PyTorch入门教学——加载数据(Dataloader)
企业开发
2023-12-17 20:24:09
阅读次数: 0
1、简介
- PyTorch中如何读取数据主要涉及到两个类,分别为Dataset和Dataloader。
- Dataset:创建可被Pytorch使用的数据集
- Dataloader:向模型传递数据
- 本文主要讲解Dataloader的使用方法。
2、Dataloader
2.1、查看使用方法
2.2、应用
- 使用Dataloader前,需要将图片转化为totensor格式。下面直接使用torchvision.datasets的数据集。
- 新建一个python文件。
-
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备测试数据集
test_data = torchvision.datasets.CIFAR10(
root="./Dataset/CIFAR10",
transform=torchvision.transforms.ToTensor(), # 将图片转换为totensor数据类型
train=False,
download=True)
# root:数据集下载后存放的目录。
# train:如果为True,则从训练集创建数据集,否则从测试集创建。
# transform:接收PIL图像的转换方式,并返回转换后的版本。
# download:如果为True,则从互联网下载数据集,然后将其放在设置的目录中。如果数据集已下载,则不会再次下载。
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, drop_last=False)
# batch_size:每次取到数据集的大小。
# shuffle:每次迭代数据集是否打乱。
# drop_last:将最后不足batch_size的部分舍去。
write = SummaryWriter("logs") # 使用TensorBoard显示图片
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
write.add_images("Epoch:{}".format(epoch), imgs, step)
step = 1 + step
write.close()
- 运行结果:

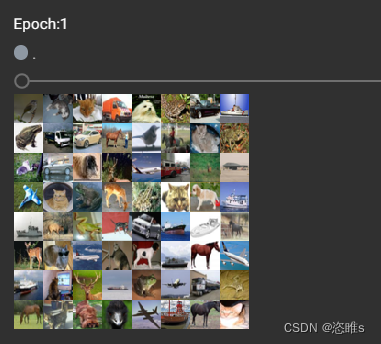
- batch_size=64,所以每次取得数据集为64张图片。
- shuffle=True,所以两次迭代得到的图片顺序是不同的。
- drop_last=False,所以最后剩下的数据集不会被舍去。
 (最后只有16张图片,不足64)
(最后只有16张图片,不足64)
- 上述案例中,使用DataLoader转换的test_loader得到的imgs可以直接供神经网络使用,即实现向模型传递数据。
转载自blog.csdn.net/weixin_45100742/article/details/134719733