几种流行的 Python 性能加速方案对比:https://zhuanlan.zhihu.com/p/604519817
对程序执行性能没有强烈需求的,可以紧跟官方步伐,升级到最新版本的 Python 既可。Numba、Codon、Taichi 等这一类,原理上基本相同,也都是从某个场景发展过来的较为通用的方案,但是也都有各自的一些限制,按照场景选择自己顺手的即可。
- Cython、Pybind11、PyO3 可以看做一类,都需要学习新语言,相对而言 Cython 在语言学习上成本最低(10分钟入门Cython:https://zhuanlan.zhihu.com/p/49573586 )。Pybind11、PyO3 比较适合的场景是为现有的 C++、Rust 代码提供 Python API,如果不想写 C++、Rust,又对性能有很高的诉求,Cython 是个不错的选择,如果是新开项目则可以尝试下 Rust。
- Codon 是一种 Python 兼容的语言,许多 Python 程序只需要很少的修改就可以工作,如果了解 Python,你就已经知道 99% 的 Codon。
如果追求极致性能,推荐使用 C、C++开发,然后使用 ctypes 粘起来。
如果只熟悉 Python,推荐使用 Codon,兼容 Python 语言。
1、高性能 Python 编译器 Codon
Codon 简介
:https://github.com/exaloop/codon
文档:https://docs.exaloop.io/codon/general/intro
编译器 充当着高级语言与机器之间的翻译官,不同版本的 Python 编译器已被开发出来,其中Codon 就是一个高性能的 Python 编译器。
Codon 作为高性能 Python 编译器,可将 Python 代码编译为本机机器代码,而无需任何运行时开销。在单线程上,Python 的典型加速大约为 10-100 倍或更多。Codon 的性能通常与 C/C++ 的性能相当。与 Python 不同,Codon 支持本机多线程,这可以使速度提高很多倍。Codon 可通过插件基础结构进行扩展,它允许用户合并新的库、编译器优化甚至关键字。
Codon 框架是完全模块化和可扩展的,允许无缝集成新模块、编译器优化、领域特定语言等,并积极为生物信息学和量化金融等多个领域开发新的 Codon 扩展。
Codon 目标
- 无学习曲线:在语法、语义和库方面尽可能接近CPython
- 顶级性能:至少与C、C++或Rust等 低级(相对Python而言) 语言相当。Codon 的编译过程实际上更接近 C++ 而不是 Julia。Julia 是一种动态类型语言,它执行类型推断作为优化,而 Codon 类型是提前检查整个程序。Codon 还试图通过采用 Python 的语法和语义来规避新语言的学习曲线。
- 硬件支持:全面、无缝地支持多核编程、多线程(无GIL!)GPU及更多
- Python优化:全面的优化框架,可以针对高级Python构造和库
- 互操作性:与Python的包和库生态系统完全互操作
- Codon 不是 CPython 的直接替代品,Python 的某些方面不适合静态编译,在 Codon 中不支持这些。有一些方法可以通过 JIT 装饰器 或者 Python extension backend 在 Python 代码库中使用 Codon,Codon 还支持通过其 Python 互操作性调用任何 Python 模块
- 虽然 Codon 确实提供了一个类似于 Numba 的 JIT 装饰器,但 Codon 通常是一个提前(ahead-of-time)编译器,可以将端到端程序编译为本机代码。它还支持编译更广泛的 Python 构造和库集。
Codon 相关链接
Docs (文档) · FAQ · Blog · Chat (交流) · Roadmap (路线图) · Benchmarks (基准测试)
路线图里面是即将要实现的功能。
常见问题解答
虽然 Codon 几乎支持 Python 的所有语法,但它并不是一个简单的替代品,大型代码库可能需要修改才能通过 Codon 编译器运行。例如,一些 Python 的模块还没有在 Codon 中实现,一些 Python 的动态特性是不允许的。Codon 编译器会生成详细的错误消息,以帮助识别和解决任何不兼容问题。Codon 支持无缝的 Python 互操作性,以处理需要特定 Python 库或动态性的情况。
- 我想使用 Codon,但我有一个大型 Python 代码库且不想移植,怎么办?
可以通过 @codon.jit 装饰器来使用 Codon,这将只编译带标注的函数,并自动处理与 Codon 之间的数据转换。它还允许使用任何特定于 Codon 的模块或扩展,例如多线程。 - 与其他语言和框架的互通性如何?
互通性是 Codon 的优先事项。我们不希望使用 Codon 使用户无法使用现有的其他优秀框架和库。Codon 支持与 Python 和 C/C++ 的完全互通。 - Codon 是否使用垃圾收集?是的,Codon 使用了 Boehm 垃圾收集器。
- Codon 不支持 Python 模块 X 或函数 Y?
虽然 Codon 涵盖了 Python 标准库的一个相当大的子集,但它还没有涵盖每个模块的每个函数。但是仍然可以通过 Python 调用缺少的函数 from python import。许多缺少 Codon 本地实现的函数(例如 I/O 或 OS 相关功能)通常不会实现 Codon 的实质性加速。 - 对于我的应用程序,Codon 并不比 Python 快?
大部分时间用在 C 语言实现的库代码中的应用程序通常不会在 Codon 中看到实质性的性能提升。同样地,受 I/O 或网络限制的应用程序在 Codon 中也会遇到相同的瓶颈。
Codon 与 Python 的区别
Codon 与 Python 的区别:https://docs.exaloop.io/codon/general/differences
- 数据类型:codon 数据类型 和 Python 有些区别。
整数:codon 的 int 是一个 64 位有符号整数,而 Python 的(版本 3 之后)可以任意大。但是,codon 确实通过 Int[N] 支持更大的整数,其中 N 是位宽。
字符串:codon 目前使用 ASCII 字符串,这与 Python 的 unicode 字符串不同。
字典:codon 的字典类型不保留插入顺序,这与 Python 3.6 的字典类型不同。
元组:由于元组编译为结构,因此在编译时必须知道元组长度,这意味着您不能将任意大小的列表转换为元组。 - 类型检查:由于 Codon 会提前执行静态类型检查,因此不允许使用 Python 的一些动态功能。例如,在运行时对 monkey 类进行修补(尽管 Codon 在编译时支持这种形式)或将不同类型的对象添加到集合中。
- 数值:出于性能原因,某些数值运算使用 C 语义而不是 Python 语义。例如,这包括在除以零时引发异常,或由数学函数完成的其他检查 。通过使用 Codon 编译器的
-numerics=py标志,可以严格遵守 Python 语义。请注意,这不会将ints 更改为 64 位。 - 模块:虽然大多数常用的内置模块都有codon原生实现,但少数尚未实现。但是,这些仍然可以通过 python 导入在 Codon 中使用
安装 Codon
Linux (x86_64)、macOS (x86_64和arm64) 的预构建二进制文件随每个版本一起提供。
方法 1:下载和安装:/bin/bash -c "$(curl -fsSL https://exaloop.io/install.sh)"
方法 2:
git clone https://github.com/facebookexperimental/codon.git
cd codon
./setup.sh方法 3:github 直接下载,解压后得到 codon-deploy,把 codon-deploy 移到了 /usr/local 目录下,然后在 .bashrc 添加路径:export PATH=/usr/local/codon-deploy/bin:$PATH
添加完成后,执行:source .bashrc
codon 帮助:codon -h

示例:codon 运行 Python 代码
def fib(n):
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
fib(1000)Codon 编译器有许多选项和模式
# 编译、运行
codon run fib.py
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
# 编译并运行启用了优化的程序
codon run -release fib.py
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
# 编译为启用了优化的可执行文件
codon build -release -exe fib.py
./fib
# 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
# 编译成LLVM IR文件与优化启用
codon build -release -llvm fib.py
# outputs file fib.ll可以从 Codon 导入和使用任何 Python 包 (需要将 CODON_PYTHON 环境变量设置为 CPython 共享库, 正如文档中解释的那样 docs )。例如:
from python import matplotlib.pyplot as plt
data = [x**2 for x in range(10)]
plt.plot(data)
plt.show()这个素数计数示例展示了 Codon 的 OpenMP 支持,通过添加一行来启用。@par 注释告诉编译器并行化下面的 for 循环,在本例中使用动态调度、块大小为100和16个线程。
from sys import argv
def is_prime(n):
factors = 0
for i in range(2, n):
if n % i == 0:
factors += 1
return factors == 0
limit = int(argv[1])
total = 0
@par(schedule='dynamic', chunk_size=100, num_threads=16)
for i in range(2, limit):
if is_prime(i):
total += 1
print(total)codon 支持编写和执行GPU内核。这里有一个计算 Mandelbrot 集合的例子:
import gpu
MAX = 1000 # maximum Mandelbrot iterations
N = 4096 # width and height of image
pixels = [0 for _ in range(N * N)]
def scale(x, a, b):
return a + (x/N)*(b - a)
@gpu.kernel
def mandelbrot(pixels):
idx = (gpu.block.x * gpu.block.dim.x) + gpu.thread.x
i, j = divmod(idx, N)
c = complex(scale(j, -2.00, 0.47), scale(i, -1.12, 1.12))
z = 0j
iteration = 0
while abs(z) <= 2 and iteration < MAX:
z = z**2 + c
iteration += 1
pixels[idx] = int(255 * iteration/MAX)
mandelbrot(pixels, grid=(N*N)//1024, block=1024)GPU编程也可以使用 @par 语法和 @par(GPU =True) 来完成。
Codon 语言
Codon 是一种 Python 兼容的语言,许多 Python 程序只需要很少的修改就可以工作,如果了解 Python,你就已经知道 99% 的 Codon。
:https://docs.exaloop.io/codon/language/basics
如果真要区分 Codon 和 Python 的关系,可以类比 C++ 之于 C
Codon 中调用 Python
通过两种方式从 Codon 中调用 Python
- from python import 允许从现有 Python 模块导入和调用 Python 函数。Python 很多 package 是不被 codon 支持的(可以粗略的理解为不兼容),可以通过 from python import xxx 进行 "借用"
- @python 允许直接在 Codon 中编写 Python 代码。
为了使用这些功能,必须将 CODON_PYTHON 环境变量设置为相应的 Python 共享库。
注意,仅支持 Python 版本 3.6 及更高版本。
vim ~/.bashrc 添加下面内容
Codon 默认的 Python库是
libpython.so,但是 Debian 使用的是具体的名字,如libpython.3.10.so,所以在编译的时候会报错找不到依赖库,执行命令(注意Python版本),创建一个软连接即可:ln -s /usr/lib/x86_64-linux-gnu/libpython3.10.so /usr/lib/x86_64-linux-gnu/libpython.so
方式 1:from python import
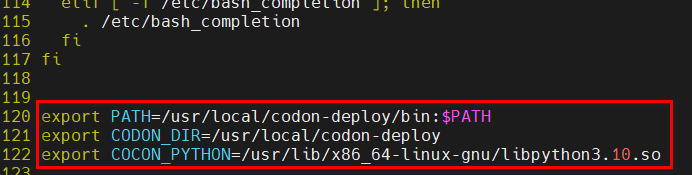
假设在 mymodule.py 中定义了一个 Python 函数:
def multiply(a, b):
return a * b可以在 Codon 中使用 from python import 调用此函数,并指示适当的调用和返回类型:
from python import mymodule.multiply(int, int) -> int
print(multiply(3, 4)) # 12确保 PYTHONPATH 环境变量包含 mymodule.py 的路径。from python import 不需要指定显式类型,在这种情况下,Codon 会直接对 Python 对象进行操作,并根据需要将 Codon 类型转换为 Python 类型:
from python import numpy as np # Codon will call NumPy through CPython's API
x = np.array([1, 2, 3, 4]) * 10
print(x) # [10 20 30 40]方式 2:@python
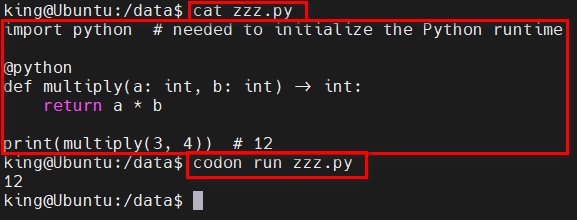
Codon 程序可以直接执行由 @Python 修饰过的 "Python函数":
import python # needed to initialize the Python runtime
@python
def multiply(a: int, b: int) -> int:
return a * b
print(multiply(3, 4)) # 12执行效果:
这使得调用 Python 模块(如 NumPy)变得非常容易:
@python
def myrange(n: int) -> List[int]:
from numpy import arange
return list(arange(n))
print(myrange(5)) # [0, 1, 2, 3, 4]数据转换
Codon 使用了两个新魔法方法来在 Python之间传输数据:
- __to_py__:在给定 Codon 对象的情况下生成一个 Python 对象(C 语言为 PyObject*)。
- __from_py__:在给定 Python 对象的情况下生成一个codon对象。
import python # needed to initialize the Python runtime
o = (42).__to_py__() # type of 'o' is 'cobj', equivalent to a pointer in C
print(o) # 0x100e00610
n = int.__from_py__(o)
print(n) # 42Codon 通过将 __to_py__ 调用的结果包装在名为 pyobj 的新类的实例中来存储这些结果,该类可以正确处理底层 Python 对象的引用计数。然后,pyobjs 上的所有操作都通过 CPython 的 API。
Python 直接执行
Codon 包含一个名为 codon 的 Python 包 ,它允许 Python 代码库中的函数或方法由 Codon 的 JIT 编译和执行。codon库 可以用
pip安装:pip install codon-jit该库将尝试使用已安装的 Codon 版本。如果 codon 安装在非标准路径上,需要设置环境变量 CODON_DIR 为 Codon 安装路径。
@codon.jit 装饰器使注解的 Python 函数由 Codon 编译,并自动将标准 Python 对象转换为原生 Codon 对象。例如:
import codon
from time import time
def is_prime_python(n):
if n <= 1:
return False
for i in range(2, n):
if n % i == 0:
return False
return True
@codon.jit
def is_prime_codon(n):
if n <= 1:
return False
for i in range(2, n):
if n % i == 0:
return False
return True
t0 = time()
ans = sum(1 for i in range(100000, 200000) if is_prime_python(i))
t1 = time()
print(f'[python] {ans} | took {t1 - t0} seconds')
t0 = time()
ans = sum(1 for i in range(100000, 200000) if is_prime_codon(i))
t1 = time()
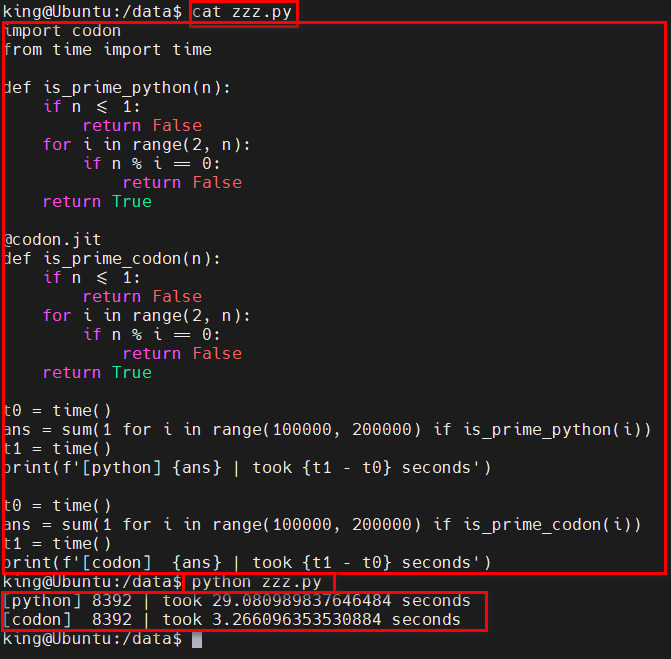
print(f'[codon] {ans} | took {t1 - t0} seconds')执行结果:可以看到 codon 装饰过的比 Python 原生快 10 倍。。。
@par(并行化 for 循环),但是在带标注的函数中使用时,必须加上前导下划线,即 _@par。
import codon
@codon.jit(debug=True)
def is_prime_codon_par(n):
if n <= 1:
return False
_@par(schedule='dynamic', chunk_size=10000, num_threads=16)
for i in range(2, n):
if n % i == 0:
return False
return True
print(is_prime_codon_par(13))执行结果:

Codon JIT 是一个用于加速 Python 代码执行的工具,但它并非支持 Python 所有的标准库或第三方库。在 Codon JIT 中,只有部分标准库和第三方库是可用的,而像 requests 这样的网络请求库可能不在支持范围内。
import codon
import requests
@codon.jit
def func_test():
_@par
for index in range(100):
req = requests.get('https://httpbin.org/')
print(req.status_code)
func_test()如果想在 Codon JIT 中使用 requests 模块,可以尝试将代码中的网络请求部分迁移到 Codon JIT 支持的其他库,比如 http.client,urllib等,或者尝试其他类似功能但更轻量级的库。
注意:JIT 模式尚不支持多态性和继承性
类型转换:@codon.jit 将尝试将任何 Python 类型转换为本机codon类型。目前的转换规则如下:
- int、float、bool、str 和 complex 等基本类型在 Codon 中转换为相同的类型。
- 元组 被转换为 codon元组(然后被编译为等效的 C 结构)。
- 集合类型(如 list、dict 和 set)将转换为相应的 Codon 集合类型,但限制集合中的所有元素必须具有相同的类型。
- 其他类型作为 Python 对象直接传递给 Codon。然后,Codon 将使用其 Python 对象 API( pyobj )来处理和操作这些对象。在内部,这包括调用适当的 CPython C API 函数,例如 PyNumber_Add(a, b) 表示 a + b。
用户定义的类可以通过 @codon.convert 转换为 codon 类:
import codon
@codon.convert
class Foo:
__slots__ = 'a', 'b', 'c'
def __init__(self, n):
self.a = n
self.b = n**2
self.c = n**3
@codon.jit
def total(self):
return self.a + self.b + self.c
print(Foo(10).total()) # 1110将全局变量传递给 codon:全局变量、函数或模块可以通过 @codon.jit 的 pyvars 参数传递给 JIT 函数:
import codon
def foo(n):
print(f'n is {n}')
@codon.jit(pyvars=['foo'])
def bar(n):
foo(n) # calls the Python function 'foo'
return n ** 2
print(bar(9)) # 'n is 9' then '81'这也允许 Codon 访问导入的 Python 模块。所有 pyvar 都作为 Python 对象传递。请注意,默认情况下,JIT 函数可以相互调用。
pyvars 将变量名称作为字符串,而不是变量本身。
调试:@codon.jit 采用一个可选的调试参数,该参数可用于打印调试信息,例如生成的 codon 函数和数据类型:
import codon
@codon.jit(debug=True)
def sum_of_squares(v):
return sum(i**2 for i in v)
print(sum_of_squares([1.4, 2.9, 3.14]))输出:
[codon::jit::execute] code:
def sum_of_squares(v):
return sum(i**2 for i in v)
-----
[python] sum_of_squares(['List[float]'])
[codon::jit::executePython] wrapper:
@export
def __codon_wrapped__sum_of_squares_0(args: cobj) -> cobj:
a0 = List[float].__from_py__(PyTuple_GetItem(args, 0))
return sum_of_squares(a0).__to_py__()
-----
20.229599999999998
在后台,codon 模块维护一个codon JIT 实例,它用于动态编译带注释的 Python 函数。然后,这些函数被包装在另一个生成的函数中,该函数执行类型转换。JIT 维护一个本机函数指针的缓存,这些指针对应于具有具体输入类型的带注释的 Python 函数。因此,多次调用 JIT 函数不会重复调用整个 Codon 编译器管道,而是重用缓存的函数指针。
尽管从 Python 到 codon 的对象转换通常很便宜,但它们确实会带来很小的开销,这意味着 @codon.jit 最适合昂贵和/或长时间运行的操作,而不是短期操作。出于同样的原因,在 codon 中可以完成的工作越多越好,而不是反复来回转移。
Python 扩展
codon 包括一个名为 pyext 的构建模式,用于生成 Python 扩展(传统上用 C、C++ 或 Cython 编写):codon build -pyext extension.codon # add -release to enable optimizations
codon build -pyext 接受以下选项:
- -o<输出对象>:将编译结果写入指定文件。
- -module <模块名称>:指定生成的 Python 模块的名称。
建议 在 Python 3.9 及更高版本中使用 pyext 构建模式。
用 codon 编写的扩展函数通常应该是完全类型的:
def foo(a: int, b: float, c: str): # return type will be deduced
return a * b + float(c)pyext 构建模式将自动生成所有必要的包装器和钩子,用于将用 Codon 编写的函数转换为可从 Python 调用的函数。
未显式键入的函数参数将被视为泛型 Python 对象,并通过 CPython API 进行操作。
在codon中也可以进行函数重载:
def bar(x: int):
return x + 2
@overload
def bar(x: str):
return x * 2这将导致单个 Python 函数 bar() 在运行时根据参数的类型调度到正确的codon bar()(或在无效的输入类型上引发 TypeError)。
codon 类定义也可以通过 @dataclass(python=True) 装饰器转换为 Python 扩展类型:
@dataclass(python=True)
class Vec:
x: float
y: float
def __init__(self, x: float = 0.0, y: float = 0.0):
self.x = x
self.y = y
def __add__(self, other: Vec):
return Vec(self.x + other.x, self.y + other.y)
def __add__(self, other: float):
return Vec(self.x + other, self.y + other)
def __repr__(self):
return f'Vec({self.x}, {self.y})'现在在 Python 中(假设我们编译为模块 vec):
from vec import Vec
a = Vec(x=3.0, y=4.0) # Vec(3.0, 4.0)
b = a + Vec(1, 2) # Vec(4.0, 6.0)
c = b + 10.0 # Vec(14.0, 16.0)高级:并行性和多线程
- OpenMP(Open Multi-Processing)是一种并行编程模型,用于编写多线程和共享内存并行程序。它提供了一套指令集和库函数,使得开发者能够利用多核处理器和共享内存系统的并行计算能力。
- OpenMP 的主要目标是简化并行程序的编写,并提供可移植性,使得程序员可以在不同的平台上编写具有并行能力的代码,而无需对底层体系结构进行详细的了解。
- 使用 OpenMP,可以通过在源代码中插入特定的编译指示(pragma)来标记需要并行执行的代码段。这些编译指示会告诉编译器如何将代码转换为并行执行的形式,并利用多线程来执行任务。
- OpenMP 提供了一些常用的指令和函数,用于控制并行执行、分配任务、同步线程等操作。这些指令和函数可以在 C、C++ 和 Fortran 等编程语言中使用。
- OpenMP 广泛应用于科学计算、数据分析、图像处理等领域,特别适用于那些需要处理大规模数据集或需要高性能计算的应用程序。
总结:OpenMP 是一个用于并行编程的标准,它简化了多线程编程的复杂性,提供了一种可移植且高效的方式来实现并行计算。
codon 通过 OpenMP 支持开箱即用的并行性和多线程。下面是一个示例:
@par
for i in range(10):
import threading as thr
print('hello from thread', thr.get_ident())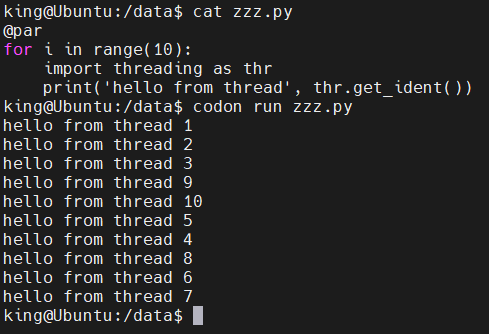
默认情况下,并行循环将使用所有可用线程 ( 默认线程数是CPU核数 )。可以把上面改成range(1000) ,查看输出结果,就可以看出 线程数等于CPU核数。
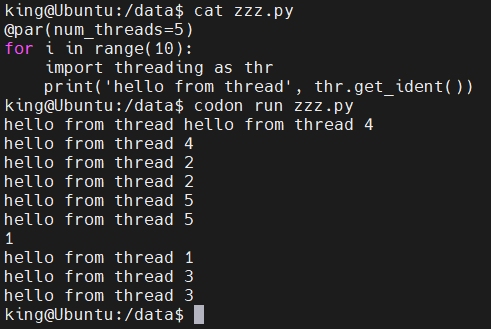
也可以使用 OMP_NUM_THREADS 环境变量指定的线程数。也可以直接在 @par 线上给出 线程数 :
@par(num_threads=5)
for i in range(10):
import threading as thr
print('hello from thread', thr.get_ident())执行结果:
@par 支持多个 OpenMP 参数,包括
num_threads(int):运行循环时使用的线程数schedule(str):静态、动态、引导式、自动或运行时chunk_size(int): 对循环选代进行分区时的块大小。ordered(bool): 循环迭代是否应该以相同的顺序执行collapse(int): 要折叠到单个选代空间中的循环嵌套数
其他 OpenMP 参数(private、shared、reduction(缩减:增加、或者减少))由编译器自动推断。例如,以下循环
a = 0
@par
for i in range(N):
a += foo(i)将自动生成变量 A 的约简。
修改并行部分中的共享对象(如列表或字典)需要使用锁或关键部分来完成。
示例:使用动态调度和块大小为 16 的 100 个线程上的并行循环,查找达到用户定义限制的素数:
from sys import argv
def is_prime(n):
factors = 0
for i in range(2, n):
if n % i == 0:
factors += 1
return factors == 0
limit = int(argv[1])
total = 0
@par(schedule='dynamic', chunk_size=100, num_threads=16)
for i in range(2, limit):
if is_prime(i):
total += 1
print(total)执行结果:
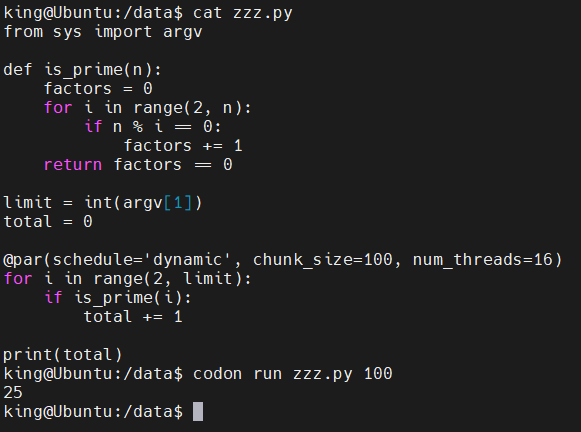
当每个循环迭代花费的时间大致相同时,静态计划效果最佳,而当每次迭代的持续时间不同时,动态计划更胜一筹。由于计算整数的因数对于较大的整数需要更多时间,因此我们在这里使用动态计划。
@par 还支持 C/C++ OpenMP 编译指示字符串。例如上面示例中的@par行也可以写成:
# same as: @par(schedule='dynamic', chunk_size=100, num_threads=16)
@par('schedule(dynamic, 100) num_threads(16)')
不同种类的循环
for 循环可以遍历任意生成器,但 OpenMP 的并行循环结构仅适用于
for i in range(a, b, c)(c是一个常数)。对于 for i in some_generator() 的 for 循环,使用基于任务的方法来代替,其中每个循环迭代都作为一个独立的任务执行。Codon 编译器还将列表上的迭代(for a in some_list)转换为命令式 for 循环,这意味着这些循环可以使用 OpenMP 的循环并行性来执行。
OpenMP 构造
OpenMP 的所有 API 函数都可以在 Codon 中直接访问。例如:
import openmp as omp
print(omp.get_num_threads())
omp.set_num_threads(32)OpenMP 的临界、主、单一和有序结构可以通过相应的装饰器应用:
import openmp as omp
@omp.critical
def only_run_by_one_thread_at_a_time():
print('critical!', omp.get_thread_num())
@omp.master
def only_run_by_master_thread():
print('master!', omp.get_thread_num())
@omp.single
def only_run_by_single_thread():
print('single!', omp.get_thread_num())
@omp.ordered
def run_ordered_by_iteration(i):
print('ordered!', i)
@par(ordered=True)
for i in range(100):
only_run_by_one_thread_at_a_time()
only_run_by_master_thread()
only_run_by_single_thread()
run_ordered_by_iteration(i)对于更细粒度的锁定,请考虑使用线程模块中的锁:
from threading import Lock
lock = Lock() # or RLock for reentrant lock
@par
for i in range(100):
with lock:
print('only one thread at a time allowed here')高级:管道
codon 使用管道运算符扩展了核心 Python 语言。可以链接多个函数和生成器以形成管道。流水线阶段可以是常规函数或生成器。对于标准函数,该函数仅应用于输入数据,并将结果传送到管道的其余部分,类似于 F# 的函数管道。另一方面,如果阶段是生成器,则生成器生成的值将延迟传递到管道的其余部分,这在许多方面反映了 Bash 中管道的实现方式。请注意,codon 确保生成器管道不会收集任何数据,除非明确请求,从而允许以流式处理方式处理数 TB 的数据,而无需内存和最小的 CPU 开销。
def add1(x):
return x + 1
2 |> add1 # 3; equivalent to add1(2)
def calc(x, y):
return x + y**2
2 |> calc(3) # 11; equivalent to calc(2, 3)
2 |> calc(..., 3) # 11; equivalent to calc(2, 3)
2 |> calc(3, ...) # 7; equivalent to calc(3, 2)
def gen(i):
for i in range(i):
yield i
5 |> gen |> print # prints 0 1 2 3 4 separated by newline
range(1, 4) |> iter |> gen |> print(end=' ') # prints 0 0 1 0 1 2 without newline
[1, 2, 3] |> print # prints [1, 2, 3]
range(100000000) |> print # prints range(0, 100000000)
range(100000000) |> iter |> print # not only prints all those numbers, but it uses almost no memory at allcodon 将链接任何实现__iter__的东西,编译器将尽可能地优化生成器。管道和生成器的组合可用于实现高效的流式处理管道。
codon 编译器可以执行优化,以更改通过管道传递的元素的顺序。因此,在使用流水线时,最好不要依赖顺序。如果需要维护顺序,请考虑使用常规循环或将索引与通过管道发送的每个元素一起传递。
并行管道
由于臭名昭著的全局解释器锁,CPython 和许多其他实现都无法利用并行性,这是一种互斥锁,可防止多个线程同时执行 Python 字节码。与 CPython 不同,Codon 没有这样的限制,并且支持完全多线程。为此,Codon 支持 并行管道算子
||>,它在语义上类似于标准管道运算符,只是它允许管道的其余部分并行处理通过它发送的元素。因此,将串行程序转换为并行程序通常只需要在 codon 中添加一个字符。此外,单个管道可以包含多个并行管道,从而产生嵌套并行性。
range(100000) |> iter ||> print # 打印出所有这些数字,可能是随机排列的
range(100000) |> iter ||> process ||> clean # 并行运行进程,然后并行清理数据Codon 将自动调度进程并尽快清理要执行的功能。您可以通过 OMP_NUM_THREADS 环境变量来控制线程数。
在内部,Codon 编译器使用 OpenMP 任务后端为并行管道生成代码。从逻辑上讲,并行管道运算符类似于并行 for 循环:并行管道之后的管道部分被概述为由 OpenMP 运行时任务生成例程调用的新函数(如 C++ 中的 omp 任务 #pragma 并在概述的段后添加同步点(#pragma omp taskwait)。
Codon 的 中间表示
在类型检查之后,但在本机代码生成之前,Codon 编译器使用称为 CIR 的新功能 ,其中发生了许多更高级别的优化、转换和分析。CIR 提供了一个全面的框架,用于编写新的优化或分析,而无需处理繁琐的抽象语法树 (AST)。:https://docs.exaloop.io/codon/advanced/ir
2、Python 调用其他语言的实现
使用 C/C++ 实现
当 Python 面临运算密集型任务时,其速度总是显得力不从心。要提升 Python 代码运行速度有多种方法,如 ctypes、cython、CFFI 等,本篇文章主要从 ctypes 方面介绍如何提升 Python 的运行速度 。ctypes 是 Python 的内置库,利用 ctypes 可以调用 C/C++ 编译成的 so 或 dll 文件 (so 存在 linux/MacOS 中,dll 存在于 windows) ,简单而言,就是将计算压力较大的逻辑利用 C/C++ 来实现,然后编译成 so 或 dll 文件,再利用 ctypes 加载进 Python,从而将计算压力大、耗时较长的逻辑交于 C/C++ 去执行。如 Numpy、Pandas 这些库其底层其实都是 C/C++ 来实现的 。
纯 Python 实现
为了对比出使用 ctypes 后程序运行速度的变化,先使用纯 Python 代码实现一段逻辑,然后再利用 C 语言去实现相同的逻辑 。这里为了模仿运算密集任务,实现一段逻辑用于计算一个集合中点与点之间的距离以及实现一个操作字符串的逻辑,具体代码如下:
import time
import random
import timeit
# 点
class Point(object):
def __init__(self, x, y):
self.x = x
self.y = y
class Test(object):
def __init__(self, string, nb):
self.string = string
self.points = []
# 初始化点集合
for i in range(nb):
self.points.append(Point(random.random(), random.random()))
self.distances = []
# 增量字符串
def increment_string(self, n):
tmp = ""
# 每个字符做一次偏移
for c in self.string:
tmp += chr(ord(c) + n)
self.string = tmp
# 这个函数计算列表中每个点之间的距离
def distance_between_points(self):
for i, a in enumerate(self.points):
for b in self.points:
# 距离公式
self.distances.append(((b.x - a.x) ** 2 + (b.y - b.x) ** 2) ** 0.5)
def main():
test = Test("A nice sentence to test.", 10000)
test.increment_string(-5) # 偏移字符串中的每个字符
test.distance_between_points() # 计算集合中点与点之间的距离
if __name__ == '__main__':
cost_time = timeit.timeit(main, number=1)
print(f'纯Python执行耗时: {cost_time}')
上述代码中,定义了 Point 类型,其中有两个属性,分别是 x 与 y,用于表示点在坐标系中的位置 ,然后定义了 Test 类,其中的 increment_string () 方法用于操作字符串,主要逻辑就是循环处理字符串中的每个字符,首先通过 ord () 方法将字符转为 unicode 数值,然后加上对应的偏移 n,接着在通过 chr () 方法将数值转换会对应的字符 。此外还实现了 distance_between_points () 方法,该方法的主要逻辑就是利用双层 for 循环,计算集合中每个点与其他点的距离。使用时,创建了 10000 个点进行程序运行时长的测试 。多次执行这份代码,其运行时间大约在 39.4 左右
使用 ctypes 提速度
要使用 ctypes,首先就要将耗时部分的逻辑通过 C 语言实现,并将其编译成 so 或 dll 文件,因为我使用的是 MacOS,所以这里会将其编译成 so 文件 ,先来看一下上述逻辑通过 C 语言实现的具体代码,如下:
#include<stdlib.h>
#include<math.h>
// 点结构
typedef struct s_point
{
double x;
double y;
} t_point;
typedef struct s_test
{
char*sentence;// 句子
int nb_points;
t_point *points;// 点
double*distances;// 两点距离,指针
} t_test;
// 增量字符串
char* increment_string(char* str, int n)
{
for(int i =0; str[i]; i++)
// 每个字符做一次偏移
str[i]= str[i]+ n;
return(str);
}
// 随机生成点集合
void generate_points(t_test *test,int nb)
{
// calloc () 函数用来动态地分配内存空间并初始化为 0
// 其实就是初始化变量,为其分配内存空间
t_point *points = calloc(nb +1,sizeof(t_point));
for(int i =0; i < nb; i++)
{
points[i].x = rand();
points[i].y = rand();
}
// 将结构地址赋值给指针
test->points = points;
test->nb_points = nb;
}
// 计算集合中点的距离
void distance_between_points(t_test *test)
{
int nb = test->nb_points;
// 创建变量空间
double* distances = calloc(nb * nb +1,sizeof(double));
for(int i =0; i < nb; i++)
for(int j =0; j < nb; j++)
// sqrt 计算平方根
distances[i * nb + j]= sqrt((test->points[j].x - test->points[i].x)*(test->points[j].x - test->points[i].x)+(test->points[j].y - test->points[i].y)*(test->points[j].y - test->points[i].y));
test->distances = distances;
}
其中具体的逻辑不再解释,可以看注释理解其中的细节,通过 C 语言实现后,接着就可以通过 gcc 来编译 C 语言源文件,将其编译成 so 文件 ,命令如下:
// 生成 .o 文件
gcc -c fastc.c
// 利用 .o 文件生成so文件
gcc -shared -fPIC -o fastc.so fastc.o
获得了 fastc.so 文件后,接着就可以利用 ctypes 将其调用并直接使用其中的方法了,需要注意的是「Windows 系统体系与 Linux/MacOS 不同,ctypes 使用方式会有差异」 ,至于 ctypes 的具体用法,后面会通过单独的文章进行讨论。ctypes 使用 fastc.so 的代码如下:
import ctypes
from ctypes import *
from ctypes.util import find_library
import time
# 定义结构,继承自ctypes.Structure,与C语言中定义的结构对应
class Point(ctypes.Structure):
_fields_ = [
('x', ctypes.c_double),
('y', ctypes.c_double)
]
class Test(ctypes.Structure):
_fields_ = [
('sentence', ctypes.c_char_p),
('nb_points', ctypes.c_int),
('points', ctypes.POINTER(Point)),
('distances', ctypes.POINTER(c_double)),
]
# Lib C functions
_libc = ctypes.CDLL(find_library('c'))
_libc.free.argtypes = [ctypes.c_void_p]
_libc.free.restype = ctypes.c_void_p
# Lib shared functions
_libblog = ctypes.CDLL("./fastc.so")
_libblog.increment_string.argtypes = [ctypes.c_char_p, ctypes.c_int]
_libblog.increment_string.restype = ctypes.c_char_p
_libblog.generate_points.argtypes = [ctypes.POINTER(Test), ctypes.c_int]
_libblog.distance_between_points.argtypes = [ctypes.POINTER(Test)]
if __name__ == '__main__':
start_time = time.time()
# 创建
test = {}
test['sentence'] = "A nice sentence to test.".encode('utf-8')
test['nb_points'] = 0
test['points'] = None
test['distances'] = None
c_test = Test(**test)
ptr_test = ctypes.pointer(c_test)
# 调用so文件中的c语言方法
_libblog.generate_points(ptr_test, 10000)
ptr_test.contents.sentence = _libblog.increment_string(ptr_test.contents.sentence, -5)
_libblog.distance_between_points(ptr_test)
_libc.free(ptr_test.contents.points)
_libc.free(ptr_test.contents.distances)
print('ctypes run time: %s' % str(time.time() - start_time))
多次执行这份代码,其运行时间大约在 1.2 左右
python 2.py
ctypes run time:1.2614238262176514
相比于纯 Python 实现的代码快了 30 倍有余
有人可能会提及使用 asyncio 异步的方式来提升 Python 运行速度,但这种方式只能提高 Python 在 IO 密集型任务中的运行速度,对于运算密集型的任务效果并不理想。
Pybind11
Pybind11 是一个轻量级的仅头文件库,它在 Python 中暴露 C++ 类型,反之亦然,主要用于创建现有 C++ 代码的 Python 绑定,它的目标和语法类似于 Boost.Python,相对大而全的 Boost 更加轻量。可是使用 C++ 来编写 Python 包。
构建上可以参考官方的样例:https://github.com/pybind/python_example
#include <pybind11/pybind11.h>
#define STRINGIFY(x) #x
#define MACRO_STRINGIFY(x) STRINGIFY(x)
int add(int i, int j) {
return i + j;
}
namespace py = pybind11;
PYBIND11_MODULE(python_example, m) {
m.doc() = R"pbdoc(
Pybind11 example plugin
-----------------------
.. currentmodule:: python_example
.. autosummary::
:toctree: _generate
add
subtract
)pbdoc";
m.def("add", &add, R"pbdoc(
Add two numbers
Some other explanation about the add function.
)pbdoc");
m.def("subtract", [](int i, int j) { return i - j; }, R"pbdoc(
Subtract two numbers
Some other explanation about the subtract function.
)pbdoc");
#ifdef VERSION_INFO
m.attr("__version__") = MACRO_STRINGIFY(VERSION_INFO);
#else
m.attr("__version__") = "dev";
#endif
}使用 Rust 实现
PyO3
PyO3 是 Python 的 Rust 绑定,包括用于创建本地 Python 扩展模块的工具。还支持从 Rust 二进制文件运行 Python 代码并与之交互。相比 pybind11,受限于 C++,Rust 工具链相对更完善一点,打包上有 maturin 方案,体验更好。
使用 Java 实现
3、Numba
官网:https://numba.pydata.org/
官网文档:https://numba.readthedocs.io/en/stable/user/installing.html
JIT 是什么
jit 的全称是 Just-in-time,在 numba 里面则特指 Just-in-time compilation(即时编译),它是一种编译技术,下面的对比即可对 jit 进行清晰的定位
编译方式
- 动态编译(dynamic compilation):指的是“在运行时进行编译”;与之相对的是事前编译(ahead-of-time compilation,简称AOT),也叫静态编译(static compilation)
- JIT编译(just-in-time compilation)狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即时编译”。JIT编译是动态编译的一种特例。JIT编译一词后来被泛化,时常与动态编译等价;但要注意广义与狭义的JIT编译所指的区别
- 自适应动态编译(adaptive dynamic compilation)也是一种动态编译,但它通常执行的时机比JIT编译迟,先让程序“以某种式”先运行起来,收集一些信息之后再做动态编译。这样的编译可以更加优化。
注意事项
- 但是jit技术并不总是能够如预期的加速代码,甚至有可能降低代码效率,这于代码的结构有关,不过绝大多数情况还是能够有明显的效果的
- JIT 之于 Python:Python 啥都好,就是太“动态”了,导致去运行效率不高,jit之于python那简直是如虎添翼
Numba 是一个开源的 JIT 编译器,通过 装饰器,Numba 可以将带注释的 Python 和 NumPy 代码的子集转换为高效的机器码。( numba 它只能加速数值计算函数,只能在numpy 包基础上进行加速。否则就绕开吧。可以看看 ctypes 和 cython。推荐直接使用 C、C++开发,然后使用 ctypes 粘起来 ) 。numba 使用 LLVM 编译器架构将纯Python代码生成优化过的机器码,将面向数组和使用大量数学的python代码优化到与c,c++和Fortran类似的性能,而无需改变Python的解释器。
numba 所完成的工作就是:解析Python函数的ast语法树并加以改造,添加类型信息;
将带类型信息的ast语法树通过llvmpy动态地转换为机器码函数,然后再通过和ctypes类似的技术为机器码函数创建包装函数供Python调用。
安装 numba
pypi ( 目前版本 0.58.1 ):https://pypi.org/project/numba/
安装:pip install numba
快速入门
5 分钟快速入门:https://numba.readthedocs.io/en/stable/user/5minguide.html
Numba 对那些代码有效
This depends on what your code looks like, if your code is numerically orientated (does a lot of math), uses NumPy a lot and/or has a lot of loops, then Numba is often a good choice. In these examples we’ll apply the most fundamental of Numba’s JIT decorators,
@jit, to try and speed up some functions to demonstrate what works well and what does not.
大致意思:如果你的代码是 "面向数字的(做很多数学运算),或者使用 NumPy,或者有很多循环",那么 Numba 通常是一个不错的选择。如下代码:
from numba import jit
import numpy as np
x = np.arange(100).reshape(10, 10)
@jit(nopython=True) # Set "nopython" mode for best performance, equivalent to @njit
def go_fast(a): # Function is compiled to machine code when called the first time
trace = 0.0
for i in range(a.shape[0]): # Numba likes loops
trace += np.tanh(a[i, i]) # Numba likes NumPy functions
return a + trace # Numba likes NumPy broadcasting
print(go_fast(x))下面的代就不适用 Numba
from numba import jit
import pandas as pd
x = {'a': [1, 2, 3], 'b': [20, 30, 40]}
@jit
def use_pandas(a): # Function will not benefit from Numba jit
df = pd.DataFrame.from_dict(a) # Numba doesn't know about pd.DataFrame
df += 1 # Numba doesn't understand what this is
return df.cov() # or this!
print(use_pandas(x))注意,Numba 无法理解 Pandas,因此 Numba 只会通过解释器运行这段代码,导致的结果是增加 Numba 内部开销的成本!
什么是 nopython 模式
Numba 的 @jit 装饰器 基本上以两种编译模式运行:
- nopython 模式:编译 "装饰过的Python函数",使其完全没有 Python 解释器的参与。这是使用 Numba 装饰器的最佳实践方法,因为它可以带来最好的性能。
- object 模式:Should the compilation in
nopythonmode fail, Numba can compile usingobject mode. This is a fall back mode for the@jitdecorator ifnopython=Trueis not set。如果没有设置 @jit 装饰器为nopython=True,则当 nopython 模式失败,Numba 会使用 object 模式,这是 @jit 的回退模式。在这种模式,可以被 Numba 识别的就编译成机器码运行,不能被识别的就交由Pyhon解释器执行。这样就会降低性能,导致的结果是增加 Numba 内部开销的成本!
测量 Numba 的性能
衡量 Numba JIT 对代码影响的一个好方法是对执行进行计时 使用 TimeIt 模块 功能;它们测量执行的多次迭代,
from numba import jit
import numpy as np
import time
x = np.arange(100).reshape(10, 10)
@jit(nopython=True)
def go_fast(a): # Function is compiled and runs in machine code
trace = 0.0
for i in range(a.shape[0]):
trace += np.tanh(a[i, i])
return a + trace
# DO NOT REPORT THIS... COMPILATION TIME IS INCLUDED IN THE EXECUTION TIME!
start = time.perf_counter()
go_fast(x)
end = time.perf_counter()
print("Elapsed (with compilation) = {}s".format((end - start)))
# NOW THE FUNCTION IS COMPILED, RE-TIME IT EXECUTING FROM CACHE
start = time.perf_counter()
go_fast(x)
end = time.perf_counter()
print("Elapsed (after compilation) = {}s".format((end - start)))Numba 装饰器
Numba 有很多的装饰器,除了已经看到的 @jit,还有:
-
@njit- 这是一个别名,因为它很常见 使用!@jit(nopython=True) -
@vectorize- 生成 NumPy s(使用所有方法 支持)。文档在这里。ufuncufunc -
@guvectorize- 产生 NumPy 通用 s. 文档在这里。ufunc -
@stencil- 将函数声明为类似模板操作的内核。文档在这里。 -
@jitclass- 用于 JIT 感知类。文档在这里。 -
@cfunc- 声明一个函数用作本机回调(要调用 来自 C/C++ 等)。文档在这里。 -
@overload- 注册你自己的函数实现,以便在 nopython 模式,例如 .文档在这里。@overload(scipy.special.j0)
某些装饰器中提供的额外选项:
ctypes/cffi/cython 互操作性:
numba的用法很简单,基本上就是用 jit 这个装饰器和一些类型对象。下面的程序列出 numba 所支持的所有类型:
print(list(map(lambda x=None: print(x), dir(numba))))
print(list(map(lambda x=None: print(x), numba.__dict__.values())))
Numba 的使用
import timeit
import numba
from numba import jit
def func_1(x, y):
s = 0
for i in range(x, y):
s += i
return s
@jit(nopython=True)
def func_2(x, y):
s = 0
for i in range(x, y):
s += i
return s
def main():
# print(list(map(lambda x=None: print(x), dir(numba))))
# print(list(map(lambda x=None: print(x), numba.__dict__.values())))
cost_time = timeit.timeit(lambda x=None: func_1(1, 100000000), number=1)
print(f'cost_time ---> {cost_time}')
cost_time = timeit.timeit(lambda x=None: func_2(1, 100000000), number=1)
print(f'cost_time ---> {cost_time}')
if __name__ == '__main__':
main()
pass
执行结果:
cost_time ---> 2.8881187999941176
cost_time ---> 0.12966140000207815
参考手册
:https://numba.readthedocs.io/en/stable/reference/index.html
4、Taichi
官网:https://taichi-lang.cn/
github:https://github.com/taichi-dev/taichi
太极编程语言中文论坛 (文档、精选demo):https://forum.taichi-lang.cn/
官网介绍:
- Taichi 是一门开源的、嵌入在 Python 中的并行编程语言
- 语法简单,上手容易,运行高效
- 大大简化高性能图形学、数值计算、人工智能应用开发
安装:pip install --upgrade taichi
import taichi as ti
import taichi.math as tm
ti.init(arch=ti.gpu)
n = 320
pixels = ti.field(dtype=float, shape=(n * 2, n))
@ti.func
def complex_sqr(z): # complex square of a 2D vector
return tm.vec2(z[0] * z[0] - z[1] * z[1], 2 * z[0] * z[1])
@ti.kernel
def paint(t: float):
for i, j in pixels: # Parallelized over all pixels
c = tm.vec2(-0.8, tm.cos(t) * 0.2)
z = tm.vec2(i / n - 1, j / n - 0.5) * 2
iterations = 0
while z.norm() < 20 and iterations < 50:
z = complex_sqr(z) + c
iterations += 1
pixels[i, j] = 1 - iterations * 0.02
gui = ti.GUI("Julia Set", res=(n * 2, n))
for i in range(1000000):
paint(i * 0.03)
gui.set_image(pixels)
gui.show()官方文档
应用示例
:https://forum.taichi-lang.cn/t/topic/2963
5、Nuitka
6、MatxScript
:https://github.com/bytedance/matxscript
文档:https://bytedance.github.io/matxscript/zh-CN/index.html
字节开源的 MATXScript (Matx) 是一个高性能可扩展的 Python 编译器,可以自动化把 Python 类或函数翻译成 C++,运行时完全没有 Python 开销。另外,Matx 通过 pmap 原语支持无锁多线程。目前 Matx 主要支持机器学习相关的应用
- 编译 (Script):Script 可将 Python 函数/类 编译为 C++ 函数/类, 并支持在 Python 或者 C++ 中直接调用。预期他们将会获得一致的行为。
- 算子 (Op):算子是编译后的 C++ 函数,包括普通函数和类成员函数,是用于通过跟踪构建计算图的基本组件。
在经过编译(script) 后,将用户的 Python 代码转换为了 C++,在与使用 Python 解释器运行的代码相比,生成的 C++ 代码带来了几个数量级的性能提升。除此之外,还要求用户对其 Python 代码进行类型标注,这样可以进一步提升性能。
安装:pip3 install matxscript
import matx
print(matx.__version__)
示例:
import matx
import timeit
def fib(n: int) -> int:
if n <= 1:
return n
else:
return fib(n - 1) + fib(n - 2)
if __name__ == '__main__':
fib_script = matx.script(fib)
# test on Macbook with m1 chip
print(f'Python execution time: {timeit.timeit(lambda: fib(30), number=10)}s') # 1.59s
print(f'Matx execution time: {timeit.timeit(lambda: fib_script(30), number=10)}s') # 0.03s快速开始
相关示例:https://github.com/bytedance/matxscript/blob/main/examples/text2ids/text2ids.py
Import 相关依赖
注意:在涉及到matx编译部分的Python代码需要进行类型标注,因此需要 import typing 模块下的一些 Python 常用类型。
from typing import List, Dict, Callable, Any, AnyStr
import matx
OP 创建
Operator(Op),可以是一个函数,或者是一个类的成员函数
class Text2Ids:
def __init__(self, texts: List[str]) -> None:
self.table: Dict[str, int] = {}
for i in range(len(texts)):
self.table[texts[i]] = i
def lookup(self, words: List[str]) -> List[int]:
return [self.table.get(word, -1) for word in words]op = Text2Ids(["hello", "world"])
examples = "hello world unknown".split()
ret = op.lookup(examples)
print(ret)
# should print out [0, 1, -1]Script 编译
cpp_text2id = matx.script(Text2Ids)(["hello", "world"])
ret = cpp_text2id.lookup(examples)
print(ret)
# should print out [0, 1, -1]Trace 保存编译产物
def wrapper(inputs):
return cpp_text2id.lookup(inputs)
# trace and save
traced = matx.trace(wrapper, examples)
traced.save("demo_text2id")
# load and run
# for matx.load, the first argument is the stored trace path
# the second argument indicates the device for further running the code
# -1 means cpu, if for gpu, just pass in the device id
loaded = matx.load("demo_text2id", -1)
# we call 'run' interface here to actually run the traced op
# note that the argument is a dict, where the key is the arg name of the traced function
# and the value is the actual input data
ret = loaded.run({"inputs": examples})
print(ret)
# should print out [0, 1, -1]C++代码调用产物
#include <iostream>
#include <map>
#include <string>
#include <vector>
#include <matxscript/pipeline/tx_session.h>
using namespace ::matxscript::runtime;
int main(int argc, char* argv[]) {
// test case
std::unordered_map<std::string, RTValue> feed_dict;
feed_dict.emplace("inputs", List{Unicode(U"hello"), Unicode(U"world"), Unicode(U"unknown")});
std::vector<std::pair<std::string, RTValue>> result;
const char* module_path = argv[1];
const char* module_name = "model.spec.json";
{
auto sess = TXSession::Load(module_path, module_name);
auto result = sess->Run(feed_dict);
for (auto& r : result) {
std::cout << "result: " << r.second << std::endl;
}
}
return 0;
}MX_CFLAGS=$(python3 -c 'import matx; print( " ".join(matx.get_cflags()) ) ' )
MX_LINK_FLAGS=$(python3 -c 'import matx; print( " ".join(matx.get_link_flags()) ) ' )
RUNTIME_PATHS=$(python3 -c 'import matx; print( " ".join(["-Wl,-rpath," + p for p in matx.cpp_extension.library_paths()]) )')
g++ -O2 -fPIC -std=c++14 $MX_CFLAGS $MX_LINK_FLAGS ${RUNTIME_PATHS} text2ids.cc -o text2ids
./text2ids demo_text2id
# should print out
# result: [0, 1, -1]
多维数组 (NDArray)
NDArray 是 MatxScript 中表示多维矩阵的数据类型,目前只实现了简单的数据装载和转换操作。 类似numpy,matx 实现了自己的 NDArray 数据结构来表示多维数组。目前NDArray主要定位为各个深度学习框架(pytorch/tensorflow/tvm)的tensor结构进行桥接数据结构,并未在NDArray上定义完备的算子。
Script 编译
通过 matx.script 可以将 Python 的类/函数翻译成 C++ 对应的实现,并提供统一接口,以 Op 的形式集成到整体流程中。
注意:所有的类的成员变量和函数的声明需要强制 类型标注
示例 1:
import matx
# make a class and compile it as a operator
class foo:
def __init__(self, i: int) -> None: # annotation of the function signature
self._i: int = i # annotation of class member
def add(self, j: int) -> int:
print("going to return self._i + j")
return self._i + j
def hello(self) -> None:
print("hello world")
obj = matx.script(foo)(1)
rc = obj.add(2)示例 2:
import matx
# make a function and compile it as a operator
@matx.script
def boo(a: str, b: str) -> str: # annotation of the function signature
return a + b
rc = boo("ab", "cd")Trace
Trace 可以追踪记录 Python 代码执行过程,生成 Graph,并支持一键打包,方便分发部署到任意地方执行。
并行支持
原生 python 受限制于 全局解释器锁 (GIL),多线程并不会真正并行执行,在 Matx 中,我们提供了 matx.pmap 原语,提供了后台并行执行能力。
import matx
from typing import Any, List
def lower_impl(s: str) -> str:
return s.lower()
def MyParallelLower(inputs: List[str]) -> List[str]:
return matx.pmap(lower_impl, inputs)
p_lower = matx.script(MyParallelLower)
print(p_lower(["Hello"]))正则表达式
Matx 内置了一个基于 PCRE 的高性能正则引擎,目前单独封装了接口,可以如下使用
import matx
from typing import Any, List
class Spliter:
def __init__(self) -> None:
self.regex: Any = matx.Regex(
r'(([\v\f\r\n]+)|(?<=[^?。;,!!?][?。;,!!?])(?=[^?。;,!!?]))')
def __call__(self, ss: str) -> List[str]:
return self.regex.split(ss)
spliter = matx.script(Spliter)()
print(spliter("hELLO \v WORLD"))matx 模块
:https://bytedance.github.io/matxscript/zh-CN/apidoc/modules.html