MySQL MVCC机制详解
MVCC, 是Multi Version Concurrency Control的缩写,其含义是多版本并发控制。这一概念的提出是为了使得MySQL可以实现RC隔离级别和RR隔离级别。
这里回顾一下MySQL的事务, MySQL的隔离级别和各种隔离级别所存在的问题。
事务是由 MySQL 的引擎来实现的,我们常见的 InnoDB 引擎它是支持事务的。
不过并不是所有的引擎都能支持事务,比如 MySQL 原生的 MyISAM 引擎就不支持事务,也正是这样,所以大多数 MySQL 的引擎都是用 InnoDB。
事务看起来感觉简单,但是要实现事务必须要遵守 4 个特性,分别如下:
- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节,而且事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样;
- 一致性(Consistency):数据库的完整性不会因为事务的执行而受到破坏,比如表中有一个字段为姓名,它有唯一约束,也就是表中姓名不能重复,如果一个事务对姓名字段进行了修改,但是在事务提交后,表中的姓名变得非唯一性了,这就破坏了事务的一致性要求,这时数据库就要撤销该事务,返回初始化的状态。
- 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
MySQL的四种隔离级别如下:
- 读未提交(read uncommitted):指一个事务还没有提交时,它做的变更才能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它所做的变更才能被其他事务看到
- 可重复度(repeated read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据时一致的,这是MySQL InnoDB引擎的默认隔离级别。
- 串行化(serializable):会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行
读未提交级别下会遇到脏读的问题,所谓脏读是指在一个事务中会读取到另一个事务没有提交的改动,例如下图中所示:
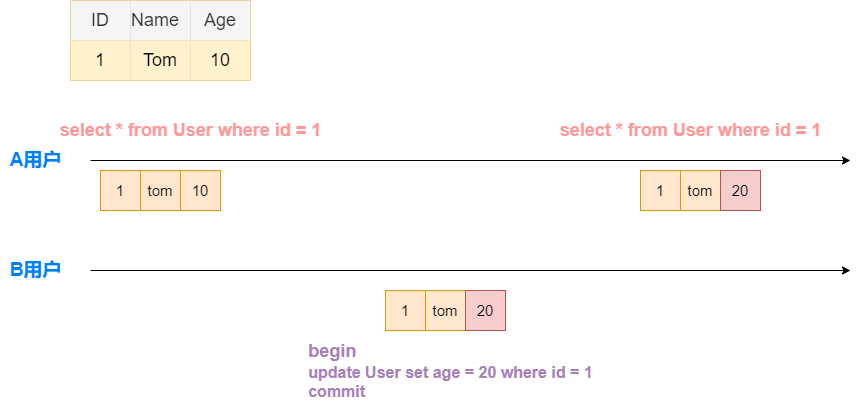
A用户在第一次查询ID=1的用户时,其年龄是10。 在这之后,B用户对ID=1的用户的age进行了修改,随后就将事务进行了回滚。但是结果A用户第二次查询ID=1的用户的年龄时发现年龄修改为了20, 即读取到了脏数据。
读提交级别下会遇到不可重复读的问题,所谓不可重复读是指在同一个事务中多次select出的数据的值发生了变化。例如下图中所示:
A用户在第一次查询ID=1的用户时,其年龄是10。 在这之后,B用户对ID=1的用户的age进行了修改,并且提交了事务,结果A用户第二次查询ID=1的用户的年龄时发现年龄修改为了20。这样的变化就是不可重复读。
MySQL使用了MVCC实现了RC和RR隔离级别,这便是MVCC机制的作用。
为了更好的去理解MVCC的原理,我们需要对MySQL的undo log有一些理解。
undo log
undo log是MySQL的三大日志之一,另外两个是bin log和redo log。
undo log译名为回滚日志,也就是用于事务回滚的日志。在事务没有提交之前, MySQL会将用户的操作记录到回滚日志中,如果用户执行了回滚操作,则根据回滚日志执行反向操作,例如:
- 如果用户向数据库插入了一条数据,回滚时执行反向操作,即删除该条数据。
- 如果用户删除了数据库的一条数据,回滚时执行反向操作,则向数据库插入该条数据。
- 如果用户更新的一条记录,则需要把原值记录下来,回滚时则执行反向操作,将该数据的值恢复为原值。
不知道看到上面的操作有没有让你联想到git revert。git是一个版本管理工具, git log便是记录了仓库的所有commit的记录。根据git的某一个commit,git revert便会生成其反向的操作。
其实undo log的思想和git是类似的。其通过隐藏列trx_id、roll_pointer将不同事务的commit按照时间线组织了起来。
隐藏列trx_id、roll_pointer的含义如下表所示:
|列名|是否必须|描述|
|trx_id|是|记录操作该行数据事务的事务ID|
|roll_pointer|是|回滚指针,指向当前记录行的undo log信息|
如下图所示,通过roll_pointer就将每个commit串成了一个版本链。
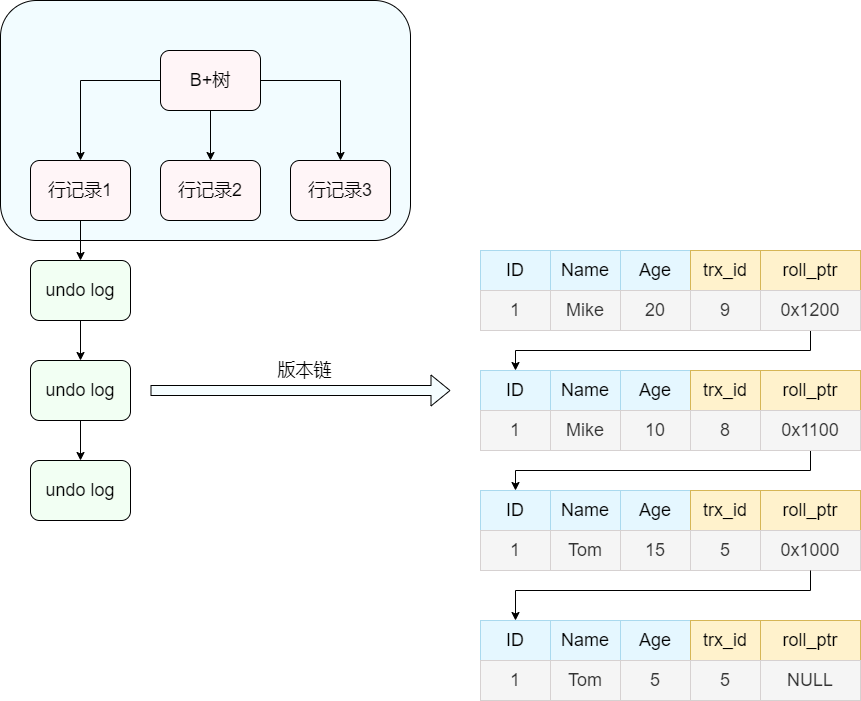
这样的版本链便给后续的ReadView的生成提供了条件。
ReadView
ReadView类似于一个snapshot(快照),ReadView是基于undo log实现的。
下面就来看看ReadView具体是如何实现的。
ReadView记录了下面一些字段:
- creator_trx_id: 创建该ReadView的事务的id
- m_ids: 创建ReadView时,当前数据库活跃且未提交的事务id列表
- up_limit_id: 创建ReadView时,当前数据库中活跃且未提交的最小事务id
- low_limit_id: 创建ReadView时,当前数据库中分配的下一个事务的id值
利用ReadView中的这些字段就可以判断undo log版本链上的每个commit对于当前的事务而言是否是可见的。
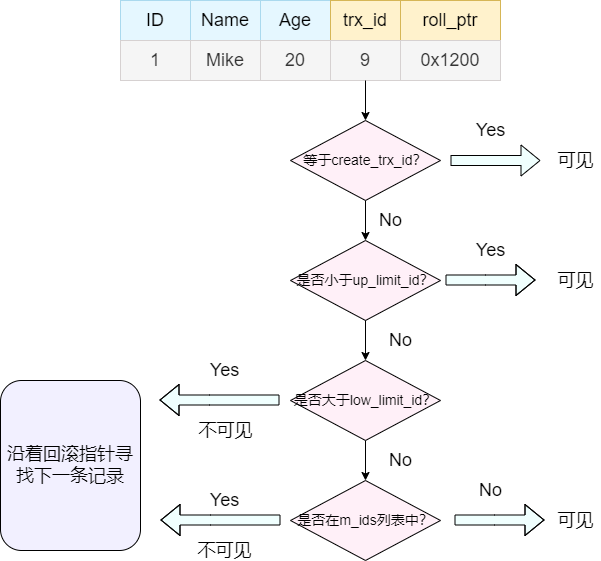
对于undo log中的某一条记录,判断其是否可见的规则如下:
- 如果被访问版本的 事务ID = creator_trx_id,那么表示当前事务访问的是自己修改过的记录,那么该版本对当前事务可见;
- 如果被访问版本的 事务ID < up_limit_id,那么表示生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的 事务ID > low_limit_id 值,那么表示生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的 事务ID在 up_limit_id和m_low_limit_id 之间,那就需要判断一下版本的事务ID是不是在 trx_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
这段逻辑写在MySQL仓库的storage/innobase/include/read0types.h文件中。
/** Check whether the changes by id are visible.
@param[in] id transaction id to check against the view
@param[in] name table name
@return whether the view sees the modifications of id. */
[[nodiscard]] bool changes_visible(trx_id_t id,
const table_name_t &name) const {
//ut 忽略
ut_ad(id > 0);
//如果被访问版本的 事务ID = creator_trx_id,那么表示当前事务访问的是自己修改过的记录,那么该版本对当前事务可见;
//如果被访问版本的 事务ID < up_limit_id,那么表示生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
if (id < m_up_limit_id || id == m_creator_trx_id) {
return (true);
}
check_trx_id_sanity(id, name);
//如果被访问版本的 事务ID > low_limit_id 值,那么表示生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
if (id >= m_low_limit_id) {
return (false);
//如果m_ids为空,则生成readview时所有的commit对于当前事务都可见
} else if (m_ids.empty()) {
return (true);
}
const ids_t::value_type *p = m_ids.data();
//如果被访问版本的 事务ID在 up_limit_id和m_low_limit_id 之间,那就需要判断一下版本的事务ID是不是在 trx_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
return (!std::binary_search(p, p + m_ids.size(), id));
}
通过源码的阅读, 也印证了上述匹配逻辑。
上面的匹配的逻辑是针对单条commit记录的。整个过程将从undo log的最新记录开始,逐条判断,如果判断结果是可见的,那么则返回该记录。如果判断结果是不可见的,则沿着undo log往下继续寻找。
整个寻找的过程可以参照下面的流程图:
下面通过一些案列来加深ReadView的理解。
在下面的案例中,事务8是当前的事务,其使用了select语句查询了表中的数据,触发了readview的生成,因此creator_trx_id=8。在readview生成的时刻,当前活跃的且未提交的事务为[4,6,7,9], 因此up_limit_id=4, low_limit_id=11。
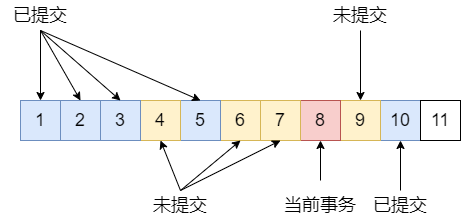
下面查看user表的id=1的undo log,其最新的改动是事务9提交的。 事务9满足下面的不等式,事务4 < 事务9 < 事务11, 因此需要查看事务9是否在trx_ids列表中。经过查看发现事务9在m_ids中,因此在生成readview的时刻,事务9的提交对于事务8并不可见。 因此需要往下滑动,检查undo log中次新的数据。
在undo log的次新的数据中。trx_id=8, 与creator_trx_id相等,因此对于当前事务可见。因此readview中可见的最新数据已经找到。
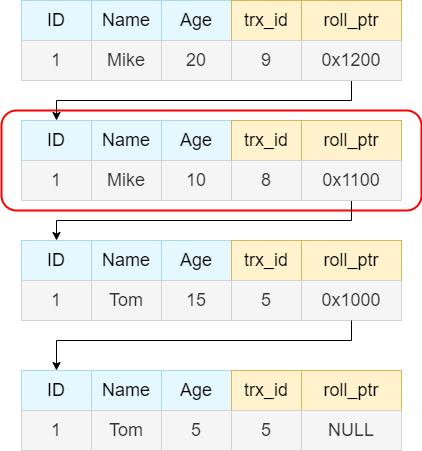
下面查看user表的id=1的undo log,其最新的改动是事务12提交的。 事务12 > low_limit_id, 事务12的提交对于事务8并不可见。 因此需要往下滑动,检查undo log中次新的数据。
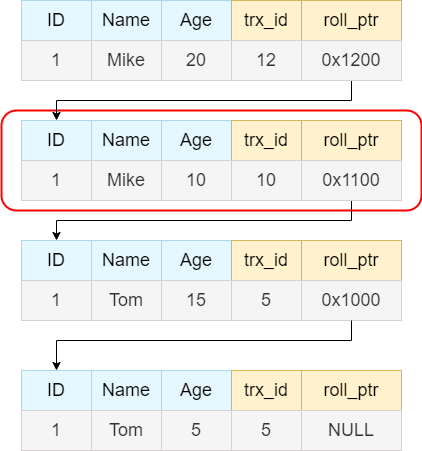
在undo log的次新的数据中。trx_id=10,在 up_limit_id和m_low_limit_id 之间,且事务10不在m_ids,说明创建 ReadView 时生成事务10已经被提交,该版本可以被访问。因此因此readview中可见的最新数据已经找到。
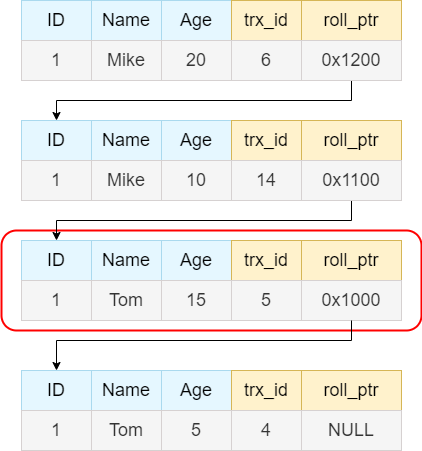
下面再看一个例子,在该例子中,undo log中最新的记录的事务id是6, 事务6满足下面的不等式, 事务4 < 事务6 < 事务11, 因此下面就需要检查事务6是否在m_ids中, 因为m_ids = [4, 6, 7, 9],因此事务6在创建readview时还没有提交,因此对于当前事务而言,该条记录并不可见。 因此沿着undo log往下找。
undo log中第二新的记录的事务id是14,事务14 > low_limit_id, 显而易见, 事务14的改动对于当前事务是不可见的。因此继续undo log往下找。
undo log中第三新的记录的事务id是5,事务4 < 事务5 < 事务11, 显而易见, 因此下面就需要检查事务5是否在m_ids中, 因为m_ids = [4, 6, 7, 9],因此事务5在创建readview时已经提交了,于是事务5对于当前事务而言是可见的, 于是找到了所需的值。
通过这三个案列对MVCC的工作机制会有非常深刻的理解了。
MVCC如何实现读提交和可重复读
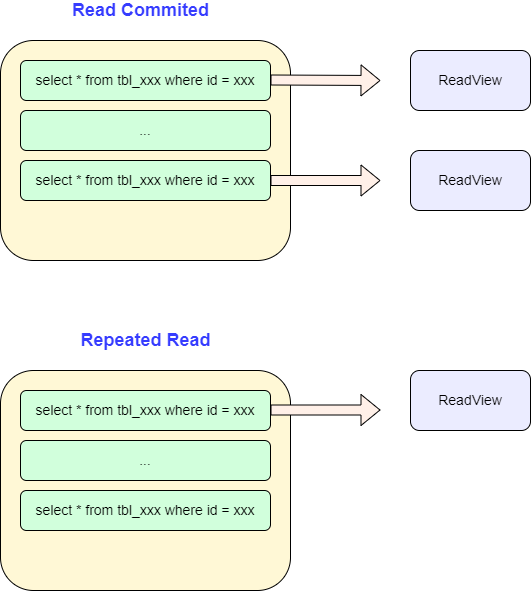
读提交和可重复读的MVCC机制是相同的。区别在于ReadView的生成时机不同。
对于读提交级别而言,其会在每一次查询操作时生成一次ReadView。因此后续再次select时,就可以读取到这期间的提交。
对于可重复读级别而言,其只会在事务的第一次查询操作时生成ReadView, 于是在ReadView生成后提交的commit就不再会看到,就好像是在对一个snapshot操作一样。
参考文章
https://www.cnblogs.com/qdhxhz/p/15750866.html
https://www.cnblogs.com/cswiki/p/15338928.html
https://www.6hu.cc/archives/86666.html