文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 pytorch教程 也可获取。
文章目录
数据读取机制Dataloader与Dataset

数据分为四个模块

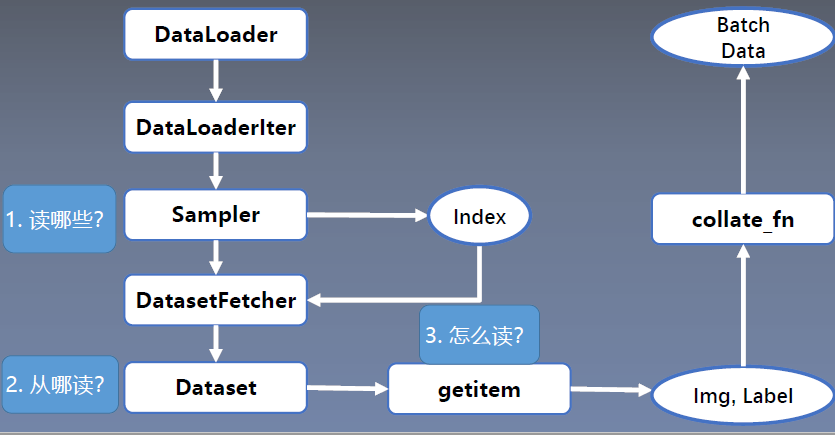
Sampler:生成索引
DataSet:根据索引读取图片及标签。
DataLoader 与 Dataset
torch.utils.data.DataLoader

功能:构建可迭代的数据装载器
- dataset : Dataset 类,决定数据从哪读取
及如何读取 - batchsize : 批大小
- num_works : 是否多进程读取数据(减少时间,加速模型训练)
- shuffle:每个 epoch 是否乱序
- drop_last :当样本数不能被 batchsize 整除时,是否舍弃最后一批数据
区分Epoch、Iteration、Batchsize
Epoch: 所有训练样本都已输入到模型中,称为一个 Epoch
Iteration:一批样本输入到模型中,称之为一个 Iteration
Batchsize:批大小,决定一个 Epoch 有多少个 Iteration
样本总数: 80 Batchsize 8
1 Epoch = 10 Iteration
样本总数: 87 Batchsize 8
1 Epoch = 10 Iteration?drop_last = True
1 Epoch = 11 Iteration?drop_last = False
torch.utils.data.Dataset

功能:
Dataset 抽象类,所有自定义的Dataset 需要继承它,并且复写_getitem_()
getitem:接收一个索引,返回一个样本
关于读取数据

通过debug详解数据的读取过程
DataLoader根据是否采用多进程,进入DataLoaderIter,使用Sampler获取index,再通过索引调用DatasetFetcher,在硬盘中读取imgandLabel,通过collate_fn整理成一个batchData。