龙猫之死?(Chinchilla’s Death)
前言
主要内容
- 在训练开始时,较小的模型比更大的模型训练地更快;一段时间之后,小模型训练速度放慢,并被更大的模型超越;当训练损失进入线性下降阶段时,较小的模型更陡峭地下降到高级知识,并且它们再次超越了较大的模型!(LLaMA1的7B和13B给出的现象。LLaMA2整个都存在这种现象 );
- 如果将训练大模型所花费的计算花在小模型上,小模型可能会达到更低的困惑度;
原文链接:(https://espadrine.github.io/blog/posts/chinchilla-s-death.html)
正文
较小的模型具有较少的乘法。因此他们跑得更快。因此他们训练得更快。然而,理论上讲,他们最终会达到知识能力的极限,之后的学习速度会减慢,而具有更大容量的更大模型的学习能力将超越他们,并在给定的训练时间内达到更好的表现。
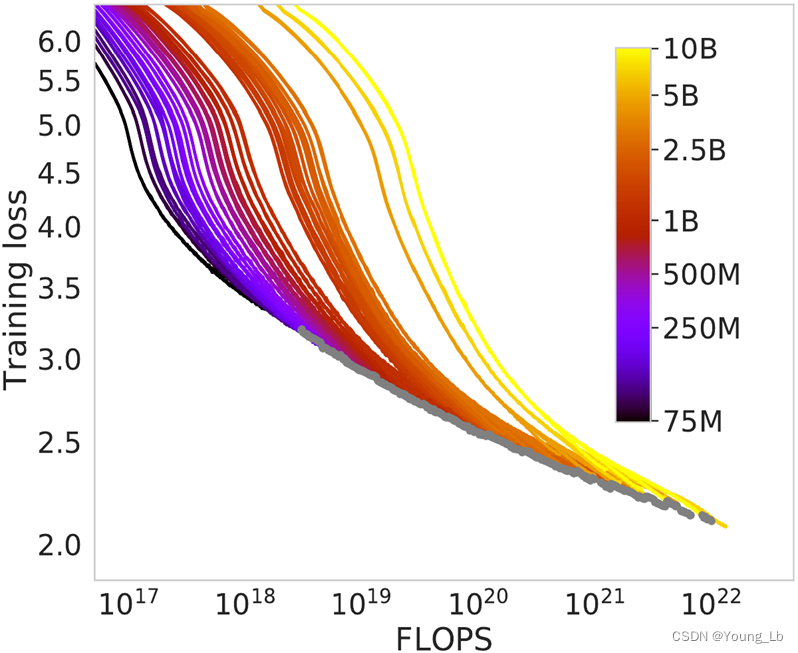
在 Chinchilla 工作中,图 2 显示了不同尺寸模型的大量训练运行的训练损失。乍一看,这些曲线遵循理论:较小的模型最初具有较低的损失(好),但最终它会减慢速度,并被较大模型的曲线所超越(坏)。(在那张图表中,每当他们指出较小的模型开始输给较大的模型时,他们就会画上灰点。灰线,即帕累托边界,是他们计算比例定律的方式。)
这种假设的问题在于,我们不知道如果让较小的模型训练更长时间会发生什么,因为它们一被超越就停止了训练。
LLAMA
今年早些时候,Meta 训练了四个不同大小的模型。与其他作品不同的是,他们对每个人的训练时间都非常长;即使是较小的。
他们公布了训练运行曲线:
- 每条曲线首先按照幂律直线下降,
- 然后似乎进入了损失的近线性下降(对应于相当恒定的知识获取率)。
- 在曲线的最顶端,它们都通过稍微变平来打破这条线 。*
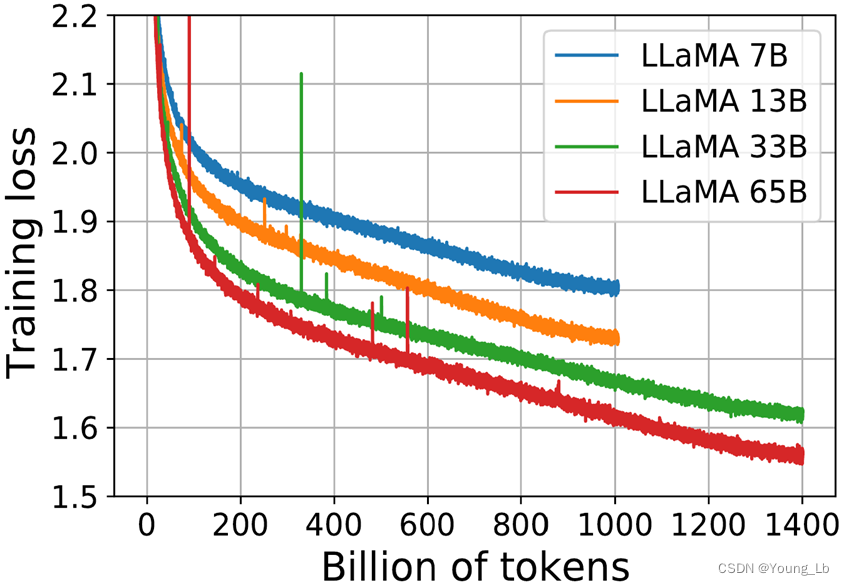
首先,我想解决人们可能对曲线末端平坦化产生的一个微妙的误解。它们都使用可变学习率(粗略地说,是一个超参数,表示沿梯度方向前进的程度)进行梯度下降训练。为了获得良好的训练,他们必须不断降低学习率,以便它能够检测源材料中更加微妙的模式。他们用于减少的公式是最广泛使用的:余弦时间表。
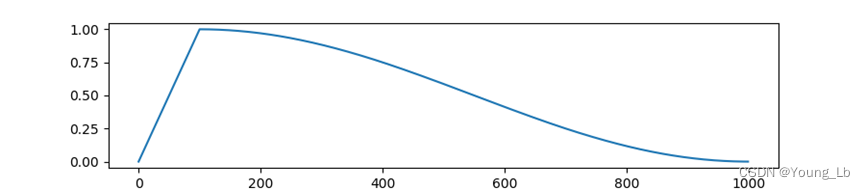
从图中可以看出,在训练运行结束时,余弦计划停止以产生如此良好的、接近线性的训练损失曲线的速度降低学习率。学习速度减慢就是这种情况造成的(也就是说模型最终loss不下降了不是因为模型学习结束了,而是学习率太小了)。该模型不一定不再具有以相同的近线性速率学习的能力!事实上,如果我们有更多的文本给它,我们就会延长余弦时间表,因此它的学习率会继续以相同的速度下降。
模型的适应度并不取决于我们可以为其训练提供的数据量;因此学习率降低的变化是不合理的。
但这不是本文的重点。
训练损失曲线可能会以另一种方式产生误导。当然,他们都接受过相同数据的训练;但他们不会以相同的速度处理这些数据。我们想知道的不是模型的样本效率如何(在这方面,较大的模型显然可以从它所看到的内容中学到更多)。让我们想象一场比赛:所有这些模型同时开始,我们想知道哪个模型首先冲过终点线。换句话说,当在训练中投入固定的计算量时,谁在这段时间内学到最多?
模型画一条直线垂直X轴会发现,训练相同的时间时,小模型的效果要优于大模型的效果,表明小模型学的更快,大模型最终效果更好只是因为他们花费了更多的计算资源。
值得庆幸的是,我们可以将损失曲线与 Meta 提供的另一条数据结合起来:每个模型训练所花费的时间。
模型 GPU-------------小时数-----------令牌/秒
LLaMA1-7B-----------82432----------3384.3
LLaMA1-13B---------135168---------2063.9
LLaMA1-33B---------530432--------730.5
LLaMA1-65B--------1022362---------379.0
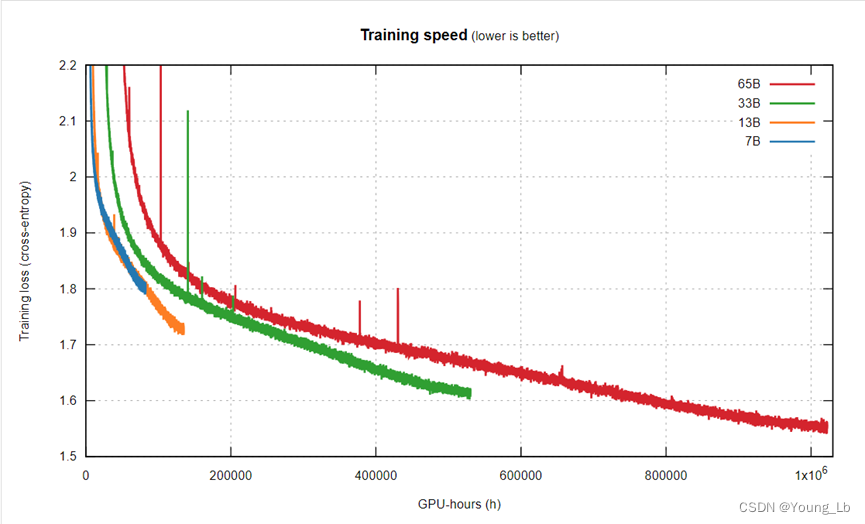
这个图应该是相同的数据训练三个不一样大小的模型
首先我们要提到的是,我们看到的整个 Chinchilla 图只覆盖了该图左侧的一小部分。在该条中,我们看到了 Chinchilla 记录的相同行为。例如,看看 7B(在 Chinchilla 图中,它实际上是尺寸最大的两条曲线之一):它最初比较大模型更快地降低损失,然后减慢速度,13B 模型超过它,首先达到1.9。
但随后,出现了一个意想不到的转折:7B 进入近线性状态,呈急剧下降趋势,并且似乎可能会再次超越 13B?很难从该图中看出如果 7B 训练更长时间会发生什么。
然而,13B 和 33B 之间似乎也存在同样的行为,最初的 Chinchilla 减速也让位于近线性状态,此时 13B 快速下降!它只是被 33B 不公平地超越,因为后者的计算时间增加了一倍多。
同样的先减速后加速的情况发生在 33B 和 65B 之间,以至于 33B 实际上从未被 65B 超越。该图显示的内容打破了 OpenAI 和 Chinchilla 的假设: 更大的模型尚未获胜。他们检测到的减速实际上并不是由于达到某些容量限制而引起的!
不过,7B线还是有点不尽如人意。如果 Meta 能训练它更长时间就好了……
LLaMA 2
悬念结束:他们做到了!他们本周发布了 LLaMA 2!
是时候证实我们的怀疑了
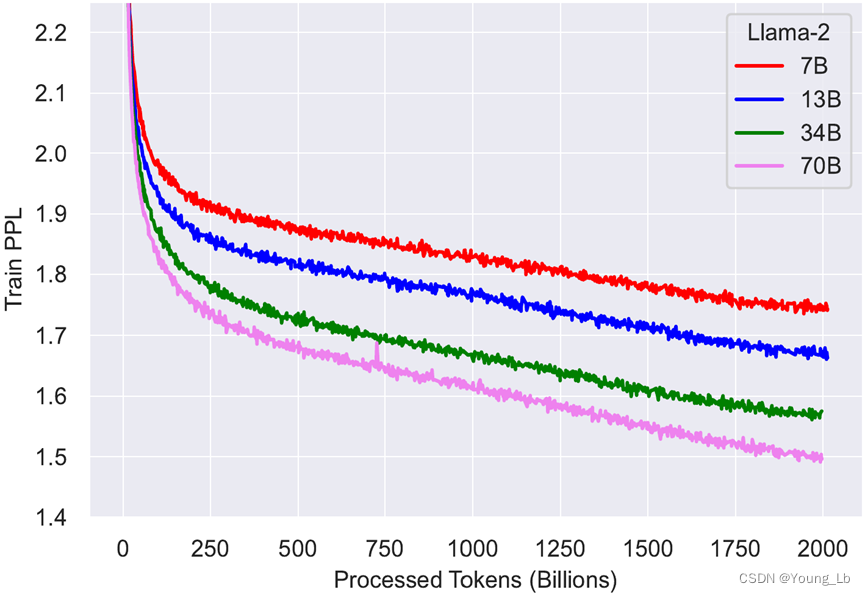
我们还再次获得了训练时间:
模型-------------------GPU 小时数------------------令牌/秒
LLaMA2-7B---------184320-------------------------3031.9
LLaMA2-13B--------368640------------------------1515.9
LLaMA2-34B--------1038336----------------------533.7
LLaMA2-70B--------1720320----------------------322.1
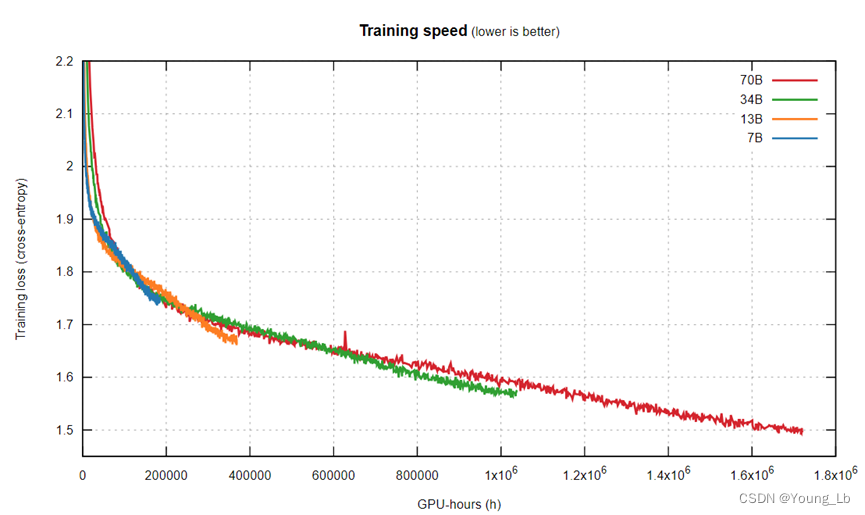
这个图应该是相同的数据训练三个不一样大小的模型(线性阶段的斜率远远降低了)
我们一眼就注意到训练曲线与 LLaMA 1 的训练曲线不匹配,即使模型相同。事实证明,LLaMA 2 是在双倍上下文大小和更长的余弦时间表上进行训练的,不幸的是,这对所有模型大小产生了负面影响。然而,较小的模型比较大的模型受到的影响更严重。结果,34B 模型在 LLaMA 1 中在任何训练时间内都始终优于 65B 模型,现在略高于 70B 模型,然后才超越它:
更重要的是,比较训练速度强烈证实了我们对 LLaMA 1 的怀疑:
1. 首先,较小的模型比更大的模型训练地更快,
2. 然后,它们放慢速度,并被更大的模型超越(根据龙猫),
3. 但随后,它们进入了近线性状态,其中较小的模型更陡峭地下降到高级知识,并且它们再次超越了较大的模型!(LLaMA1的7B和13B给出的现象。LLaMA2整个都存在这种现象 )。
一个令人着迷的结果与开始训练时做出正确的选择有关:与普遍的看法相反,较大的模型会产生更差的结果。如果您必须选择参数大小和数据集,那么您最好选择 7B 模型并在数万亿个代币上进行 7 个 epoch 的训练。
看看 7B 模型的近线性状态,并将其线推断到 70B 模型停止时:如果 70B 计算花在 7B 上,它可能会达到更低的困惑度!
我们从 LLaMA 2 中注意到的另一件事是,LLaMA 1 曲线末尾的学习减速确实是余弦时间表的人为因素。(为什么这么说?因为llama2中同样大小的模型在更多的数据上训练的loss更小,而按照道理llama1的模型学的数据更少,他应该对这部分数据拟合的更好趋近于过拟合,loss应该小宇llama2的,但实际情况却是相反的,也就是说llama1的模型并没有学完,而是因为其他因素导致最后loss区域平缓。)在 LLaMA 2 训练运行中,在读取 1 万亿个令牌的相应标记上完全不存在这种放缓。
事实上,也许在同一时刻,LLaMA 2 7B 模型的质量比 LLaMA 1 7B 模型差,可能是因为它的余弦时间表被拉长了!
让我们回到 Chinchilla 论文来论证这一点。在附录 A 的图 A1 中,他们展示了对各种余弦调度参数的消融研究(换句话说:拉伸学习率曲线的各种方法)。
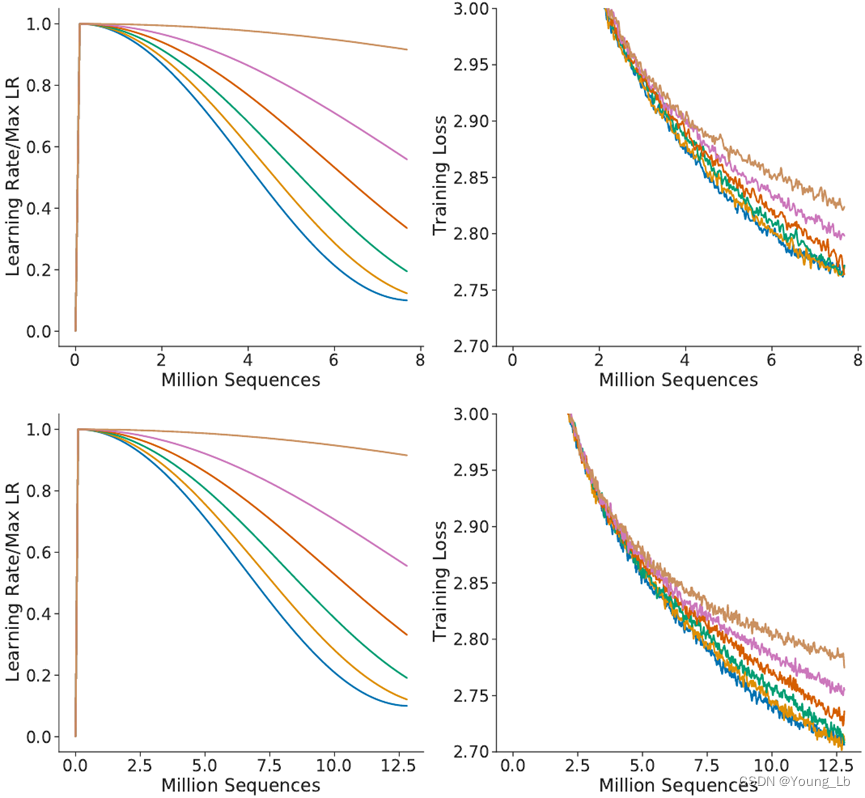
他们指出,当曲线不拉伸时,损失最低。图表支持了这一点,但我们注意到一些不对劲的地方。读取 600 万个 token 后,由上图中模型的训练损失低于 2.8;同时,在相同的标记下,右下图中模型的训练损失大于2.8。(由于llama1和llama2的训练数据量不同,所以可能是因为上面那个600W个token可能是300W个token看了两遍,而下面这个是600W个不同的token看了一遍,所以在开始的时候llama1学的更好)。然而,模型之间的唯一区别是余弦时间表!由于底部模型预计要经过更多训练数据,因此计算了更多步骤的“未拉伸”余弦计划,从而有效地对其进行了拉伸。如果学习率遵循分配给较少训练步骤的时间表,那么在相同的训练时间内,它会有更好的损失。
更广泛地说,这提出了一个我未解决的问题:如果余弦时间表不是最佳的,那么它的尾部形状应该如何
总结
- 在训练开始时,较小的模型比更大的模型训练地更快;一段时间之后,小模型训练速度放慢,并被更大的模型超越;当训练损失进入线性下降阶段时,较小的模型更陡峭地下降到高级知识,并且它们再次超越了较大的模型!(LLaMA1的7B和13B给出的现象。LLaMA2整个都存在这种现象 );
- 如果将训练大模型所花费的计算花在小模型上,小模型可能会达到更低的困惑度;