IO 是英文 Input 和 Output 的首字母,代表了输入和输出。操作系统(Linux)负责对计算机的资源进行管理和对进程进行调度,应用程序运行在操作系统上,处于用户空间。应用程序不能直接对硬件进行操作,只能通过操作系统提供的API 来操作硬件。需要将进程切换到内核空间,才能进行 IO 操作,并且应用程序不能直接操作内核空间的数据,需要把内核空间的数据拷贝到用户空间。
应用程序运行在用户空间,它不存在实质的 IO 过程,真正的IO 是在操作系统执行的。那么应用程序操作 IO 就会有两个动作:IO 调用和 IO 执行。IO 调用是应用程序向操作系统内核发起调用,IO 执行是操作系统内核完成的 IO 操作。
IO 模型根据实现的功能可以划分为为阻塞 IO、非阻塞 IO、信号驱动IO,IO多路复用和异步 IO。根据等待 IO 的执行结果进行划分,前四个 IO 模型又被称为同步IO,如下图
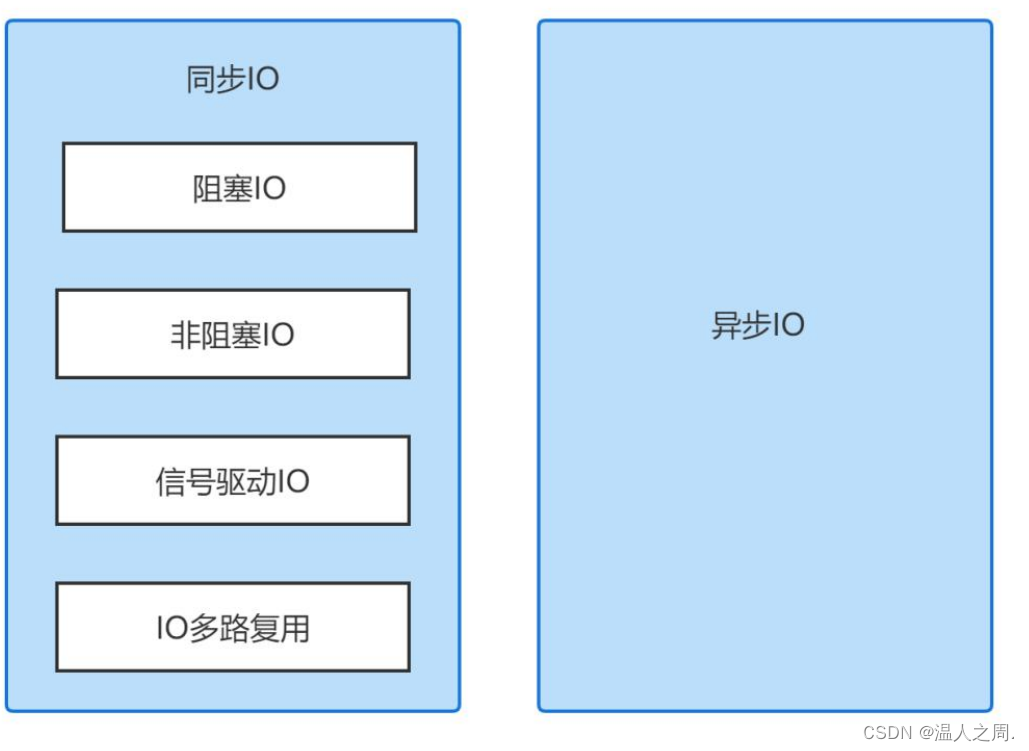
所谓同步,即发出一个功能调用后,只有得到结果该调用才会返回。异步的概念和同步相对。当一个异步过程调用发出后,调用者并不能立刻得到结果,实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
一、阻塞 IO
以阻塞读为例:进程进行 IO 操作时(如 read 操作),首先会发起一个系统调用,从而转到内核空间进行处理,内核空间的数据没有准备就绪时,进程会被阻塞,不会继续向下执行,直到内核空间的数据准备完成后,数据才会从内核空间拷贝到用户空间,最后返回用户进程,由用户空间进行数据的处理
阻塞 IO 的优势与不足为:首先可以及时的获取结果,并立刻对获取到的结果进行处理,然而在获取结果之前,无法去处理其他任务,需要时刻对结果进行监听。
二、非阻塞 IO
和阻塞 IO 模型不同,非阻塞 IO 进行 IO 操作时,如果内核数据没有准备好,内核会立即向进程返回 err,不会进行阻塞;如果内核空间数据准备就绪,内核会立即把数据返回给用户空间的进程
非阻塞 IO 的优点是效率高,同样的时间可以做更多的事。但是缺点也很明显,需要不断对结果进行轮询查看,从而导致结果获取不及时(结果可能在两次轮询之间就已经准备完毕,但是只能在发起轮询的时候才能知道),如果要增加非阻塞IO的实时性,就要加快轮询的频率,但这样无疑也会增加 CPU 的负担。
三、IO 多路复用
通常情况下使用 select()、poll()、epoll()函数实现 IO 多路复用。以select 函数为例,使用时可以对 select 传入多个描述符,并设置超时时间。当执行select 的时候,系统会发起一个系统调用,内核会遍历检查传入的描述符是否有事件发生(如可读、可写事件)。如有,立即返回,否则进入睡眠状态,使进程进入阻塞状态,直到任何一个描述符事件产生后(或者等待超时)立刻返回。此时用户空间需要对全部描述符进行遍历,以确认具体是哪个发生了事件,这样就能使用一个进程对多个 IO 进行管理
这样的优点是一个进程/线程可以同时监听和处理多路 IO,效率成倍提高。但是IO多路复用也有缺点:虽然 IO 多路复用可以监听多个IO,但是实际上对结果的处理也只能依次进行,比较适合 IO 密集但是每一路 IO 数据量不多且到达时间分散的场合(如网络聊天)。
另外 select 监听的描述符有上限(一般描述符最大不超过1024),而且需要遍历究竟是哪一个 IO 产生了数据。因此 IO 较多时,效率不高
四、信号驱动IO
信号驱动 IO 顾名思义与信号相关。系统在一些事件发生之后,会对进程发出特定的信号,而信号与处理函数相绑定,当信号产生时就会调用绑定的处理函数。例如在Linux 系统任务执行的过程中可以按下 ctrl+C 来对任务进行终止,系统实际上是对该进程发送一个SIGINT信号,该信号的默认处理函数就是退出当前程序。
具体到 IO 模型上,可以对 SIGIO 信号注册相应的信号处理函数,并打开对应描述符的信号驱动。每当有 IO 数据产生时,系统就会发送一个 SIGIO 信号,进而调用相应的信号处理函数,从而在这个处理函数中对数据进行读取
五、异步 IO
aio_read 函数常常用于异步 IO,当进程使用 aio_read 读取数据时,如果数据尚未准备就绪就立即返回,不会阻塞。若数据准备就绪就会把数据从内核空间拷贝到用户空间的缓冲区中,然后执行定义好的回调函数对接收到的数据进行处理。