EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
本文提出的StreamLLM是注意力计算的一种改进,同时选择了注意力窗口和注意力池来计算attention,并且在计算过程中不适用原输入序列中的绝对位置,而是注意力池和注意力窗口拼接后的相对位置,作者验证在这些改进下,模型可以生成高质量且无限长的文本序列。
本文主要创新点:
1、对注意力机制进行改进,提出了attention sink,将初始位置几个token和附近的几个token拼接为当前位置解码,提升了解码速度;
2、初始位置的attention sink可以添加专门的、可训练的token,而不是原输入语句的前几个字符;
3、拼接后的attention token不使用元输入序列中的position,而是使用拼接之后的position,可以大大增加文本生成的长度;
前言
在流式应用程序中部署大型语言模型(llm),如多轮对话,在这些应用程序中需要长时间的交互,这是迫切需要的,但存在两个主要挑战。
1、在解码阶段,缓存先前token的key和value会消耗大量的内存;
2、流行的LLM不能推广到比训练序列长度更长的文本(如:在训练时定义的最大输出长度为4096,则推理阶段生成的文本长度也不会超过4096);
一、自注意力
自注意力机制是Transformer架构中机器重要的组成部分,但是其计算的时间和空间复杂度的与序列长度L的平方有关系。所以在计算过程中会消耗大量的计算资源和内存资源。所以降低自注意力的计算复杂度可以大大降低模型在训练和推理时的速度,主要的优化方案包括稀疏近似、低秩近似等方法。
图1、注意力矩阵

图1(a)为传统的注意力矩阵,占用较多的计算资源和内存空间。通过对一些训练好多的Transformer模型中的注意力矩阵分析发现,其中很多矩阵式稀疏的,因此可以通过限制Q-K对的数量来减少计算的复杂度,这类方案统称为稀疏注意力方案,主要有窗口注意力图1(b)、全局注意力图2(a)、膨胀注意力图2(b)、随机注意力图2(c)、局部块注意力图2(d)及其组合。
图2、稀疏注意力
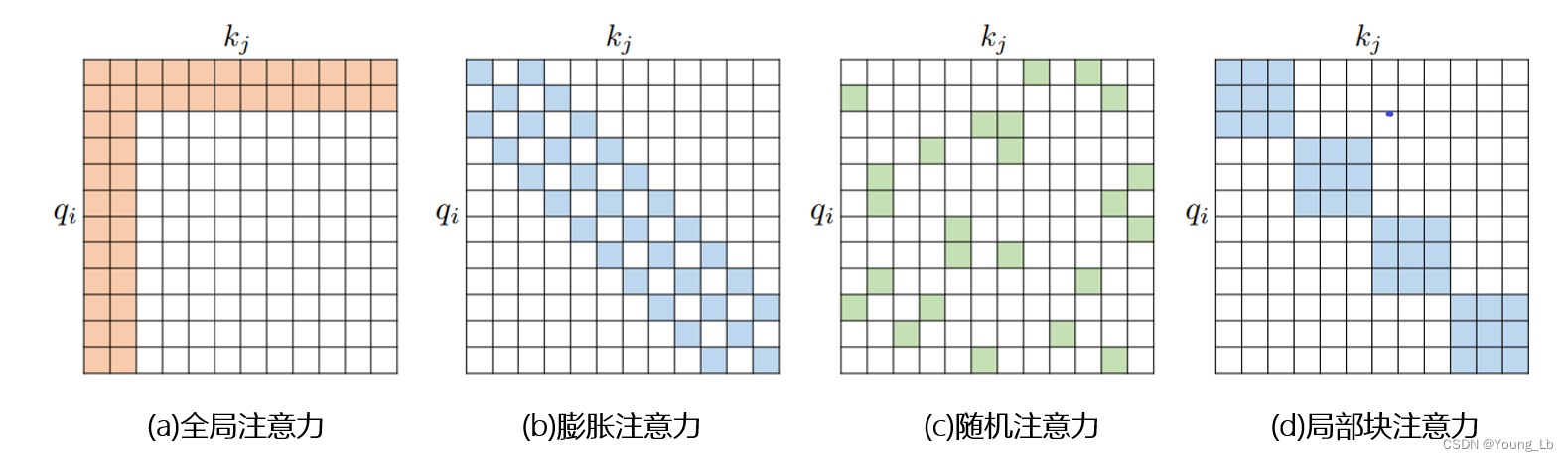
图1(c)中,每次在解码时要对前几个token重新计算注意力embedding,通过增加计算量连少内存占用。图1(d)为本文方案,将输入序列最前端的几个token与窗口内token拼接后计算注意力对当前的位置进行解码。
那么为什么可以进行这样的操作呢?这样处理会不会降低文本生成的质量?
作者对训练完成之后的注意力矩阵进行可视化展示,如图3所示:
图3、注意力可视化
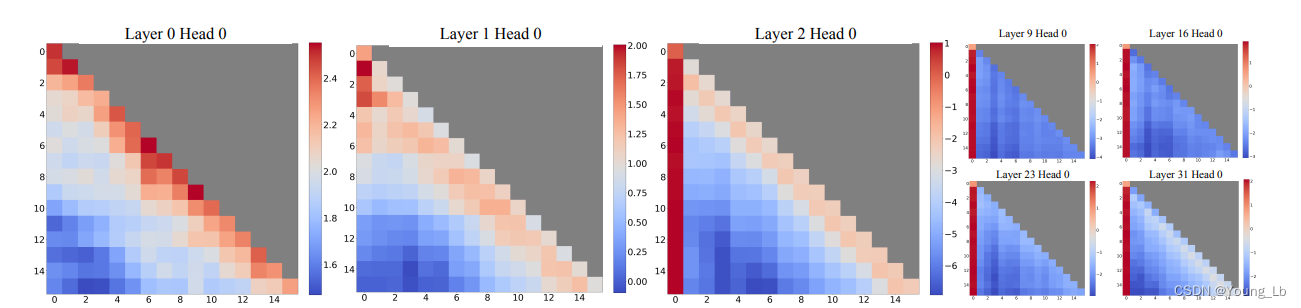
图中可以发现,从第三层开始,初始token在解码任何一个位置token的时候都占据了较大的注意力权重。而其他位置的token所占用的注意力权重远低于初始位置,所以将只使用初始位置和窗口内token对当前位置进行解码不会造成严重的信息丢失。
那又为什么第一个初始token在所有位置token解码的时候都占据很大的注意力权重呢?
很多人解释是在解码一个token时,可能会存在注意力过剩的情况,(就是之前解码完成的token与当前待解码的token注意力都很小,但是多余的注意力总得分配掉,所以就将剩余的注意力分配给了初始位置的token。相当于是个槽,不要的都给它。)
(个人认为从数学角度也可以做出一定解释):因为第一个token出现的时间最早,在所有的token解码时,他都会产生影响,所以他会对整个句子中任何一个token的解码都有很强的指导作用。
假设输入序列的所有字符占据同样的权重,那么:
解码第一个token时,第一个token所占权重为1;
解码第二个token时,第一个token所占权重为0.5, 第二个token所占权重为0.5;
解码第三个token时,第一个token所占权重为0.333+0.333/2, 第二个token所占权重为0.333/2, 第三个token所占权重为0.333;
……以此类推,在解码任何一个token时,第一个字符所占据的权重都是最高的;
二、解码长度扩展
传统的基于Transformer架构的模型在训练时,会固定输入长度和输出长度的大小,如4096。那么在推理阶段时,最大的生成长度也为4096(因为超过训练时定义的序列长度时,如4097,就没有对应的4097的position embedding来继续往后解码了)。后来也出现了一些方案来对上下文窗口进行扩展,如位置插值,使用相对位置编码取代绝对位置编码等,来对已经解码的序列进行注意力计算,但是也都存在上限。
本文主要关注的是处理无限长度的文本生成,所以本文对token的编码方式进行了调整,如下图:
图4、StreamLLM得到位置编码
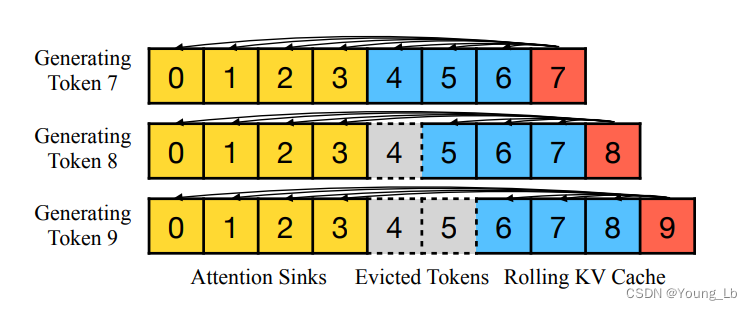
本文作者选取序列初始的几个token作为attention sink与窗口内的token拼接作为注意力计算的区域。传统的位置embedding往往选择这些token在原始输入序列中的位置进行计算。
如attention sink选择初始的4个token,窗口选择当前位置前面的四个token。
在解码前八个token时,使用的就是之前的所有token,所以对应的position就是1、2、3、4、5、6、7;
解码第九个token时是使用前八个token,所以对应的position就是1、2、3、4、5、6、7、8;
解码第十个token时是使用1-4和6-9这八个token,但是position并不是1、2、3、4、6、7、8、9,而依然是1、2、3、4、5、6、7、8;
以这样的方式对输入语句进行编码就不会存在position embedding超出预训练时定义的范围了,就可以无限生成后续文本。
三、实验
图5、attention sink的大小
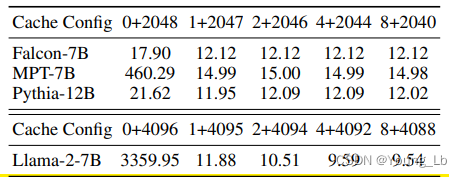

文中探究了attention sink的大小对解码质量的影响,对size=0、1、2、4、8分别进行了测试。当size=0时生成的文本的困惑度很高,当加入一个字符时,困惑度达到量级提升,适当增加大小还可以进一步降低。文中选择了size=4,我认为时继续增加size的大小,对困惑度的提升很小,反而会带来更多的计算量。
除了探究attention sink的size之外,还对这四个token的内容进行了探究,发现即使将最初的4个token 换成四个"\n",依然会有相同的效果。
图6、可学习的attention sink
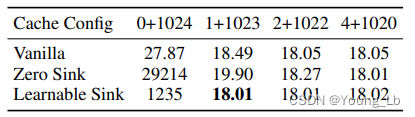
在后续实验中,作者将attention sink中的token改成了可学习的token插入到输入序列的起始位置,对比可学习的attention sink和未学习的attention sink进行对比,结果中展示二者效果相差不多。
一句话总结就是:不管是什么样的attention sink,只要有就行。
总结
本文设计了一种注意力计算方案,并且对位置编码进行了调整,可以让大模型解码无限长的序列。