CPU缓存一致性原理
在本站的文章CPU缓存那些事儿中, 介绍了cpu的多级缓存的架构和cpu缓存行cache line的结构。CPU对于缓存的操作包含读和写,读操作在cache line中有所涉及,在本文中,将重点讨论CPU对于缓存进行写时的行为。
单核CPU对高速缓存的读操作
CPU对于高速缓存的读操作的过程在之前的文章中有提到过,这里梳理一下其流程:
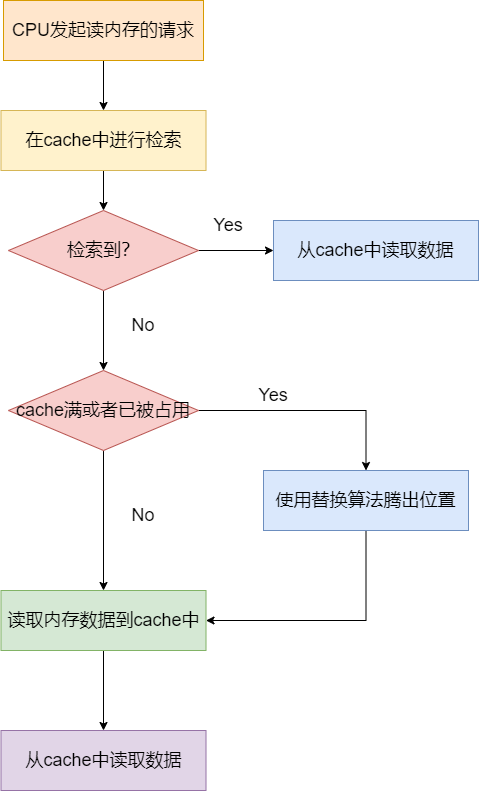
- 1.首先对于一个内存地址,CPU会按照索引规则(直接映射/多路组相连/全相连)优先去cache line中进行检索。
- 2.如果检索到了,意味着该内存地址的内容已经存在于cache中,则直接读取内容到CPU中,流程结束。如果没有检索到,进行步骤3。
- 3.此时确认内存的数据不在cache line中,如果cache已经存满或者已经被其他内存地址映射,则进入步骤4,如果cache line中还有空位,则进入步骤5.
- 4.执行缓存淘汰策略,腾出位置
- 5.加载内存数据到cache line中,将cache块上的内容读取到cpu中。
对于单核CPU, 对cache的读操作的流程如下所示:
单核CPU对于高速缓存的写操作
CPU对于高速缓存的写操作比读操作要复杂一些,写操作会修改cache中的数据,而这一数据最终需要同步到内存中,在同步到内存这个点上,写操作的策略可以分为写直达策略和写回策略。注意这里的讨论仍然是针对单核CPU而言的。
写直达策略(Write-Through)
写直达策略的思想是对于写入操作,同时修改cache中的数据和内存中的数据,使得cache和内存中的数据保持一致。这将使得cache和内存拥有数据的强一致性。
写直达策略中写数据的流程可以被细化为下列的步骤:
- 1.判断待写入的数据是否已经存在于cache中。如写入的数据已经存在于cache中,则跳转到步骤2,否则跳转到步骤3。
- 2.将数据写入cache中。
- 3.将数据写入内存。
而写直达策略中读数据的流程并没有任何改变,因为cache和内存的数据是强一致的。
写直达策略的流程概括为如下所示:
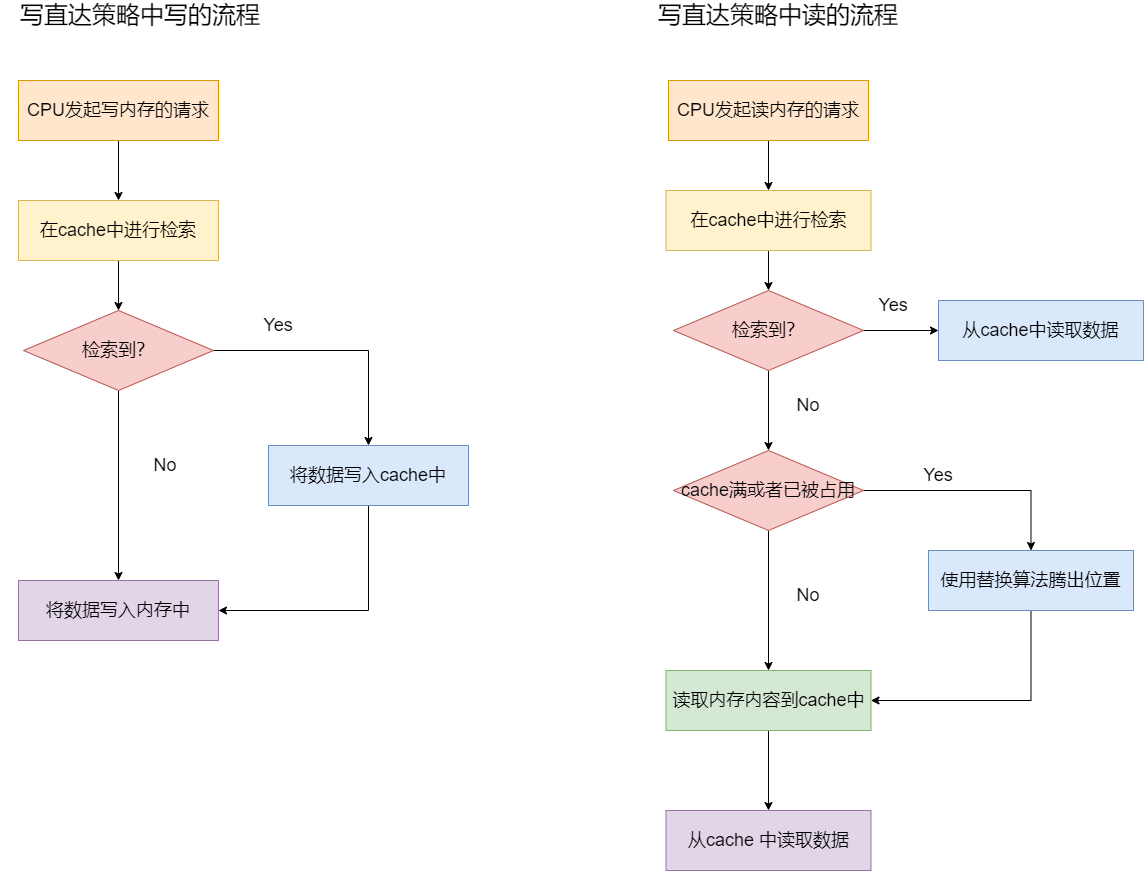
对于写直达策略,读cache的流程并没有任何改变,这一点和写回策略是有区别的。
写直达的优缺点如下:
优点:对于写操作而言,可以保证内存和高速缓存内容的强一致性。
缺点:由于每次写入操作都需要将数据写入内存,使得写操作的耗时增加,失去了高速缓存的高效性。
写回策略(Write-Back)
写直达策略的思想是当需要修改cache时,延迟修改内存。在每个cache line上增加了Dirty的标记,当修改了cache中的内容时,会将Dirty标记置位,表明它的数据和内存数据不一致。注意此时,并不会立即写回内存。只有当cache块被替换出去时,才会回写到内存中。这其实是一种异步的思想,其相较于写直达也要复杂一些。写回策略实现的是一种最终一致性。
写回策略是由读和写配合完成的。
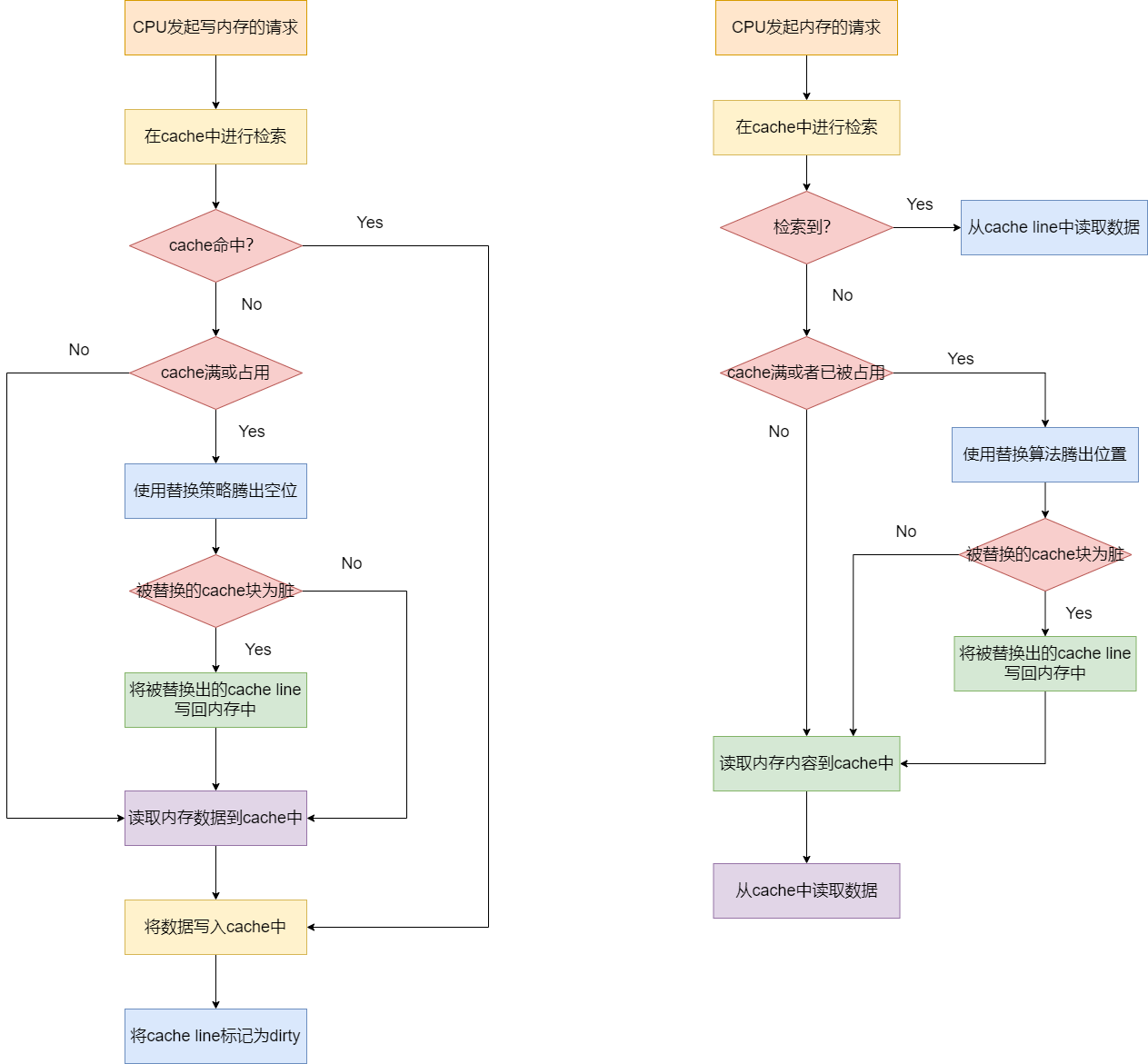
对于写回策略中的写操作,其流程如下:
- 1.首先判断写操作的地址是否存在于cache中,如存在,进入步骤6,否则进入步骤2。
- 2.如果写操作的地址不在cache中,则尝试读取内存数据到cache中。这里需要判断cache此时是否已经满或者被占用。如果已经满或者被占用,则进入步骤3,否则进入步骤5。
- 3.如果cache此时是否已经满或者被占用,则使用替换策略挪出空位。此时还需要判断被替换出的cache line是否为脏数据,如果是脏数据,则进入步骤4,否则进入步骤5
- 4.将被替换出的cache line的数据写回内存中。
- 5.读取内存块的数据到cache line中。
- 6.将数据写入cache中
- 7.将cache line标记为脏数据。
由于替换策略也可能发生在读操作中,因此对于写回策略中的读操作也发生了修改,其流程如下所示:
- 1.首先对于一个内存地址,CPU会按照索引规则(直接映射/多路组相连/全相连)优先去cache line中进行检索。
- 2.如果检索到了,意味着该内存地址的内容已经存在于cache中,则直接读取内容到CPU中,流程结束。如果没有检索到,进行步骤3。
- 3.此时确认内存的数据不在cache line中,如果cache已经存满或者已经被其他内存地址映射,则进入步骤4,如果cache line中还有空位,则进入步骤6.
- 4.执行缓存淘汰策略,腾出位置,此时需要判断被替换出的cache line是否为脏数据,如果是,则进入步骤5,否则进入步骤6.
- 5.将脏数据写回到内存中。
- 6.加载内存数据到cache line中,将cache块上的内容读取到cpu中。
写回策略的读写操作的流程如下所示:
多CPU核的缓存一致性问题。
上面的写直达策略和写回策略可以解决单核CPU的cache和内存的一致性问题。而现代的CPU往往都是多核CPU,每个核心都拥有其自己的cache。那么对于写操作而言,除了保证本CPU的cache和内存的一致性,还需要保证其它CPU的cache和内存的一致性问题。
MESI协议就是用来解决这个问题的。
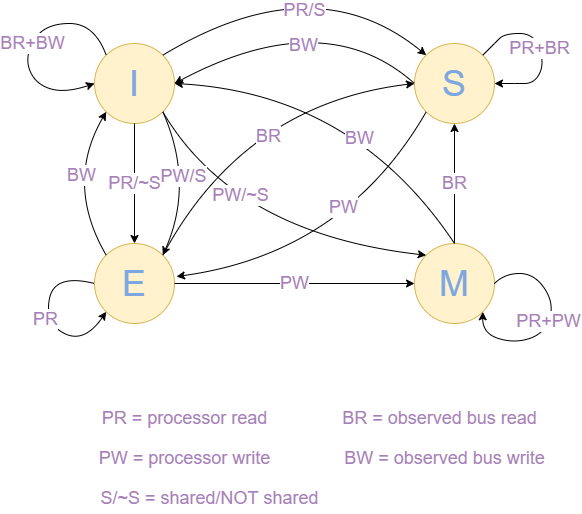
MESI协议是一种用于保证缓存一致性的协议,其对应了CPU cache的四种状态,每个字母代表了一种状态,其含义如下:
- M(Modified,已修改): 表明 Cache 块被修改过,但未同步回内存;
- E(Exclusive,独占): 表明 Cache 块被当前核心独占,而其它核心的同一个 Cache 块会失效;
- S(Shared,共享): 表明 Cache 块被多个核心持有且都是有效的;
- I(Invalidated,已失效): 表明 Cache 块的数据是过时的。
MESI 协议其实是 CPU Cache 的有限状态机,其四种状态的转化如下图所示:
对于MESI协议,有一个可视化的网站可以演示其过程,网址:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm。
下面我们借助该网站来理解MESI每个状态的变换过程。
独占状态E转已修改状态M E->M
如下图所示,此时cpu0上有a0的缓存,a0的缓存状态是独占状态E。
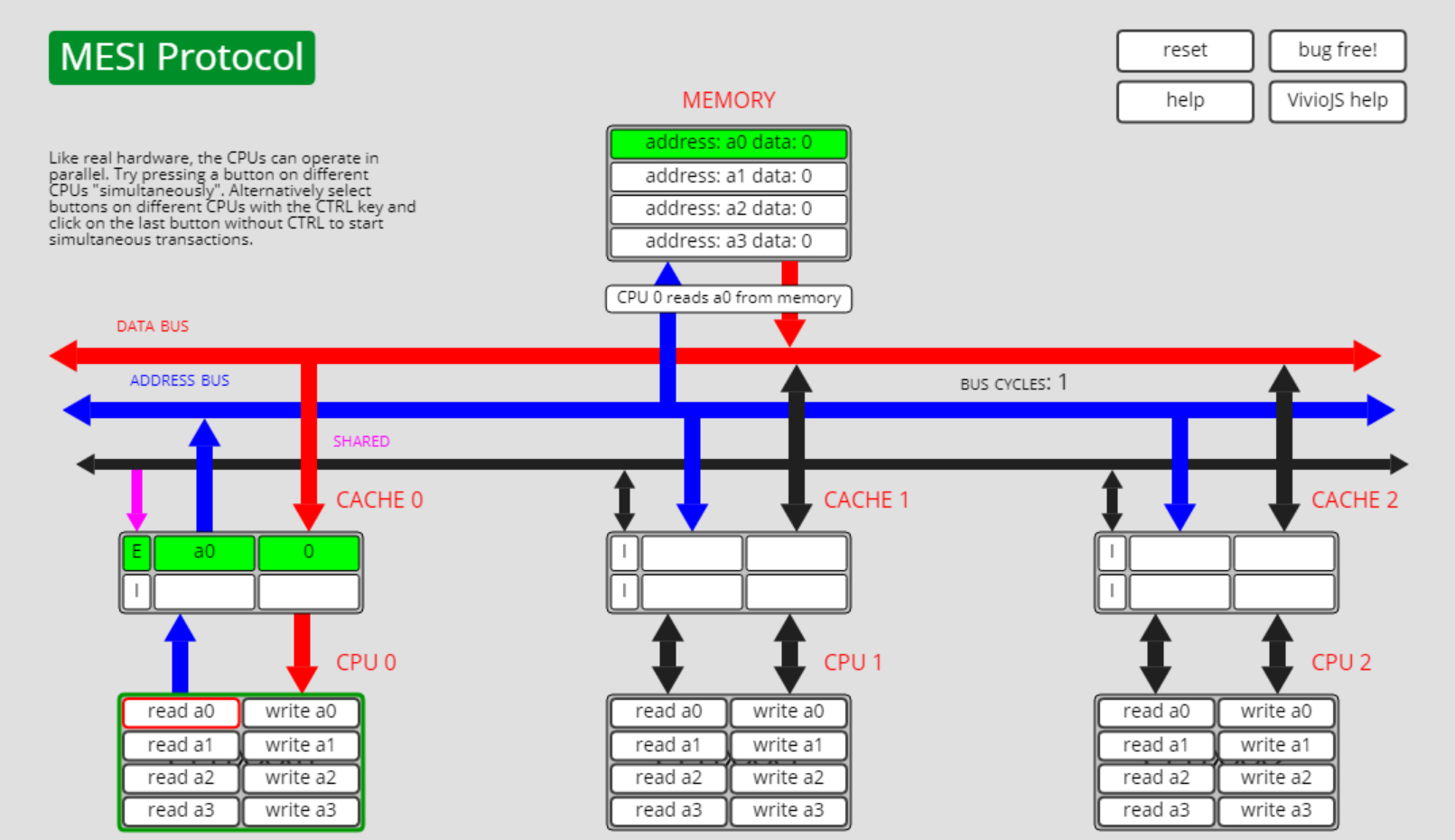
此时cpu0执行write a0操作,由于其它cpu上没有a0数据,状态E转为状态M:
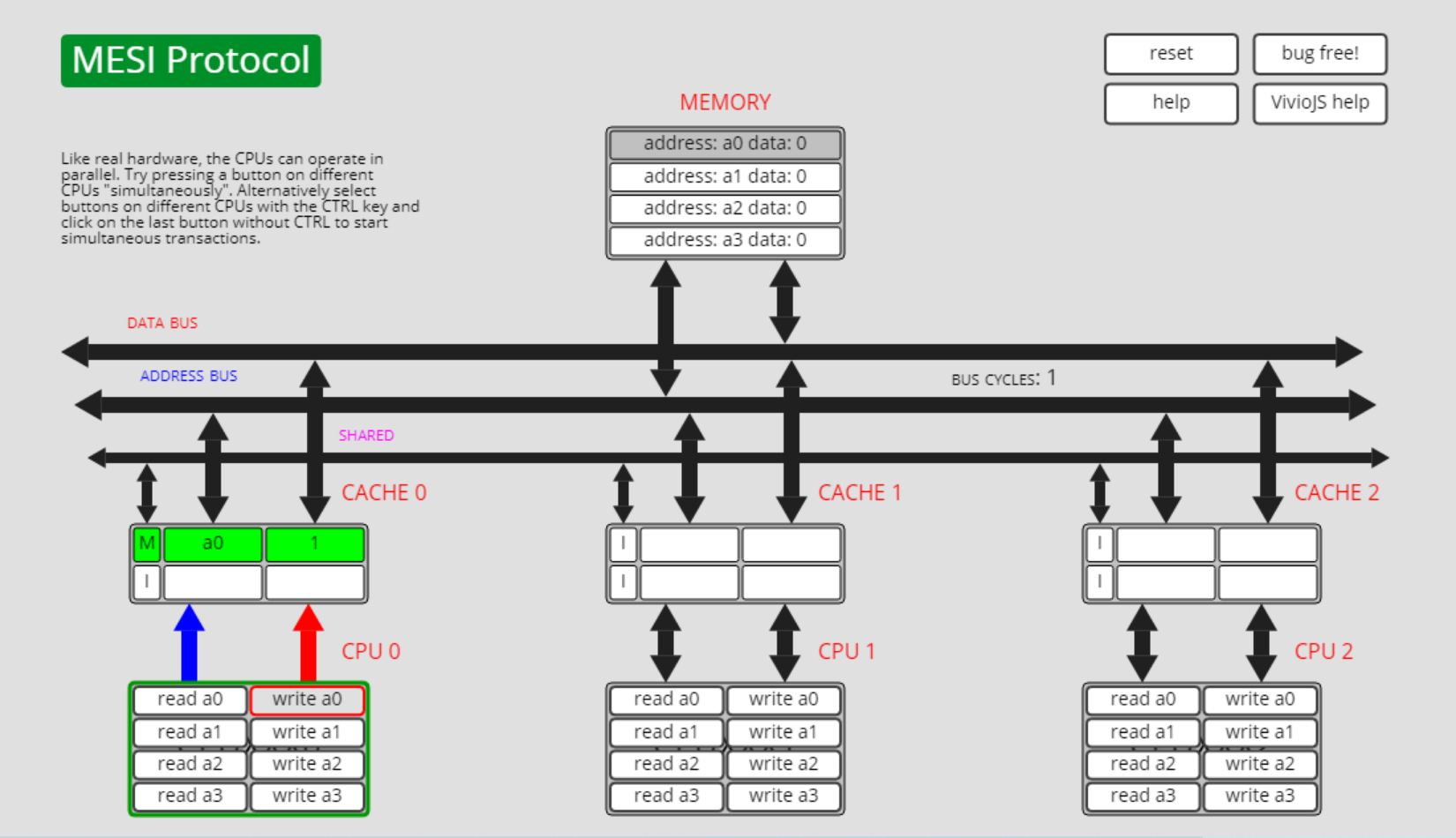
已修改状态M转共享状态S,M->S
如下图所示,此时cpu0上有a0的缓存,a0的缓存状态是已修改状态M:
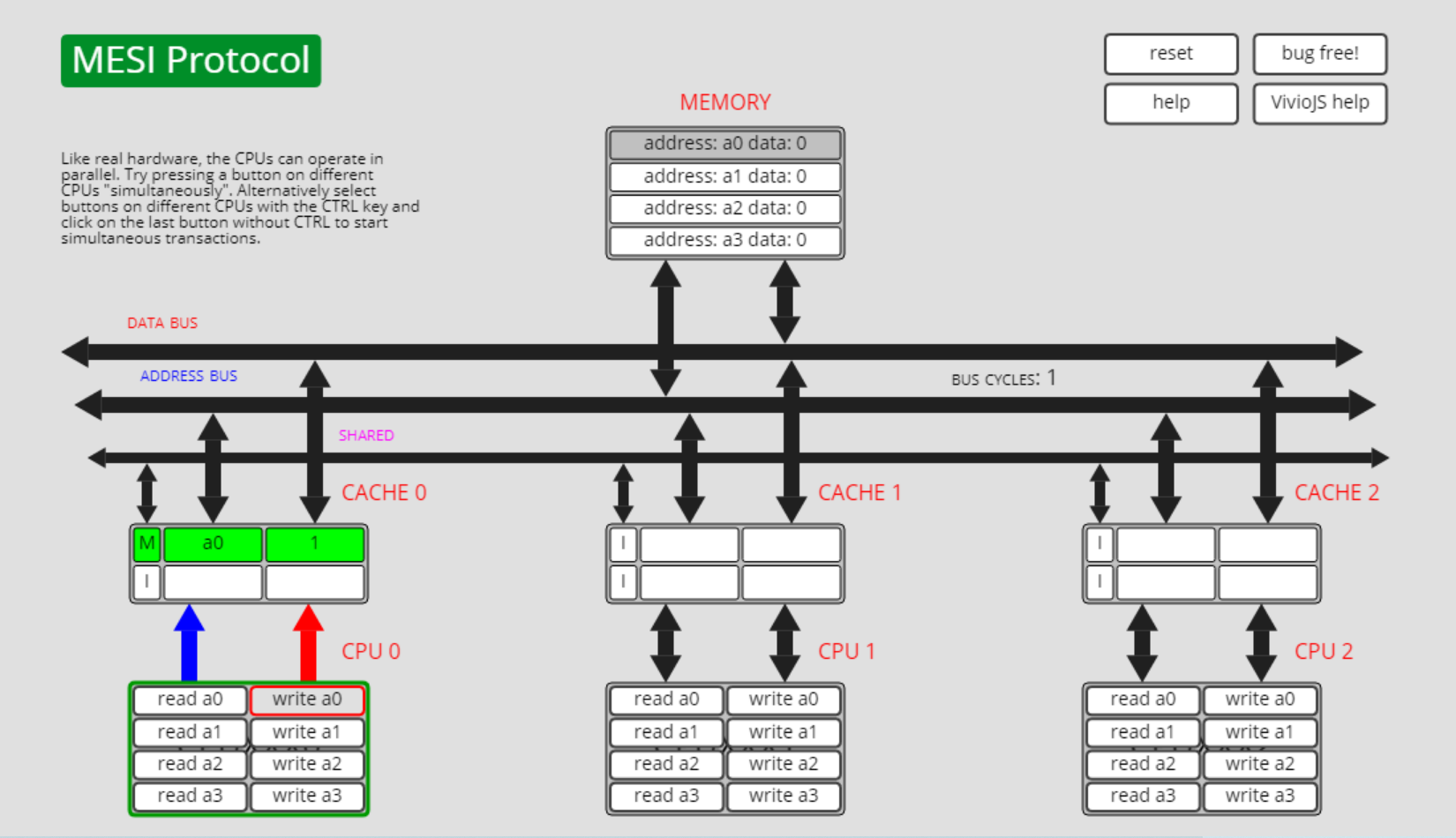
随后cpu1上执行read a0的操作,则cpu 0上的a0从状态M转为状态S:
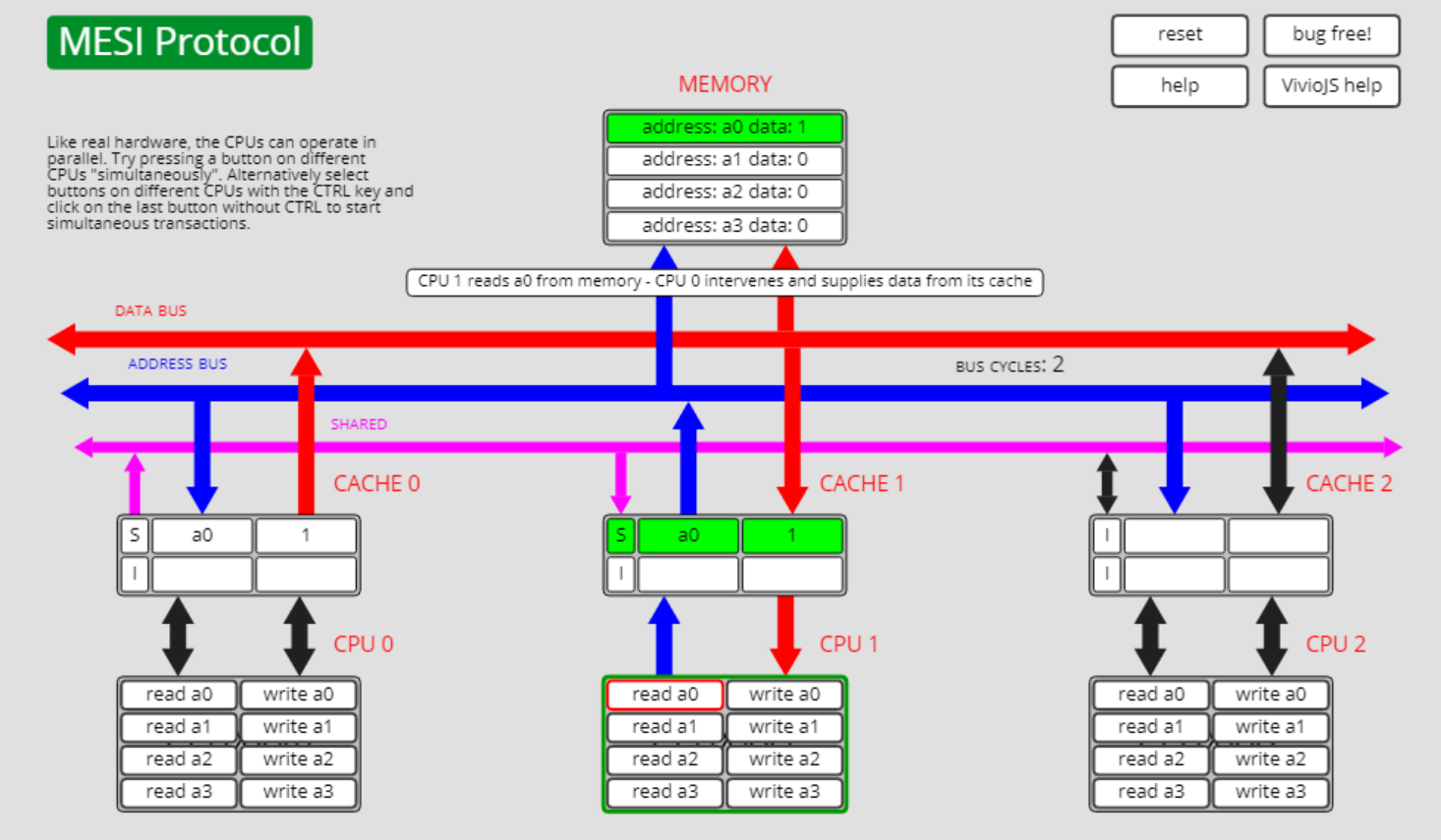
共享状态S转已失效状态I, S->I
如下图所示,此时cpu0上有a0的缓存,其状态为S。除此以外,cpu1上也有a0的缓存。
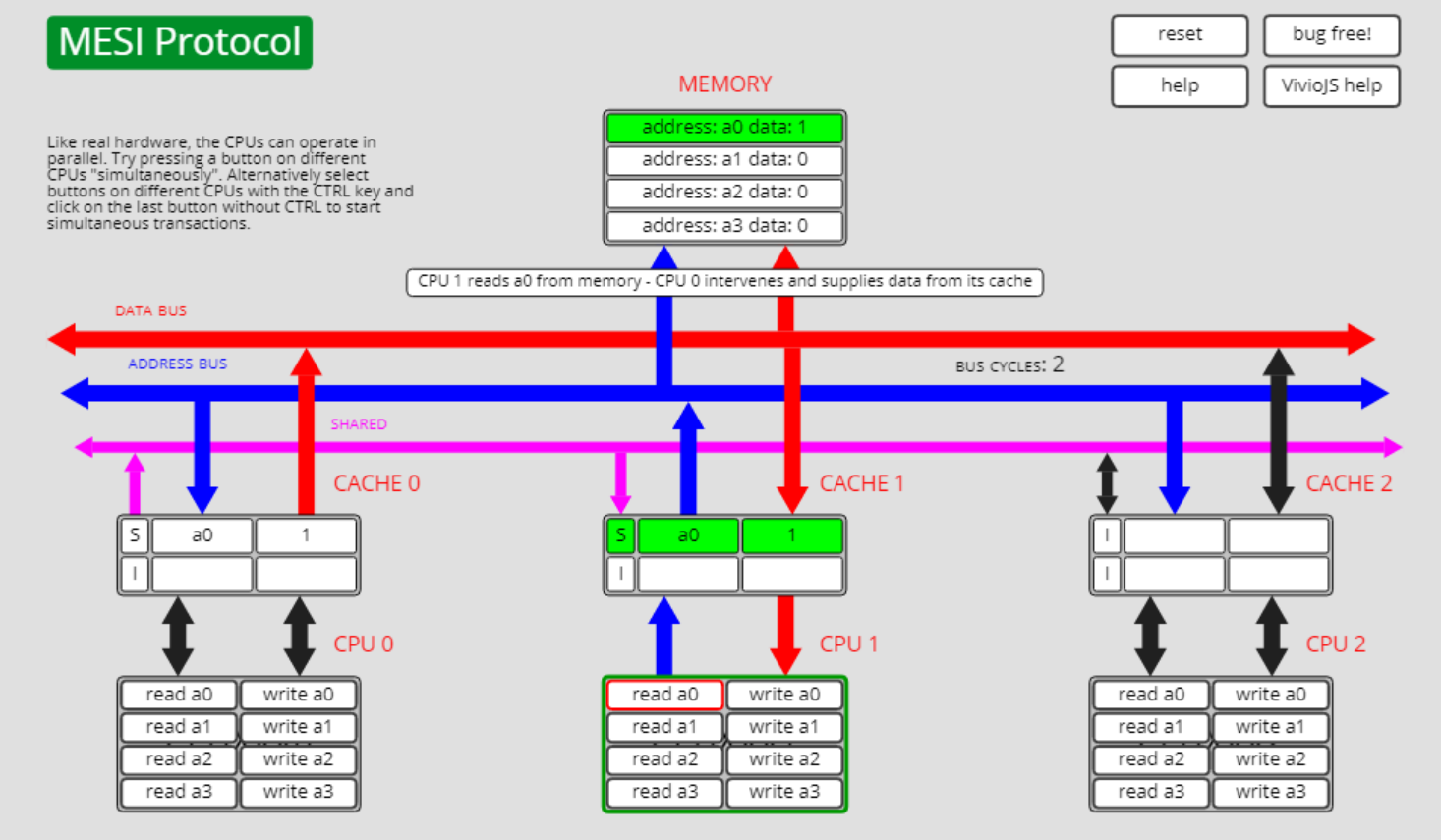
此时cpu1上执行write a0的操作,则cpu0上的a0状态从S转为了I:

共享状态S转独占状态E, S->E
如下图所示,此时cpu0上有a0的缓存,其状态为S。除此以外,cpu1上也有a0的缓存。
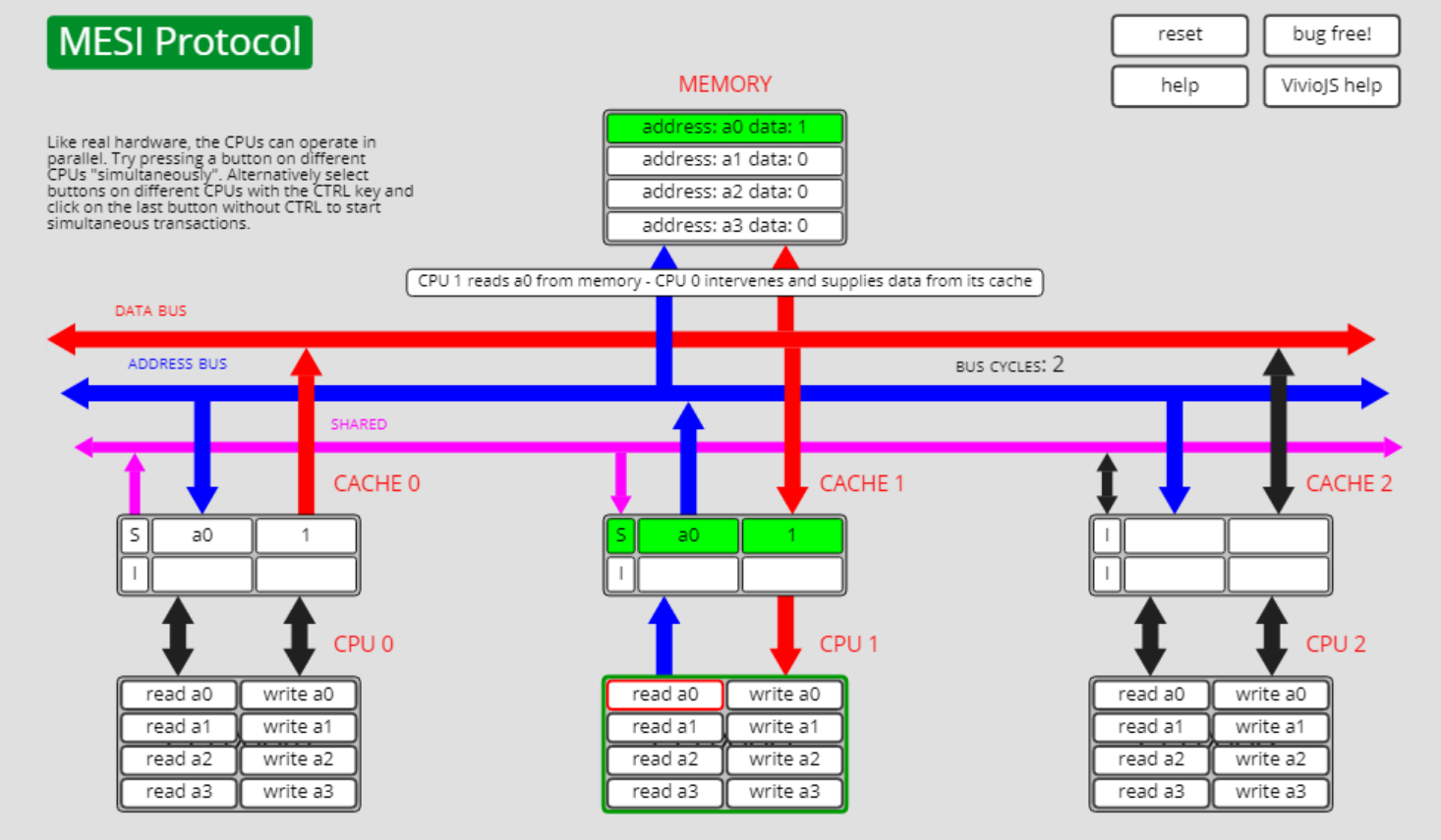
此时cpu1上执行write a0的操作,则cpu1上的a0状态从S转为了E:
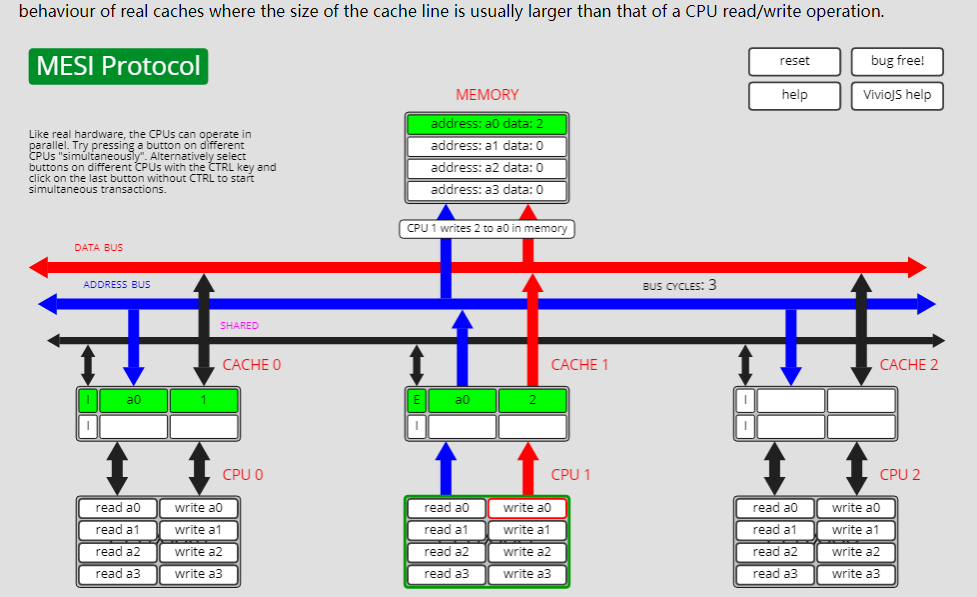
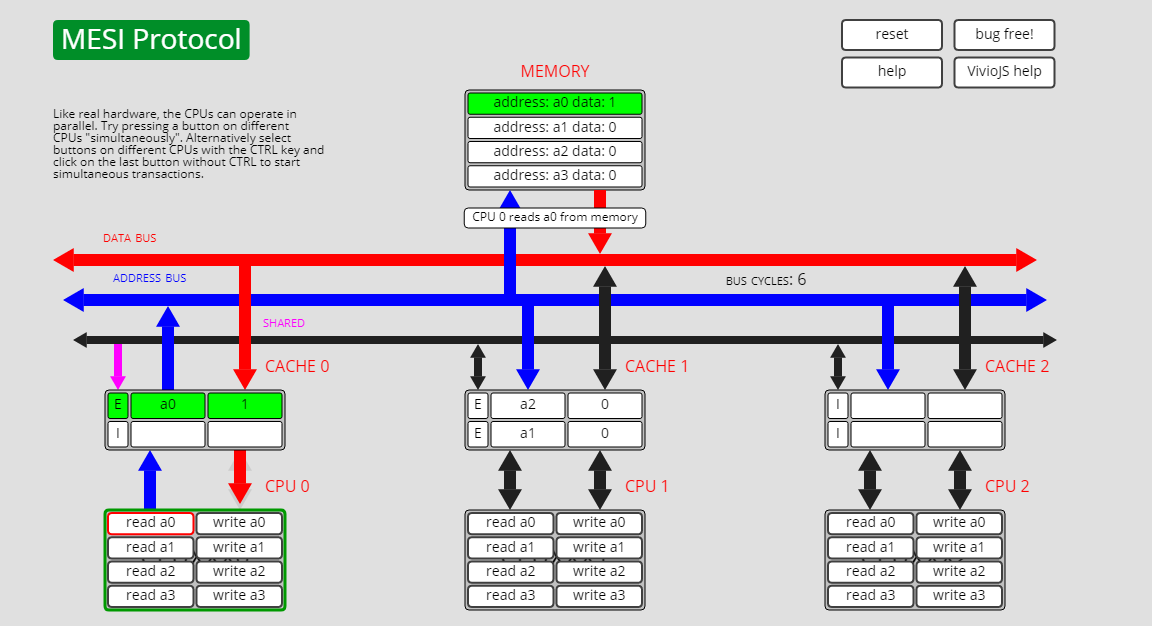
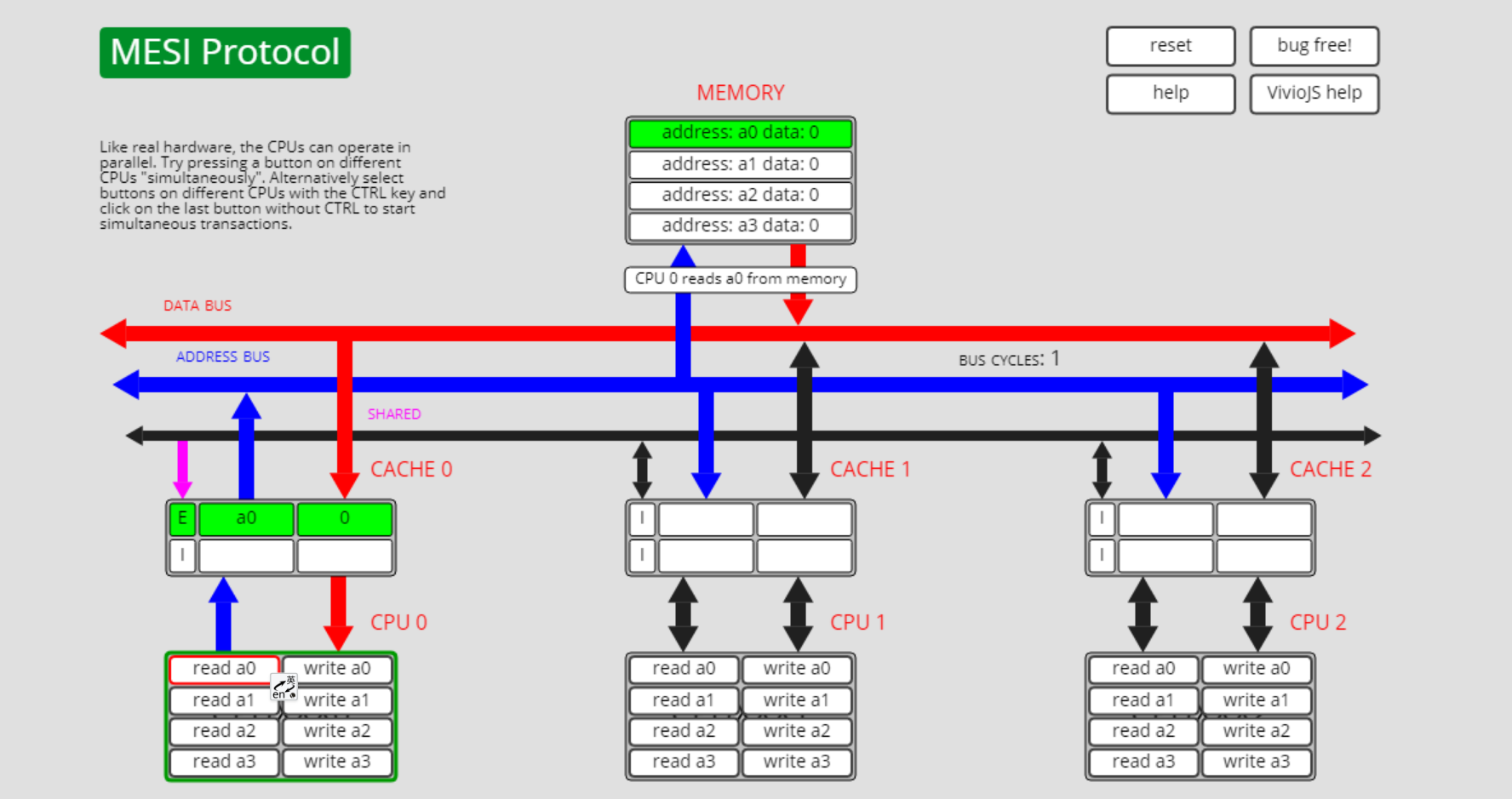
已失效状态I转独占状态E,I->E
状态I转状态E有两种路径,第一种是通过Processor Read, 此时a0数据仅存在于cpu0的cache中:
cpu0执行read a0操作,a0状态从I转为了E:
第二种是通过process write, 注意此时a0数据存在于cpu0和cpu1的cache中:
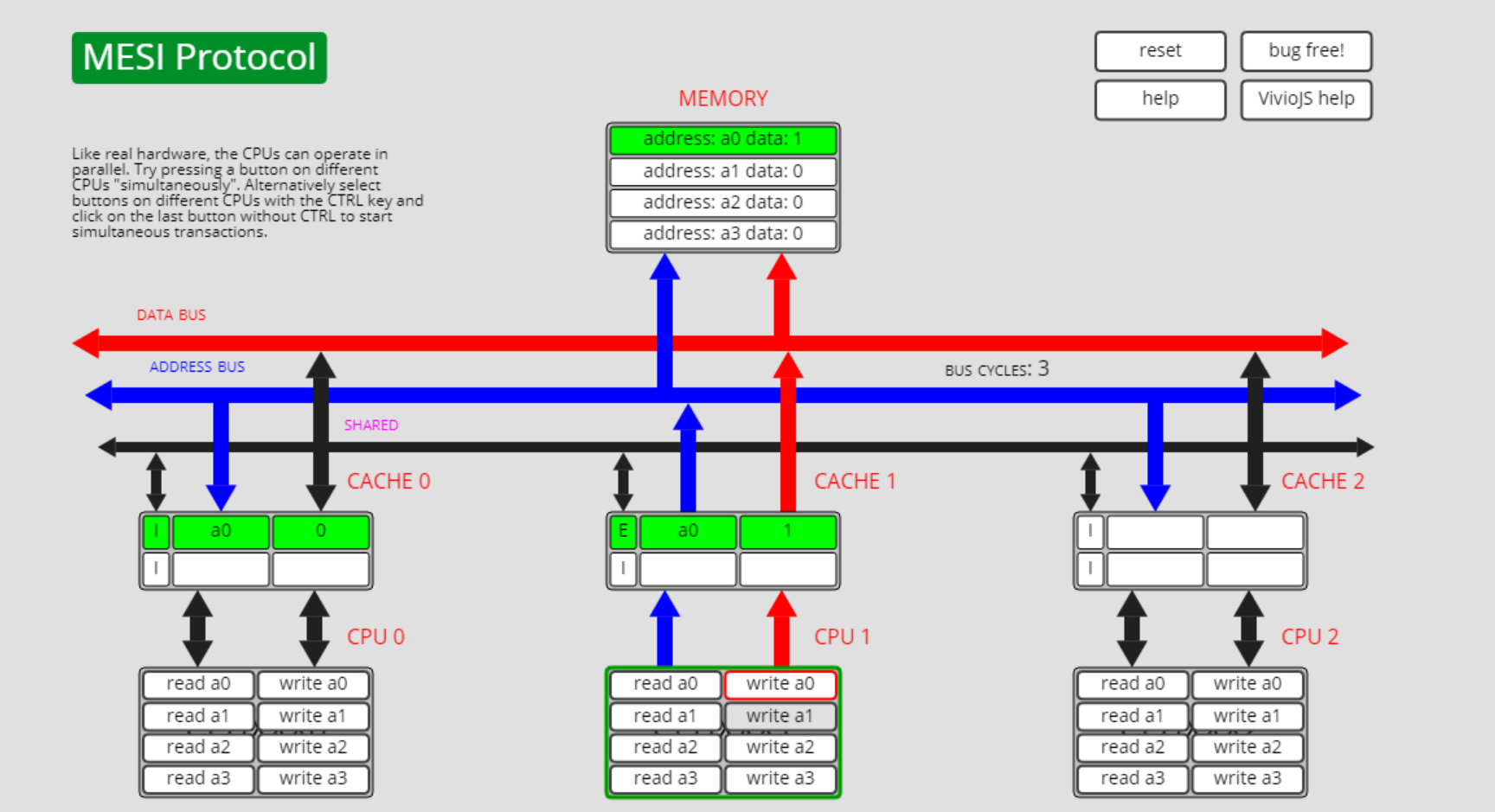
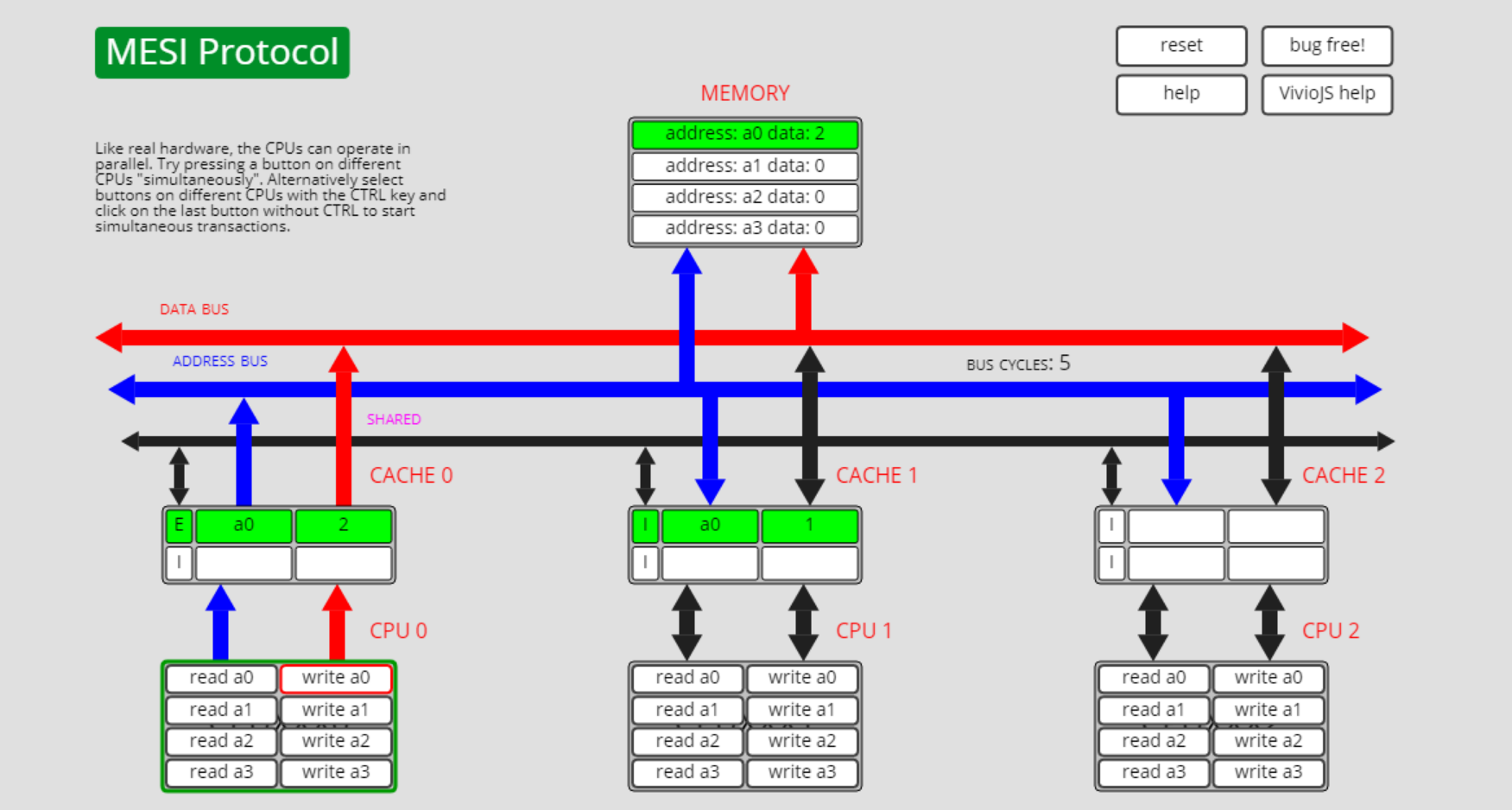
cpu0执行write a0操作,a0状态从I转为了E:
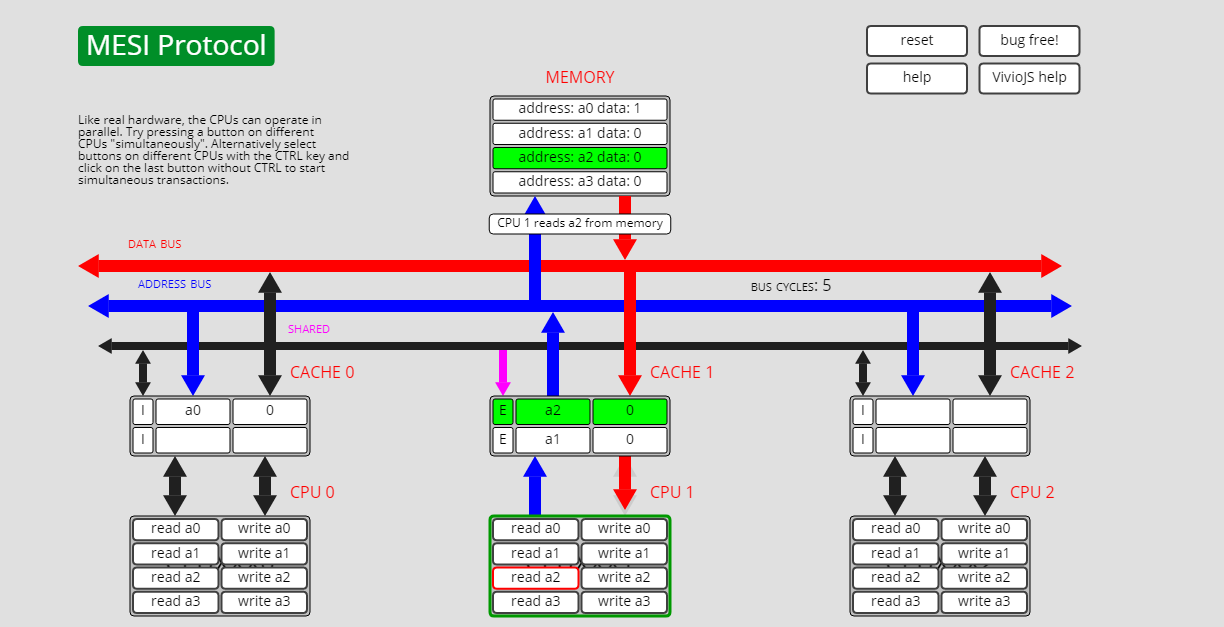
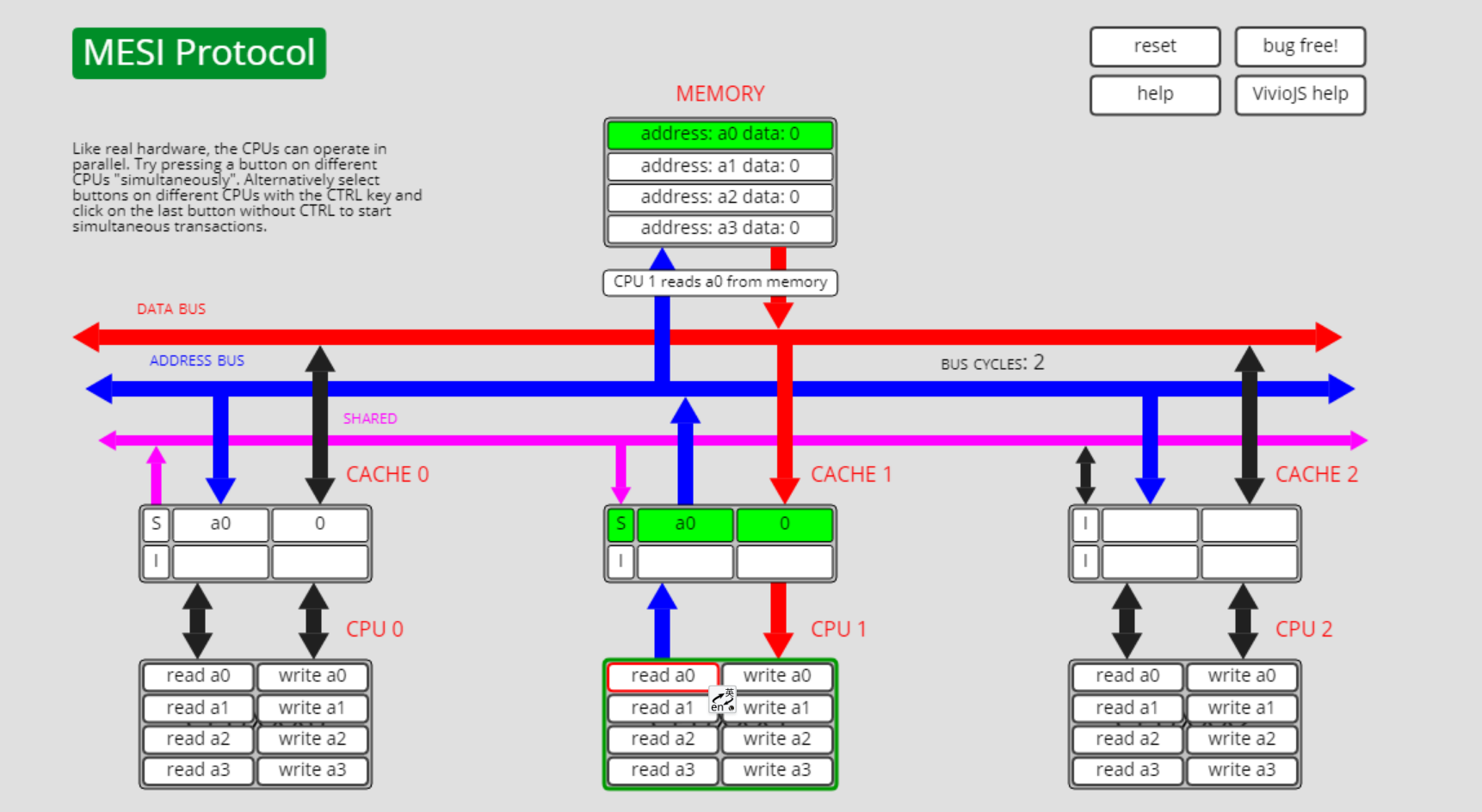
已失效状态I转共享状态S,I->S
此时cpu0上a0的状态是I, 而cpu1上a0的状态是E:
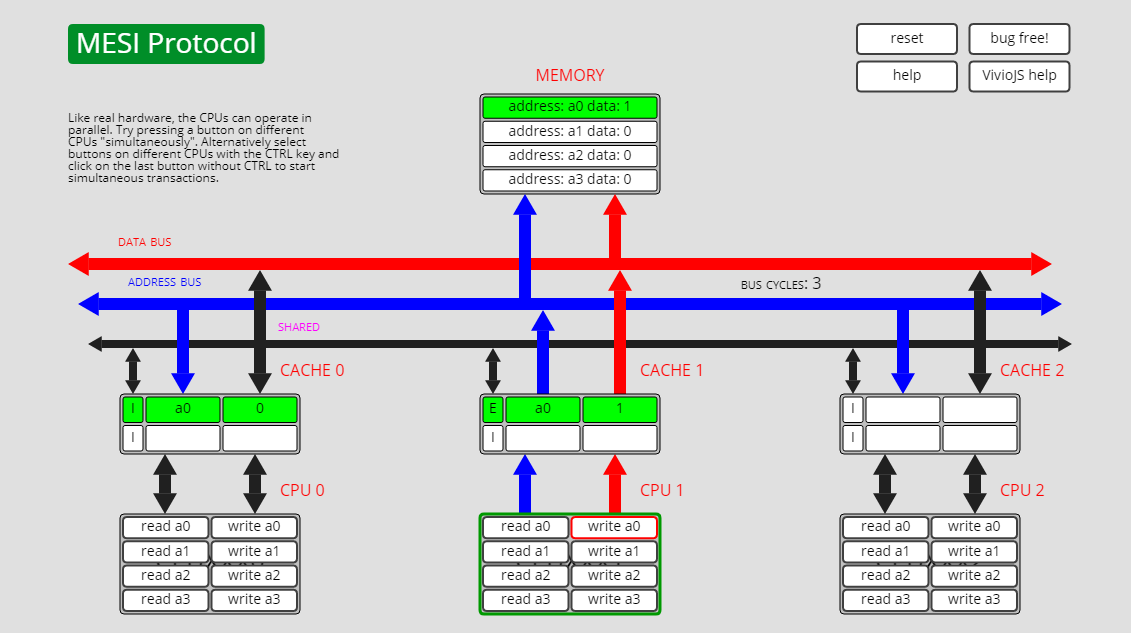
此时cpu0执行read a0操作,cpu0上的a0从I转为S:
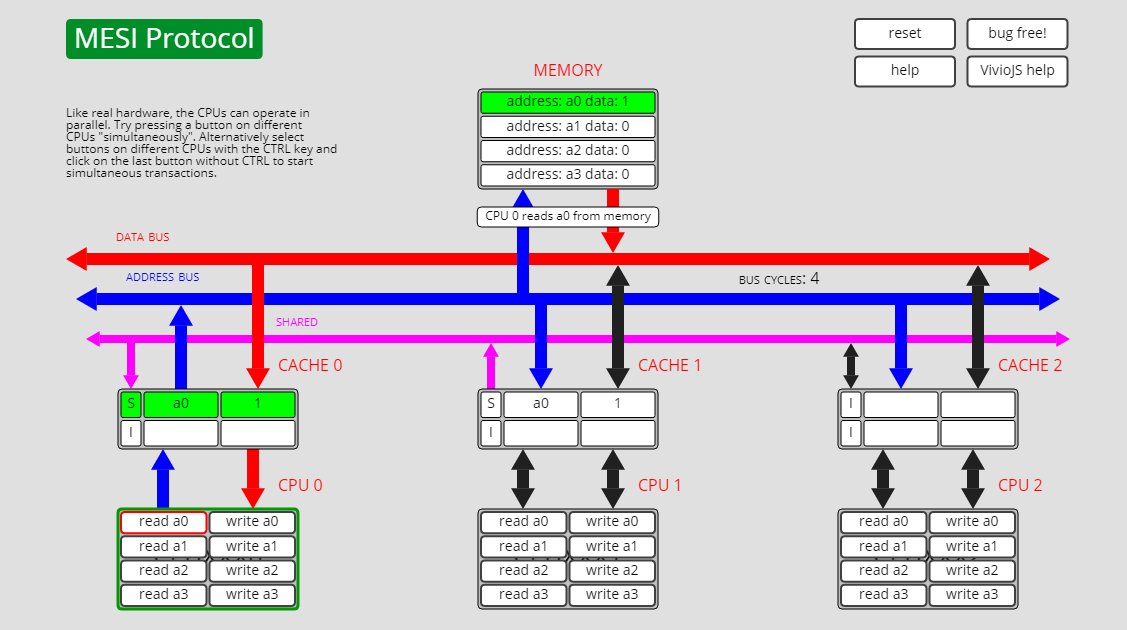
独占状态E转已失效状态I,E->I
此时cpu0上的有a0的缓存,且状态为E,其它cpu上没有a0的缓存:

此时cpu1执行write a0的操作,此时cpu0上a0的状态从E转为I:
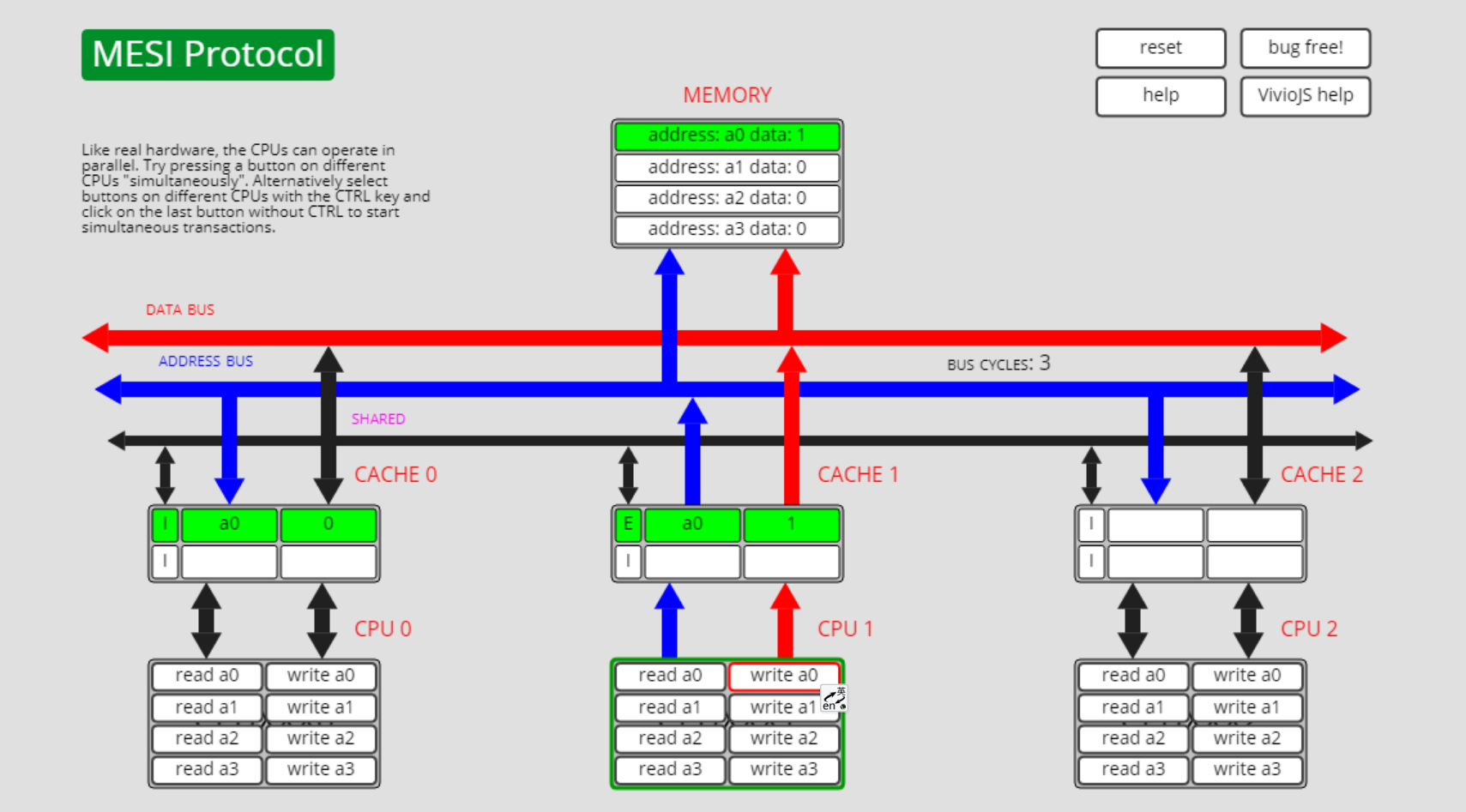
已修改状态E转共享状态S,E->S
如下图所示,此时cpu0的独占a0:
此时cpu1执行read a0的操作:
独占状态M转失效状态I, M->I
此时cpu0上拥有a0的缓存,且状态为M,其它cpu上没有a0的缓存:
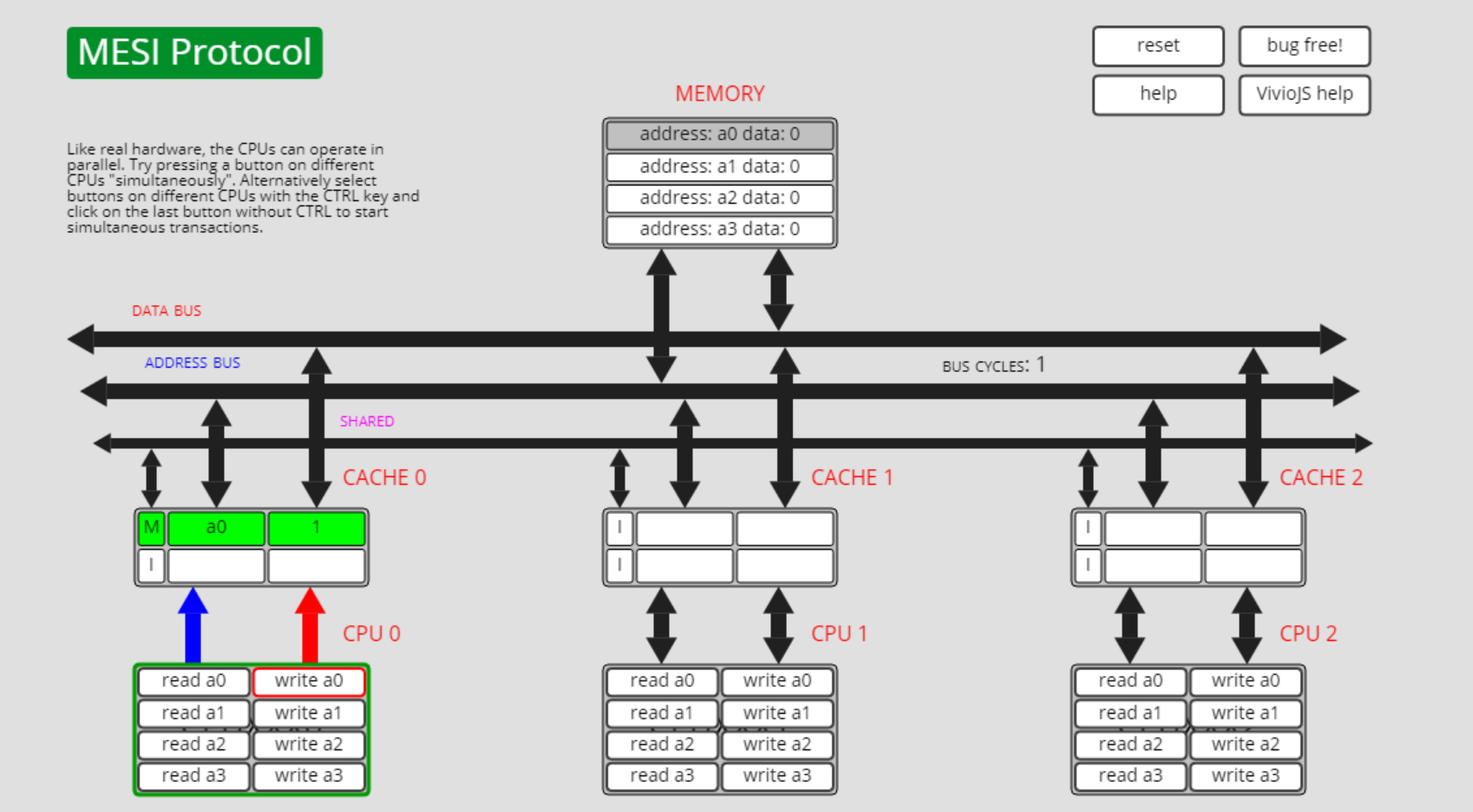
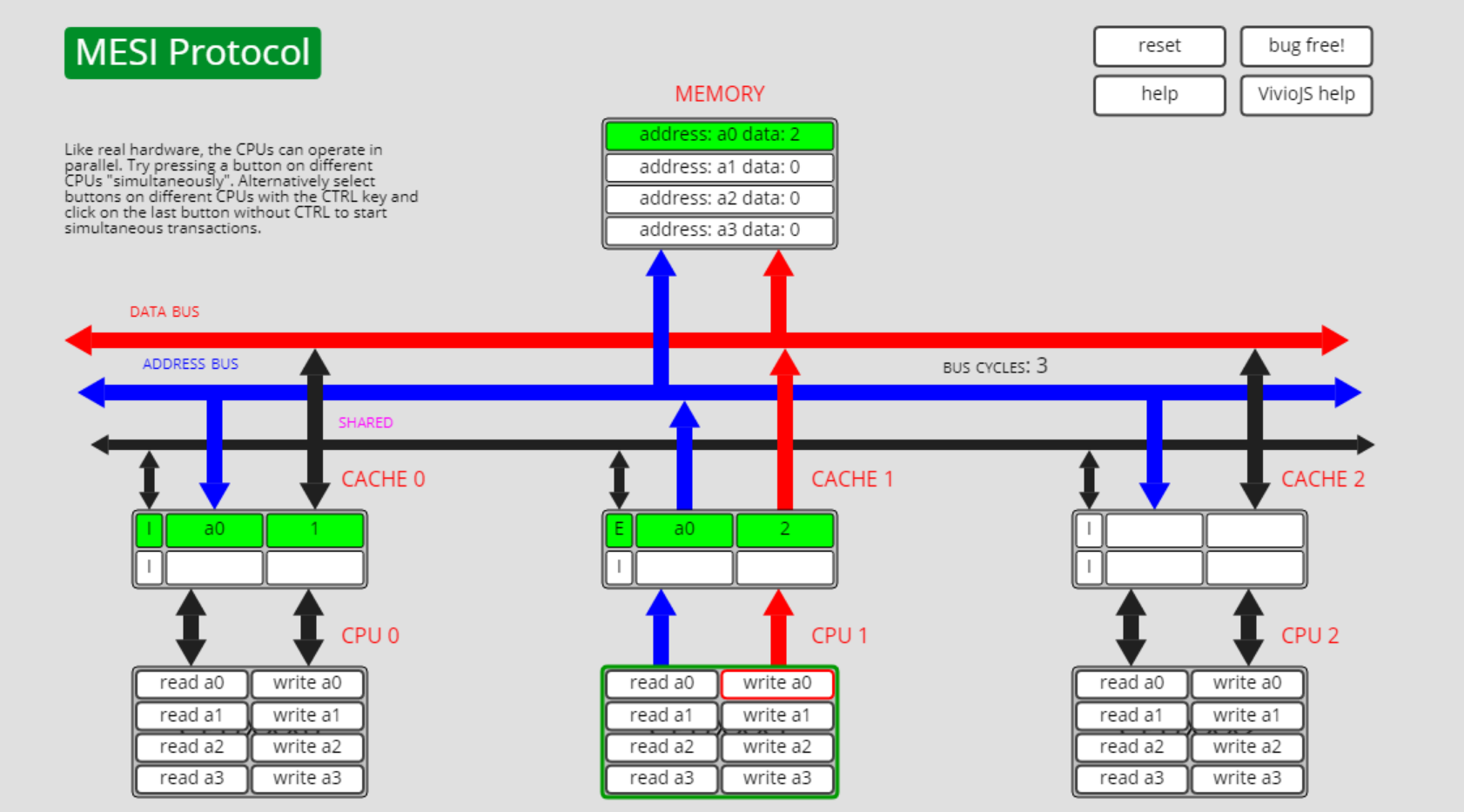
此时cpu1执行write a0的操作,则cpu0上a0缓存的状态从独占(M)转为了失效(I):
已失效状态I转已修改状态M,I->M
此时cpu0上a0缓存的状态是I,其它cpu上没有a0的缓存:
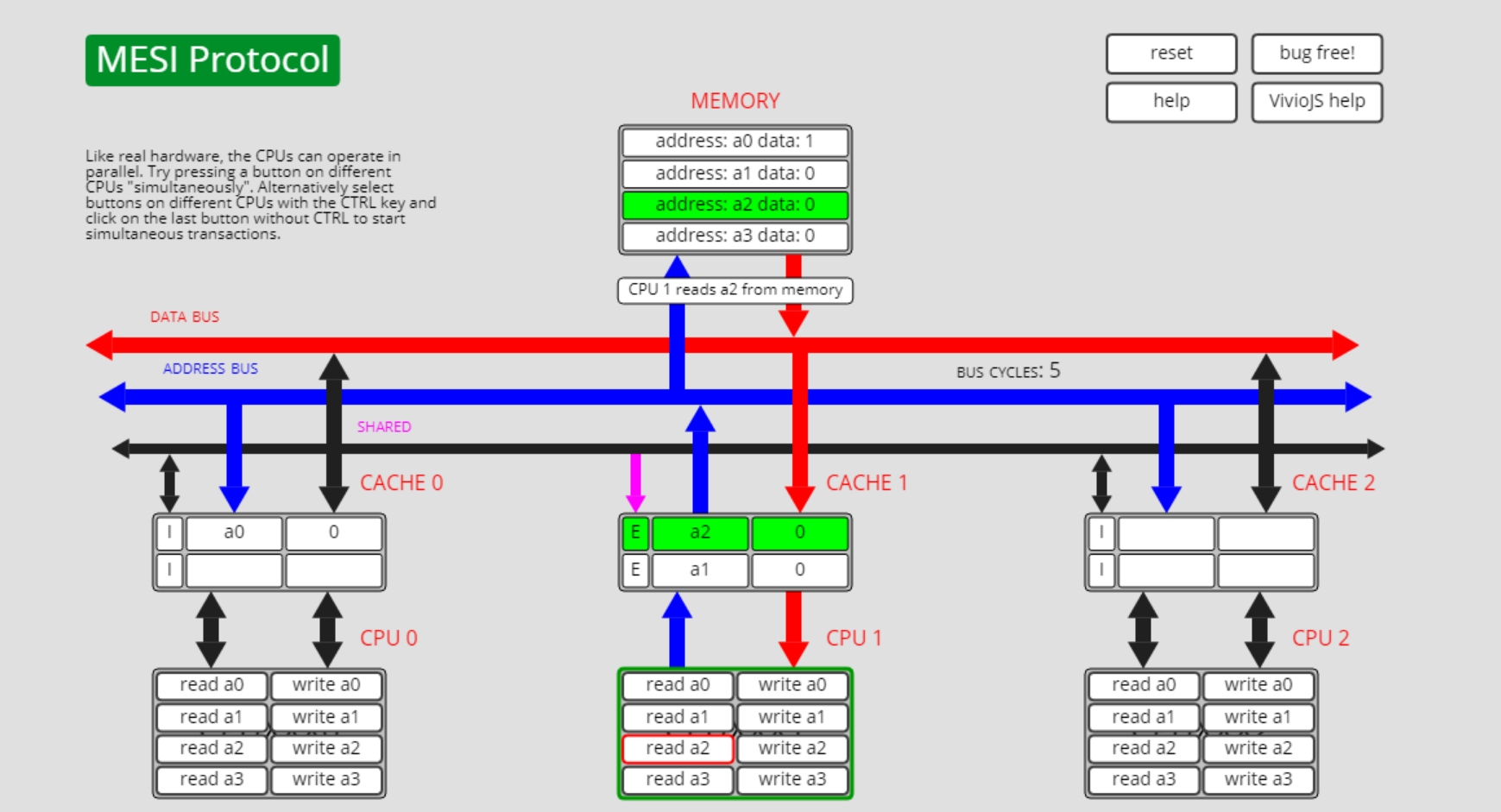
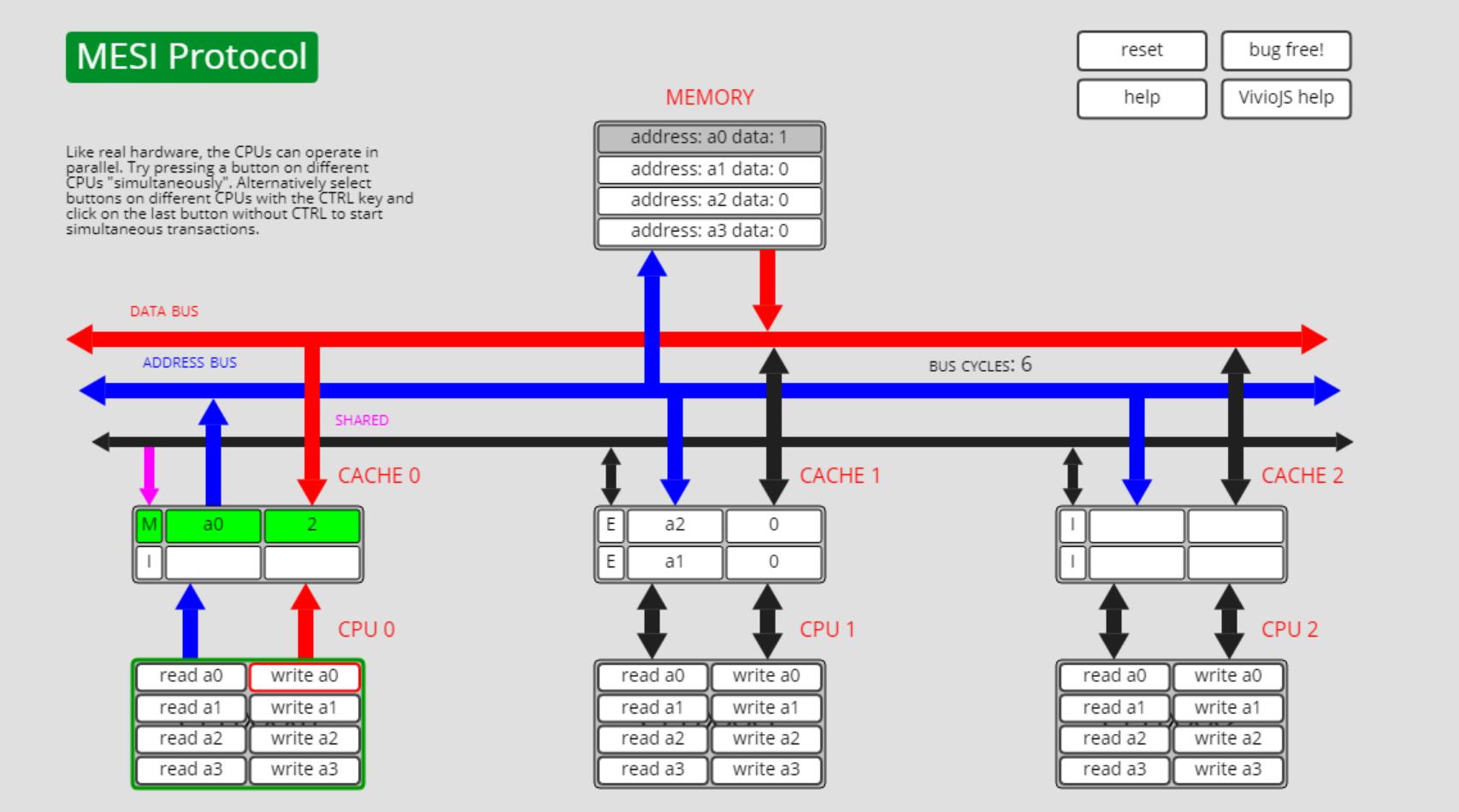
此时cpu0执行write a0, 则cpu0上的a0从I转为了E:
写缓冲区和失效队列
写缓冲区和失效队列实际上是对MESI的优化策略。
写缓冲区(Store Buffer)
从上面的对于MESI的理解中,不难发现,MESI协议其实并不高效。例如当CPU1将要修改cache line时,需要广播RFO获得独占权,当收到其它cpu核的ACK之前,CPU1只能空等。 这对于CPU1而言,是一种资源的浪费。写缓冲区就是为了解决这个问题的。当CPU核需要写操作时,会将写操作放入缓冲区中,然后就可以执行其它指令了。当收到其它核心的ACK后,就可以将写入的内容写入cache中。
失效队列(Invalidation Queue)
写缓冲区是对写操作发送命令时的优化,而失效队列则是针对收写操作命令时的优化。
对于其它的CPU核心而言,在其收到RFO请求时,需要更新当前CPU的cache line状态,并回复ACK。然而在收到RFO请求时,CPU核心可能在处理其它的事情,不能及时回复
写缓冲区和失效队列将RFO请求的收发修改为了异步的,这实际上实现的是一种最终一致性。这也会引入新的问题,即CPU对于指令会有重排。如果有一些程序对于内存序有要求,那么就需要进行考虑。
考虑下面的场景,cpu0和cpu1分别执行下面的指令:
cpu0上指令
a = 1 //A1
x = b //A2
cpu1上指令
b = 1 //B1
y = a //B2
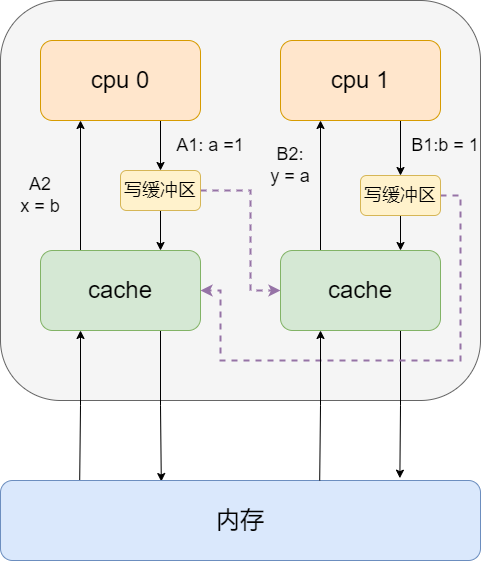
由于store-buffer的存在,尽管A1操作先于A2操作之前发生,但是A1操作完成时间可能晚于A2,如下表中反应的顺序:
| 顺序 | cpu0 | cpu1 |
|---|---|---|
| 0 | a=1写入store buffer | b = 1写入store buffer |
| 1 | x=b | |
| 2 | y = a | |
| 3 | b = 1操作完成 | |
| 4 | a=1操作完成 |
尽管A1操作发生于B2之前,但是由于写操作的异步特性,当执行到y=a时,读取到的还是旧值。同理x=b也可能读取到旧的值。
对于这种cpu层面的指令重排问题,则需要内存屏障进行解决。
总结
- 对于单核cpu,写操作需要考虑cache和内存的一致性,通常有写直达和写回两种策略。
- 对于多核cpu,除了cache和内存的一致性需要保证,还需要保证每个cpu的cache的数据的一致性。
- MESI协议就是一种解决多核cpu缓存一致性的算法
- 为了改善MESI的效率,引入了store-buffer和Invalidation Queue,提升了效率,但是也引入了指令重排的问题。通常可以使用内存屏障解决。
参考文献
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
https://blog.csdn.net/weixin_46215617/article/details/115433851?share_token=0637ba7e-fc4b-4d21-8d6b-000301e7fe3e
https://juejin.cn/post/7158395475362578462
https://blog.51cto.com/qmiller/5285102