目录
卷积&滤波
线性滤波是图像处理最基本的方法,它可以允许我们对图像进行处理,产生很多不同的效果。
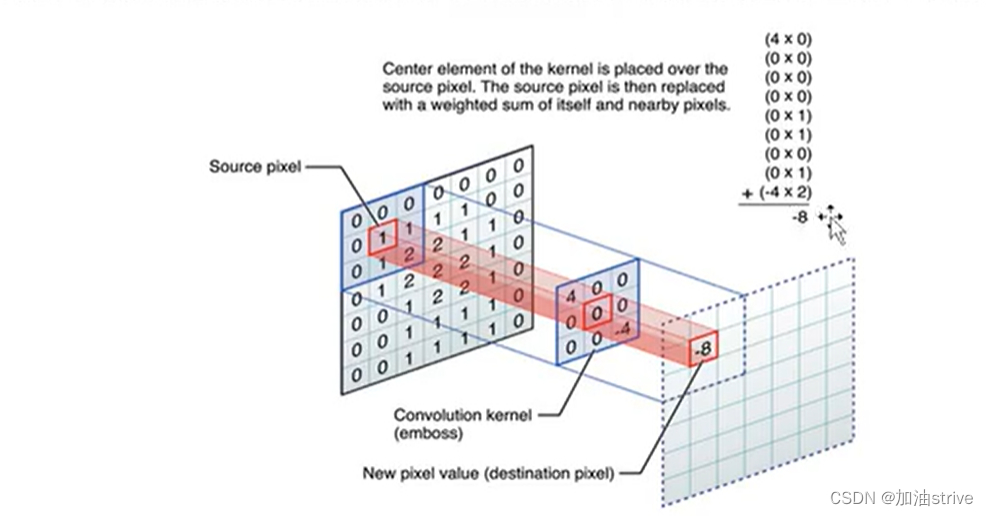
图像像素位置和kernel核每个位置的权重,
对应的位置相乘再相加
卷积和滤波的区别:卷积操作在做乘积之前,需要先将kernel核翻转180度
几种卷积核 帮助理解:
1.一个没有任何效果的卷积核

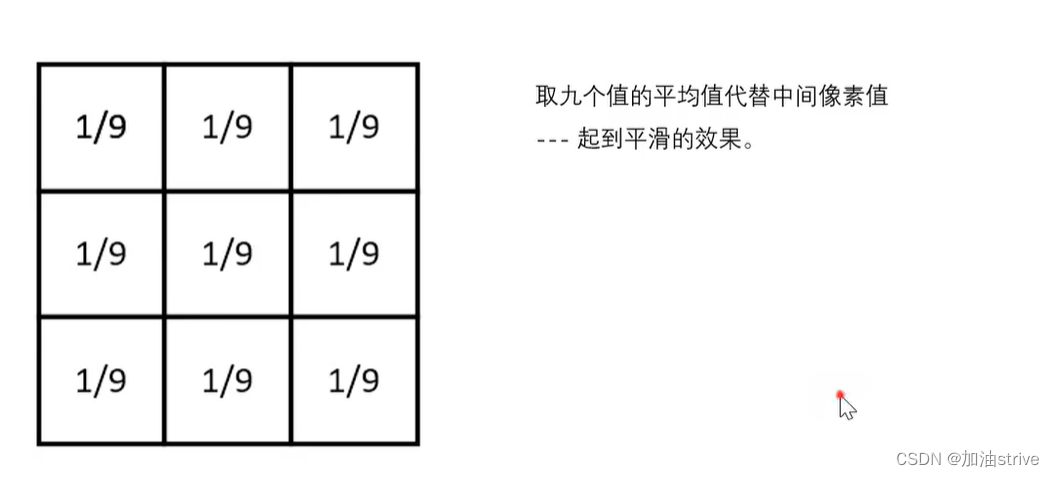
2.平均均值滤波
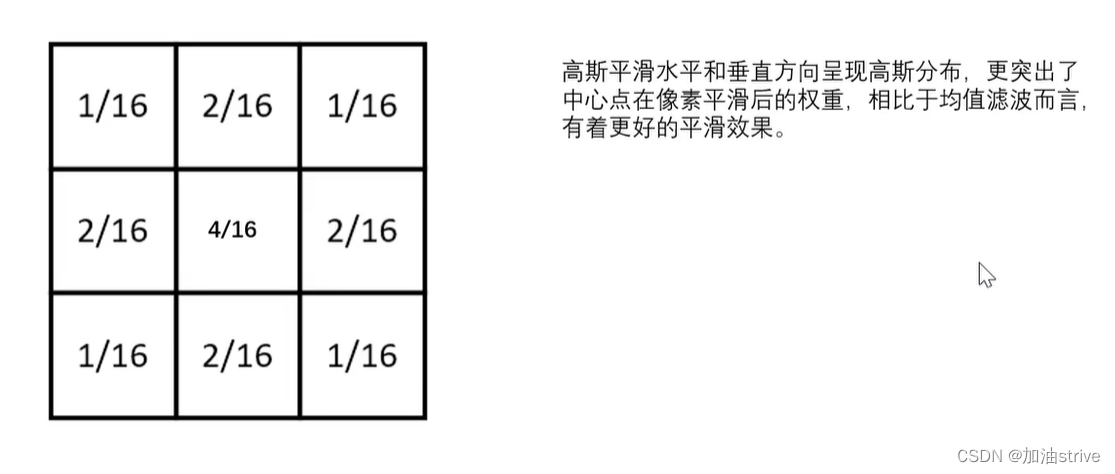
高斯平滑
3.图像锐化
拉普拉斯变换核函数

4.soble边缘检测
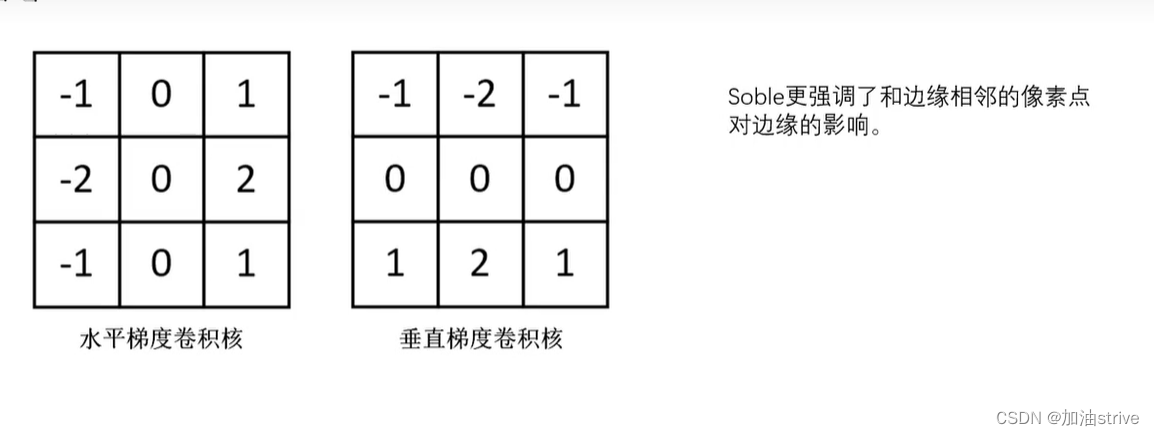
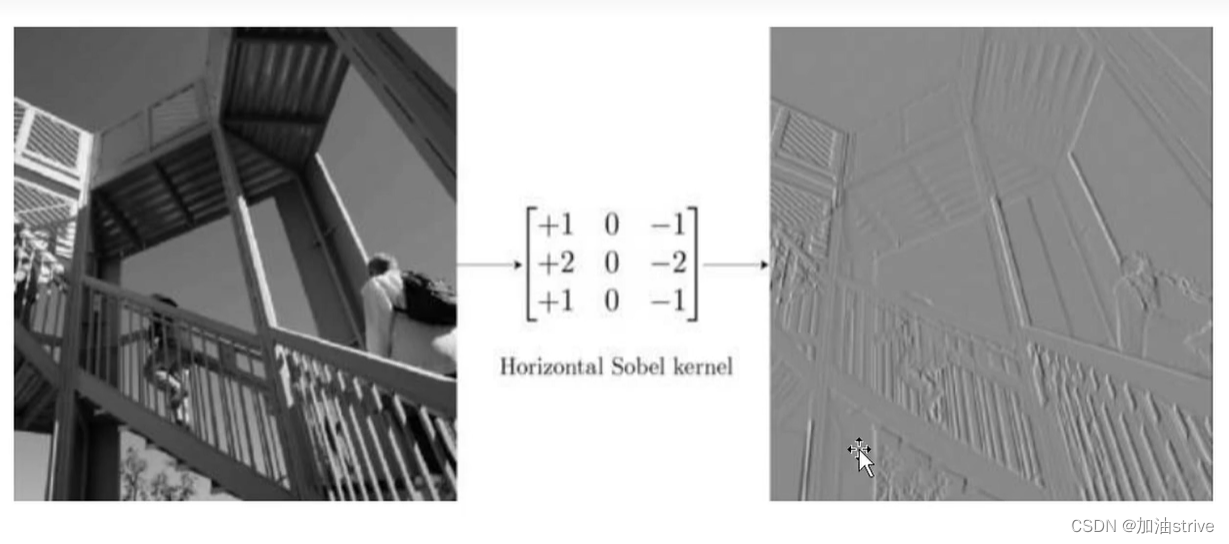
原理自行理解一下

卷积的三种填充模式
1.padding --> same模式 最常用的模式
为了解决卷积后图像变小,进而丢失信息的问题,我们可以在边界补0,使用padding方法,
如下图所示:
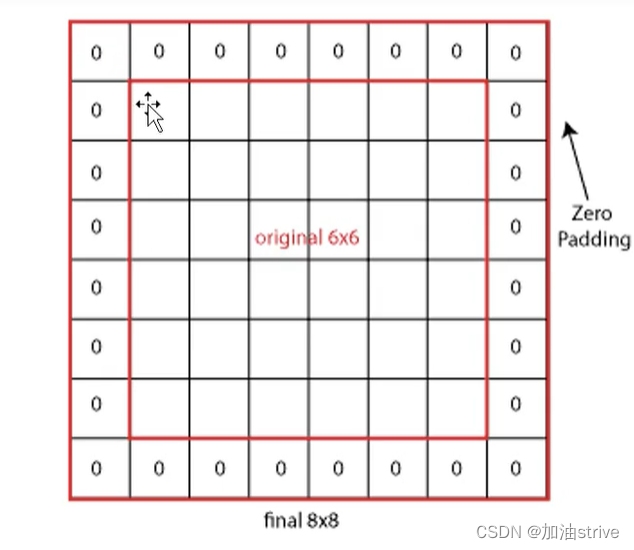
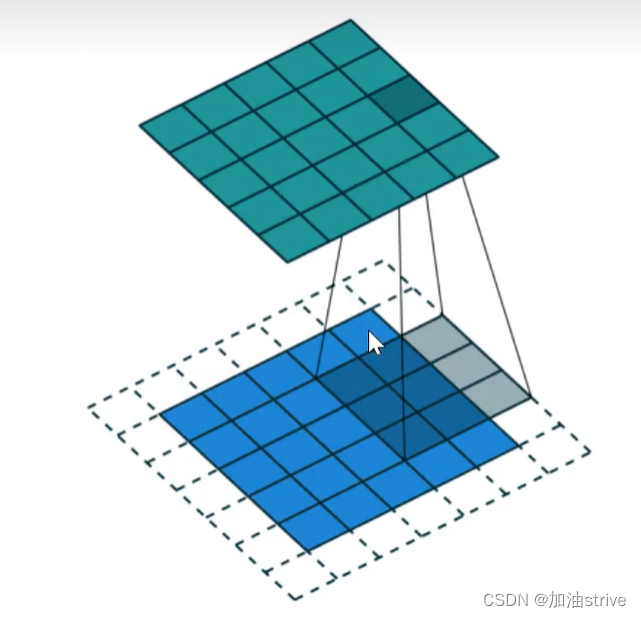
此时,原图像与卷积后的图像尺寸大小保持一致
2.full和valid模式

三通道卷积
每个通道单独进行卷积,注意每个卷积核的权重矩阵都可能都不一样
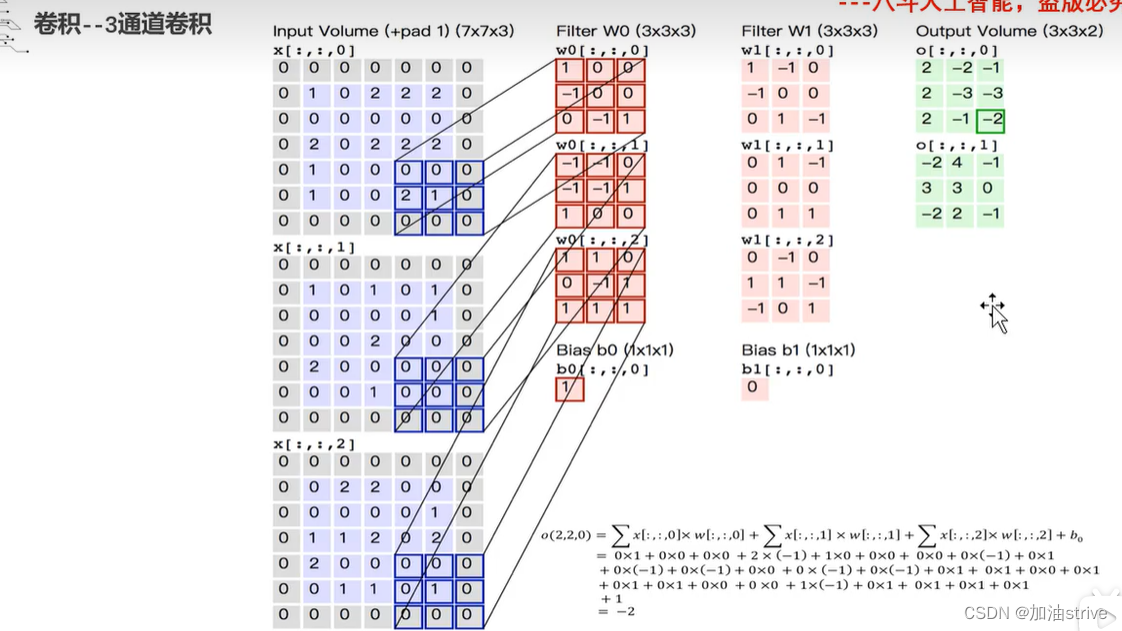
每个通道作为一个单独的层,不同的卷积核的权重矩阵,可以提取不同的图像特征。
CNN卷积神经网络的强大之处在于:过滤器的特征并不是人为确定的,而是通过大量图片自己训练出来的。
canny边缘检测算法(效果最好)
边缘检测主要是图像的灰度变化的度量、检测和定位。

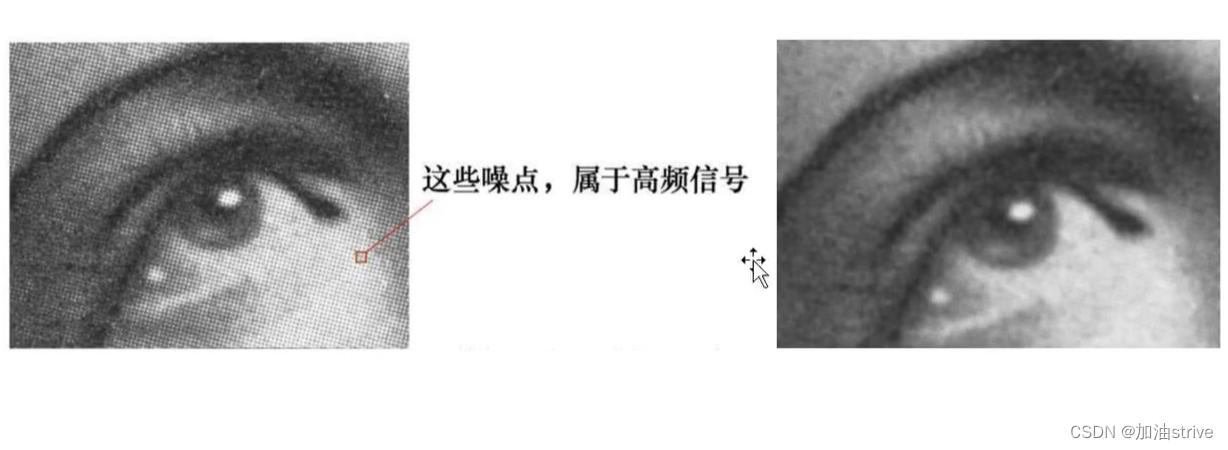
图像中的低频信号和高频信号也叫做低频分量和高频分量
简单来说,图像中的高频分量,指的就是图像强度变化剧烈的地方,也就是边缘
图像中的低频分量,指的是图像强度变化平缓的地方,也就是大片色块的地方。
人眼对图像中的高频信号更为敏感
边缘检测的基本步骤如下:
- 灰度化:将彩色图像转换为灰度图像,以便更容易检测边缘。
- 去噪:使用滤波器去除图像中的噪声,以减少边缘检测时的误差。常用的滤波器包括高斯滤波器、中值滤波器等。
- 计算梯度:对图像进行梯度计算,以确定图像中每个像素的变化率。常用的算法包括Sobel算子、Prewitt算子等。
- 非极大值抑制:在计算出梯度后,为了获得更细的边缘,需要进行非极大值抑制,以使边缘像素具有更窄的宽度。
- 阈值处理:在进行非极大值抑制后,得到了一张二值图像,需要确定阈值来确定哪些像素是边缘像素。
canny边缘检测算法是目前最优秀的边缘检测算法
Canny边缘检测是一种广泛使用的边缘检测算法,它能够检测出图像中的强边缘,并抑制图像中的弱边缘。以下是使用cv2库实现Canny边缘检测的代码:
import cv2
# 读取图片
img = cv2.imread('test.jpg', 0)
# 进行高斯模糊 去除图片噪音
img_blur = cv2.GaussianBlur(img, (3, 3), 0)
# 进行Canny边缘检测
canny = cv2.Canny(img_blur, 50, 150)
# 显示结果
cv2.imshow('Canny Edge Detection', canny)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个代码中,首先读取一张灰度图像,然后使用高斯模糊来减少噪声的影响。接着,使用cv2.Canny函数来进行边缘检测,其中第一个参数为输入图像,第二个和第三个参数分别是Canny算法中的两个阈值。最后,使用cv2.imshow函数来显示处理后的图像。
需要注意的是,在使用Canny边缘检测算法时,需要先对图像进行高斯模糊,这可以帮助去除图像中的噪声。同时,阈值的选取对检测结果有很大的影响,需要根据具体情况进行调整。
简单来说一下
Canny边缘检测算法中的第二个和第三个参数分别为低阈值和高阈值的含义。
在Canny边缘检测算法中,首先使用高斯滤波器对图像进行平滑处理,然后计算每个像素的梯度幅值和方向。接着,根据梯度幅值和方向,将像素点分为三类:强边缘、弱边缘和非边缘。
为了确定哪些边缘是真实的边缘,需要设置两个阈值。当像素点的梯度幅值超过高阈值时,将其标记为强边缘。当像素点的梯度幅值小于低阈值时,将其标记为非边缘。当像素点的梯度幅值在低阈值和高阈值之间时,如果它与一个强边缘相连,则将其标记为强边缘;否则将其标记为非边缘。
因此,通过调整低阈值和高阈值可以得到不同的边缘检测效果。一般来说,低阈值和高阈值之间的差异越大,得到的边缘也越少,但是这些边缘更可靠。相反,低阈值和高阈值之间的差异越小,得到的边缘越多,但是这些边缘可能不太可靠。
然后再说一下高斯滤波去除噪音的函数
在cv2.GaussianBlur函数中,第二个参数表示高斯滤波器的大小,即核的大小。该参数必须是一个正奇数,例如3、5、7等等。这是因为高斯滤波器的中心点是由核的大小确定的,所以必须确保中心点是一个像素而不是在两个或更多像素之间。
核的大小越大,图像被平滑的程度越高,但是可能会导致图像细节丢失。另外,对于不同的图像和应用场景,合适的核大小可能会有所不同。一般来说,需要根据实际情况进行调整和优化。
第三个参数表示高斯滤波器的标准差,即高斯函数的标准差。标准差决定了高斯函数的形状,它越大,高斯函数的分布越宽,平滑效果越强,反之则越弱。
在实际应用中,标准差的选择需要根据实际情况进行调整。一般来说,当图像噪声较小或者需要保留更多的细节时,应该选择较小的标准差;而当图像噪声较大或者需要更强的平滑效果时,应该选择较大的标准差。
需要注意的是,当标准差越大时,核的大小也会增加。一般来说,标准差的值和核的大小应该相互搭配,以达到较好的平滑效果和图像细节保留程度。
Sobel算子、Prewitt算子
代码实现如下:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# Sobel算子
sobel_x = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3)
# cv2.addWeighted()用于将两个图像进行加权求和
sobel_xy = cv2.addWeighted(sobel_x, 0.5, sobel_y, 0.5, 0)
# Prewitt算子
# 定义kernel核
kernel_x = np.array([[-1, 0, 1], [-1, 0, 1], [-1, 0, 1]], dtype=np.float32)
kernel_y = np.array([[-1, -1, -1], [0, 0, 0], [1, 1, 1]], dtype=np.float32)
prewitt_x = cv2.filter2D(img, -1, kernel_x)
prewitt_y = cv2.filter2D(img, -1, kernel_y)
prewitt_xy = cv2.addWeighted(prewitt_x, 0.5, prewitt_y, 0.5, 0)
# 显示图像
cv2.imshow('Sobel X', sobel_x)
cv2.imshow('Sobel Y', sobel_y)
cv2.imshow('Sobel XY', sobel_xy)
cv2.imshow('Prewitt X', prewitt_x)
cv2.imshow('Prewitt Y', prewitt_y)
cv2.imshow('Prewitt XY', prewitt_xy)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.Sobel()用于计算Sobel算子,第一个参数为输入图像,第二个参数为输出图像的深度,第三个和第四个参数分别为x方向和y方向的导数,最后一个参数ksize为Sobel算子的大小(指sobel卷积核的大小,默认3*3)。
cv2.filter2D()用于计算Prewitt算子,第一个参数为输入图像,第二个参数为输出图像的深度,第三个参数为卷积核。cv2.addWeighted()用于将两个图像进行加权求和。
相机模型
在相机拍摄的过程中,原图可能会发生变化,如下图所示:
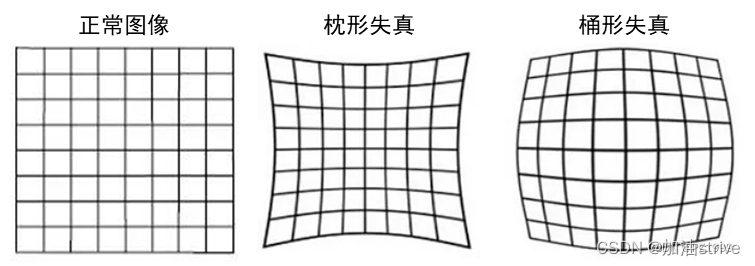

畸变矫正
要进行图像畸变矫正,通常需要使用相机标定得到相机的内参和畸变系数。然后可以使用OpenCV提供的cv2.undistort()函数来实现畸变矫正。下面是一个简单的示例代码:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('distorted_image.jpg')
# 相机内参和畸变系数
camera_matrix = np.array([[fx, 0, cx], [0, fy, cy], [0, 0, 1]], dtype=np.float32)
dist_coeffs = np.array([k1, k2, p1, p2, k3], dtype=np.float32)
# 畸变矫正
img_undistorted = cv2.undistort(img, camera_matrix, dist_coeffs)
# 显示结果
cv2.imshow('Original Image', img)
cv2.imshow('Undistorted Image', img_undistorted)
cv2.waitKey(0)
cv2.destroyAllWindows()
其中,fx和fy是相机的焦距,cx和cy是相机的光心在图像坐标系下的坐标,k1、k2、p1、p2和k3是畸变系数。函数cv2.undistort()的第一个参数是待矫正的图像,第二个参数是相机内参矩阵,第三个参数是相机的畸变系数。函数返回一个畸变矫正后的图像。
cv2.undistort()函数主要有五个参数:
1.输入图像:待矫正的图像
2.摄像机内部参数矩阵:该参数包含摄像机的内部参数,如焦距、光心等信息。可以通过摄像机标定得到。
3.畸变系数矩阵:该参数包含了径向畸变和切向畸变等信息。同样可以通过摄像机标定得到。
4.可选参数newCameraMatrix:新的相机内部参数矩阵。默认值为None,表示使用原始内部参数矩阵。
5.输出图像的大小:输出图像的大小,可以通过参数newCameraMatrix和输入图像大小来计算得到。默认值为输入图像的大小。
其中前两个参数是必须要指定的,后三个参数是可选的。
图像相似度比较哈希算法
哈希算法一共有三种:
1.均值哈希算法 aHash
2.差值哈希算法 dHash
3.感知哈希算法 pHash
汉明距离


均值哈希算法(Average Hashing Algorithm):它是最简单的哈希算法之一。它的思想是:
将图像缩小为8*8的小图像,计算它的平均灰度值作为图像的指纹。
在实现时,具体过程如下:
1.先将图像转为灰度图
2.将图片缩小为88大小
3.将缩小后图像的像素平均值作为指纹
4.最后比较指纹值的汉明距离来判断图像的相似度。
差值哈希算法(Difference Hashing Algorithm):它和均值哈希算法类似,不同之处在于它计算的是图像像素之间的差异。
具体过程如下:
1.先将图像转为灰度图,
2.将图片缩小为8*8大小
3.计算相邻像素之间的差异,将像素的差异转换为二进制码
4.最终将所有的二进制码拼接起来作为图像的指纹。
5.最后比较指纹值的汉明距离来判断图像的相似度。
步骤3和步骤4是与均值哈希算法之间最主要的差异。
感知哈希算法(Perceptual Hashing Algorithm):它是一种比均值哈希算法和差值哈希算法更为复杂的哈希算法。它不仅考虑像素的平均值和差异,还考虑了像素的高频信息和人眼的视觉感知。
感知哈希算法的实现过程如下:
1.先将图像转为灰度图
2.将图片缩小为8*8大小
3.然后进行DCT变换,提取图像中的高频信息,再将高频信息量化为二进制码。
4.最终将所有的二进制码拼接起来作为图像的指纹。
5.最后比较指纹值的汉明距离来判断图像的相似度。
步骤3是与差值哈希算法最主要的差异。
其中:DCT变换的介绍:
离散余弦变换(Discrete Cosine Transform,DCT)是一种常用的信号处理技术,常用于图像、音频和视频压缩中。与傅里叶变换类似,DCT也是将一个信号从时域(或空域)转换到频域,但它对于大部分实际信号来说更加紧凑,且DCT产生的系数是实数。因此,DCT在许多应用中比傅里叶变换更加实用
以下是cv2的实现实例:
- 均值哈希算法
import cv2
import numpy as np
def ahash(image, size=8):
# 调整图像大小
image = cv2.resize(image, (size, size))
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 计算均值
avg = gray.mean()
# 将图像转为01串
hash_code = ''
for i in range(size):
for j in range(size):
if gray[i, j] > avg:
hash_code += '1'
else:
hash_code += '0'
return hash_code
# 加载图像
image = cv2.imread('image.jpg')
# 计算均值哈希值
ahash_code = ahash(image)
print(ahash_code)
2.差值哈希算法
import cv2
import numpy as np
def dhash(image, size=8):
# 调整图像大小
image = cv2.resize(image, (size + 1, size))
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 计算哈希值
hash_code = ''
for i in range(size):
for j in range(size):
# 差值的实现过程
if gray[i, j] > gray[i, j + 1]:
hash_code += '1'
else:
hash_code += '0'
return hash_code
# 加载图像
image = cv2.imread('image.jpg')
# 计算差值哈希值
dhash_code = dhash(image)
print(dhash_code)
- 感知哈希算法
import cv2
import numpy as np
def phash(image, size=32):
# 调整图像大小
image = cv2.resize(image, (size, size))
# 转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 计算DCT变换
dct = cv2.dct(np.float32(gray))
# 取左上角8*8的DCT系数,计算均值
avg = dct[:8, :8].mean()
# 将DCT系数转为01串
hash_code = ''
for i in range(8):
for j in range(8):
if dct[i, j] > avg:
hash_code += '1'
else:
hash_code += '0'
return hash_code
# 加载图像
image = cv2.imread('image.jpg')
# 计算感知哈希值
phash_code = phash(image)
print(phash_code)