1.torch.nn.Softmax
做什么的:将Softmax函数应用于n维输入张量,重新缩放它们,以便n维输出张量的元素位于[0,1]范围内,并且总和为1。
注意事项:需要指定按照行和为1还是列和为1,参数设置dim=1表示行和为1,dim=0表示列和为1。
计算公式:

难点:看到公式,手动该如何计算?假设需要进行softmax操作的张量是:[[1,2,3],[1,2,4]]是一个2*3规模的张量,经过softmax后,希望行和为1,手动计算过程(把公式列举出来,计算可以使用百度帮忙计算):
根据计算公式,把算式列出来,通过百度计算出结果。
![]()
![]()
![]()



手动计算结果出来了,接着写段代码来验证一下,看看是否和计算结果一致。
代码:
import torch
import torch.nn as nn
m = nn.Softmax(dim=1)
input = torch.Tensor([[1,2,3],[1,2,4]])
print(input)
output = m(input)
print(output)代码运行结果:
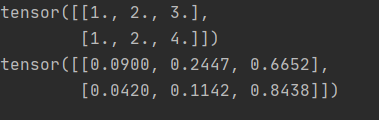
观察结果:结果都是小数点后保留4位小数,对比第一行手动计算结果,是一致的。接着按照同样的公式,把第二行的结果计算出来
![]()
![]()
![]()



对比结果中的第二行,确实是一致的。观察结果:每行的和为1,这是因为dim=1这个参数所控制的。
总结:该公式的意义有点像计算每个值占总和中的比例,总和为1,每个值的范围是[0,1]之间。可以理解为概率。
2.torch.nn.LogSoftmax
做什么的:通过softmax计算出来的占比,也可以理解为概率大小,因为都是0-1之间的数,概率很小的时候,还要进行连乘操作,会导致结果更小,为了避免下溢,将积运算转换为和运算,使用的公式是:
![]()
注意事项:公式中只写了一个log,底数没有给出,需要首先确定底数是多少,一般底数比较特殊的就是2和e以及10,e可以排除,如果是e,一般是写为ln,10为底一般可以写为lg,所以优先猜测是以2位底的,其次,计算机机器码就是0和1组成,所以是2的可能性很大。
计算公式:

观察公式,好像就是比Softmax的结果上加了一个log,也就是取对数。那我把上面计算结果去对数看看:
python中有数学公式,直接调用,这次就不要傻傻的去百度计算结果,因为输入的时候不好计算,对数m为底n的对数,输入不方便,所以调用现成的。
代码:
x00 = math.log(0.0900)
x01 = math.log(0.2447)
x02 = math.log(0.6652)
x10 = math.log(0.0420)
x11 = math.log(0.1142)
x12 = math.log(0.8438)
print(x00, x01, x02)
print(x10, x11, x12)运行结果:

这个计算结果就理解为手动计算出来的结果,也就是将softmax计算出来的结果,取了对数,可能存在一些误差,softmax计算出来的结果是保留了4位小数的。
为了验证手动计算结果是否准确,上代码,看看运行结果
代码:
import torch
import torch.nn as nn
m = nn.LogSoftmax(dim=1)
input = torch.Tensor([[1,2,3],[1,2,4]])
print(input)
output = m(input)
print(output)
代码运行结果:

结果显示:和手动结算结果是一致的。说明我们对公式的理解没有问题。注意:举例都是在dim=1参数下做的,不要把条件搞忘了。
总结:在softmax上加了对数,可以理解为对数概率。
3.torch.nn.NLLLoss
做什么的:负对数似然损失,训练分类。
手动计算过程:首先需要明确的点是:NLLLoss函数输入input之前,需要对input进行log_softmax处理。
假设数据是:[[1,2,3],[1,2,4]],标签为:[1,2] dim设置为1,按行求和
首先计算softmax,计算结果是[[0.0900,0.2447,0.6652],[0.0420,0.1142,0.8438]]
再取对数,计算结果是:[[-2.4076,-1.4076,-0.4076],[-3.1698,-2.1698,-0.1698]]
计算负对数似然,首先取负数,再计算,默认是取均值。
根据标签,1表示第一行的索引为1的的数,即:-1.4076
2表示第二行的索引为2的数,即:-0.1698
取负数后,1.4076和0.1698
求均值:(1.4076+0.1698)/2 = 1.5774/2=0.7887
注意事项:标签中的索引号范围是:[0,C-1],比如分为3类,则最多出现:0,1,2,不可能出现比0小或者比2大的数成为标签中的元素。
写段代码验证一下手动计算结果。
代码:
m = nn.LogSoftmax(dim=1) # 模型
loss = nn.NLLLoss() # 计算损失的标准
input = torch.Tensor([[1,2,3],[1,2,4]])
print('input:',input)
target = torch.tensor([1, 2])#每一项的范围是[0,C-1]
print('target:', target)
output = loss(m(input), target)
print('output:', output)代码运行结果:

4.torch.nn.CrossEntropyLoss
前面所说的一切,都是为了给交叉熵作铺垫,^_^,先看下官网怎么说的:

这句描述说的是:交叉熵是LogSoftmax()和NLLLoss()组合而成,而LogSoftmax()实际上是softmax+log,所以通俗的讲:交叉熵是softmax+log+NLLLoss组合而成。并没有什么新的内容。
变相的说,调用交叉熵的结果,和上面一步一步实现的结果是一样的。
代码:
input = torch.Tensor([[1,2,3],[1,2,4]])
target = torch.Tensor([1,2]).long()
criterion = nn.CrossEntropyLoss()
loss = criterion(input, target)
print(loss)代码运行结果:
![]()
再单独一步一步执行测试一下:
代码:
import torch
import torch.nn as nn
input = torch.Tensor([[1, 2, 3], [1, 2, 4]])
target = torch.Tensor([1, 2]).long()
m1 = nn.Softmax(dim=1)
r1 = m1(input)
print('softmax结果:\n', r1)
r2 = torch.log(r1)
print('log结果:\n', r2)
m2 = nn.NLLLoss()
loss = m2(r2, target)
print('NLLLoss结果:\n',loss)
print(loss)代码运行结果:

总结:我感觉最难的点是公式看不懂,不知道如何展开,其次,就是测试的时候最好是自己写数字,因为随机产生的,不好计算,自己写的,手动计算的时候稍微好计算一些。总之,无论多艰难,一步一步走,大不了多花点时间,总会弄明白。