LangChain系列文章
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
- LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
- LangChain 7 文本模型TextLangChain和聊天模型ChatLangChain
- LangChain 8 模型Model I/O:输入提示、调用模型、解析输出
- LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPrompt
- LangChain 10思维链Chain of Thought一步一步的思考 think step by step
- LangChain 11实现思维树Implementing the Tree of Thoughts in LangChain’s Chain
- LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5
- LangChain 13输出解析Output Parsers 自动修复解析器
- LangChain 14 SequencialChain链接不同的组件
- LangChain 15根据问题自动路由Router Chain确定用户的意图
- LangChain 16 通过Memory记住历史对话的内容
- LangChain 17 LangSmith调试、测试、评估和监视基于任何LLM框架构建的链和智能代理
- LangChain 18 LangSmith监控评估Agent并创建对应的数据库
- LangChain 19 Agents Reason+Action自定义agent处理OpenAI的计算缺陷
- LangChain 20 Agents调用google搜索API搜索市场价格 Reason Action:在语言模型中协同推理和行动
- LangChain 21 Agents自问自答与搜索 Self-ask with search
- LangChain 22 LangServe用于一键部署LangChain应用程序
1. tools 用于增强和扩展Agents
在Langchain框架中,tools是一种重要的组件,用于增强和扩展智能代理(agent)的功能。这些tools提供了一系列附加能力,使得代理可以执行特定的任务,处理复杂的数据类型,或与外部服务进行交互。以下是对Langchain中tools的详细解释:
定义和作用
- 定义:
tools在Langchain中指的是可以被智能代理用来执行特定操作或任务的功能模块或服务。 - 作用:这些工具使得代理不仅限于其内置的语言处理能力,还可以执行更复杂的任务,如数据分析、图像处理、网络搜索等。
类型和示例
- 数据处理工具:用于处理和分析数据,如数据清洗、格式转换、统计分析等。
- 搜索工具:使代理能够进行网络搜索,获取信息或回答查询。
- 交互工具:用于提高与用户的交互效果,如自然语言理解、情感分析等。
- API集成:允许代理与外部API进行交互,获取或发送数据。
实现方式
- 集成:
tools通常通过API或特定的编程接口集成到Langchain框架中。 - 配置:开发者可以根据需要配置和定制
tools,以适应特定的应用场景。
应用场景
- 多功能代理:使用
tools扩展代理的能力,让其能处理更多类型的任务。 - 特定任务:针对特定的业务需求或技术挑战,定制相应的
tools。 - 用户体验:通过交互和数据处理工具,提高代理与用户互动的质量和效果。
优势和局限性
- 优势:提供灵活性和扩展性,使代理能够适应多种不同的任务和场景。
- 局限性:依赖外部服务或数据源可能带来安全性和可靠性方面的考虑。
结论
Langchain中的tools为开发者提供了一种强大的方式来增强智能代理的功能和适用范围。通过合理地选择和配置这些工具,可以创建出能够处理复杂任务、提供丰富交互体验的高效智能代理。然而,开发者需要考虑到集成外部工具的安全性和稳定性,确保整体系统的可靠运行。
2. Langchain的tools的arxiv
在Langchain中,arxiv是一种特定的工具(tool),用于与Arxiv API进行交互。Arxiv API是一个公开的接口,允许用户访问Arxiv数据库中的大量科学论文和出版物。下面是对arxiv工具的详细介绍:
Arxiv API Wrapper
- 功能:
ArxivAPIWrapper是一个封装器(wrapper),它简化了与Arxiv API的交互,使得在Langchain中可以方便地获取论文信息。 - 用途:通过这个工具,Langchain智能代理可以查询Arxiv数据库,获取特定论文的信息,如标题、作者、摘要、发表日期等。
使用方式
- 初始化:首先,需要创建
ArxivAPIWrapper的实例。这通常在初始化智能代理时通过load_tools函数完成。 - 查询:可以通过传递论文的唯一标识符(如arXiv ID)来查询特定论文的详细信息。
示例应用
- 论文摘要获取:可以获取指定论文的摘要,用于了解论文的主要内容和贡献。
- 作者信息查询:可以检索特定作者的发布论文列表或其研究领域。
- 论文搜索:支持按关键词或其他条件搜索相关论文。
优点
- 直接访问:提供了直接访问科学论文数据库的便利,方便在智能代理中嵌入学术研究的功能。
- 自动化信息检索:可以自动化地检索和处理大量学术数据,提高效率。
使用场景
- 学术研究辅助:用于帮助研究人员快速找到相关的学术资料。
- 教育和学习:在教育应用中,可以用于获取特定领域的最新研究成果。
注意事项
- 版权和使用限制:在使用Arxiv API获取的数据时,需要遵守相关的版权和使用条款。
- 数据准确性:虽然Arxiv提供的是学术论文,但用户在使用这些信息时仍需自行判断其准确性和可靠性。
总的来说,Langchain中的arxiv工具提供了一个方便的接口,让智能代理能够轻松访问和利用Arxiv上的丰富学术资源。
3. 代码实现
读取paper 的信息 Large Language Models
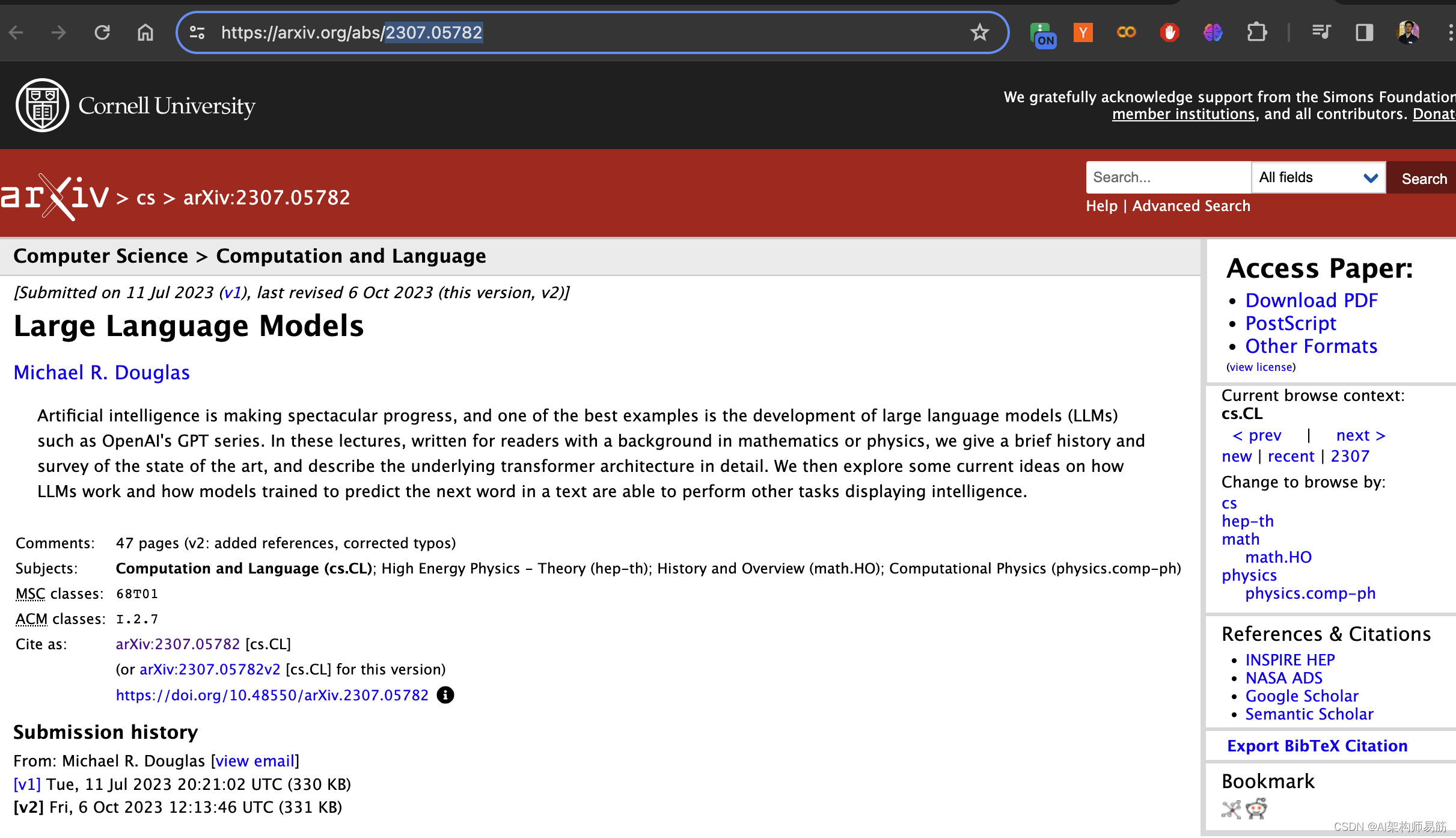
Tools/chat_tools_arxiv.py这段代码主要用于演示如何使用Langchain结合OpenAI聊天模型和Arxiv API来获取论文相关的信息。代码中包含了从加载环境变量、初始化智能代理到使用API获取数据的完整流程。
from langchain.llms import OpenAI # 导入Langchain库的OpenAI模块,提供与OpenAI模型的交互功能
from langchain.prompts import PromptTemplate # 导入用于创建和管理提示模板的模块
from langchain.chains import LLMChain # 导入用于构建基于大型语言模型的处理链的模块
from dotenv import load_dotenv # 导入dotenv库,用于从.env文件加载环境变量,管理敏感数据如API密钥
from langchain.chat_models import ChatOpenAI # 导入用于创建和管理OpenAI聊天模型的类
from langchain.agents import AgentType, initialize_agent, load_tools # 导入用于初始化智能代理和加载工具的函数
from langchain.utilities import ArxivAPIWrapper # 导入Arxiv API的包装器,用于与Arxiv数据库交互
load_dotenv() # 调用dotenv函数加载.env文件中的环境变量
llm = ChatOpenAI(temperature=0.0) # 创建一个温度参数为0.0的OpenAI聊天模型实例,温度0意味着输出更确定性
tools = load_tools(["arxiv"]) # 加载Arxiv工具,以便代理可以访问Arxiv数据库信息
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True, # 初始化一个智能代理,使用零次学习的方式来根据描述做出反应
)
paper = "2307.05782"
response = agent_chain.run("请描述论文的主要内容 " + paper) # 运行代理链,获取指定论文ID的内容描述
print(response) # 打印论文描述的响应
arxiv = ArxivAPIWrapper()
docs = arxiv.run(paper) # 使用Arxiv API获取特定论文的详细信息
print(docs) # 打印论文的详细信息
author = arxiv.run("Michael R. Douglas") # 使用Arxiv API获取指定作者的信息
print(author) # 打印作者信息
nondocs = arxiv.run("1605.08386WWW") # 尝试使用一个非标准格式的ID来获取信息,可能无法正确检索
print(nondocs) # 打印这次非标准检索的结果
运行结果如下
(develop)⚡ % python Tools/chat_tools_arxiv.py ~/Workspace/LLM/langchain-llm-app
> Entering new AgentExecutor chain...
I need to find the main content of the paper with the given arXiv ID.
Action: arxiv
Action Input: 2307.05782
Observation: Published: 2023-10-06
Title: Large Language Models
Authors: Michael R. Douglas
Summary: Artificial intelligence is making spectacular progress, and one of the best
examples is the development of large language models (LLMs) such as OpenAI's
GPT series. In these lectures, written for readers with a background in
mathematics or physics, we give a brief history and survey of the state of the
art, and describe the underlying transformer architecture in detail. We then
explore some current ideas on how LLMs work and how models trained to predict
the next word in a text are able to perform other tasks displaying
intelligence.
Thought:The main content of the paper is about large language models, specifically focusing on the development of OpenAI's GPT series. It provides a history and survey of the state of the art, describes the transformer architecture, and explores current ideas on how LLMs work and their ability to perform various tasks displaying intelligence.
Final Answer: The main content of the paper is about large language models, with a focus on OpenAI's GPT series and their underlying transformer architecture.
> Finished chain.
The main content of the paper is about large language models, with a focus on OpenAI's GPT series and their underlying transformer architecture.
(develop)⚡ % python Tools/chat_tools_arxiv.py ~/Workspace/LLM/langchain-llm-app
Published: 2023-10-06
Title: Large Language Models
Authors: Michael R. Douglas
Summary: Artificial intelligence is making spectacular progress, and one of the best
examples is the development of large language models (LLMs) such as OpenAI's
GPT series. In these lectures, written for readers with a background in
mathematics or physics, we give a brief history and survey of the state of the
art, and describe the underlying transformer architecture in detail. We then
explore some current ideas on how LLMs work and how models trained to predict
the next word in a text are able to perform other tasks displaying
intelligence.
(develop)⚡ % python Tools/chat_tools_arxiv.py ~/Workspace/LLM/langchain-llm-app
Published: 2006-02-24
Title: Understanding the landscape
Authors: Michael R. Douglas
Summary: Based on comments made at the 23rd Solvay Conference, December 2005,
Brussels.
Published: 2005-08-09
Title: Random algebraic geometry, attractors and flux vacua
Authors: Michael R. Douglas
Summary: This is a submission to the Encyclopedia of Mathematical Physics (Elsevier,
2006) and conforms to its referencing guidelines.
Published: 2001-05-02
Title: D-Branes and N=1 Supersymmetry
Authors: Michael R. Douglas
Summary: We discuss the recent proposal that BPS D-branes in Calabi-Yau
compactification of type II string theory are Pi-stable objects in the derived
category of coherent sheaves.
(develop)⚡ % python Tools/chat_tools_arxiv.py ~/Workspace/LLM/langchain-llm-app
No good Arxiv Result was found
4. 根据给定的描述或指令理解并执行任务ZERO_SHOT_REACT_DESCRIPTION
Langchain中的ZERO_SHOT_REACT_DESCRIPTION是一种用于定义和构建智能代理(agent)的方法,属于Langchain框架中的一个组件。它专注于实现代理的“零次学习”(zero-shot learning)能力,即在没有针对具体任务进行专门训练的情况下,根据描述直接做出反应和处理问题。下面详细解释这个概念:
零次学习(Zero-Shot Learning)
- 定义:零次学习是一种机器学习方法,使得模型能够处理它在训练阶段没有直接见过的任务或数据。这种方法依赖于模型对问题的一般理解和处理能力。
- 应用:在Langchain中,这意味着智能代理可以根据描述直接处理各种问题,而不需要针对每种问题进行单独的训练。
Langchain中的ZERO_SHOT_REACT_DESCRIPTION
- 作用:这个模式使得代理能够根据给定的描述或指令理解并执行任务。代理会使用其内置的语言模型来解析和响应问题。
- 实现:通常,这涉及到使用大型语言模型(如GPT系列)来解析自然语言描述,并根据这些描述生成回应或执行操作。
- 优势:这种方法的优势在于灵活性和广泛的适用性,代理不需要对每一种特定的任务类型进行训练即可应对新问题。
- 局限性:然而,由于它依赖于模型的通用理解能力,可能在特定、复杂或非常专业化的任务上不如专门训练的模型准确。
应用场景
- 多功能代理:能够处理各种类型的查询和任务,如信息检索、简单的数据分析、生成文本等。
- 快速适应新任务:在新场景或对新类型的问题作出响应时,不需要额外的训练或配置。
结论
ZERO_SHOT_REACT_DESCRIPTION在Langchain中为开发者提供了一种构建能够处理多种任务的通用智能代理的方法。这种方法特别适合于快速开发和部署、需要高度灵活性和广泛适用性的应用场景。然而,对于需要高度专业化或极端精确度的任务,可能需要考虑其他更专门化的解决方案。
代码
https://github.com/zgpeace/pets-name-langchain/tree/develop
参考
https://python.langchain.com/docs/integrations/tools/arxiv