1、HDFS API简单操作文件
package cn.ctgu.hdfs;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import org.apache.commons.io.output.ByteArrayOutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test;
/*
* 读取hdfs文件
*
* */
public class TestHDFS {
//读取hdfs文件
@Test
public void readFile() throws IOException {
//注册url流处理器工厂(hdfs)
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//获取hdfs的URL连接,即文件所在地
URL url=new URL("hdfs://172.25.11.200:8020/user/hadoop/test.txt");
//打开连接
URLConnection conn=url.openConnection();
//获取输入流
InputStream is=conn.getInputStream();
byte[]buf=new byte[is.available()];
is.read(buf);
is.close();
String str=new String(buf);
System.out.println(str);
}
/*
* 通过hadoop API访问文件
* */
@Test
public void readFileByAPI() throws IOException {
//创建配置文件
Configuration conf=new Configuration();
//设置配置文件
conf.set("fs.defaultFS", "hdfs://172.25.11.200:8020/");
//获取文件系统的一个句柄
FileSystem fs=FileSystem.get(conf);
//获取文件路径
Path p=new Path("/user/hadoop/test.txt");
//打开文件
FSDataInputStream fis=fs.open(p);
byte[]buf=new byte[1024];
int len=-1;
ByteArrayOutputStream baos=new ByteArrayOutputStream();
while((len=fis.read(buf))!=-1) {
baos.write(buf,0,len);
}
fis.close();
baos.close();
System.out.println(new String(baos.toByteArray()));
}
@Test
public void readFileByAPI2() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://172.25.11.200:8020/");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("/user/hadoop/test.txt");
FSDataInputStream fis=fs.open(p);
ByteArrayOutputStream baos=new ByteArrayOutputStream();
//将fis中的数据写入到baos中,缓冲区为1024个字节
IOUtils.copyBytes(fis,baos,1024);
System.out.println(new String(baos.toByteArray()));
}
/*
*
* 权限问题很重要,比如删除文件,我们在window下的角色就是Adminastrator
* 创建出来的就是Adminastrator的,删除也因此只能删除它的
*mkdir,创建目录
*
*
* */
@Test
public void mkdir() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://172.25.11.200:8020/");
FileSystem fs=FileSystem.get(conf);
fs.mkdirs(new Path("/user/hadoop/myhadoop"));
}
/*
*创建文件
*
*
* */
@Test
public void putFile() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://172.25.11.200:8020/");
FileSystem fs=FileSystem.get(conf);
FSDataOutputStream out=fs.create(new Path("/user/hadoop/myhadoop/a.txt"));
out.write("helloworld".getBytes());
out.close();
}
/*
*remove,删除文件
*
*
* */
@Test
public void removeFile() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://172.25.11.200:8020/");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("/user/hadoop/myhadoop/a.txt");
fs.delete(p,true);
}
//定制副本数和块大小
@Test
public void testWriter2() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
//第一个参数是路径,第二参数是是否重写配置,第三个参数是写入文件的缓冲区大小,第四个参数是副本数量,第五个参数是设置块大小
//这里设置为5个字节,默认最小块为1M,可以在hdfs-site.xml中配置,我们可以从hadoop的默认配置文件hdfs-default.xml中找到相应的配置
//文件太小影响性能,尤其是影响namenode,因为一个文件namenode需要152个字节对它进行索引,并且它是存储在内存中的,所以当小文件太多的话需要耗费巨大内存从而导致性能降低
FSDataOutputStream fout=fs.create(new Path("/user/hadoop/hello.txt"),
true,1024,(short)2,5);
}
}
2、MapReduce
2.1 MapReduce代码剖析
WCMapper.java
package cn.ctgu.Hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/9.
*/
public class WCMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text keyout=new Text();
IntWritable valueOut=new IntWritable();
String[] arr=value.toString().split(" ");
for(String s:arr){
keyout.set(s);
valueOut.set(1);
context.write(keyout,valueOut);
}
}
}WCReducer.java
package cn.ctgu.Hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/9.
*/
public class WCReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable iw:values){
count=count+iw.get();
}
context.write(key,new IntWritable(count));
}
}WCApp.java
package cn.ctgu.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/9.
*/
public class WCApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
//conf.set("fs.defaultFS","file:///");//如果在本地windows上运行就得加上这个
Job job=Job.getInstance(conf);
//设置job的各种属性
job.setJobName("WCApp");//作业名称
job.setJarByClass(WCApp.class);//搜索类
job.setInputFormatClass(TextInputFormat.class);//设置输入格式
//添加输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapperClass(WCMapper.class);//mapper类
job.setReducerClass(WCReducer.class);//reduce类
job.setNumReduceTasks(1);//reduce个数
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);//
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}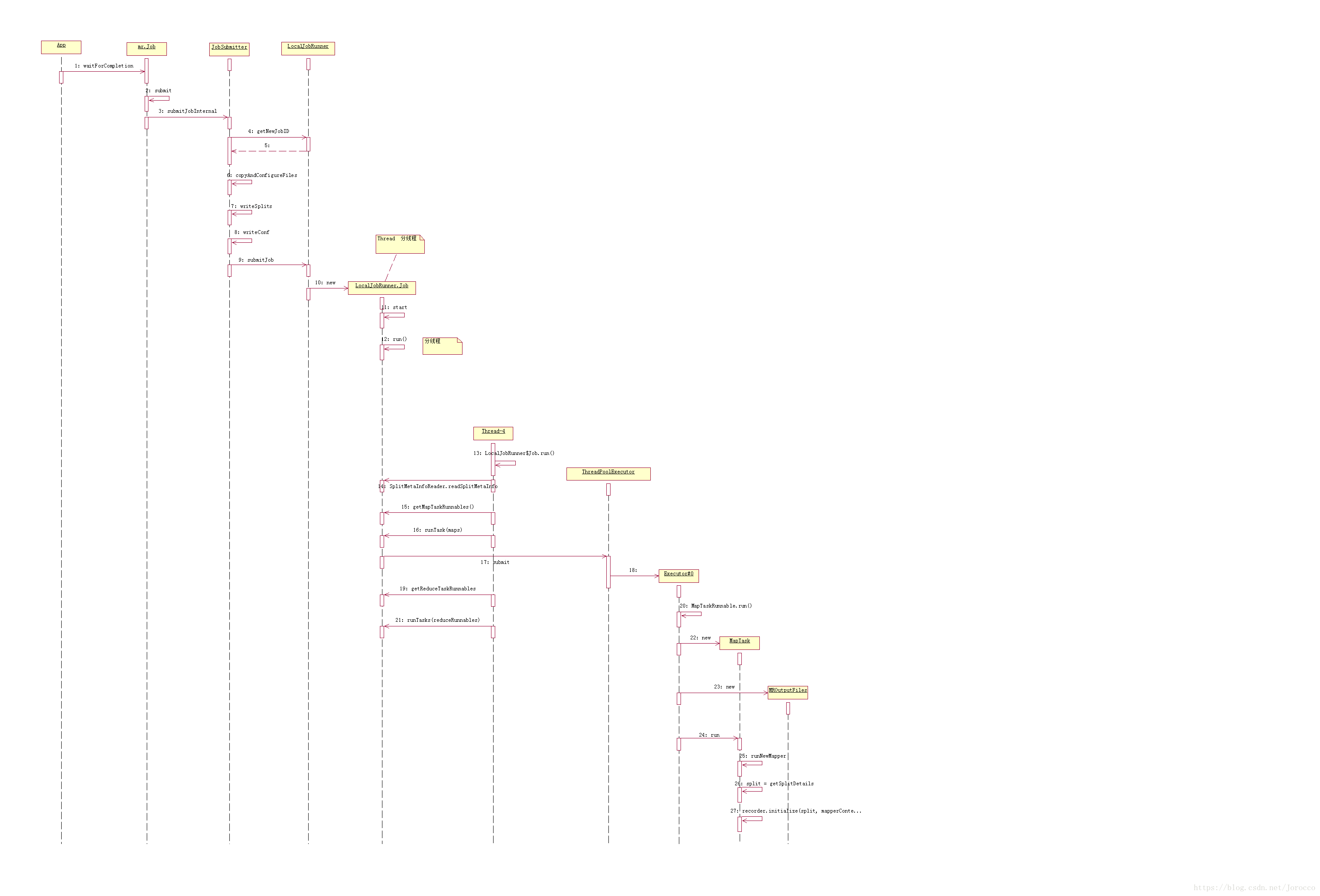
Local模式运行MR流程
1.创建外部Job(mapreduce.Job),设置配置信息
2.通过jobsubmitter将job.xml + split等文件写入临时目录
3.通过jobSubmitter提交job给localJobRunner,
4.LocalJobRunner将外部Job 转换成成内部Job
5.内部Job线程,开放分线程执行job
6.job执行线程分别计算Map和reduce任务信息并通过线程池孵化新线程执行MR任务。
在hadoop集群上运行mrjob
1.导出jar包,通过运行pom.xml中的package命令
maven 2.丢到hadoop
3.运行hadoop jar命令
$>hadoop jar HdfsDemo-1.0-SNAPSHOT.jar cn.ctgu.hdfs.mr.WCApp hdfs:/user/hadoop/wc/data hdfs:/user/hadoop/wc/out
2.2 Job的文件split计算法则
HDFS的写入是以数据包的形式写入的
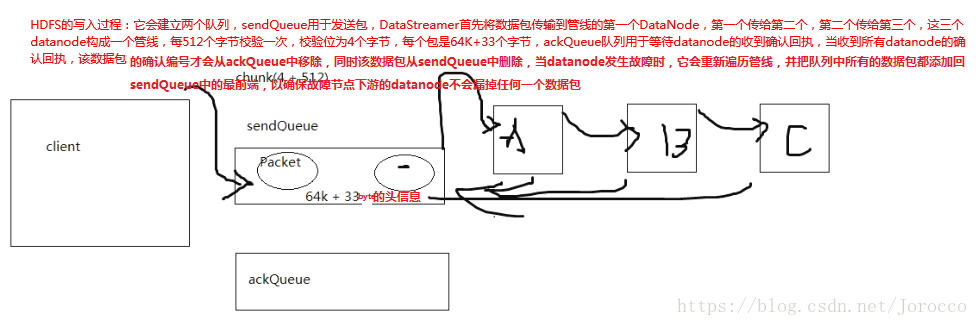
切片
hdfs 切片计算方式(压缩文件不可切割,在源码中通过isSplitable(job,path)判断)
getFormatMinSplitSize() = 1
//最小值(>=1) 1 0
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//最大值(<= Long.Max , mapreduce.input.fileinputformat.split.maxsize=)
long maxSize = getMaxSplitSize(job);
//得到block大小
long blockSize = file.getBlockSize();
//minSplit maxSplit blockSize
//Math.max(minSize, Math.min(maxSize, blockSize));
在最小切片、块大小、最大切片之间取中间值,如果不配置最大、最小切片则取块大小LF : Line feed,换行符
private static final byte CR = '\r';
private static final byte LF = '\n';

3、压缩文件
文件压缩有两大好处:减少存储文件所需要的磁盘空间,加速数据在网络和磁盘上的传输。压缩分为RECORD,即针对每条记录进行压缩,以及BLOCK,即针对一组记录进行压缩,这种效率更高,一般推荐这种压缩。可以使用mapred.output.compression.type属性来设置压缩格式。
package cn.ctgu.Hdfs.compress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.util.ReflectionUtils;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/11.
*
* 测试压缩
*/
public class TestCompress {
@Test
public void deflateCompress() throws IOException {
//deflate编解码器类
Class codecClass= DeflateCodec.class;
//实例对象
CompressionCodec codec=(CompressionCodec)ReflectionUtils.newInstance(codecClass,new Configuration());
//创建文件输出流
FileOutputStream fos=new FileOutputStream("F:/comp/1.deflate");
//得到压缩流
CompressionOutputStream zipout=codec.createOutputStream(fos);
IOUtils.copyBytes(new FileInputStream("F:/徐培成——spark/大数据Spark.docx"),zipout,1024);
zipout.close();
}
@Test
public void deflateCompress1() throws IOException {
Class[]zipClass={
DeflateCodec.class,
GzipCodec.class,
BZip2Codec.class,
SnappyCodec.class,
Lz4Codec.class
};
//压缩
for(Class c:zipClass){
zip(c);
}
//解压缩
for(Class c:zipClass){
unzip(c);
}
}
//压缩测试
public void zip(Class codecClass) throws IOException {
long start=System.currentTimeMillis();
//实例化对象
CompressionCodec codec= (CompressionCodec) ReflectionUtils.newInstance(codecClass,new Configuration());
//创建文件输出流,得到默认扩展名
FileOutputStream fos=new FileOutputStream("F:/comp/b."+codec.getDefaultExtension());
//得到压缩流
CompressionOutputStream zipOut=codec.createOutputStream(fos);
IOUtils.copyBytes(new FileInputStream("F:/徐培成——spark/大数据Spark.docx"),zipOut,1024);
zipOut.close();
System.out.println(codecClass.getSimpleName()+":"+(System.currentTimeMillis()-start));
}
//解压缩
public void unzip(Class codecClass) throws IOException {
long start=System.currentTimeMillis();
//实例化对象
CompressionCodec codec= (CompressionCodec) ReflectionUtils.newInstance(codecClass,new Configuration());
//创建文件输入流
FileInputStream fis=new FileInputStream("F:/comp/b"+codec.getDefaultExtension());
//得到压缩流
CompressionInputStream zipIn=codec.createInputStream(fis);
IOUtils.copyBytes(zipIn,new FileOutputStream("F:/comp/b"+codec.getDefaultExtension()+".txt"),1024);
zipIn.close();
System.out.println(codecClass.getSimpleName()+":"+(System.currentTimeMillis()-start));
}
}1.Windows
源文件大小:82.8k
源文件类型:txt
压缩性能比较
| DeflateCodec GzipCodec BZip2Codec Lz4Codec SnappyCodec |结论
------------|-------------------------------------------------------------------|----------------------
压缩时间(ms)| 450 7 196 44 不支持 |Gzip > Lz4 > BZip2 > Deflate
------------|-------------------------------------------------------------------|----------------------
解压时间(ms)| 444 66 85 33 |lz4 > gzip > bzip2 > Deflate
------------|-------------------------------------------------------------------|----------------------
占用空间(k) | 19k 19k 17k 31k 不支持 |Bzip > Deflate = Gzip > Lz4
| |
2.CentOS
源文件大小:82.8k
源文件类型:txt
| DeflateCodec GzipCodec BZip2Codec Lz4Codec LZO SnappyCodec |结论
------------|---------------------------------------------------------------------------|----------------------
压缩时间(ms)| 944 77 261 53 77 |Gzip > Lz4 > BZip2 > Deflate
------------|---------------------------------------------------------------------------|----------------------
解压时间(ms)| 67 66 106 52 73 |lz4 > gzip > Deflate> lzo > bzip2
------------|---------------------------------------------------------------------------|----------------------
占用空间(k) | 19k 19k 17k 31k 34k |Bzip > Deflate = Gzip > Lz4 > lzo
对于SnappyCodec出现java.lang.RuntimeException: native snappy library not available: this version of libhadoop was built without snappy support.
在centos上使用yum安装snappy压缩库文件
$>sudo yum search snappy #查看是否有snappy库
$>sudo yum install -y snappy.x86_64 #根据centos型号安装snappy压缩解压缩库LZO不是Apache下的,所以需要另外添加依赖
1.在pom.xml引入lzo依赖
<dependency>
<groupId>org.anarres.lzo</groupId>
<artifactId>lzo-hadoop</artifactId>
<version>1.0.0</version>
<scope>compile</scope>
</dependency>2.在centos上安装lzo库
$>sudo yum -y install lzo3.使用mvn命令下载工件中的所有依赖,进入pom.xml所在目录,运行cmd:
mvn -DoutputDirectory=./lib -DgroupId=cn.ctgu -DartifactId=HdfsDemo -Dversion=1.0-SNAPSHOT dependency:copy-dependencies4.在lib下存放依赖所有的第三方jar
5.找出lzo-hadoop.jar + lzo-core.jar复制到centos的hadoop的响应目录下。
$>cp lzo-hadoop.jar lzo-core.jar /soft/hadoop/shared/hadoop/common/lib4、远程调试
开发环境:windows的Intellij idea+centos的集群环境
远程调试:先将在Intellij idea中编辑好的代码打包发送到centos上,然后通过Intellij idea的远程调试机制,在同样的代码上打断点对centos上的运行代码进行调试,和本机运行代码调试机制并无差别,只是代码实质运行在centos上,错误消息也显示在centos上,windows的Intellji idea只是起个打断点调试的作用,两者如此结合使得调试变得更加的便捷。
1.设置服务器java vm的-agentlib:jdwp选项,在centos上进行如下设置:
set JAVA_OPTS=%JAVA_OPTS% -agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=n
下面的是上面的简化,一般用下面的这种方式
export HADOOP_CLIENT_OPTS=-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=y2.在server启动java程序
hadoop jar HdfsDemo.jar cn.ctgu.hdfs.mr.compress.TestCompress3.server会暂挂在8888.
Listening ...4.客户端通过远程调试连接到远程主机的8888.
Run-->Edit Configurations-->RemotesIntellij idea远程调试设置
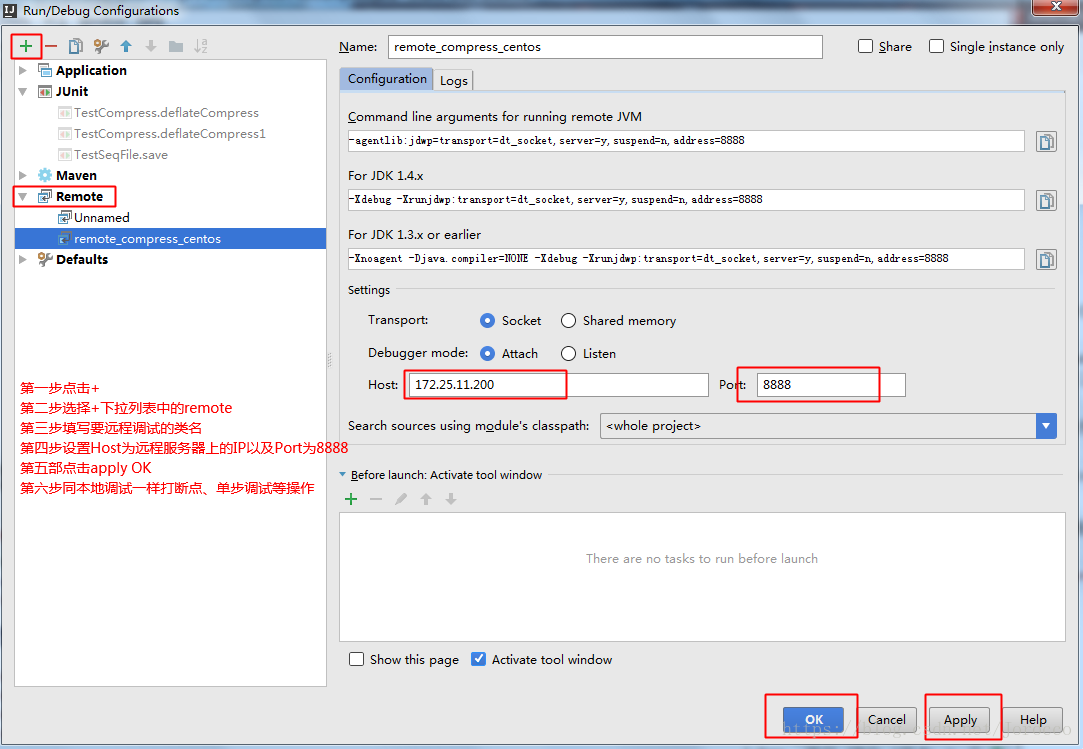
当连接成功之后,centos会一直处于监听状态

当Intellij idea上显示连接成功,就可以进行相应的调试动作
在pom.xml中引入新的插件(maven-antrun-plugin),实现文件的复制.
<build>
<plugins>
...
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-antrun-plugin</artifactId>
<version>1.8</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>run</goal>
</goals>
<configuration>
<tasks>
<echo>---------开始复制jar包到共享目录下----------</echo>
<delete file="D:\downloads\bigdata\data\HdfsDemo-1.0-SNAPSHOT.jar"></delete>
<copy file="target/HdfsDemo-1.0-SNAPSHOT.jar" toFile="D:\downloads\bigdata\data\HdfsDemo.jar">
</copy>
</tasks>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>修改maven使用aliyun镜像,国内镜像相对稳定
[maven/conf/settings.xml]
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>5、SequenceFile
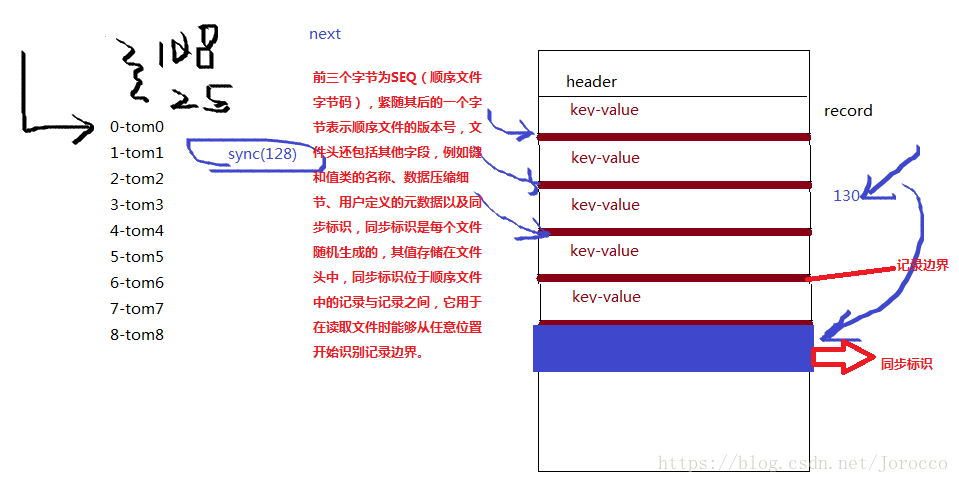
文件格式:SequenceFile,当在MapReduce中操作SequnceFile的时候输入格式也要改成相应的SequenceFileInputFormat,它不是文本文件,而是一种二进制文件,可切割,因为有同步点,一般不压缩,record压缩的时候只压缩value,Block压缩是按照多个record形成一个block。
package cn.ctgu.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.junit.Test;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/11.
*/
public class TestSeqFile {
//序列文件(二进制)写操作
@Test
public void save() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS","File:///");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("J:/hadoop/home/comp/1.seq");
SequenceFile.Writer writer=SequenceFile.createWriter(fs,conf,p, IntWritable.class, Text.class);
for(int i=0;i<10;i++){
writer.append(new IntWritable(i),new Text("tom"+i));
}
writer.close();
}
//读操作
@Test
public void read() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS","File:///");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("J:/hadoop/home/comp/1.seq");
SequenceFile.Reader reader=new SequenceFile.Reader(fs,p,conf);
IntWritable key=new IntWritable();
Text value=new Text();
//获取当前的值
/* while(reader.next(key)){
reader.getCurrentValue(value);
System.out.println(value.toString());
}*/
while(reader.next(key,value)){
reader.getCurrentValue(value);
System.out.println(key.get()+":"+value.toString());
}
reader.close();
}
//读操作
@Test
public void read1() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS","File:///");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("J:/hadoop/home/comp/1.seq");
SequenceFile.Reader reader=new SequenceFile.Reader(fs,p,conf);
//得到文件指针
long pos= reader.getPosition();
System.out.println(pos);
}
}
6、MapFile
MapFile是已经排过序的SequenceFile,它有索引,可以按键查找。
文件格式:MapFile,Key-value存储,key按升序写入(可重复),mapFile对应一个目录,目录下有index和data文件,都是序列文件。index文件划分key区间,用于快速定位。
ackage cn.ctgu.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.junit.Test;
import java.io.IOException;
/**
* Created by Administrator on 2018/6/11.
*/
public class TestMapFile {
//mapFile文件写操作
@Test
public void save() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS","File:///");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("J:/hadoop/home/comp/1.seq");
MapFile.Writer writer=new MapFile.Writer(conf,fs,"J:/Program/comp",IntWritable.class,Text.class);
for(int i=0;i<10000;i++){
writer.append(new IntWritable(i),new Text("tom"+i));
}
writer.close();
}
//读操作
@Test
public void read() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS","File:///");
FileSystem fs=FileSystem.get(conf);
Path p=new Path("J:/hadoop/home/comp/1.seq");
MapFile.Reader reader=new MapFile.Reader(fs,"J:/Program/comp",conf);
IntWritable key=new IntWritable();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key.get()+":"+value.toString());
}
reader.close();
}
}可通过 hdfs dfs -text 1.seq 查看相关文件