目录
4.3 ByteToMessageDecoder#channelRead
1.协议说明
Netty框架是基于Java NIO框架,性能彪悍,支持的协议丰富,广受Java爱好者亲莱,支持如下协议
- TCP/UDP:Netty提供了基于NIO的TCP和UDP编程框架,可以用来构建高性能、高可用性的网络应用。
- HTTP/HTTPS:Netty提供了HTTP/HTTPS编程框架,可以用来开发Web服务器和客户端。
- WebSocket:Netty提供了WebSocket编程框架,可以用来实现双向通信应用程序,如聊天室等。
- SPDY/HTTP2:Netty提供了SPDY和HTTP2编程框架,可以用来实现高效的Web应用程序。
- MQTT/CoAP:Netty提供了MQTT和CoAP编程框架,可以用来构建IoT应用程序。
我们在基于Netty框架开发过程中往往需要自定义私有协议,如端到端的通信协议,端到平台数据通信协议,我们需要根据业务的特点自定义数据报文格式,举例如下:
| 帧头 | 版本 | 命令标识符 | 序列号 | 设备编码 | 帧长 | 正文 | 校验码 |
|---|---|---|---|---|---|---|---|
| 1byte | 1byte | 1byte | 2byte | 4byte | 4byte | N个byte | 2byte |
假如我们定义了上述私有协议的TCP报文,通过netty框架发送和解析
发送端:某类通信设备(client)
接收端:Java应用服务(Server)
本节我主要分析一下server端解析报文的一个过程,client当然也很重要,尤其在建立TCP连接和关闭连接需要严格控制,否则服务端会发现大量的CLOSE_WAIT(被动关闭连接),甚至大量TIME_WAIT(主动关闭连接),关于这个处理之前的文章有讲解。
本节Server端是基于Netty版本:netty-all-4.1.30.Final
本节源码分析需求就是要解析一个自定义TCP协议的数据报文进行解码,关于编码解码熟悉网络编程的同学都明白,不清楚的可以稍微查阅一下资料有助于学习为什么要解码以及如何解码。本节不会对具体报文的解析做具体讲解,只对Netty提供的解码器基类ByteToMessageDecoder做一下源码分解,以及如何使用ByteToMessageDecoder开发属于自己的Decoder,接下来我们看看ByteToMessageDecoder的定义。
/*继承ChannelInboundHandlerAdapter
* 字节到消息的编码器,是Inbound操作,这类解码器处理器都不是共享的,因为需要存没有
* 解码完的数据,还有各种状态,是独立的,不能进行共享。
* 所以在pipeline上需要每次创建新的对象,不是能够进行对象复用。
*/
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
}2.类的实现
解码器的ByteToMessageDecoder ,该类继承了ChannelInboundHandlerAdapter ,ChannelInboundHandlerAdapter继承ChannelHandlerAdapter,
ChannelInboundHandlerAdapter实现ChannelInboundHandler接口,也就是说ChannelInboundHandler定义了解码器需要处理的工作(方法)
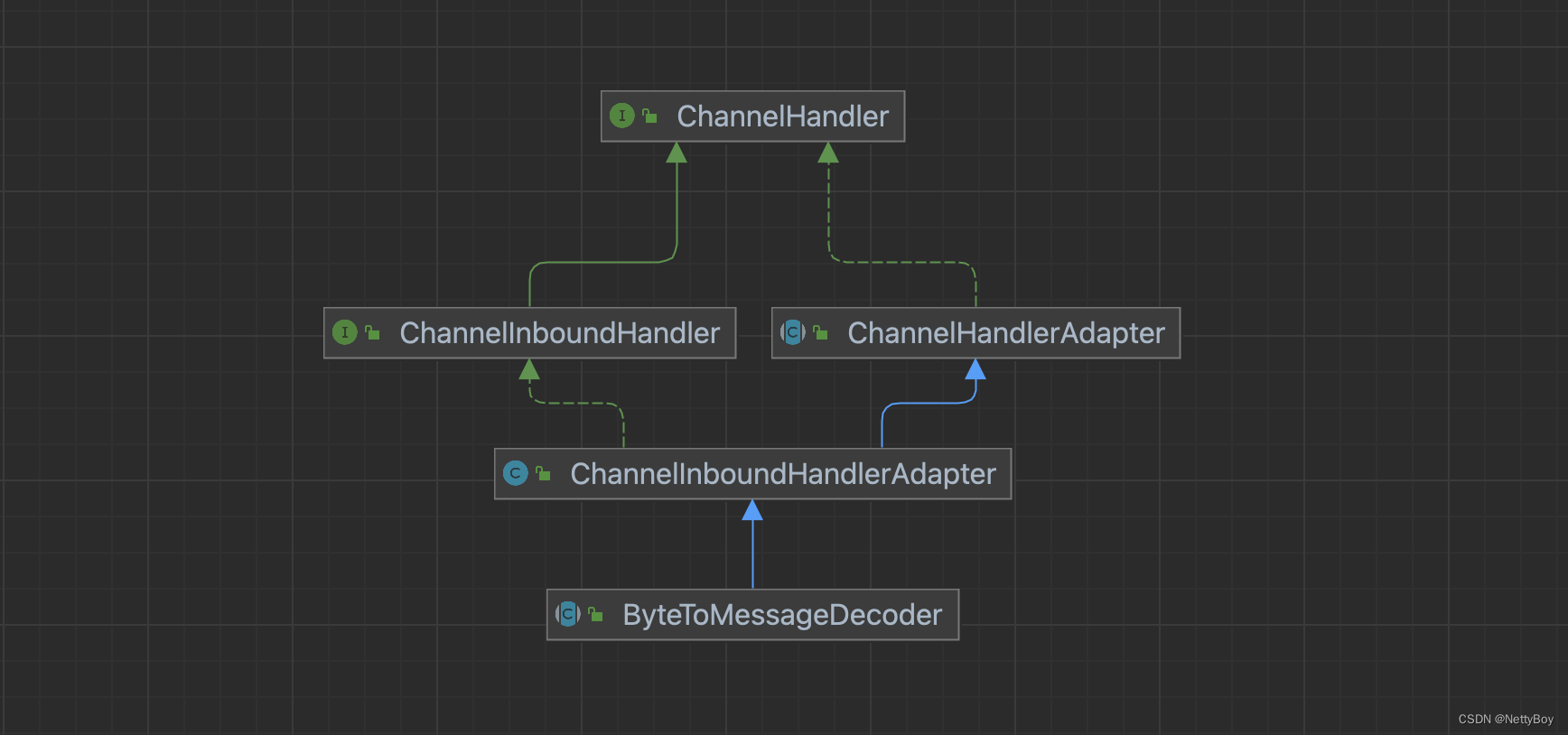
ChannelInboundHandlerAdapter是一个适配器模式,负责Decoder的扩展。它的实现有很多,简单列举一下:
-
HeartBeatHandler
-
MessageToMessageDecoder
-
SimpleChannelInboundHandler(实现抽象了channelRead方法,提供抽象方法channelRead0)
ByteToMessageDecoder。。。。。。
以上都是比较常用的Decoder或Handler,基于这些基类还定义了很多handler,有兴趣的同学可以跟代码查阅。
3.Decoder工作流程
每当数据到达Server端时,SocketServer通过Reactor模型分配具体的worker线程进行处理数据,处理数据就需要我们的事先定义好的Decoder以及handler,假如我们定义了以下两个对象:
- MyDecoder extends
ByteToMessageDecoder{} 作为解码器 MyHandler extendsSimpleChannelInboundHandler{} 作为解码后的业务处理器
worker线程——〉MyDecoder#channelRead实际就是调用ByteToMessageDecoder#channelRead——〉Cumulator累加器处理——〉
解码器decode处理(MyDecoder需要实现decode方法)——〉Myhandler#channelRead0处理具体的数据(msg),msg是通过MyDecoder#decode方法解码后的数据对象。
4.源码解析
4.1 累加器Cumulator(数据累加缓冲区)
累加器Cumulator的作用是数据累加缓冲区,解决tcp数据包中出现半包和粘包问题。
半包:接收到的byte字节不足一个完整的数据包,
半包处理办法:不足一个完整的数据包先放入累加器不做解码,等待续传的数据包;
粘包:接收到的byte字节数据包中包括其他数据包的数据(靠数据包协议中定义的帧头帧尾标识来识别,多于1个以上的帧头或帧尾数据包为粘包数据),
粘包处理办法:按照数据包帧结构定义去解析,需要结合累加器,解析完一个数据包交给handler去处理,剩下的不足一个数据包长度的字节保存在累加器等待续传的数据包收到之后继续解码。
ByteToMessageDecoder内部定义了Cumulator接口
/**
* Cumulate {@link ByteBuf}s.
*/
public interface Cumulator {
/**
* Cumulate the given {@link ByteBuf}s and return the {@link ByteBuf} that holds the cumulated bytes.
* The implementation is responsible to correctly handle the life-cycle of the given {@link ByteBuf}s and so
* call {@link ByteBuf#release()} if a {@link ByteBuf} is fully consumed.
*/
ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in);
}其中在类最开始的时候构建了两个对象,分别是MERGE_CUMULATOR,COMPOSITE_CUMULATOR,代码如下
/**
* Cumulate {@link ByteBuf}s by merge them into one {@link ByteBuf}'s, using memory copies.
*/
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
/**
* 主要是做一般缓冲区的合并,直接将新的缓冲区拷贝到累加缓冲区中。
* cumulation 累加的缓冲区
* in 新读取的数据
*/
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
try {
final ByteBuf buffer;
//1.如果累加器ByteBuf 剩余可写的capacity不满足当前需要写入的ByteBuf(in)长度,则进行扩容累加器ByteBuf容量,执行expandCumulation方法
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
//2.写入累加器并返回更新后的cumulation
buffer.writeBytes(in);
return buffer;
} finally {
// We must release in in all cases as otherwise it may produce a leak if writeBytes(...) throw
// for whatever release (for example because of OutOfMemoryError)
//3.由于是对in的拷贝,in不需要在进行往下的传递,所以应该直接释放,需要release
in.release();
}
}
};
//通过对CompositeByteBuf的累加器的实现,CompositeByteBuf内部使用ComponentList
//实现对ByteBuf进行追加
//ComponentList是ArrayList的实现,所以每次Add操作都是一次内存拷贝。
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
try {
if (cumulation.refCnt() > 1) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
buffer.writeBytes(in);
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
composite.addComponent(true, in);
in = null;
buffer = composite;
}
return buffer;
} finally {
if (in != null) {
//因为是对ByteBuf in的拷贝,所以需要释放
in.release();
}
}
}
};
4.2 状态码说明
//状态码
private static final byte STATE_INIT = 0; //表示初始化状态
private static final byte STATE_CALLING_CHILD_DECODE = 1; //表示正在调用子类解码器
private static final byte STATE_HANDLER_REMOVED_PENDING = 2; //表示handler正在删除
ByteBuf cumulation; //核心重点 累加的缓冲区(累加器)
private Cumulator cumulator = MERGE_CUMULATOR; //累加器的默认状(默认是合并的累加器)
private boolean singleDecode; //是否解码一次
private boolean decodeWasNull; //out对象有被添加或者设置,表是有读过了
private boolean first; //是否是第一次累加缓冲区,true表示第一次累加缓存区,false表示不是第一次累加缓冲区
/**
* A bitmask where the bits are defined as
* <ul>
* <li>{@link #STATE_INIT}</li>
* <li>{@link #STATE_CALLING_CHILD_DECODE}</li>
* <li>{@link #STATE_HANDLER_REMOVED_PENDING}</li>
* </ul>
*/
private byte decodeState = STATE_INIT; //解码初始状态
private int discardAfterReads = 16; //读取16个字节后丢弃已读的
private int numReads; //累加器(cumulation)读取数据的次数
4.3 ByteToMessageDecoder#channelRead
/**
* 接收数据并读取
* 只是在业务的处理前进行解码和缓存的操作。主要将读取的数据(msg)叠加到累加缓冲区(cumulation)中,并且调用解码方法(callDecode)
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//如果是设置在ServerBootstrap的childHandler那么msg的对象类型就是ByteBuf,否则就执行else
if (msg instanceof ByteBuf) {
//CodecOutputList对象可以查阅文档https://www.freesion.com/article/4800509769/
//这个out对象随着callDecode方法进行传递,解码后的数据保存在out中
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
//1.第一次读取数据时cumulation是null,所以first是ture
first = cumulation == null;
if (first) {
//2.第一次收到数据累加器为null,将数据赋值给cumulation
cumulation = data;
} else {
//3.第二次收到数据累加器需要评估ByteBuf的capacity,够用则追加到cumulation,capacity不够则进行扩容
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
//4.调用callDecode进行解码
//5.CodecOutputList out对象保存解码后的数据,它的实现是基于AbstractList,
//重新定义了add(),set(),remove()等方法,其中add()方法实现对Array数组中
//进行insert,没有直接拷贝而是通过对象引用,将对象指向数据索引的index,是性能的一个提升。
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
//6.如果累加器cumulation中的数据被解码器读完了,则可以完全释放累加器cumulation
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
//7.释放累加器cumulation里面的已读数据,防止cumulation无限制增长
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
//8.out对象有被添加或者设置,表示有读过了
decodeWasNull = !out.insertSinceRecycled();
//9.解码完成后需要触发事先定义好的handler的channelRead()方法处理解码后的out数据
fireChannelRead(ctx, out, size);
//10.最终需要回收out对象
out.recycle();
}
} else {
//11.非ByteBuf直接向后触发传递
ctx.fireChannelRead(msg);
}
}
在ByteToMessageDecoder#channelRead看到了将累加器交给callDecoder方法
注意,这里有个while循环,会循环读取缓冲区字节数据,循环调用我们自己实现的MyDecoder,所以在自己实现的Mydecoder#decode()方法中不需要循环读取字节,只需要按照指定的数据报文帧结构解码即可,解码后的对象需要加入到List<Object> out。
//这里ByteBuf in 就是累加器对象cumulaction,从累加器中读取字节交给decode去解码
// List<Object> out 是list,存放解码后的对象
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
//1. 循环读取累加器对象的byte,循环直到累加缓冲区没有可读数据,或者直接跳出循环为止
while (in.isReadable()) {
int outSize = out.size();
//2.如果解码后out对象中产生数据则触发后边的handler(MyHandler)处理数据
if (outSize > 0) {
fireChannelRead(ctx, out, outSize);
// 处理完清空out
out.clear();
//判断handler的上下文是否被删除,被删除就不在处理,直接跳出循环
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
//3.继续解析累加器传递过来的byte,获取可读的字节长度
int oldInputLength = in.readableBytes();
//4.注意out对象是从channelRead()方法传递过来,继续传递下去
decodeRemovalReentryProtection(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
//4.判断当前的outSize是否等于list列表的长度,等于表示没有生成新的消息,可能读取的字节长度不够,无法解码出一个消息。
//不相等说明解码后生成了一个新的消息
if (outSize == out.size()) {
//5.如果解码器decode没有消费累加器 in 任何字节,结束循环 if (oldInputLength == in.readableBytes()) {
break;
//6.否则继续循环调用解码器decode
} else {
continue;
}
}
//7.如果已经解码获取到消息,但是累加器ByteBuf in中可读字节数依然没有变化,说明readIndex没有修改,
//说明实现的解码器decode()方法有bug,需要检查自身代码问题(需要readByte(),不能getByte(),getByte()会导致readIndex不会修改)
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
//8.是否设定每次调用解码器一次,如果是,则结束本次解码
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
} catch (Exception cause) {
}
}
继续查看ByteToMessageDecoder#decodeRemovalReentryProtection方法
//此方法不允许重写
final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
//1.切换ByteToMessageDecoder的状态为子类解码状态,表示当前正在解码
decodeState = STATE_CALLING_CHILD_DECODE;
try {
//2.核心方法decode,这是一个抽象方法,没有实现,需要在自定义的Decoder(Mydecoder)进行实现
//3.自定义Decoder需要将解码后的数据放入到out对象中
decode(ctx, in, out);
} finally {
//4.判断decodeState状态是否为待删除,如果不是返回ture,如果是返回false
boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING;
//5.重置decodeState为初始化状态
decodeState = STATE_INIT;
//6.如果当前ByetToMessageDecoder为待删除状态
if (removePending) {
/7.删除handlercontext的上下文
handlerRemoved(ctx);
}
}
}
//解码decode方法需要子类(自定义的实现类)去实现该方法,最终将解码后的消息放入List<Object> out
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;4.4 Decoder实现举例
基于ByteToMessageDecoder的实现很多,简单列举一下
- JsonObjectDecoder
- RedisDecoder
- XmlDecoder
- MqttDecoder
- ReplayingDecoder
- SslDecoder
- DelimiterBasedFrameDecoder
- FixedLengthFrameDecoder
- LengthFieldBasedFrameDecoder
-
....
我们拿JsonObjectDecoder举例如下:
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 省略代码。。。。。。
int idx = this.idx;
int wrtIdx = in.writerIndex();
//省略代码。。。。。。。
for (/* use current idx */; idx < wrtIdx; idx++) {
byte c = in.getByte(idx);
if (state == ST_DECODING_NORMAL) {
decodeByte(c, in, idx);
if (openBraces == 0) {
ByteBuf json = extractObject(ctx, in, in.readerIndex(), idx + 1 - in.readerIndex());
//1.解析后的对象加入out中
if (json != null) {
out.add(json);
}
in.readerIndex(idx + 1);
reset();
}
} else if (state == ST_DECODING_ARRAY_STREAM) {
//2.自身实现解析json格式的方法
decodeByte(c, in, idx);
if (!insideString && (openBraces == 1 && c == ',' || openBraces == 0 && c == ']')) {
for (int i = in.readerIndex(); Character.isWhitespace(in.getByte(i)); i++) {
in.skipBytes(1);
}
// skip trailing spaces.
int idxNoSpaces = idx - 1;
while (idxNoSpaces >= in.readerIndex() && Character.isWhitespace(in.getByte(idxNoSpaces))) {
idxNoSpaces--;
}
ByteBuf json = extractObject(ctx, in, in.readerIndex(), idxNoSpaces + 1 - in.readerIndex());
//3.解析后的对象加入out中
if (json != null) {
out.add(json);
}
in.readerIndex(idx + 1);
if (c == ']') {
reset();
}
}
}
//省略代码。。。。。。
}
if (in.readableBytes() == 0) {
this.idx = 0;
} else {
this.idx = idx;
}
this.lastReaderIndex = in.readerIndex();
}5. 如何开发自己的Decoder
读了ByteToMessageDecoder的部分源码,以及它的实现JsonObjectDecoder,那么如果我们自己实现一个Decoder该如何实现,这里提供三个思路给大家,有时间再补充代码。
- 基于ByteToMessageDecoder实现,MyDecoder extends ByteToMessageDecoder{实现decode()方法},可参考RedisDecoder、XmlDecoder等实现。
- 基于
ChannelInboundHandlerAdapter实现,这个时候需要自己负责解决TCP报文半包和粘包问题,重写其中的channelRead()方法。 直接使用已经实现ByteToMessageDecoder的解码器,如FixedLengthFrameDecoder、DelimiterBasedFrameDecoder、LengthFieldBasedFrameDecoder。
注意事项:
* Be aware that sub-classes of {@link ByteToMessageDecoder} <strong>MUST NOT</strong>
* annotated with {@link @Sharable}.
ByteToMessageDecoder的子类不能使用@Sharable注解修饰,因为解码器只能单独为一个Channel进行解码,也就是说每个worker线程需要独立的Decoder。
* <p>
* Some methods such as {@link ByteBuf#readBytes(int)} will cause a memory leak if the returned buffer
* is not released or added to the <tt>out</tt> {@link List}. Use derived buffers like {@link ByteBuf#readSlice(int)}
* to avoid leaking memory.如果基于
ChannelInboundHandlerAdapter自己实现Decoder#channelRead()方法时注意内存泄露问题,ByteBuf#readBytes(int)方法会产生一个新的ByteBuf,需要手动释放。或者
基于
ByteToMessageDecoder实现decode()方法时将解析后的对象放入out对象中(上面源码分析中有提示)
或者
使用派生的ByteBuf,如调用ByteBuf#readSlice(int)方法,返回的ByteBuf与原有ByteBuf共享内存,不会产生新的Reference count,可以避免内存泄露。
Netty Project官网也有说明:
Reference counted objects
ByteBuf.duplicate(), ByteBuf.slice() and ByteBuf.order(ByteOrder) create a derived buffer which shares the memory region of the parent buffer. A derived buffer does not have its own reference count, but shares the reference count of the parent buffer.