https://zhuanlan.zhihu.com/p/634534308
大型语言模型(LLMs)已在自然语言处理(NLP)领域崭露头角,并在推荐系统(RS)领域近期受到了极大关注。这些模型通过自监督学习在大量数据上进行训练,已在学习通用表示上取得了显著成功,并有可能通过一些有效的迁移技术(如微调和提示调整等)来增强推荐系统的各个方面。
利用语言模型的力量来提高推荐质量的关键在于利用它们对文本特征的高质量表示以及对外部知识的广泛覆盖,以建立项目和用户之间的关联。
为了提供对现有基于LLM的推荐系统的全面理解,本综述提出了一种分类法,将这些模型分为两大范式,分别是用于推荐的判别型LLM(DLLM4Rec)和用于推荐的生成型LLM(GLLM4Rec),其中后者是首次被系统地整理出来。此外,我们在每种范式中都系统地回顾并分析了现有的基于LLM的推荐系统,提供了它们的方法、技术和性能的洞察。此外,我们也识别出了关键的挑战和一些有价值的发现,以为研究者和实践者提供灵感。
–>学术、搜广推技术、知识图谱、NLP、ML等技术交流、面试技巧与资料、解惑答疑等,移至文末加入我们

1. 引言
推荐系统在帮助用户寻找相关和个性化的项目或内容方面发挥了至关重要的作用。随着在自然语言处理(NLP)领域出现的大型语言模型(LLMs),人们对利用这些模型的能力来增强推荐系统的兴趣日益增强。
将大型语言模型(LLMs)融入推荐系统的关键优势在于,它们能够提取高质量的文本特征表示,并利用其中编码的广泛外部知识[Liu等人,2023b]。此综述将LLM视为基于Transformer的模型,这种模型参数众多,通过使用自/半监督学习技术在大规模数据集上进行训练,例如BERT,GPT系列,PaLM系列等。与传统的推荐系统不同,基于LLM的模型擅长捕获上下文信息,更有效地理解用户查询、项目描述和其他文本数据[Geng等人,2022]。通过理解上下文,基于LLM的推荐系统(RS)可以提高推荐的准确性和相关性,从而提高用户满意度。同时,面对有限的历史交互数据稀疏问题[Da’u和Salim,2020],LLMs还通过零/少样本推荐能力[Sileo等人,2022]为推荐系统带来新的可能性。这些模型可以推广到未见过的候选项,因为它们通过事实信息、领域专业知识和常识推理进行了广泛的预训练,使它们即使没有接触过特定的项目或用户,也能提供合理的推荐。
上述策略已在判别模型中得到了良好的应用。然而,随着AI学习范式的演变,生成语言模型开始受到关注[Zhao等人,2023]。这一发展的一个重要例证就是ChatGPT和其他类似模型的出现,它们已经对人类的生活和工作模式产生了重大影响。此外,将生成模型与推荐系统相结合,有可能带来更多创新和实用的应用。例如,可以提高推荐的可解释性,因为基于LLM的系统能够根据其语言生成能力提供解释[Gao等人,2023],帮助用户理解影响推荐的因素。此外,生成语言模型使得更个性化和上下文感知的推荐成为可能,例如在聊天式推荐系统中用户可以定制提示[Li等人,2023],增强用户对结果多样性的参与和满意度。
受到上述范式在解决数据稀疏性和效率问题上显著效果的启发,将语言建模范式用于推荐已经在学术界和工业界中成为了一个有前景的方向,显著地推进了推荐系统研究的最新技术。到目前为止,有一些研究回顾了这个领域的相关论文[Zeng等人,2021; Liu等人,2023b]。Zeng等人(2021)总结了一些关于推荐模型预训练的研究,并讨论了不同领域间的知识转移方法。Liu等人(2023b)提出了一种正交分类法,将现有的基于预训练语言模型的推荐系统根据它们的训练策略和目标进行划分,分析和总结了预训练语言模型基础训练范式和不同输入数据类型之间的联系。然而,这两项调查主要关注的是预训练语言模型中训练技术和策略的转移,而不是探索语言模型及其能力,即基于LLM的方式。此外,他们缺乏对推荐领域中生成大型语言模型最近进展和系统介绍的全面概览。为解决这个问题,我们深入研究了基于LLM的推荐系统,将它们分为用于推荐的判别性LLM和用于推荐的生成性LLM,我们的回顾重点放在后者上。据我们所知,我们的综述是第一个对推荐系统的生成大型语言模型进行最新和全面回顾的工作。
我们的综述主要贡献如下:
我们对当前基于LLM的推荐系统的状态进行了系统性的综述,重点是扩大语言模型的能力。通过分析现有方法,我们对相关进展和应用提供了系统的概览。
据我们所知,我们的调查是首个专门针对推荐系统的生成型大型语言模型的全面和最新的回顾。
我们的综述批判性地分析了现有方法的优点、缺点和限制。我们确定了基于LLM的推荐系统面临的关键挑战,并提出了有价值的发现,可以激发在这个有潜力的领域进一步的研究。
2 建模范式和分类法
所有大型语言模型的基本框架都由几个Transformer块组成,例如GPT,PaLM,LLaMA等。这种架构的输入通常由token嵌入或位置嵌入等组成,而在输出模块可以获得期望的输出嵌入或token。在这里,输入和输出数据类型都是文本序列。如图1的(1)-(3)所示,对于在推荐中适应语言模型,即建模范式,现有的工作可以大致分为以下三类:
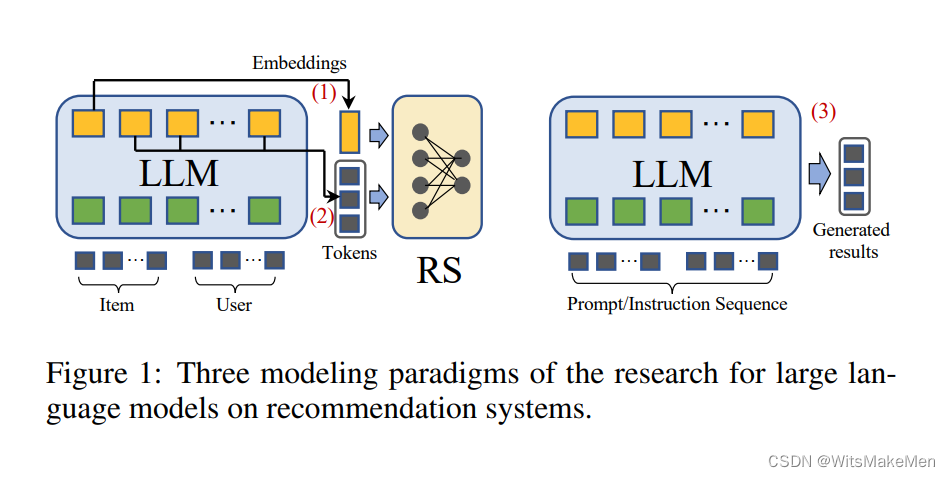
(1) LLM Embeddings + RS。这种建模范式将语言模型视为特征提取器,将物品和用户的特征输入到LLM中并输出相应的嵌入。传统的RS模型可以利用知识感知嵌入进行各种推荐任务。(2) LLM Tokens + RS。与前一种方法类似,这种方法根据输入的物品和用户的特征生成token。生成的令牌通过语义挖掘捕捉潜在的偏好,可以被整合到推荐系统的决策过程中。(3) LLM作为RS。与(1)和(2)不同,这个范式的目标是直接将预训练的LLM转换为一个强大的推荐系统。输入序列通常包括简介描述、行为提示和任务指示。输出序列预计会提供一个合理的推荐结果。
在实际应用中,语言模型的选择显著影响推荐系统中建模范式的设计。如图2所示,在本文中,我们将现有的工作划分为两个主要类别,分别是用于推荐的判别性LLM和生成性LLM。用于推荐的LLM的分类可以根据训练方式进一步细分,不同方式之间的区别在图3中有所说明。一般来说,判别性语言模型非常适合在范式(1)中嵌入,而生成性语言模型的响应生成能力进一步支持范式(2)或(3)。
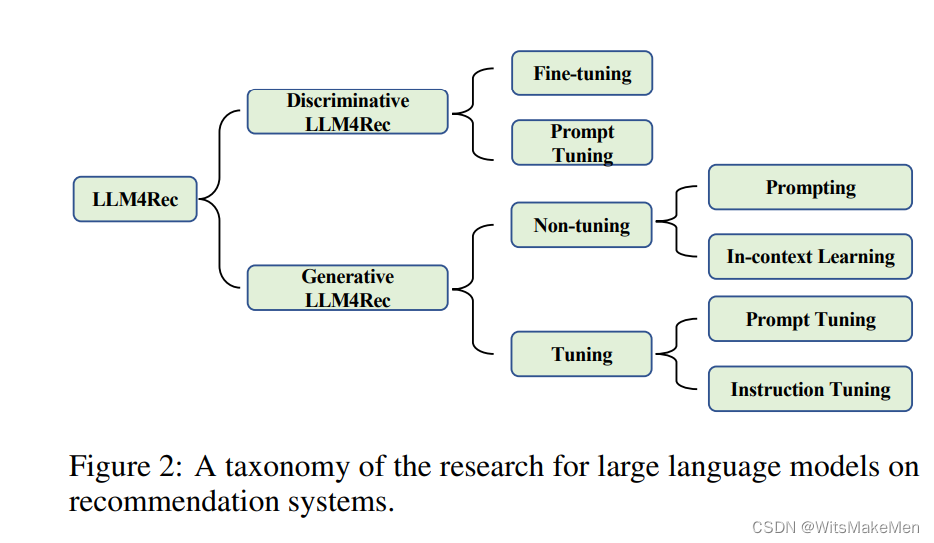
3 用于推荐的判别性LLM
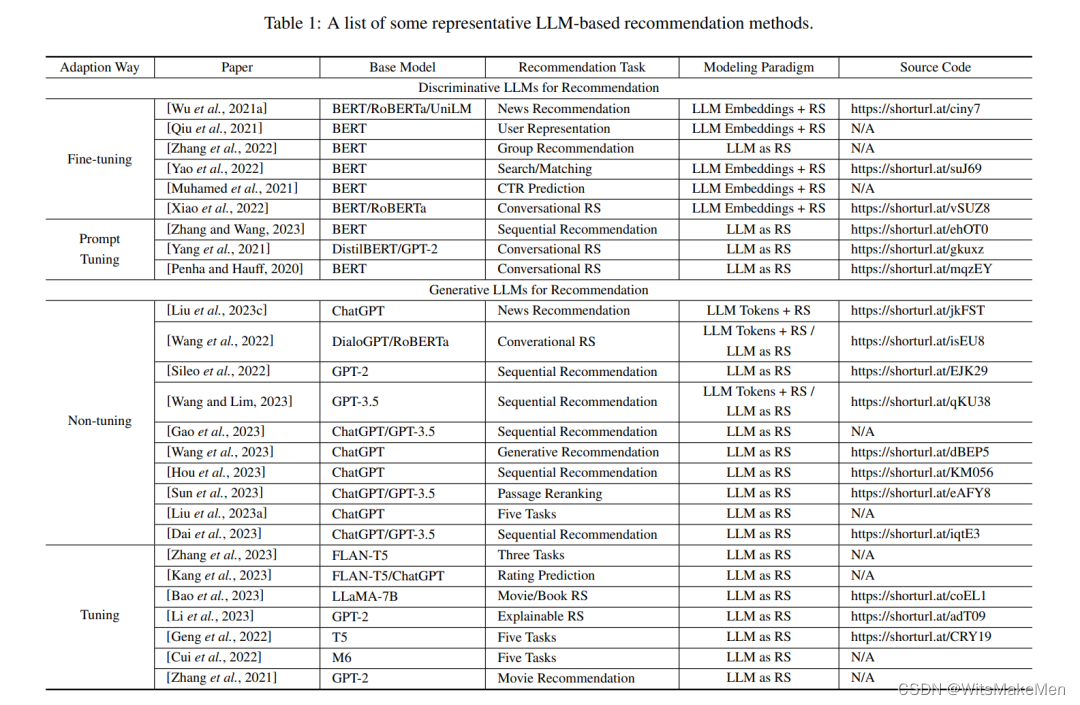
确实,所谓的在推荐领域的判别性语言模型主要是指BERT系列的模型[Devlin等人,2019]。由于判别性语言模型在自然语言理解任务中的专业性,它们通常被视为下游任务的嵌入骨干。这也适用于推荐系统。大多数现有的工作通过微调将像BERT这样的预训练模型的表现与特定领域的数据进行对齐。另外,一些研究探索了像提示调整这样的训练策略。代表性的方法和常用的数据集在表1和表2中列出。
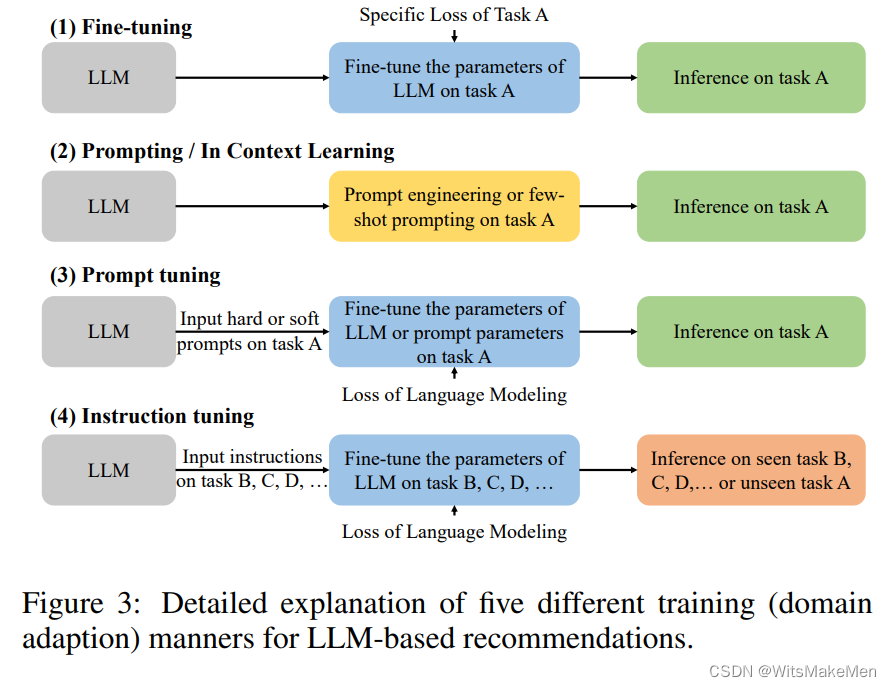
3.1 微调
微调预训练的语言模型是一种在各种自然语言处理(NLP)任务中,包括推荐系统,受到了显著关注的通用技术。微调背后的思想是,采取一个已经从大规模文本数据中学习了丰富的语言表达的语言模型,并通过在特定任务的数据上进一步训练它,使其适应特定的任务或领域。微调的过程包括用其学习到的参数初始化预训练的语言模型,然后在针对推荐的特定数据集上训练它。这个数据集通常包括用户-物品互动、物品的文本描述、用户配置文件和其他相关的上下文信息。在微调过程中,模型的参数根据特定任务的数据进行更新,使其能够适应和专门用于推荐任务。在预训练和微调阶段,学习目标可以是不同的。由于微调策略是灵活的,大多数基于BERT增强的推荐方法可以归纳到这个轨道。对于基本的表示任务,邱等人(2021)提出了一种新的基于预训练和微调的方法U-BERT来学习用户的表示,该方法利用内容丰富的领域来补充那些行为数据不足的用户特征。设计了一个评论共匹配层来捕获用户和物品评论之间的隐式语义交互。同样,在UserBERT [Wu et al., 2021b]中,加入了两个自监督任务,对未标记的行为数据进行用户模型预训练,以增强用户建模。这个模型利用中等难度的对比学习、遮蔽行为预测和行为序列匹配,通过捕捉内在的用户兴趣和相关性,训练精确的用户表示。
预训练的BERT在排名任务中取得了突破性的成就。BECR [Yang等人,2022]提出了一种轻量级的复合重新排名方案,该方案同时结合了深度上下文token交互和传统的词汇词项匹配特性。通过新颖的复合token编码,BECR有效地利用基于单字和跳字n-grams的可预计算token嵌入来逼近查询表示,从而在临时排名相关性和效率之间实现了合理的权衡。此外,Wu等人(2022)提出了一个端到端的多任务学习框架,用于产品排名,使用领域特定的BERT进行微调,以解决查询和产品之间的词汇不匹配问题。作者利用了专家混合层和任务之间的概率转移,以利用丰富的用户参与数据。还有许多其他特定任务或场景的相关研究,例如团队推荐[Zhang等人,2022],搜索/匹配[Yao等人,2022],CTR预测[Muhamed等人,2021]。特别地,"预训练,微调"机制在几个顺序或基于会话的推荐系统中起到了重要作用,如BERT4Rec [Sun等人,2019],RESETBERT4Rec [Zhao,2022]。然而,上述模型只是利用了训练策略的优势,而没有将大型语言模型扩展到推荐领域,因此不是我们讨论的重点。序列表示学习模型UniSRec [Hou等人,2022]开发了一个BERT微调框架,将项目的描述文本关联起来,在不同的推荐场景中学习可转移的表示。对于基于内容的推荐,特别是新闻推荐,NRMS [Wu等人,2021a],Tiny-NewsRec [Yu等人,2022],PREC [Liu等人,2022],利用大型语言模型通过处理已知的领域转移问题或减少转移成本来增强新闻推荐。总的来说,将BERT微调集成到推荐系统中,融合了强大的外部知识和个性化的用户偏好,主要目标是提高推荐准确性,同时获得对具有有限历史数据的新项目的一些冷启动处理能力。
3.2 提示调优
与设计特定目标函数来适应不同的下游推荐任务不同,提示调优 [Lester等人,2021]试图通过硬/软提示和标签词语 verbalizer,将推荐的调优对象与预训练的损失对齐。例如,Penha和Hauff (2020)利用BERT的Masked Language Modeling (MLM)头来通过cloze-style提示揭示其对项目类型的理解。他们进一步利用了BERT的Next Sentence Prediction (NSP)头和表示的相似性 (SIM) 来比较相关和不相关的搜索和推荐查询-文档输入。实验表明,BERT在没有任何微调的情况下,可以在排名过程中优先考虑相关项目。Yang等人 (2021)开发了一个带有提示的对话推荐系统,其中一个基于BERT的项目编码器直接将每个项目的元数据映射到一个嵌入中。最近,Prompt4NR [Zhang和Wang, 2023]率先应用了提示学习范式进行新闻推荐。这个框架重新定义了预测用户点击候选新闻的目标,作为一个cloze-style的 maskprediction任务。实验发现,通过利用多提示集成,推荐系统的性能显著提高,超过了在离散和连续模板上使用单一提示所达到的结果。这突出了提示集成在结合多个提示做出更明智决策方面的有效性。
4 针对推荐的生成型LLMs
相比于判别型模型,生成型模型具有更好的自然语言生成能力。因此,不像大多数基于判别模型的方法将LLMs学习到的表示与推荐领域对齐,大多数基于生成模型的工作将推荐任务翻译为自然语言任务,然后应用像在上下文中学习,提示调优,和指导调优这样的技术,来适应LLMs直接生成推荐结果。此外,随着ChatGPT展示出的令人印象深刻的能力,这类工作近来受到了更多的关注。如图2所示,根据是否调整参数,这些基于生成型LLM的方法可以进一步划分为两种范例:无调优范例和调优范例。以下两个小节将分别讨论它们的细节。代表性的方法和常用的数据集也在表1和表2中列出。
4.1 无调整范式
LLMs在许多未见任务中展示出强大的零/少量样本学习能力 [Brown et al., 2020; Ouyang et al., 2022]。因此,一些最近的研究假设LLMs已经具有推荐能力,并试图通过引入特定的提示来触发这些能力。他们采用了最近的Instruction和In-Context Learning [Brown et al., 2020]实践,以在不调整模型参数的情况下将LLMs适应推荐任务。根据提示是否包含示例,这个范式中的研究主要属于以下两类:提示和上下文学习。
提示范例 这类工作旨在设计更适合的指示和提示,帮助LLMs更好地理解和解决推荐任务。Liu等人(2023a)系统地评估了ChatGPT在五个常见推荐任务上的表现,即评分预测,序列推荐,直接推荐,解释生成和评论摘要。他们提出了一个通用的推荐提示构建框架,包括:(1)任务描述,将推荐任务适应为自然语言处理任务;(2)行为注入,将用户-项目交互纳入,帮助LLMs捕获用户的喜好和需求;(3)格式指示器,约束输出格式,使推荐结果更容易理解和评估。同样,Dai等人(2023)对ChatGPT在三个常见信息检索任务(包括点对点,对对,和列表排序)上的推荐能力进行了实证分析。他们为不同类型的任务提出了不同的提示,并在提示的开头引入了角色指示(例如,你现在是一个新闻推荐系统。)来增强ChatGPT的领域适应能力。除了提出一般框架外,有些工作专注于为特定推荐任务设计有效的提示。Sileo等人(2022)从GPT-2的预训练语料库中挖掘出了电影推荐提示。Hou等人(2023)介绍了两种提升LLMs序列推荐能力的提示方法:以近期为重的序列提示,使LLMs能够感知到用户交互历史中的序列信息,和引导法,将候选项目列表多次洗牌并取平均得分进行排名,以缓解位置偏见问题。由于LLMs允许的输入token数量有限,很难在提示中输入一个长的候选列表。为解决这个问题,Sun等人(2023)提出了一种滑动窗口提示策略,每次只在窗口中对候选项进行排序,然后以从后到前的顺序滑动窗口,最后重复这个过程多次,以获得总体排名结果。
除了将LLMs作为推荐系统,一些研究还利用LLMs来构建模型特征。GENRE [Liu等人,2023c]引入了三个提示,使用LLMs进行新闻推荐的三个特征增强子任务。具体来说,它使用ChatGPT根据摘要优化新闻标题,从用户阅读历史中提取关键词,并生成合成新闻以丰富用户的历史交互。通过整合LLMs构建的这些特征,传统的新闻推荐模型可以得到显著改善。类似地,NIR [Wang和Lim,2023]设计了两个提示来生成用户偏好关键词,并从用户交互历史中提取代表性电影,以改进电影推荐。
在实践中,除了排序模型外,整个推荐系统通常由多个重要组件组成,如内容数据库、候选检索模型等。因此,另一种利用LLMs进行推荐的方法是将它们作为整个系统的控制器。ChatREC [Gao et al., 2023]围绕ChatGPT设计了一个交互式推荐框架,该框架通过多轮对话理解用户需求,并调用现有推荐系统提供结果。此外,ChatGPT可以控制数据库检索相关内容以补充提示,并解决冷启动项目问题。GeneRec [Wang et al., 2023]提出了一种生成性推荐框架,并使用LLMs控制何时推荐现有项目或通过AIGC模型生成新项目。总的来说,这些研究利用自然语言提示激活LLM在推荐任务中的零样本学习能力,提供了一种低成本且实用的解决方案。
4.2 调整范式
如上所述,LLMs具有强大的zero/few-shot能力,通过适当的提示设计,它们在推荐性能方面可以显著超越随机猜测。然而,仅以这种方式构建的推荐系统往往无法超越专门针对特定任务和特定数据训练的推荐模型的性能。因此,许多研究人员通过进一步的微调或提示学习来增强LLMs的推荐能力。在本文中,我们按照[Wei等,2022]的分类,将调整方法的范式划分为两种不同类型,分别是提示调整和指令调整。具体而言,在提示调整范式下,LLMs的参数或软提示针对特定任务进行微调,例如评分预测;而在指令调整范式下,LLMs通过在不同类型的指令下对多个任务进行微调来获得更好的性能。然而,目前对于这两种微调范式还没有明确的划分或普遍接受的定义。
5 发现
在本综述中,我们系统地回顾了大型语言模型在推荐系统中的应用范式和适应策略,特别是针对生成式语言模型。我们已经确定了它们在特定任务中改进传统推荐模型性能的潜力。然而,需要注意的是,这个领域的整体探索仍处于早期阶段。研究人员可能会发现确定最值得研究的问题和痛点是具有挑战性的。为了解决这个问题,我们总结了许多大规模模型推荐研究中提出的共同发现。这些发现突出了一些技术挑战,并呈现了进一步发展的潜在机会,包括模型偏见、提示设计和评估。
6 结论
本文回顾了大型语言模型(LLMs)在推荐系统领域的研究。我们将现有的工作分为判别模型和生成模型,并通过领域适应方式对其进行了详细阐述。为了防止概念混淆,我们对LLM-based推荐中的微调、提示、提示调整和指令调整进行了定义和区分。据我们所知,我们的调查是专门针对生成式LLMs在推荐系统中的首次系统且最新的综述,进一步总结了许多相关研究中提出的共同发现和挑战。因此,本调查为研究人员提供了宝贵的资源,帮助他们全面了解LLM推荐,并探索潜在的研究方向。
技术交流群
论文探讨、算法交流、求职内推、干货分享、解惑答疑,与10000+来自港大、北大、腾讯、科大讯飞、阿里等开发者互动学习。
想要技术交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向+学校/公司+知乎,即可。然后就可以拉你进群了。
强烈推荐大家关注 @沪漂城哥知乎账号,可以快速了解到最新优质文章。
精选文章
快手提出基于双兴趣分解头注意序列的推荐模型!
推荐系统何去何从,经典ID范式要被颠覆?
一文详解搜广推 CTR 建模
推荐收藏!京东广告精排百分位AUC提升技术方案
快手提出基于双兴趣分解头注意序列的推荐模型!
快手:基于强化学习的多任务推荐框架 RMTL
快手新研究:将因果关系估计引入推荐系统、提升推荐模型效果!
多序列融合召回在淘宝新用户冷启动上的应用
干货分享!图神经网络在快手推荐召回中的应用和挑战
干货分享!图神经网络在快手推荐召回中的应用和挑战
小米电商推荐算法秘籍:新模型如何快速热启动?
值得收藏!腾讯搜索词推荐算法探索实践
干货 | PID算法在广告成本控制领域的应用
干货推荐 | 携程酒店推荐模型优化
腾讯音乐:全民K歌直播推荐系统详解
阿里妈妈搜索广告CTR模型的“瘦身”之路
如何改进双塔模型,更好的提升算法效果?
淘宝直播全屏页重排算法实践
推荐收藏!推荐系统技术发展综述
一种全新的点击率建模方案
京东推荐算法精排技术实践
美团搜索粗排优化的探索与实践
【NLP+图神经网络+推荐领域】最值得收藏的经典综述性文章汇总!
召回技术在内容推荐的实践总结
冷启动系统优化与内容潜力预估实践
微博推荐实时大模型的技术演进
深度粗排在天猫新品中的实践
快手精排模型实践
交互式推荐算法在美团外卖场景的探索与应用
小红书高时效推荐系统背后的技术升级
百亿数据个性化推荐:弹幕工程架构演进
推荐收藏!算法岗最频繁考察的200道面试题汇总!
多场景多任务学习在美团到店餐饮推荐的实践
深度盘点:2W+字详解推荐系统算法!
深度盘点:3W+字详解排序算法!
ZEUS:淘宝多场景推荐排序模型
面经分享| 学长的算法岗面试总结
万字长文!我的校招算法岗面经总结!
用通俗易懂的方式讲解:NLP 这样学习才是正确路线
保姆级教程,用PyTorch和BERT进行文本分类
保姆级教程,用PyTorch和BERT进行命名实体识别
一网打尽:14种预训练语言模型大汇总
盘点一下 Pretrain-Finetune(预训练+精调)四种类型的创新招式!
NLP中的数据增强方法!
总结!语义信息检索中的预训练模型
深度梳理:实体关系抽取任务方法及SOTA模型总结!
【NLP】实体关系抽取综述及相关顶会论文介绍
【深度总结】推荐算法中的这些特征工程技巧必须掌握!
12篇顶会论文,深度学习时间序列预测经典方案汇总
一文梳理推荐系统中的特征交互排序模型