块设备是Linux三大设备之一,其驱动模型主要针对磁盘,Flash等存储类设备,块设备(blockdevice)是一种具有一定结构的随机存取设备,对这种设备的读写是按块(所以叫块设备)进行的,他使用缓冲区来存放暂时的数据,待条件成熟后,从缓存一次性写入设备或者从设备一次性读到缓冲区。作为存储设备,块设备驱动的核心问题就是哪些page->segment->block->sector与哪些sector有数据交互,本文以3.14为蓝本,探讨内核中的块设备驱动模型。
框架
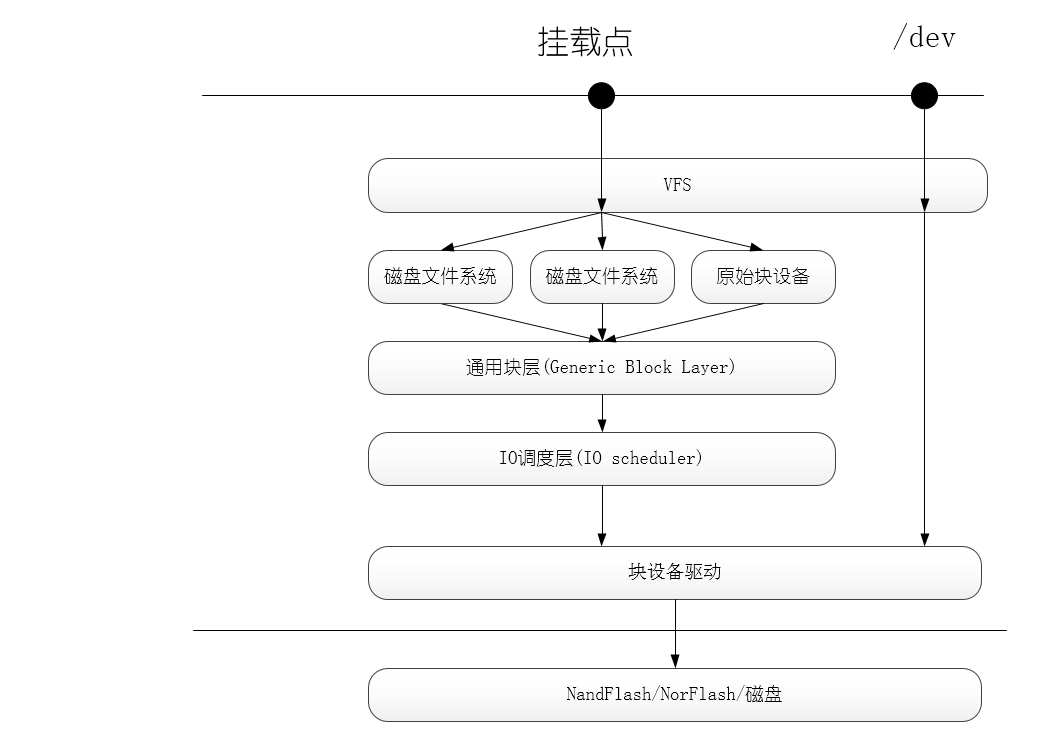
下图是Linux中的块设备模型示意图,应用层程序有两种方式访问一个块设备:/dev和文件系统挂载点,前者和字符设备一样,通常用于配置,后者就是我们mount之后通过文件系统直接访问一个块设备了。
- read()系统调用最终会调用一个适当的VFS函数(read()-->sys_read()-->vfs_read()),将文件描述符fd和文件内的偏移量offset传递给它。
- VFS会判断这个SCI的处理方式,如果访问的内容已经被缓存在RAM中(磁盘高速缓存机制),就直接访问,否则从磁盘中读取
- 为了从物理磁盘中读取,内核依赖映射层mapping layer,即上图中的磁盘文件系统
- 确定该文件所在文件系统的块的大小,并根据文件块的大小计算所请求数据的长度。本质上,文件被拆成很多块,因此内核需要确定请求数据所在的块
- 映射层调用一个具体的文件系统的函数,这个层的函数会访问文件的磁盘节点,然后根据逻辑块号确定所请求数据在磁盘上的位置。
- 内核利用通用块层(generic block layer)启动IO操作来传达所请求的数据,通常,一个IO操作只针对磁盘上一组连续的块。
- IO调度程序根据预先定义的内核策略将待处理的IO进行重排和合并
- 块设备驱动程序向磁盘控制器硬件接口发送适当的指令,进行实际的数据操作
块设备 VS 字符设备
作为一种存储设备,和字符设备相比,块设备有以下几种不同:
| 字符设备 | 块设备 |
|---|---|
| 1byte | 块,硬件块各有不同,但是内核都使用512byte描述 |
| 顺序访问 | 随机访问 |
| 没有缓存,实时操作 | 有缓存,不是实时操作 |
| 一般提供接口给应用层 | 块设备一般提供接口给文件系统 |
| 是被用户程序调用 | 由文件系统程序调用 |
此外,大多数情况下,磁盘控制器都是直接使用DMA方式进行数据传送。
IO调度
就是电梯算法。我们知道,磁盘是的读写是通过机械性的移动磁头来实现读写的,理论上磁盘设备满足块设备的随机读写的要求,但是出于节约磁盘,提高效率的考虑,我们希望当磁头处于某一个位置的时候,一起将最近需要写在附近的数据写入,而不是这写一下,那写一下然后再回来,IO调度就是将上层发下来的IO请求的顺序进行重新排序以及对多个请求进行合并,这样就可以实现上述的提高效率、节约磁盘的目的。这种解决问题的思路使用电梯算法,一个运行中的电梯,一个人20楼->1楼,另外一个人15->5楼,电梯不会先将第一个人送到1楼再去15楼接第二个人将其送到5楼,而是从20楼下来,到15楼的时候停下接人,到5楼将第二个放下,最后到达1楼,一句话,电梯算法最终服务的优先顺序并不按照按按钮的先后顺序。Linux内核中提供了下面的几种电梯算法来实现IO调度:
- No-op I/O scheduler只实现了简单的FIFO的,只进行最简单的合并,比较适合基于Flash的存储
- Anticipatory I/O scheduler推迟IO请求(大约几个微秒),以期能对他们进行排序,获得更高效率
- Deadline I/O scheduler试图把每次请求的延迟降到最低,同时也会对BIO重新排序,特别适用于读取较多的场合,比如数据库
- CFQ I/O scheduler为系统内所有的任务分配均匀的IO带宽,提供一个公平的工作环境,在多媒体环境中,能保证音视频及时从磁盘中读取数据,是当前内核默认的调度器
我们可以通过内核传参的方式指定使用的调度算法
kernel elevator=deadline或者,使用如下命令改变内核调度算法
echo SCHEDULER > /sys/block/DEVICE/queue/schedulerPage->Segment->Block->Sector VS Sector
VS左面(Page->Segment->Block->Sector)是数据交互中的内存部分,Page就是内存映射的最小单位; Segment就是一个Page中我们要操作的一部分,由若干个相邻的块组成; Block(块)是逻辑上的进行数据存取的最小单位,是文件系统的抽象,逻辑块的大小是在格式化的时候确定的, 一个 Block 最多仅能容纳一个文件(即不存在多个文件同一个block的情况)。如果一个文件比block小,他也会占用一个block,因而block中空余的空间会浪费掉。而一个大文件,可以占多个甚至数十个成百上千万的block。Linux内核要求 Block_Size = Sector_Size * (2的n次方),并且Block_Size <= 内存的Page_Size(页大小), 如ext2 fs的block缺省是4k。若block太大,则存取小文件时,有空间浪费的问题;若block太小,则硬盘的 Block 数目会大增,而造成 inode 在指向 block 的时候的一些搜寻时间的增加,又会造成大文件读写方面的效率较差,block是VFS和文件系统传送数据的基本单位。block对应磁盘上的一个或多个相邻的扇区,而VFS将其看成是一个单一的数据单元,块设备的block的大小不是唯一的,创建一个磁盘文件系统时,管理员可以选择合适的扇区的大小,同一个磁盘的几个分区可以使用不同的块大小。此外,对块设备文件的每次读或写操作是一种"原始"访问,因为它绕过了磁盘文件系统,内核通过使用最大的块(4096)执行该操作。Linux对内存中的block会被进一步划分为Sector,Sector是硬件设备传送数据的基本单位,这个Sector就是512byte,和物理设备上的概念不一样,如果实际的设备的sector不是512byte,而是4096byte(eg SSD),那么只需要将多个内核sector对应一个设备sector即可
VS右边是物理上的概念,磁盘中一个Sector是512Byte,SSD中一个Sector是4K
核心结构与方法简述
核心结构
- gendisk是一个物理磁盘或分区在内核中的描述
- block_device_operations描述磁盘的操作方法集,block_device_operations之于gendisk,类似于file_operations之于cdev
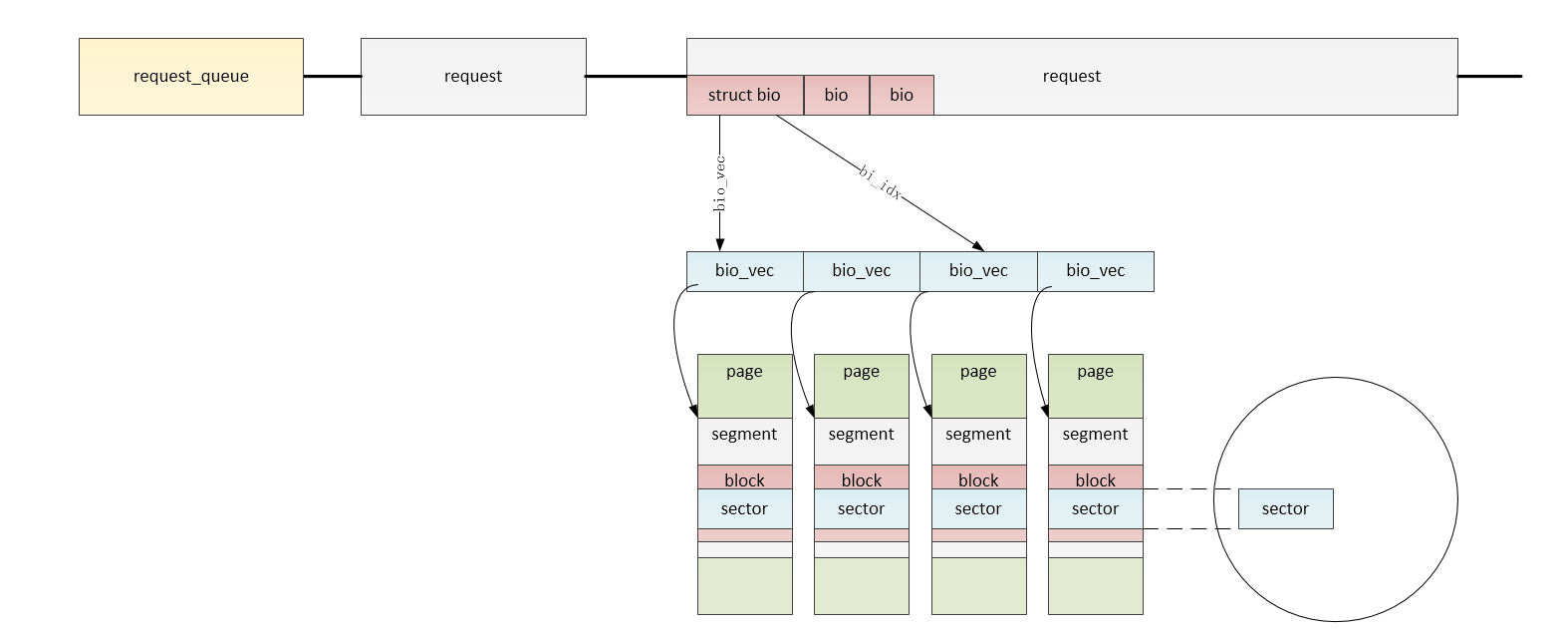
- request_queue对象表示针对一个gendisk对象的所有请求的队列,是相应gendisk对象的一个域
- request表示经过IO调度之后的针对一个gendisk(磁盘)的一个"请求",是request_queue的一个节点。多个request构成了一个request_queue
- bio表示应用程序对一个gendisk(磁盘)原始的访问请求,一个bio由多个bio_vec,多个bio经过IO调度和合并之后可以形成一个request。
- bio_vec描述的应用层准备读写一个gendisk(磁盘)时需要使用的内存页page的一部分,即上文中的"段",多个bio_vec和bio_iter形成一个bio
- bvec_iter描述一个bio_vec中的一个sector信息
核心方法
- set_capacity()设置gendisk对应的磁盘的物理参数
- blk_init_queue()分配+初始化+绑定一个有IO调度的gendisk的requst_queue,处理函数是**void (request_fn_proc) (struct request_queue *q);**类型
- blk_alloc_queue() 分配+初始化一个没有IO调度的gendisk的request_queue,
- blk_queue_make_request()绑定处理函数到一个没有IO调度的request_queue,处理函数函数是void (make_request_fn) (struct request_queue q, struct bio bio);类型
- __rq_for_each_bio()遍历一个request中的所有的bio
- bio_for_each_segment()遍历一个bio中所有的segment
- rq_for_each_segment()遍历一个request中的所有的bio中的所有的segment
最后三个遍历算法都是用在request_queue绑定的处理函数中,这个函数负责对上层请求的处理。
核心结构与方法详述
gendisk
同样是面向对象的设计方法,Linux内核使用gendisk对象描述一个系统的中的块设备,类似于Windows系统中的磁盘分区和物理磁盘的关系,OS眼中的磁盘都是逻辑磁盘,也就是一个磁盘分区,一个物理磁盘可以对应多个磁盘分区,在Linux中,这个gendisk就是用来描述一个逻辑磁盘,也就是一个磁盘分区。


1 struct gendisk { 2 /* major, first_minor and minors are input parameters only, 3 * don't use directly. Use disk_devt() and disk_max_parts(). 4 */ 5 int major; /* major number of driver */ 6 int first_minor; 7 int minors; /* maximum number of minors, =1 for 8 * disks that can't be partitioned. */ 9 10 char disk_name[DISK_NAME_LEN]; /* name of major driver */ 11 char *(*devnode)(struct gendisk *gd, umode_t *mode); 12 13 unsigned int events; /* supported events */ 14 unsigned int async_events; /* async events, subset of all */ 15 16 /* Array of pointers to partitions indexed by partno. 17 * Protected with matching bdev lock but stat and other 18 * non-critical accesses use RCU. Always access through 19 * helpers. 20 */ 21 struct disk_part_tbl __rcu *part_tbl; 22 struct hd_struct part0; 23 24 const struct block_device_operations *fops; 25 struct request_queue *queue; 26 void *private_data; 27 28 int flags; 29 struct device *driverfs_dev; // FIXME: remove 30 struct kobject *slave_dir; 31 32 struct timer_rand_state *random; 33 atomic_t sync_io; /* RAID */ 34 struct disk_events *ev; 35 #ifdef CONFIG_BLK_DEV_INTEGRITY 36 struct blk_integrity *integrity; 37 #endif 38 int node_id; 39 };
--major: 驱动的主设备号
--first_minor: 第一个次设备号
--minors: 次设备号的数量,即允许的最大分区的数量,1表示不允许分区
--disk_name: 设备名称
--part_tbl: 分区表数组首地址
--part0: 第一个分区,相当于part_tbl->part[0]
--fops: 操作方法集指针
--queue: 请求对象指针
--private_data: 私有数据指针
--driverfs_dev: 表示这是一个设备
gendisk是一个动态分配的结构体,所以不要自己手动来分配,而是使用内核相应的API来分配,其中会做一些初始化的工作
struct gendisk *alloc_disk(int minors); //注册gendisk类型对象到内核 void add_disk(struct gendisk *disk); //从内核注销gendisk对象 void del_gendisk(struct gendisk *gp);
上面几个API是一个块设备驱动中必不可少的部分,下面的两个主要是用来内核对于设备管理用的,通常不要驱动来实现
//对gendisk的引用计数+1 struct kobject *get_disk(struct gendisk *disk); //对gendisk的引用计数-1 void put_disk(struct gendisk *disk);
这两个API最终回调用kobject *get_disk() 和kobject_put()来实现对设备的引用计数
block_device_operations
和字符设备一样,如果使用/dev接口访问块设备,最终就会回调这个操作方法集的注册函数
1 //linux-4.0\include\linux\blkdev.h 2 struct block_device_operations { 3 int (*open) (struct block_device *, fmode_t); 4 void (*release) (struct gendisk *, fmode_t); 5 int (*rw_page)(struct block_device *, sector_t, struct page *, int rw); 6 int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); 7 int (*compat_ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); 8 long (*direct_access)(struct block_device *, sector_t,void **, unsigned long *pfn, long size); 9 unsigned int (*check_events) (struct gendisk *disk,unsigned int clearing); 10 /* ->media_changed() is DEPRECATED, use ->check_events() instead */ 11 int (*media_changed) (struct gendisk *); 12 void (*unlock_native_capacity) (struct gendisk *); 13 int (*revalidate_disk) (struct gendisk *); 14 int (*getgeo)(struct block_device *, struct hd_geometry *); 15 /* this callback is with swap_lock and sometimes page table lock held */ 16 void (*swap_slot_free_notify) (struct block_device *, unsigned long); 17 struct module *owner; 18 };
struct block_device_operations
--open: 当应用层打开一个块设备的时候被回调
--release: 当应用层关闭一个块设备的时候被回调
--compat_ioctl: 相当于file_operations里的compat_ioctl,不过块设备的ioctl包含大量的标准操作,所以在这个接口实现的操作很少
--direct_access:在移动块设备中测试介质是否改变的方法,已经过时,同样的功能被check_event()实现 (热插拔)
--getgeo: 即get geometry,获取驱动器的几何信息,获取到的信息会被填充在一个hd_geometry结构中
--owner: 模块所属,通常填THIS_MODULE
request_queue
每一个gendisk对象都有一个request_queue对象,前文说过,块设备有两种访问接口,一种是/dev下,一种是通过文件系统,后者经过IO调度在这个gendisk->request_queue上增加请求,最终回调与request_queue绑定的处理函数,将这些请求向下变成具体的硬件操作
1 struct request_queue { 2 /* 3 * Together with queue_head for cacheline sharing 4 */ 5 struct list_head queue_head; 6 struct request *last_merge; 7 struct elevator_queue *elevator; 8 int nr_rqs[2]; /* # allocated [a]sync rqs */ 9 int nr_rqs_elvpriv; /* # allocated rqs w/ elvpriv */ 10 11 ............................. 12 };
--queue_head:请求队列的链表头
--elevator:请求队列使用的IO调度算法,通过内核启动参数选择:kernel elevator=deadline
request_queue_t和gendisk一样需要使用内核API来分配并初始化,里面大量的成员不要直接操作, 此外, 请求队列如果要正常工作还需要绑定到一个处理函数中, 当请求队列不为空时, 处理函数会被回调, 这就是块设备驱动中处理请求的核心部分!
从驱动模型的角度来说, 块设备主要分为两类需要IO调度的和不需要IO调度的, 前者包括磁盘, 光盘等, 后者包括Flash, SD卡等, 为了保证模型的统一性 , Linux中对这两种使用同样的模型但是通过不同的API来完成上述的初始化和绑定
有IO调度类设备API
//初始化+绑定 struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)
无IO调度类设备API
//初始化 struct request_queue *blk_alloc_queue(gfp_t gfp_mask) //绑定 void blk_queue_make_request(struct request_queue *q, make_request_fn *mfn)
共用API
针对请求队列的操作是块设备的一个核心任务, 其实质就是对请求队列操作函数的编写, 这个函数的主要功能就是从请求队列中获取请求并根据请求进行相应的操作 内核中已经提供了大量的API供该函数使用
//清除请求队列, 通常在卸载函数中使用 void blk_cleanup_queue(struct request_queue *q) //从队列中去除请求 blkdev_dequeue_request(struct request *rq) //提取请求 struct request *blk_fetch_request(struct request_queue *q) //从队列中去除请求 struct request *blk_peek_request(struct request_queue *q) //启停请求队列, 当设备进入到不能处理请求队列的状态时,应通知通用块层 void blk_stop_queue(struct request_queue *q) void blk_start_queue(struct request_queue *q)
request
1 struct request { 2 struct list_head queuelist; 3 union { 4 struct call_single_data csd; 5 unsigned long fifo_time; 6 }; 7 8 struct request_queue *q; 9 struct blk_mq_ctx *mq_ctx; 10 11 u64 cmd_flags; 12 enum rq_cmd_type_bits cmd_type; 13 unsigned long atomic_flags; 14 15 int cpu; 16 17 /* the following two fields are internal, NEVER access directly */ 18 unsigned int __data_len; /* total data len */ 19 sector_t __sector; /* sector cursor */ 20 21 struct bio *bio; 22 struct bio *biotail; 23 24 /* 25 * The hash is used inside the scheduler, and killed once the 26 * request reaches the dispatch list. The ipi_list is only used 27 * to queue the request for softirq completion, which is long 28 * after the request has been unhashed (and even removed from 29 * the dispatch list). 30 */ 31 union { 32 struct hlist_node hash; /* merge hash */ 33 struct list_head ipi_list; 34 }; 35 36 /* 37 * The rb_node is only used inside the io scheduler, requests 38 * are pruned when moved to the dispatch queue. So let the 39 * completion_data share space with the rb_node. 40 */ 41 union { 42 struct rb_node rb_node; /* sort/lookup */ 43 void *completion_data; 44 }; 45 46 /* 47 * Three pointers are available for the IO schedulers, if they need 48 * more they have to dynamically allocate it. Flush requests are 49 * never put on the IO scheduler. So let the flush fields share 50 * space with the elevator data. 51 */ 52 union { 53 struct { 54 struct io_cq *icq; 55 void *priv[2]; 56 } elv; 57 58 struct { 59 unsigned int seq; 60 struct list_head list; 61 rq_end_io_fn *saved_end_io; 62 } flush; 63 }; 64 65 struct gendisk *rq_disk; 66 struct hd_struct *part; 67 unsigned long start_time; 68 ............................. 69 };
queuelist:将这个request挂接到链表的节点
q:这个request从属的request_queue
bio:组成这个request的bio链表头指针
biotail:组成这个request的bio链表的为指针
hash:内核hash表头指针
bio
bio用来描述单一的I/O请求,它记录了一次I/O操作所必需的相关信息,如用于I/O操作的数据缓存位置,,I/O操作的块设备起始扇区,是读操作还是写操作等等
下列结构体定义并未完整定义。
1 struct bio { 2 struct bio *bi_next; /* request queue link */ 3 struct block_device *bi_bdev; 4 unsigned long bi_flags; /* status, command, etc */ 5 unsigned long bi_rw; /* bottom bits READ/WRITE, 6 * top bits priority 7 */ 8 struct bvec_iter bi_iter; 9 unsigned int bi_phys_segments; 10 unsigned int bi_seg_front_size; 11 unsigned int bi_seg_back_size; 12 atomic_t bi_remaining; 13 bio_end_io_t *bi_end_io; 14 void *bi_private; 15 unsigned short bi_vcnt; /* how many bio_vec's */ 16 unsigned short bi_max_vecs; /* max bvl_vecs we can hold */ 17 struct bio_vec *bi_io_vec; /* the actual vec list */ 18 struct bio_vec bi_inline_vecs[0]; 19 };
bi_next:指向链表中下一个bio的指针bi_next
bi_rw:低位表示读写READ/WRITE, 高位表示优先级
bi_vcnt:bio对象包含bio_vec对象的数目
bi_max_vecs:这个bio能承载的最大的io_vec的数目
bi_io_vec:实际的vec列表
bi_inline_vecs[0]:表示这个bio包含的bio_vec变量的数组,即这个bio对应的某一个page中的一"段"内存
bio_vec
描述指定page中的一块连续的区域,在bio中描述的就是一个page中的一个"段"(segment)
1 struct bio_vec { 2 struct page *bv_page;//描述的page 3 unsigned int bv_len;//描述的长度 4 unsigned int bv_offset;//描述的起始地址偏移量 5 };
bio_iter
用于记录当前bvec被处理的情况,用于遍历bio
1 struct bvec_iter { 2 sector_t bi_sector; /* device address in 512 byte sectors */ 3 unsigned int bi_size; /* residual I/O count */ 4 unsigned int bi_idx; /* current index into bvl_vec */ 5 unsigned int bi_bvec_done; /* number of bytes completed in current bvec */ 6 };
__rq_for_each_bio()
遍历一个request的每一个bio
1 #define __rq_for_each_bio(_bio, rq) \ 2 if ((rq->bio)) \ 3 for (_bio = (rq)->bio; _bio; _bio = _bio->bi_next)
bio_for_each_segment()
遍历一个bio中的每一个segment
1 #define bio_for_each_segment(bvl, bio, iter) \ 2 __bio_for_each_segment(bvl, bio, iter, (bio)->bi_iter)
rq_for_each_segment()
遍历一个request中的每一个segment
1 #define rq_for_each_segment(bvl, _rq, _iter) \ 2 __rq_for_each_bio(_iter.bio, _rq) \ 3 bio_for_each_segment(bvl, _iter.bio, _iter.iter)
小结
遍历request_queue,绑定函数的一个必要的工作就是将request_queue中的数据取出, 所以遍历是必不可少的, 针对有IO调度的设备, 我们需要从中提取请求再继续操作, 对于没有IO调度的设备, 我们可以直接从request_queue中提取bio进行操作, 这两种处理函数的接口就不一样,下面的例子是对LDD3中的代码进行了修剪而来的,相应的API使用的是3.14版本,可以看出这两种模式的使用方法的不同。
sbull_init
└── setup_device
├──sbull_make_request
│ ├──sbull_xfer_bio
│ └──sbull_transfer
└──sbull_full_request
├──blk_fetch_request
└──sbull_xfer_request
├── __rq_for_each_bio
└── sbull_xfer_bio
└──sbull_transfer
1 /* 2 * Handle an I/O request. 3 * 实现扇区的读写 4 */ 5 static void sbull_transfer(struct sbull_dev *dev, unsigned long sector,unsigned long nsect, char *buffer, int write) 6 { 7 unsigned long offset = sector*KERNEL_SECTOR_SIZE; 8 unsigned long nbytes = nsect*KERNEL_SECTOR_SIZE; 9 if (write) 10 memcpy(dev->data + offset, buffer, nbytes); 11 else 12 memcpy(buffer, dev->data + offset, nbytes); 13 } 14 /* 15 * Transfer a single BIO. 16 */ 17 static int sbull_xfer_bio(struct sbull_dev *dev, struct bio *bio) 18 { 19 struct bvec_iter i; //用来遍历bio_vec对象 20 struct bio_vec bvec; 21 sector_t sector = bio->bi_iter.bi_sector; 22 /* Do each segment independently. */ 23 bio_for_each_segment(bvec, bio, i) { //bvec会遍历bio中每一个bio_vec对象 24 char *buffer = __bio_kmap_atomic(bio, i, KM_USER0); 25 sbull_transfer(dev, sector, bio_cur_bytes(bio)>>9 ,buffer, bio_data_dir(bio) == WRITE); 26 sector += bio_cur_bytes(bio)>>9; 27 __bio_kunmap_atomic(bio, KM_USER0); 28 } 29 return 0; /* Always "succeed" */ 30 } 31 32 /* 33 * Transfer a full request. 34 */ 35 static int sbull_xfer_request(struct sbull_dev *dev, struct request *req) 36 { 37 struct bio *bio; 38 int nsect = 0; 39 40 __rq_for_each_bio(bio, req) { 41 sbull_xfer_bio(dev, bio); 42 nsect += bio->bi_size/KERNEL_SECTOR_SIZE; 43 } 44 return nsect; 45 } 46 47 /* 48 * Smarter request function that "handles clustering".*/ 49 static void sbull_full_request(struct request_queue *q) 50 { 51 struct request *req; 52 int nsect; 53 struct sbull_dev *dev ; 54 int i = 0; 55 while ((req = blk_fetch_request(q)) != NULL) { 56 dev = req->rq_disk->private_data; 57 nsect = sbull_xfer_request(dev, req); 58 __blk_end_request(req, 0, (nsect<<9)); 59 printk ("i = %d\n", ++i); 60 } 61 } 62 63 //The direct make request version 64 static void sbull_make_request(struct request_queue *q, struct bio *bio) 65 { 66 struct sbull_dev *dev = q->queuedata; 67 int status; 68 69 status = sbull_xfer_bio(dev, bio); 70 bio_endio(bio, status); 71 72 return; 73 } 74 /* 75 * The device operations structure. 76 */ 77 static struct block_device_operations sbull_ops = { 78 .owner = THIS_MODULE, 79 .open = sbull_open, 80 .release= sbull_release, 81 .getgeo = sbull_getgeo, 82 }; 83 84 /* 85 * Set up our internal device. 86 */ 87 static void setup_device(struct sbull_dev *dev, int which) 88 { 89 /* 90 * Get some memory. 91 */ 92 memset (dev, 0, sizeof (struct sbull_dev)); 93 dev->size = nsectors * hardsect_size; 94 dev->data = vmalloc(dev->size); 95 96 97 /* 98 * The I/O queue, depending on whether we are using our own 99 * make_request function or not. 100 */ 101 switch (request_mode) { 102 case RM_NOQUEUE: 103 dev->queue = blk_alloc_queue(GFP_KERNEL); 104 blk_queue_make_request(dev->queue, sbull_make_request); 105 break; 106 107 case RM_FULL: 108 dev->queue = blk_init_queue(sbull_full_request, &dev->lock); 109 break; 110 } 111 dev->queue->queuedata = dev; 112 /* 113 * And the gendisk structure. 114 */ 115 dev->gd = alloc_disk(SBULL_MINORS); 116 dev->gd->major = sbull_major; 117 dev->gd->first_minor = which*SBULL_MINORS; 118 dev->gd->fops = &sbull_ops; 119 dev->gd->queue = dev->queue; 120 dev->gd->private_data = dev; 121 snprintf (dev->gd->disk_name, 32, "sbull%c", which + 'a'); 122 set_capacity(dev->gd, nsectors*(hardsect_size/KERNEL_SECTOR_SIZE)); 123 add_disk(dev->gd); 124 return; 125 } 126 127 static int __init sbull_init(void) 128 { 129 int i; 130 /* 131 * Get registered. 132 */ 133 sbull_major = register_blkdev(sbull_major, "sbull"); 134 /* 135 * Allocate the device array, and initialize each one. 136 */ 137 Devices = (struct sbull_dev *)kmalloc(ndevices*sizeof (struct sbull_dev), GFP_KERNEL); 138 for (i = 0; i < ndevices; i++) 139 setup_device(Devices + i, i); 140 return 0; 141 }
原文链接:
Linux块设备IO子系统(一) _驱动模型 - Abnor - 博客园 https://www.cnblogs.com/xiaojiang1025/p/6500557.html
Linux块设备IO子系统(二) _页高速缓存 - Abnor - 博客园 http://www.cnblogs.com/xiaojiang1025/p/6605776.html