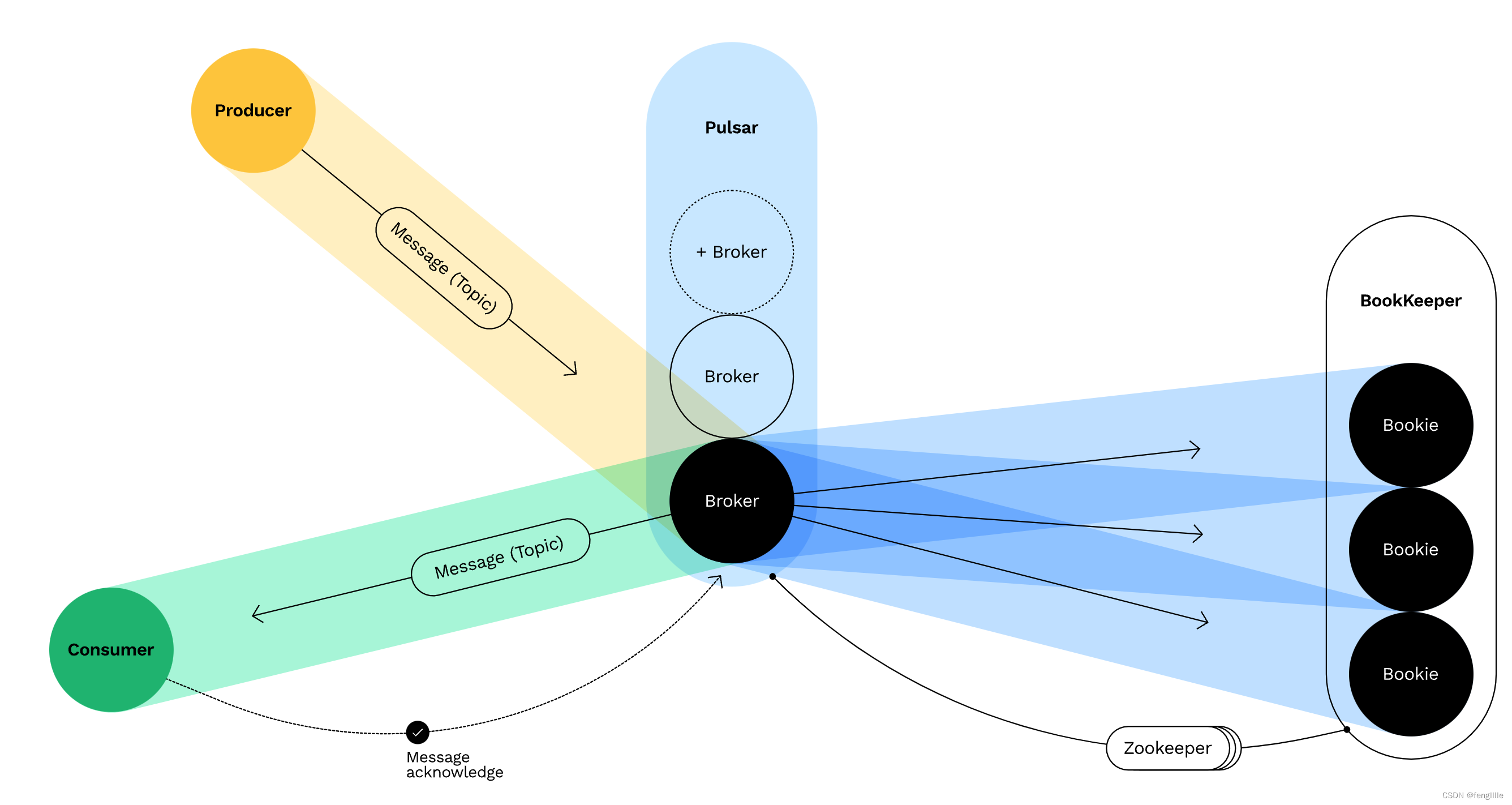
存储和运算分离
单元化设计
只不过连接资源是宝贵的,所以应用不能无线的扩容,所以有了单元化架构,实际上是把存算合并了,并单元化,但是在跨数据中心时,效率就会很低,一般使用部分数据复制的方式解决,类似单元化缓存,这就是比如我们在物理位置变了,打开某个app,第一次打开的数据加载很慢的原因,流量的标记分发存储。

其中一个单元不可用,那么损失一部分流量,以前出现过xx宝xx地区机房宕机导致某个地区服务不可用的情况,因为他们就是这种架构模式,比如安装地区分发流量,因为CDN和物理网络等因素,性能比较强。
延展集群
延展集群是一个集群,采用Paxos、Raft和ZAB(都是基于paxos变种)自主选主,复制算法,通过数据的复制,实现过半强一致和最终一致性。

复制实际上是没什么区别的,实际上连接集群也是类似的技术,不过很多中间件已经实现了,比如consul(raft),mongodb等。但是这种设计,必须两地三中心。
连接集群
连接集群是最传统的双活设计,主要是考虑的2点,数据复制和应用连接
复制过程
实际上连接集群的数据复制跟上面的延展集群类似,跨机房复制数据,但是一般没有开源解决方案,或者没有成熟的方案,需要自己实现,双活从某种意义上就是副本

每个机房有完整的数据,通过相互复制实现数据同步,需要考虑一致性和延迟与带宽的考虑,实际上数据的传递参考CPU的缓存设计,以Intel CPU为例

数据的交换一般是缓存,批量flush,决定效率的是缓存大小和缓存定时flush的时间。缓存满了,无论如何都需要flush;同理定时时间到了也需要flush(否则延迟会非常高),取最下限的逻辑。实际上包括硬件:CPU 内存 硬盘,中间件:MySQL,MongoDB,rocketmq等都是这么传输数据的,典型的NIO buffer设计。实际上CPU某些情况就是提升cache,升级IPC的。

跨数据中心同步,先本地缓存一部分数据,最好是定制的二进制(节省同步的空间大小),然后定时的flush到另一侧数据中心,有互联网和专线,专线比较贵(速度极快),AWS在中国就拉了专线解决2个数据中心延迟。
数据标签
数据的相互复制,需要对每一条写的数据打上标签,防止循环复制,读的数据没必要复制,如果发现数据标签与当前数据中心的标签不一致,则不触发复制的缓存写入。
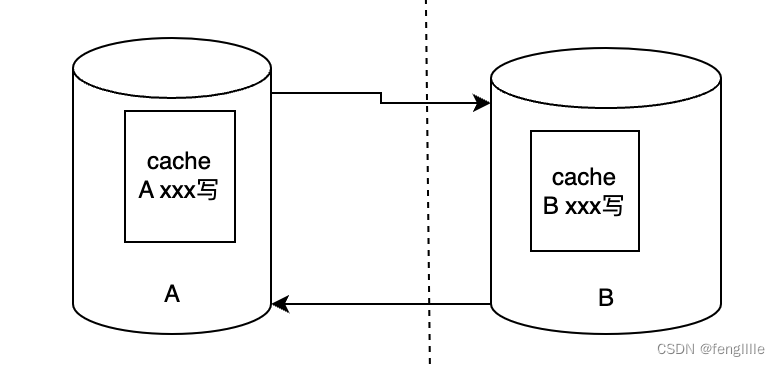
同时复制同步的缓存可以分离,分为发送缓存和接受缓存,使用不同的线程处理,避免业务交叉,读取和写入缓存线程。
集群使用
连接集群使用跟延展集群不同,延展集群是自主选主,多个节点自动切换,连接集群也可以自动切换,也可以手动切换,比如DNS切换,或者心跳切换,负载均衡切换等。
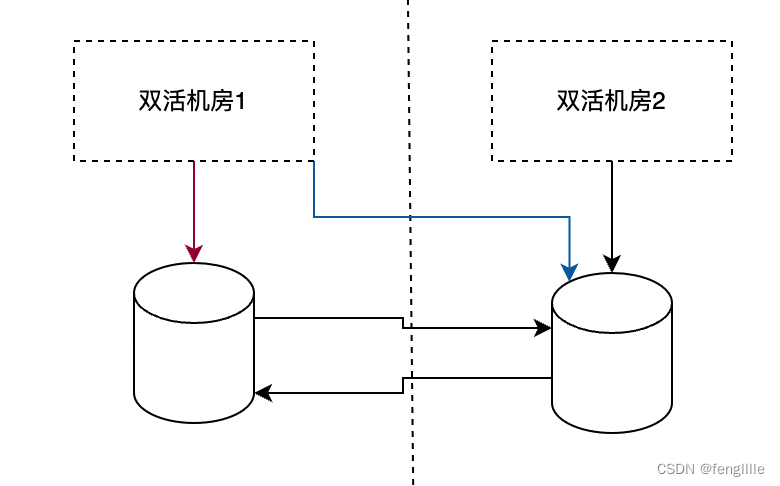
机房内的运算资源优先连接机房内的存储资源,实际上是一个大的机房单元,如果机房内发生故障(红线)自动或者手动切到另一个机房区(蓝线),要求连接域名或者注册中心或者VIP支持。
双活分片
分片集群实际上完美的适应双活架构,每个机房可以认为是一个分片,在分片的功能正常时是最小量数据流量的复制方案,但是一旦一个机房分片挂掉,那个分片的服务不可用,实际上单元化也是分片。

注意双向箭头。是相互连接,而不是复制,意味着机房1访问机房2的服务,通过连接机房2返回数据,缓存到自己本地,如果再有一个sidecar就很完美
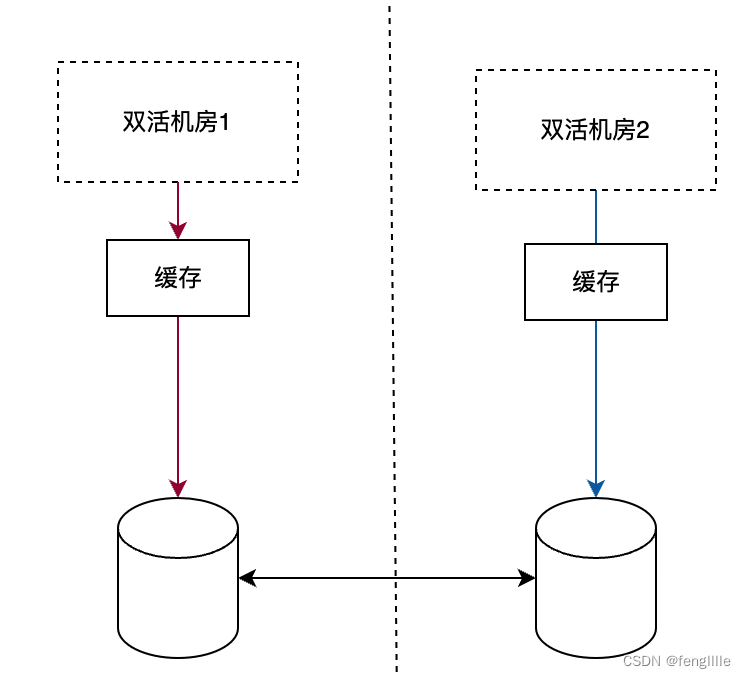
参考consul设计
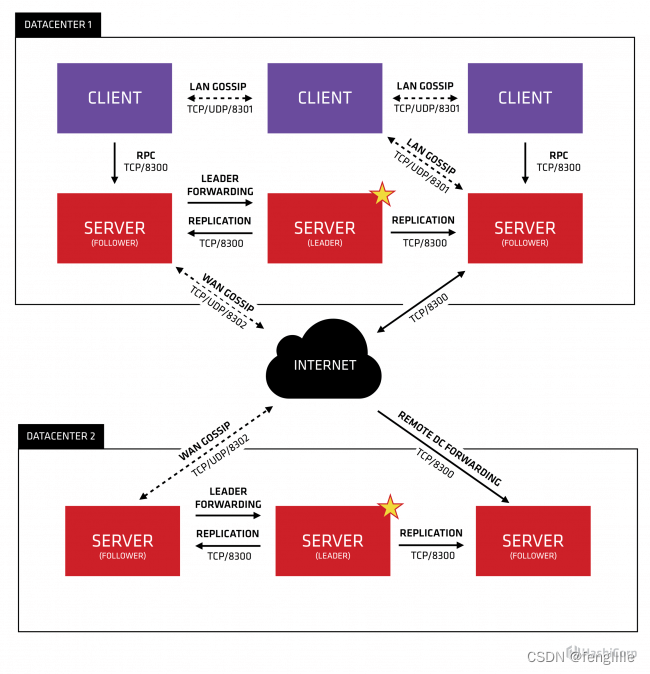
这种设计有个缺点,虽然不需要建立连接集群,也不用像延展集群和连接集群复制数据,但是 每个机房的数据不是完整的,其中一个机房的集群宕机,就会损失那个机房的服务,需要自我修复能力,比如挂掉后,连接不通就向另一个机房发起数据的写入,适合有定时心跳和定时注册的能力(数据量小),非常适合注册中心,所以consul集群就是这样设计。
总结
双活的设计是很有必要的,而且很传统的解决方案,融合了单元化思想,存算分离思想,实际上是矛盾又是统一的整体,单元化是有状态的,存算分离又是让运算无状态。那么设计存储一致性就很重要,保证一致性和最佳的性能,又会大量的使用缓存的思想。