线程安全性的原理分析
写在前面
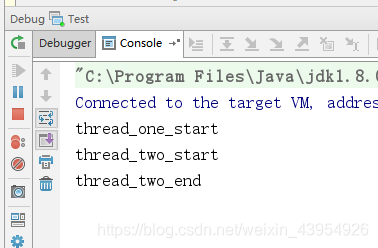
一段代码引来的思考:为什么程序一直走不出Thread_One的while循环呢?
public class Test{
public static boolean threadOneFlag = true;
public volatile static boolean threadTwoFlag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
System.out.println("thread_one_start");
while (threadOneFlag){ }
System.out.println("thread_one_end");
},"Thread_One").start();
new Thread(()->{
System.out.println("thread_two_start");
while (threadTwoFlag){ }
System.out.println("thread_two_end");
},"Thread_Two").start();
Thread.sleep(1000);
//对threadOneFlag变量的修改在线程Thread_One中并不可见
threadOneFlag = false;
threadTwoFlag = false;
}
}
运行结果:
从硬件层面了解可见性的本质
程序运行时用到的存储设备有:CPU、内存、磁盘(IO设备),三者有不同的处理速度,而且差异很大。当一个程序运行时如果三者都需要访问,如果不做任何处理的话,计算效率受限于最慢的设备,计算机硬件对此做了一些优化:
- CPU增加了高速缓存
- 多核CPU并且增加了进程、线程概念,通过时间片切换最大化提升CPU的使用率
- 编译器的指令优化,更合理的去利用好CPU的高速缓存
这些优化虽然提升了计算机的计算效率,但是却带来的可见性和重排序的问题,下面慢慢讲解
CPU高速缓存
- 存在的意义:绝大多数的运算任务不能仅通过处理器来完成,还需要和内存进行交互。例如:读取运算数据,存储运算结果。因为计算机的存储设备与处理器运算速度差距很大,所以会增加CPU高速缓存作为两者之间的缓冲:将运算需要使用的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步到内存之中。
- 存在的弊端:会带来缓存一致性的问题
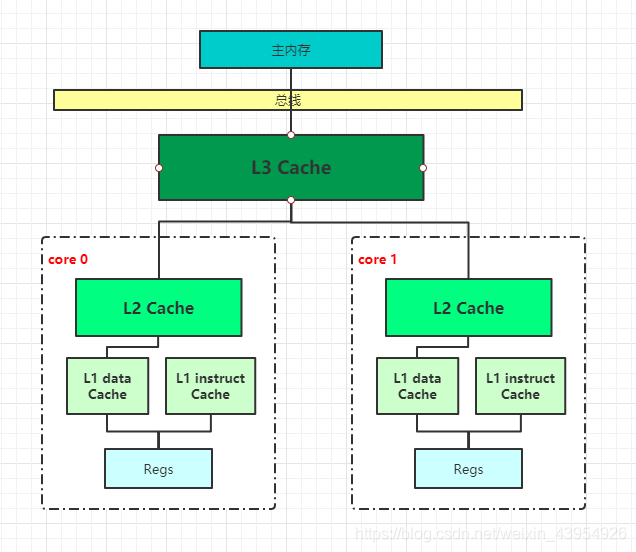
- CPU高速缓存的结构:
分为L1,L2,L3三级缓存,L1和L2是CPU私有的,其中L1最小,L1又分为数据缓存和指令缓存
缓存一致性
- 当高速缓存存在以后,每个CPU获取/存储数据直接操作高速缓存,而不是内存,这样当多个线程运行在不同CPU中时。同一份内存数据就可能会缓存于多个CPU高速缓存中,如不进行限制,就会出现缓存一致性问题
- CPU层面提出了两种解决办法:1. 总线锁,2. 缓存锁
总线锁和缓存锁
- 总线锁:在多CPU下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个LOCK信号,使得其他处理器无法访问共享数据,开销很大,如果我们能够控制锁的粒度就能减少开销,从而引入了缓存锁。
- 缓存锁:只要保证多个CPU缓存的同一份数据是一致的就可以了,基于缓存一致性协议来实现的
缓存一致性协议
为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有MSI、MESI、MOSI。最常见的是MESI协议。
MESI协议
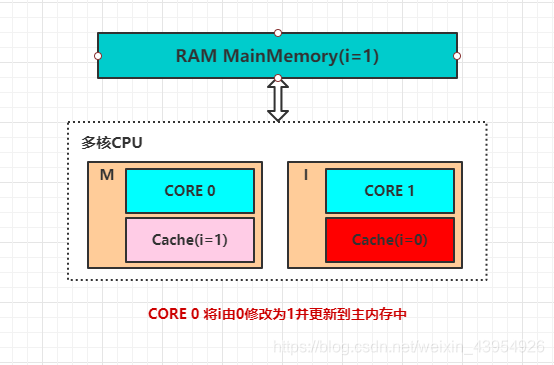
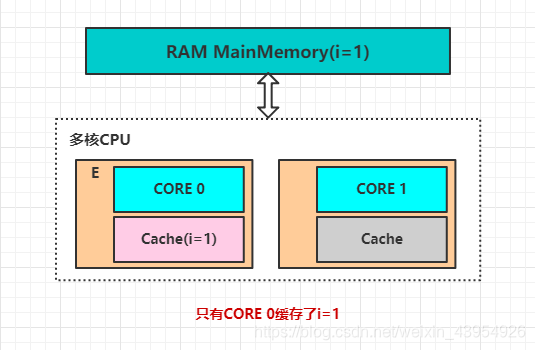
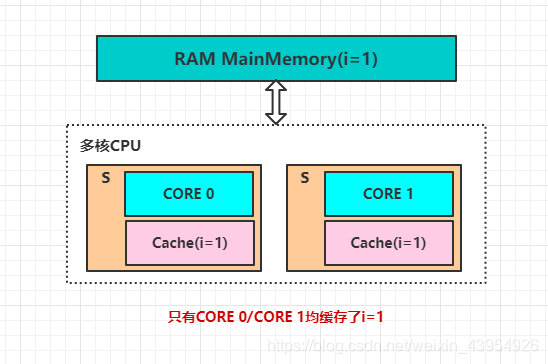
在MESI协议中,每个缓存的缓存控制器不仅知道自己的读写操作,而且也监听其他Cache的读写操作。共有四种状态,分别是:
- M(Modify)表示共享数据只缓存在当前CPU缓存中,并且是被修改的状态。此时表示当前CPU缓存数据与主内存中不一致,其他CPU缓存中如果缓存了当前数据应是无效状态,因为该数据已被修改且并没更新到主内存
- E(Exclusive)表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
- S(Shared)表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存中的数据一致
- I(Invalid)表示当前缓存已经失效
- 图解四种状态:
- 对于MESI协议,从CPU读写角度来说会遵循一下原则:
- CPU读请求:缓存处于M、E、S状态都可以被读取,I状态CPU只能从主内存中读取数据
- CPU写请求:缓存处于M、E状态才可以被写入主内存中。对于S状态的写,需要将其他CPU中缓存行设置为无效才可写。
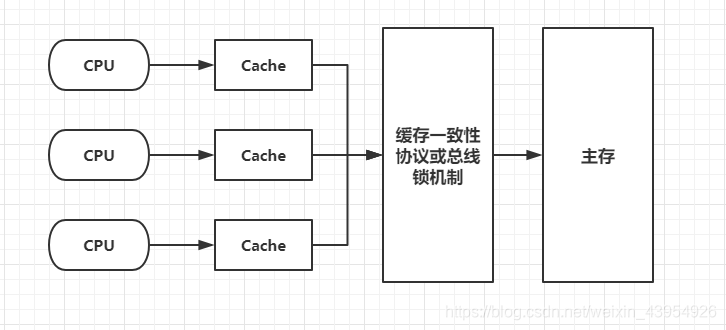
- 使用总线锁和缓存锁机制之后,CPU对于内存的操作可以做如下抽象:
MESI协议的不足之处
- 当一个CPU_0需要将缓存中的数据进行写入时,首先需要发送失效信息给其他缓存了该数据的CPU,等回执确认之后才会进行写入。等待回执确认的过程中CPU_0会处于阻塞状态,为了避免阻塞造成的资源浪费,CPU中引入了Store Bufferes。
- 引入Sotr Bufferes后,CPU_0在写入共享数据时,只需将数据写入store bufferes中,同时向其他缓存了共享数据的CPU发送失效指令就可以做其他操作了。由store bufferes等待回执确认信息,并负责同步到主内存
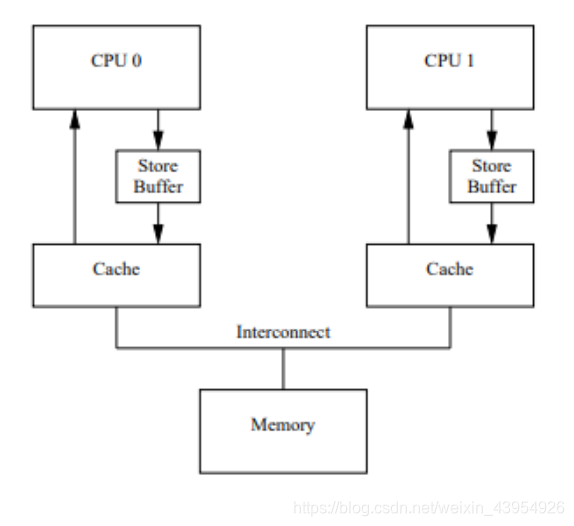
- 这种优化方式带来了两个现象,引起重排序的问题:
- 数据什么时候提交不确定,因为需要等待其他CPU确认回执之后才会提交,这是一个异步操作
- 引入storebufferes后,处理器会先尝试从storebuffere中读取值,如果storebufferes中有数据,则直接从storebuffer中读取,否则再从缓存行中读取
重排序
- 请看如下代码:假如exeToCPU0和exeToCPU1执行在不同CPU上,当exeToCPU0执行完两行赋值代码时,此时exeToCPU1执行if语句时,isFinsh = true,但是可能value并不为10,这就是重排序问题。
- 原因在于:假设CPU0缓存的两个变量及状态为:isFinish(E),value(S),CPU0修改value时只会先将修改结果保存到Store Buffer中,然后继续执行isFinish=true指令,因为isFinish是(E),所以会直接将修改结果写入内存中。此时CPU1读书两个值时,可能的结果就是:isfinish=true,value=3(不等于10)

- 为了解决此类问题,CPU层面提出了内存屏障
CPU层面的内存屏障
- 可以将其粗犷的理解为:将store buffer中的指令写入到内存,从而使得其他访问同一共享内存的线程的可见性
- X86的 memory barrier的指令包括:读屏障、写屏障以及全屏障
- 写屏障:告诉处理器在写屏障之前的所有已经存储在存储缓存(store bufferes)中的数据同步到主内存,也就是,写屏障之前的指令对于屏障之后的读操作都是可见的。
- 读屏障:处理器读屏障之后的读操作都在屏障之后执行
- 全屏障:确保屏障前的内存读写操作的结果都对屏障之后的操作可见
- 这些都不需要我们程序员来维护,和我们直接打交道的是JMM
JMM
- JMM全称是Java Memory Model,是隶属于JVM的,是属于语言级别的抽象内存模型,可以简单理解为对硬件模型的抽象,它定义了共享内存中多线程程序读写操作的行为规范。JMM并没有提升或者损失执行性能,也没有直接限制指令重排序,JMM只是将底层问题抽象到JVM层面,是基于CPU层面提供的内存屏障及限制编译器的重排序来解决问题的
- JMM抽象模型分为主内存和工作内存。主内存是所有线程共享的,工作内存是每个线程独占的。线程对变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量,线程之间共享变量的传递都是基于主内存来完成的
- JMM体统了一些禁用缓存以及禁止重排序的方法,来解决可见性和有序性问题,例如:volatile、synchronized、final
- 在JMM中如果一个操作的执行结果必须对另外一个操作可见,两个操作必须要存在happens-before关系,即happen-before规则(具体参见:happen-before规则)。
▄█▀█●各位同仁,如果我的代码对你有帮助,请给我一个赞吧,为了下次方便找到,也可关注加收藏呀
如果有什么意见或建议,也可留言区讨论
