实验二 模型机组合部件的实现(一)
班级 计XXXXX 姓名 wolf 学号 2021080XXXXX
一、实验目的
1.了解简易模型机的内部结构和工作原理。
2.熟悉译码器、运算器的工作原理。
3.分析模型机的功能,设计指令译码器。
4.分析模型机的功能,设计 ALU。
二、实验内容
1.指令译码器
指令译码器是根据指令系统表中的指令编码,对输入的 8 位指令进行解析,
| 汇编符号 |
功能 |
编码 |
| MOV R1,R2 |
(R2)→ R1 |
1100 R1 R2 |
| MOV M,R2 |
(R2)→(C) |
1100 11 R2 |
| MOV R1,M |
((C))→R1 |
1100 R1 11 |
| ADD R1,R2 |
(R1)+(R2)→ R1 |
1001 R1 R2 |
| SUB R1,R2 |
(R1)-(R2)→ R1 |
0110 R1 R2 |
| AND R1,R2 |
(R1)&(R2)→ R1 |
1011 R1 R2 |
| NOT R1 |
/(R1)→ R1 |
0101 R1 XX |
| RSR R1 |
(R1)循环右移一位→ R1 |
1010 R1 00 |
| RSL R1 |
(R1)循环左移一位→ R1 |
1010 R1 11 |
| JMP add |
add → PC |
0011 00 00,address |
| JZ add |
结果为 0 时 add → PC |
0011 00 01,address |
| JC add |
结果有进位时 add → PC |
0011 00 10,address |
| IN R1 |
(开关 7-0)→ R1 |
0010 R1 XX |
| OUT R2 |
(R2)→ 发光二极管 7-0 |
0100 XX R2 |
| NOP |
0111 00 00 |
|
| HALT |
停机 |
1000 00 00 |
判定是哪条指令,则对应指令的输出为 1,否则输出为 0。
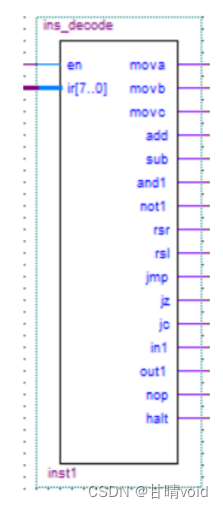
指令译码器的输入输出引脚如上图所示。en 为使能信号,ir[7..0]是 8 位指令
编码,输出是对应的 16 条指令。引脚之间的相互关系如下表所示:
表 2 指令译码器引脚关系
| en |
ir[7..0] |
16 个输出信号 |
| 1 |
8 位的指令编码 |
指令编码对应的指令输出为 1,其它输出为 0 |
| 0 |
8 位的指令编码 |
不管 ir 为何值,16 个输出全为 0 |
2.ALU
算术逻辑运算类指令:
ADD R1, R2
SUB R1, R2
AND R1, R2
NOT R1
这类指令的执行过程为:
由 R2 的编码通过 RAA1、RAA0 从通用寄存器组 A 口读出 R2 的内容,由 R1的编码通过 RWBA1、RWBA0 从通用寄存器组 B 口读出 R1 的内容,在 S3~S0和 M 的控制下,实现运算,经移位逻辑送入总线 BUS;由/WE 控制和 R1 的编码选择 RWBA1、RWBA0,将 BUS 上的数据写入通用寄存器 R1。其中 ADD 和 SUB 指令影响状态位 Cf 和 Zf。
指令具体功能如下:
| 汇编符号 |
功能 |
编码 |
| ADD R1,R2 |
(R1)+(R2)→ R1 |
1001 R1 R2 |
| SUB R1,R2 |
(R1)-(R2)→ R1 |
0110 R1 R2 |
| AND R1,R2 |
(R1)&(R2)→ R1 |
1011 R1 R2 |
| NOT R1 |
/(R1)→ R1 |
0101 R1 XX |
ALU 除了要完成 ADD、SUB、AND、NOT 运算外,还需在 MOVA、MOVB、
RSR、RSL 和 OUT 五条指令执行时,提供将数据传送至总线的数据通路。ALU
模块的输入输出引脚如下图所示:

其中m和s[3..0]是控制信号,控制a[7..0]和b[7..0]输入的数据进行什么操作,
并将产生的结果输出到t[7..0]、cf和zf。各引脚间的相互关系如下表所示:
表 3 ALU 引脚关系
| m |
s[3..0] |
t[7..0] |
cf |
zf |
| 1 |
1001 |
t=a+b |
有进位,cf=1 无进位,cf=0 |
和为零,zf=1 和不为零,zf=0 |
| 1 |
0110 |
t=b-a |
有借位,cf=1 无借位,cf=0 |
差为零,zf=1 差不为零,zf=0 |
| 1 |
1011 |
t=a&b |
不影响 |
不影响 |
| 1 |
0101 |
t=/b(注:b 相反) |
不影响 |
不影响 |
| 0 |
1010 |
t=b |
不影响 |
不影响 |
| 0 |
1100 或 0100 |
t=a |
不影响 |
不影响 |
三、实验过程
1、指令译码器
A)创建工程(选择的芯片为family=Cyclone II;name=EP2C5T144C8)
步骤:左上角 file->New Project Wizard->选择工程位置和工程名->选择芯片 Cyclone II,
available device 中选择 EP2C5T144C8->点击 next->最后点击 finish 完成创建工程
工程创建图:

B) 编写源代码
根据实验指导和要求实现的功能写出对应的 Verilog 代码。
步骤:左上角 file->new->Verilog hdl file->编写代码(模块名需与工程名一致)->编译
成功后保存到工程文件中
代码图:
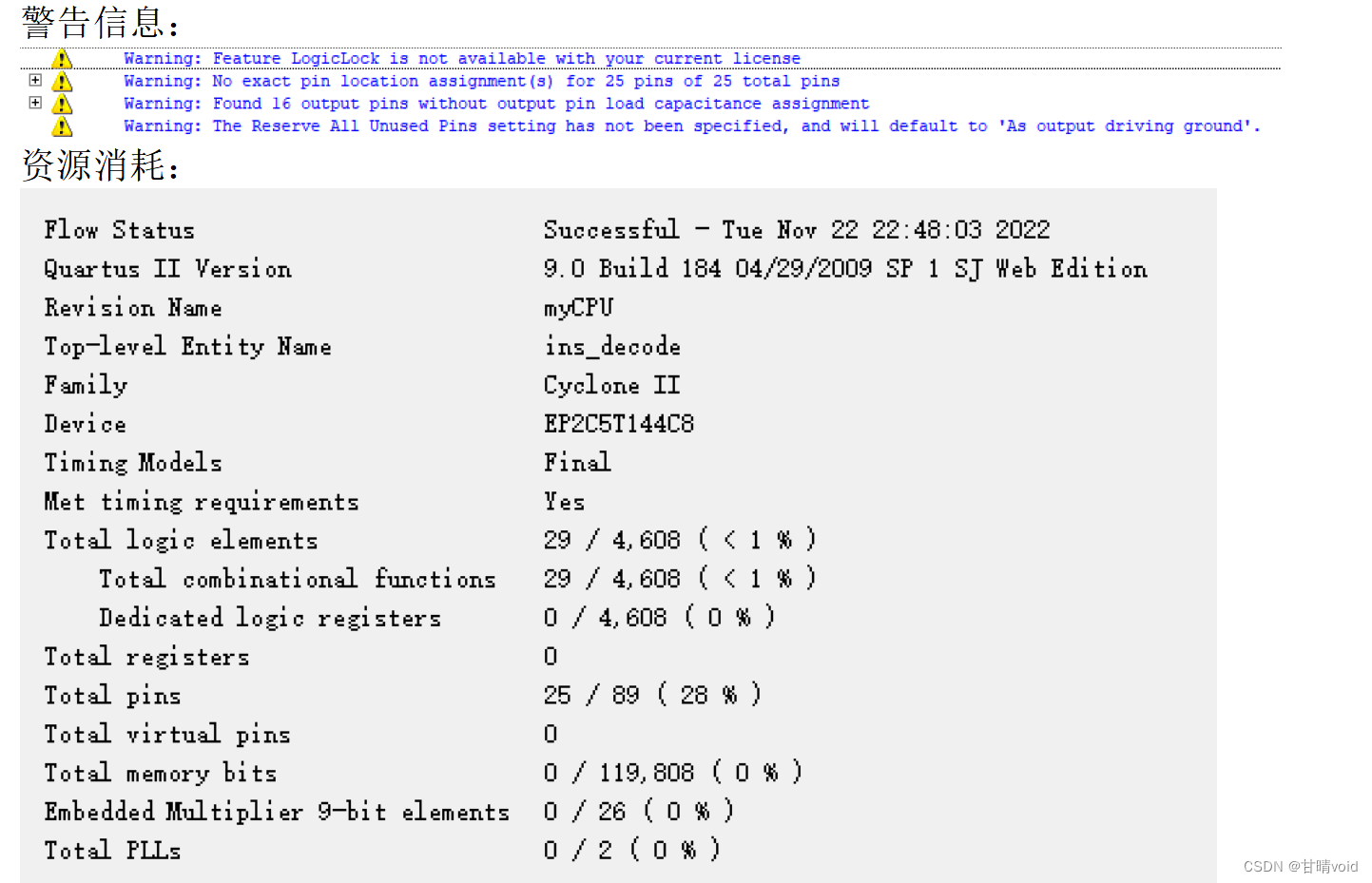
C) 编译与调试(包含编译调试过程中的错误、警告信息以及资源消耗)
确定源代码文件为当前工程文件,点击【processing】-【start compilation】进行文件编译,编译成功,保存文件。
D) RTL视图
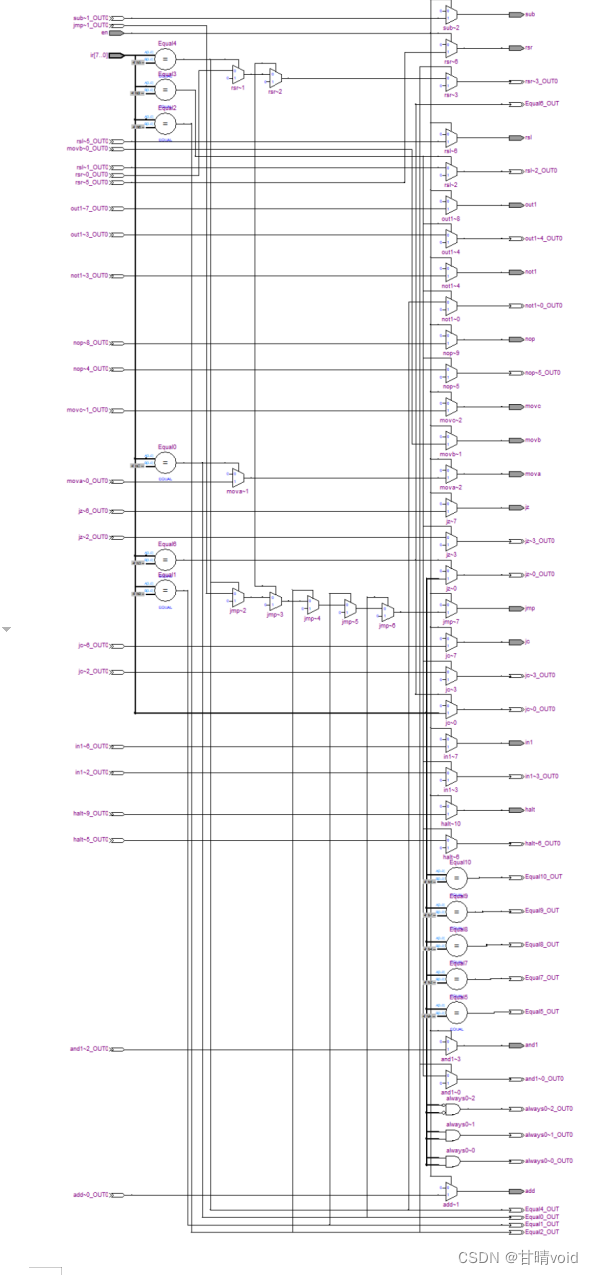
视图分析及结论:
分析:
- 由视图可得,视图左边为输入,右边为输出。
- 其中连接有一系列的元器件。比如比较器:当输入相等时输出 1,不相等时输出 0;
- 还有许多 2-1 选择器,当控制信号为 0 时,输出第一位,控制信号为 1 时,输出第二位。图中输入信号为 ir 和 en,输出信号包 括 add 等 16 种情况。各个输出端口之间通过导线相连。
结论:一个功能的实现需要经过多重门的处理后才能实现,一个元件的内部原理结构图十分复杂。
E) 功能仿真波形

结果分析及结论:
分析:功能仿真是指不考虑器件延时和布线延时的理想情况下对源代码进行逻辑功能的验
证。由仿真波形可得,对于输入状态的变化,输出结果实时变化,没有延迟,其结果与电路
设计的真值表的结果相对应。
当 en 为 0 时,不管 ir 为何值,16 个输出全为 0
当 en 为 1 时:
当 ir=11000000 时,mova 输出为 1;
当 ir=11001100 时,movb 输出为 1;
当 ir=11000011 时,movc 输出为 1;
当 ir=10010000 时,add 输出为 1;
当 ir=01100000 时,sub 输出为 1;
当 ir=10110000 时,and1 输出为 1;
当 ir=01010000 时,not1 输出为 1;
当 ir=10100000 时,rsr 输出为 1;
当 ir=10100011 时,rsl 输出为 1;
当 ir=00110000 时,jmp 输出为 1;
当 ir=00110001 时,jz 输出为 1;
当 ir=00110010 时,jc 输出为 1;
当 ir=00100000 时,in1 输出为 1;
当 ir=01000000 时,out1 输出为 1;
当 ir=01110000 时,nop 输出为 1;
当 ir=10000000 时,halt 输出为 1;
结论:功能仿真操作简单,能体现和验证实验的功能,但忽略延迟的影响会使结果与实际结
果有一定误差。
F) 时序仿真波形
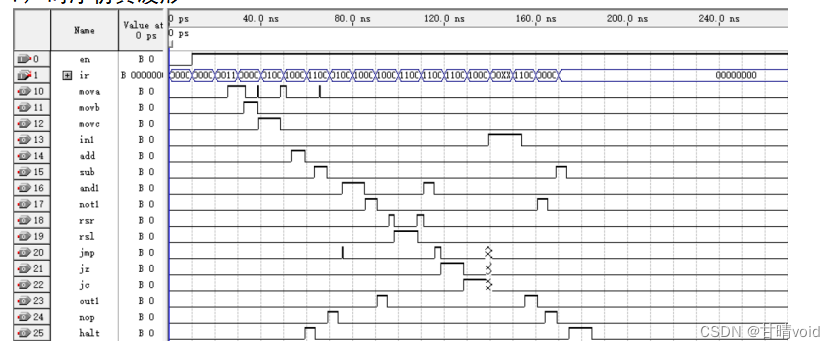
结果分析及结论:
分析:
- 时序仿真是指在布线后进行,是最接近真实器件运行的仿真,它与特定的器件有关,又包含了器件和布线的延时信息。
- 由波形可得,当输入状态发生改变时,输出结果并未同时改变,而是有一定延迟,同时由于输入状态的改变,导致电路出现“冒险”,导致输出结果并未与预期结果相同。
结论:
- 时序仿真可以用来验证程序在目标器件中的时序关系。同时考虑了器件的延迟后,其输出结果跟接近实际情况,但是考虑的情况过多,不容易操作,容易产生错误。
- 时序仿真不仅反应出输出和输入的逻辑关系,同时还计算了时间的延时信息,是与实际系统更接近的一种仿真结果。不过,要注意的是,这个时间延时是仿真软件“估算”出来的。
G) 时序分析
操作方法是:编译后,在compilation report中选择【timing analysis】-【summary】和【tpd】
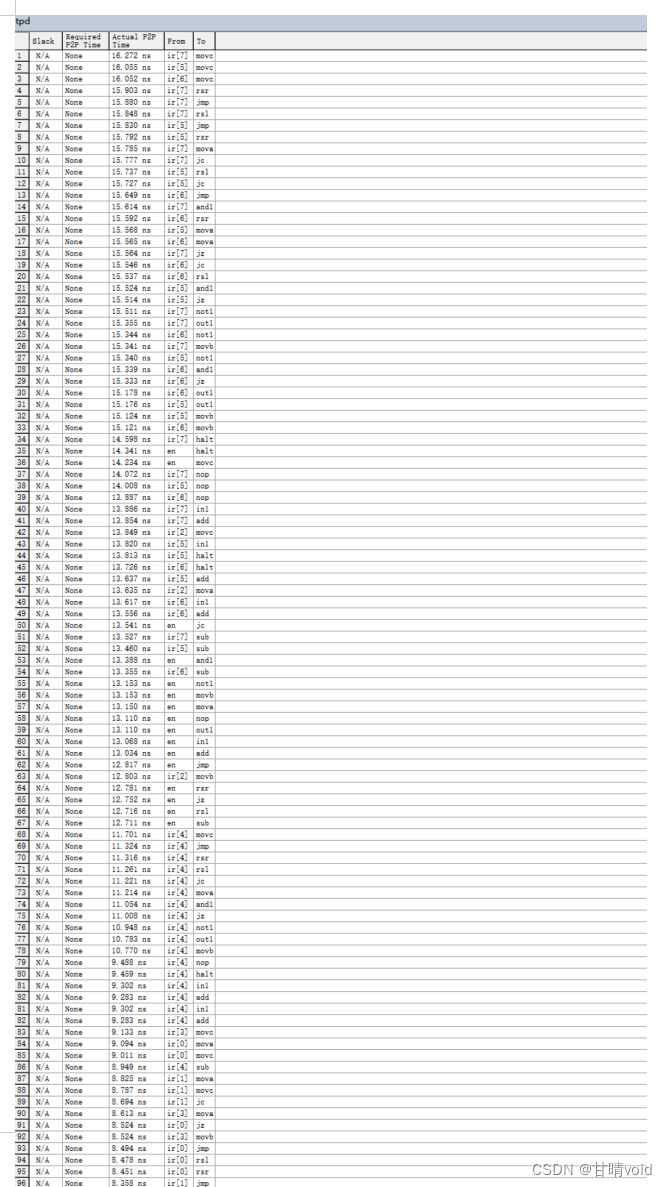
结果分析及结论:
分析:
1、由图可得,Timing Analyzer Summmary总结所有经典定时分析的结果,并报告每个 定时特性的最坏情况定时。比如从 ir[3]到jmp的最坏定时情况的 tpd 为 11.720ns。下面的tpd 报告表则给出了源节点和目标节点之间的tpd延迟时间,比如第二行中 ir[5]到 add 的tpd 为 11.699ns。
结论:实际连接图中个元器件连接之间是存在时间延迟的,而且不同的元器件之间的时间延
迟也不相同。
2、算术逻辑单元ALU
A)创建工程(选择的芯片为family=FLEX10K;name=EPF10K20TI144-4)

B) 编写源代码

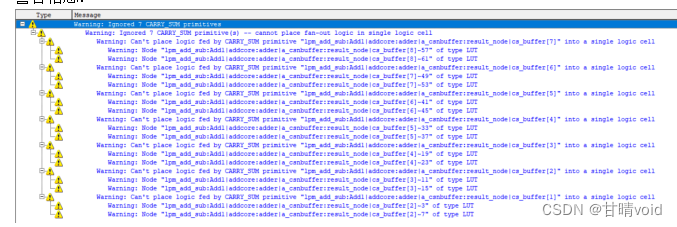
C) 编译与调试(包含编译调试过程中的错误、警告信息以及资源消耗)
警告信息:
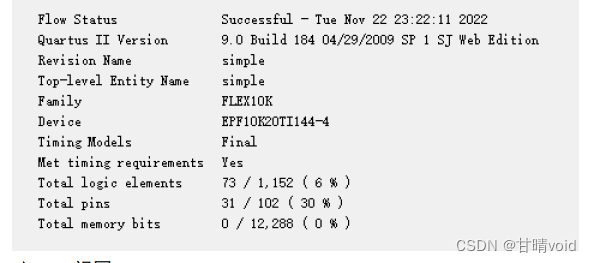
资源消耗:
- RTL视图
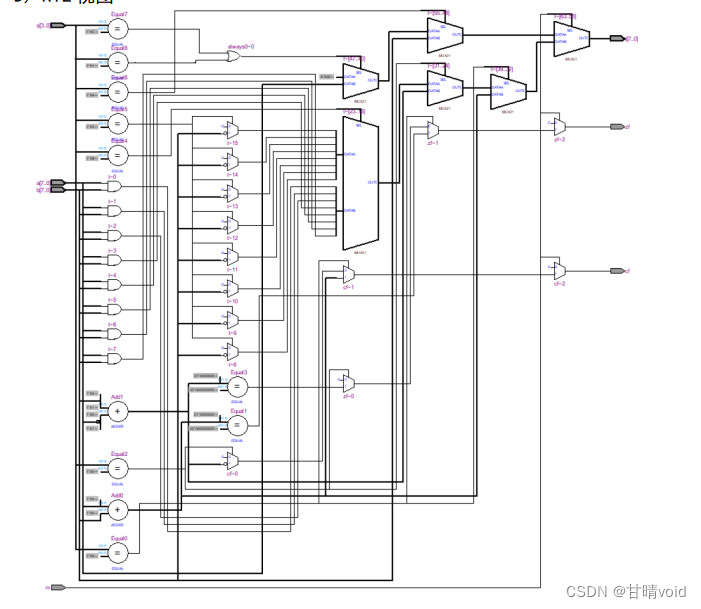
结果分析及结论:
分析:
1、由视图可得,视图左边为输入,右边为输出。其中连接有一系列的元器件。比如比较
器:当输入相等时输出 1,不相等时输出 0;
2、同时存在大量的 2-1 选择器,当控制信号为0 时,输出第一位,控制信号为1时,输出第二位。图中输入信号为 m,s,a,b,输出信号 为 t,cf,zf。各个输出端口之间通过导线相连。
结论:一个功能的实现需要经过多重门的处理后才能实现,一个元件的内部原理结构图十分
复杂。
E) 功能仿真波形

结果分析及结论:
分析:功能仿真是指不考虑器件延时和布线延时的理想情况下对源代码进行逻辑功能的验
证。由仿真波形可得,对于输入状态的变化,输出结果实时变化,没有延迟,其结果与电路
设计的真值表的结果相对应。
当控制信号 m 为 1,s 为 1001 时,执行 t=a+b
当控制信号 m 为 1,s 为 0110 时,执行 t=b-a
当控制信号 m 为 1,s 为 1011 时,执行 t=a&b
当控制信号 m 为 1,s 为 0101 时,执行 t=~b
当控制信号 m 为 1,s 为 1010 时,执行 t=b
当控制信号 m 为 0,s 为 1100 时,执行 t=a
有进位和借位时 cf 为 1,否则为 0;
和为 0 或差为 0 时 zf 为 1,否则为 0;
结论:功能仿真操作简单,能体现和验证实验的功能,但忽略延迟的影响会使结果与实际结
果有一定误差。
F) 时序仿真波形

结果分析及结论:
分析:
- 时序仿真是指在布线后进行,是最接近真实器件运行的仿真,它与特定的器件有关,又包含了器件和布线的延时信息。
- 由波形可得,当输入状态发生改变时,输出结果并未同时改变,而是有一定延迟,同时由于输入状态的改变,导致电路出现“冒险”,导致输出结果并未与预期结果相同。
结论:
1、时序仿真可以用来验证程序在目标器件中的时序关系。同时考虑了器件的延迟后,其输出结果跟接近实际情况,但是考虑的情况过多,不容易操作,容易产生错误。
2、时序仿真不 仅反应出输出和输入的逻辑关系,同时还计算了时间的延时信息,是与实际系统更接近的一种仿真结果。不过,要注意的是,这个时间延时是仿真软件“估算”出来的。
- 时序分析

结果分析及结论:
分析:
1、由图可得,Timing Analyzer Summmary 总结所有经典定时分析的结果,并报告每个 定时特性的最坏情况定时。比如从 a[0]到 zf 的最坏定时情况的 tpd 为 38.50ns。下面的 tpd 报告表则给出了源节点和目标节点之间的 tpd 延迟时间,比如第二行中 s[0]到 t[0]的 tpd 为 29.6ns。
结论:实际连接图中个元器件连接之间是存在时间延迟的,而且不同的元器件之间的时间延
迟也不相同。
四、思考题
1.指令译码器必须要16个输出吗?可否将一些输出合并,哪些可以合并,为什么?
答:不一定。jmp 和 add 可以合并起来,因为 jmp 是将 add 后的结果写入 pc 中,则可以进
行 add 操作后直接进行写入操作。Add 和 sub 和 and 操作可以合并,因为这三个操作类似,
且输出为使能信号,故可以用一个合并使能信号来作为三个输出的共同使能信号。
- ALU中的S[3..0]控制信号是来自哪里或者说与什么信息相同?
答:来自指令码 ir 的前四位。
3、为何S[3..0]等于1100或0100时将输入a传给t,S[3..0]等于1010时将输入b传给t?
答:S[3..0]为控制信号,当 S[3..0]输入为 1100 时,控制输出 t 等于 a,S[3..0]等于 1010 或0100 时,t 等于 b,此时 alu 相当于选择器。
五、实验总结、必得体会及建议
1、从需要掌握的理论、遇到的困难、解决的办法以及经验教训等方面进行总结。
(1)需要掌握的理论:基本了解了简易模型机的内部结构和工作原理。同时熟悉了译码器、ALU 的工作原理。学会 使用 Verilog 语言编写电路。
(2)遇到的困难:对于 QuartusII 的使用还不够熟练,特别是进行波形仿真的功能仿真和时许仿真分别怎么操作的方面有一定不足。
(3)解决方法:通过上网查询相关资料和询问同学后得以解决问题,并通过分析报告发现电路中的问题。有不理解的还请教了老师,不仅收获了方法还掌握的技巧。
(4)经验教训:对于电子电路的学习一定要肯动手,光是看是学不会的,一定要落到实处,多自己使用软件进行仿真,才能加深对于这门课程的理解。
2、对本实验内容、过程和方法的改进建议(可选项)。
1、对于“无影响”的变量,是否可以规定它的输出以实现更好的统一以及传递一些信息。
2、这两个模块是否还可以添加更多的功能以更贴合市场的需求。