持续更新中…
文章目录
1 传统方法
这里传统方法指的是可以显而易见的方法,比如for循环等等的优化
1.1 对称矩阵(symmetric matrix)
比如如下矩阵
沿着主对角线,左右两边是对称的。
传统情况下,大家可能在给矩阵元素赋值时,采用的是

for i in range(len(matrix)):
for j in range(len(matrix)):
if i == j:
mat[i][j]=...
else:
mat[i][j]=...
这里对i,j都循环,比如矩阵大小为10*10,那么循环了100次
由于矩阵对称,所以实际上可以减少循环次数。
在循环体时,j的循环可以从i开始,然后另对角线两边相等即可,如下
for i in range(4):
for j in range(i,4):
if i==j:
mat[i][j] = ...
else:
mat[i][j] = ...
mat[j][i] = mat[i][j]
在计算数据量比较大的时候,特别是循环体比较多的时候,这个时候一般有比较好的提升速度。
比如我在计算某稍微复杂的循环时候,速度从0.18分钟提升到0.13分钟,提升27%的速度。增加循环次数之后从1.61提升到1.185,提升26%
1.2避免循环体内调用
1.2.1, 数据提取
假如已经在文本中保存有 的数据( ),当存在循环体时,不要将文本在循环体中调用,而应该放到循环体外。即避免多次调用,实现一次调用即可
data = np.loadtxt('x.txt')
for l in range(len(x))
data[l]...
避免如下
for l in range(len(x))
data = np.loadtxt('x.txt')
data[l]...
当函数比较多的时候不容易看出来是否有问题,比如下面这个函数,判断是否重复读取文件
import healpy as hp
import numpy as np
import settings
import time
st = settings.Settings()
class Synchrotron():
"""The contribution from synchrotron to TOD
unit: MJy/sr
"""
def __init__(self):
self.sync_ampl = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ampl.fits',
field=(0,1,2))
self.sync_ind = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ind.fits',
field=(0))
def sync_map(self,nu):
"""Return synchrotron maps"""
return self.sync_ampl*(nu/st.nu_sync_ref)**self.sync_ind
def map_smoothing(map_in,fwhm):
"""Return smoothed map
- fwhm : radians
"""
return hp.smoothing(map_in,fwhm,verbose=False)
def FWHM(nu):
"""Return full width at half maximum for a given frequency
in the unit of arcmin
- nu : array_like with unit in GHz
- D : optical aperture of telescope,
- fwhm : radians
"""
lam = st.c/(nu*10**9) #unit: m
fwhm = 1.22*lam/st.D #unit: rad
# fwhm_arcmin = fwhm*180/np.pi*60 # arcmin
return fwhm
if __name__ == "__main__":
t = time.time()
band = np.arange(1,1000)
sync_maps = np.array([map_smoothing(Synchrotron().sync_map(nu),FWHM(nu)) for nu in band])
np.save('sync_maps_smoothed',sync_maps)
e = time.time()
print(e-t)
很明显我们看到数据读取是在函数内的,所以当最后对nu循环的时候会重复读取文件,判断是否重复读取文件的一个小技巧是,在文件下打印出一串字符,如
def __init__(self):
self.sync_ampl = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ampl.fits',
field=(0,1,2))
print("*************")
self.sync_ind = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ind.fits',
field=(0))
如果*******重复出现,说明重复调用了,如下:
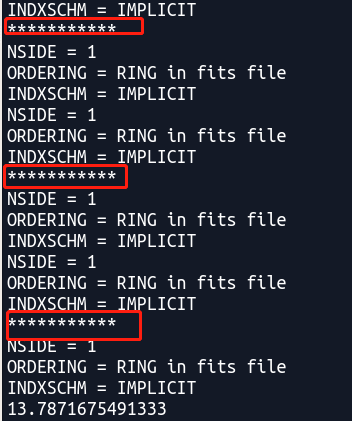
实际上我们知道python是解释型语言,每一次调用的时候都是一行一行读取的,所以一旦经过Synchrotron这个类,就会一行一行读到提取数据,使得速度变慢。而C,C++都是编译型语言,一旦进行一次之后,就不会这么慢了。所以方法是将读取数据放在最外面
import healpy as hp
import numpy as np
import settings
import time
st = settings.Settings()
sync_ampl = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ampl.fits',
field=(0,1,2))
sync_ind = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ind.fits',
field=(0))
class Synchrotron():
"""The contribution from synchrotron to TOD
unit: MJy/sr
"""
def __init__(self):
pass
def sync_map(self,nu):
"""Return synchrotron maps"""
return sync_ampl*(nu/st.nu_sync_ref)**sync_ind
def map_smoothing(map_in,fwhm):
"""Return smoothed map
- fwhm : radians
"""
return hp.smoothing(map_in,fwhm,verbose=False)
def FWHM(nu):
"""Return full width at half maximum for a given frequency
in the unit of arcmin
- nu : array_like with unit in GHz
- D : optical aperture of telescope,
- fwhm : radians
"""
lam = st.c/(nu*10**9) #unit: m
fwhm = 1.22*lam/st.D #unit: rad
# fwhm_arcmin = fwhm*180/np.pi*60 # arcmin
return fwhm
if __name__ == "__main__":
t = time.time()
band = np.arange(1,1000)
sync_maps = np.array([map_smoothing(Synchrotron().sync_map(nu),FWHM(nu)) for nu in band])
np.save('sync_maps_smoothed',sync_maps)
e = time.time()
print(e-t)
上面放在循环内的花了13秒,而这种放外面的画了0.5秒,这还是数据非常小的情况,一旦数据量很大,读取都要花非常多的时间。
此外: 可能有的人会觉得上面将文件提取放在首行会不自在,没有在函数中调用的可读性高(因为类synchrotron的确应该作为一个模块,让所有的与它相关的东西都放一块,包括提取它的数据)。那么我们也可以在计算的时候单独使其实例化,然后使用实例化之后的值,同时也可以不再让循环进入Synchrotron类(同理可以在类中使用print("*******")测试,可以看到只会打印一次*******)
import healpy as hp
import numpy as np
import settings
import time
st = settings.Settings()
class Synchrotron():
"""The contribution from synchrotron to TOD
unit: MJy/sr
"""
def sync_ampl(self,config=None):
sync_ampl = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ampl.fits',
field=(0,1,2))
return sync_ampl
def sync_ind(self):
"""unit: unitless"""
sync_ind = hp.read_map(r'../data/psm/components/synchrotron/test_sync_ind.fits',
field=(0))
return sync_ind
def sync_map(nu,ampl,ind):
"""Return synchrotron maps"""
return ampl*(nu/st.nu_sync_ref)**ind
def map_smoothing(map_in,fwhm):
"""Return smoothed map
- fwhm : radians
"""
return hp.smoothing(map_in,fwhm,verbose=False)
def FWHM(nu):
"""Return full width at half maximum for a given frequency
in the unit of arcmin
- nu : array_like with unit in GHz
- D : optical aperture of telescope,
- fwhm : radians
"""
lam = st.c/(nu*10**9) #unit: m
fwhm = 1.22*lam/st.D #unit: rad
# fwhm_arcmin = fwhm*180/np.pi*60 # arcmin
return fwhm
if __name__ == "__main__":
t = time.time()
band = np.arange(1,1000)
ampl = Synchrotron().sync_ampl() #实例化
ind = Synchrotron().sync_ind() #实例化
#下面开始进入循环,这样就不会再调用Synchrotron类了。
sync_maps = np.array([map_smoothing(sync_map(nu,ampl,ind),FWHM(nu)) for nu in band])
np.save('sync_maps_smoothed',sync_maps)
e = time.time()
print(e-t)
3 使用numpy
3.1 np.sum求和代替for求和
1, 使用numpy进行矩阵数组计算,矢量运算等,而不是python自身函数。
由于numpy很多是c-based, 运算速度可以接近c,我们选择numpy来进行数据处理。
以numpy.sum()求和为例
a) 使用for来求和
import numpy as np
import time
np.random.seed(0) #种子生成器
x = np.random.randint(1,100,20000000) #产生2千万个1-100之间的整数矢量
y = 0
s = time.time()
for i in range(len(x)): #用for来求和
y+=x[i]
e = time.time()
print(y)
print('time cost: %.5f'%(e-s))
b) 使用np.sum()
import numpy as np
import time
np.random.seed(0)
x = np.random.randint(1,100,20000000)
s = time.time()
y = np.sum(x)
e = time.time()
print(y)
print('time cost: %.5f'%(e-s))
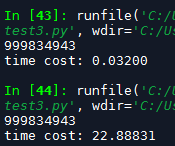
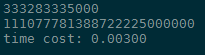
第一个是np.sum结果,花了0.03秒,for花了22.89秒,相差763倍。
更多numpy相关见:https://blog.csdn.net/zhangxinyu11021130/article/details/76736038
https://juejin.im/entry/599aa96c518825242860fb28/
2 两层for循环时改为矩阵,然后使用numpy的矩阵运算
3.2 numpy数组代替for循环(1)
这里以求
来举例
例,计算
这里采用的计算
的式子是(维基-pi):以防有人不能进维基百科,截图如下:
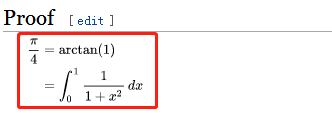
如果我们只是为了知道
的值,可以调用积分包计算即可,但是我们的目的是要对比数组代替for来提升计算速度,所以不调用包。对于数值积分而言,我们可以使用求和代替积分:
import numpy as np
import time
def pi_comput(step):
partial_pi = 0
dx = 1/step
for i in np.arange(0,1,dx):
partial_pi += 4/(1+i*i)*dx
return partial_pi
t0 = time.time()
print('pi is :>>> ',pi_comput(10000000))
t1 = time.time()
print('time cost: %s sec'%(t1-t0))
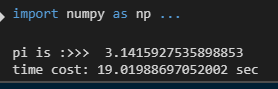
可以看到当我们取10000000步长时,已经可以比较准确的计算出pi了,但是时间却花了19秒,我们的目标是减少时间使用,现在使用数组的方法,即事先给定一个数组,数组的长度是我们划分的长度,如step=100,则表示将0到1分成100分,长度则是100.
import numpy as np
import time
def pi_comput(step):
dx = 1/step
x = np.arange(0,1,dx) #x = np.array([0,dx,2dx,...,1])
return np.sum(4/(1+x*x)*dx) #x*x直接数组计算,对应元素相乘
t0 = time.time()
print('pi is :>>> ',pi_comput(10000000))
t1 = time.time()
print('time cost: %s sec'%(t1-t0))
通过上面的数组直接运算,花的时间是:

上面for循环的时间是这个的115倍!!
进一步提升
对于这个问题,我们可以进一步提升速度
由于我们看到计算公式中有乘以
的项,对于
而言,我们可以将
提出来,因此公式变为:
那么上面的代码即最后一句改为
return np.sum(4/(1+x*x))*dx dx提到了求和外面
这样避免了每次计算dx的乘法和求和,时间如下

进一步提升速度见3.3节
3.3 在3.2的基础上使用多进程提升速度
这里我们使用了多进程的方法结合numpy的方法一起使用,结果是非常明显的,花的时间是0.052秒!!
(笔者在另一博文(可点击)写得非常详细)
3.4 numpy数组代替for循环(2)
这里举一个数学/量子力学中常见的球谐函数展开的例子,为了简单,已经简化这个问题。问题描述为:
求Cl
这里m的取值是从-ell到ell。
1)两层循环
大家最容易想到的就是两层循环搞定:
import numpy as np
import time
import matplotlib.pyplot as plt
lmin = 2
lmax = 1000
t0 = time.time()
Cl = []
for l in range(lmin,lmax+1):
ans = 0
for m in range(-l,l+1):
ans = ans + l*np.exp(-m*(m+1))
Cl.append(ans)
t1 = time.time()
print('Time costs: >>>',t1-t0)
plt.loglog(np.arange(len(Cl)),Cl)
plt.show()
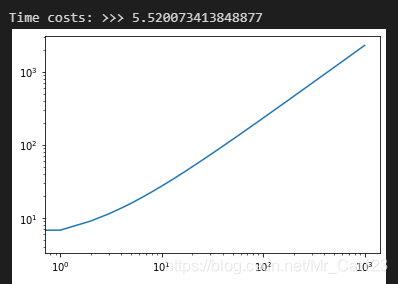
两层循环在l到1000的时候花了5秒
2)一层循环
python里面循环是一定要想方设法避免的,因为它花的时间太多了,而通常的避免方法就是使用数组运算,这样就将时间复杂度推给了空间复杂度(数组比较庞大的时候很占内存)
import numpy as np
import time
import matplotlib.pyplot as plt
lmin = 2
lmax = 1000
t0 = time.time()
Cl = []
for l in range(lmin,lmax+1):
m = np.arange(-1,l+1)
ans = np.sum(l*np.exp(-m*(m+1)))
Cl.append(ans)
t1 = time.time()
print('Time costs: >>>', t1-t0)
plt.loglog(np.arange(len(Cl)), Cl)
plt.show()
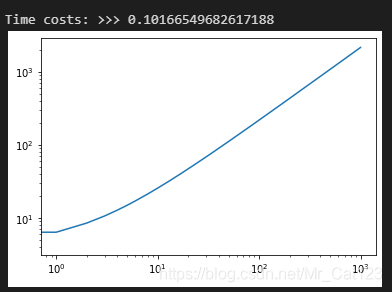
同样的计算结果,只花了0.1秒,速度提高了55倍,特别是在ell比较大的时候提高更是明显的。
上面可以看到,当ell很大时,m是很大的一个数组,比较占内存,尤其是多维数组的情形,所以牺牲内存换取时间。
3.5 数组代替for----求积分
3.5.1 一重积分
实际上上面关于计算 的例子中已经使用了数组代替for求积分,具体看上面的内容
3.5.2 二重积分
现在要计算
不调用积分函数的情况下,手动写代码数值计算。最一般的想法肯定是两个for循环
import numpy as np
import time
s = time.time()
t = 0
step_x = 0.01
step_y = 0.02
for x in np.arange(0,10,step_x):
for y in np.arange(0,20,step_y):
t = t+x*y*step_x*step_y
print('answer: ',t)
e = time.time()
print('time cost: ',(e-s))
花了2.87秒

通过上面计算
的例子,我们知道可以减少一层for循环,于是改进如下:
import numpy as np
import time
s = time.time()
t = 0
step_x = 0.01
step_y = 0.02
y = np.arange(0,20,step_y)
for x in np.arange(0,10,step_x):
t = t+np.sum(x*y*step_y*step_x)
print('answer: ',t)
e = time.time()
print('time cost: ',(e-s))

只花了0.089秒,速度提高了30倍。
进一步改进:由于我们知道,可以将公因子step_x*step_y提到括号外,所以可以改进如下:
import numpy as np
import time
s = time.time()
t = 0
step_x = 0.01
step_y = 0.02
y = np.arange(0,20,step_y)
for x in np.arange(0,10,step_x):
t = t+np.sum(x*y)
print('answer: ',t*step_x*step_y)
e = time.time()
print('time cost: ',(e-s))

只花了0.056秒
现在尝试将第一个for也去掉,这样就需要改成一个二维数组(或者说矩阵)
import numpy as np
import time
s = time.time()
x = np.arange(0,10,step_x)
y = np.arange(0,20,step_y)
t = np.sum(np.mat(x).T*np.mat(y))*step_x*step_y
print('answer: ',t)
e = time.time()
print('time cost: ',(e-s))

可以看到没有提升。
在三重积分中是否也是变为矩阵没有提升呢?
3.5.3 三重积分
计算
1) 使用三层for循环
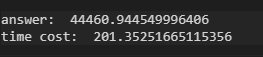
花了超过3分钟!!!
2)使用数组代替其中一层循环(由于数组很快,所以代替那层循环最多的,即代替了对
积分的那层)
import numpy as np
import time
s = time.time()
t = 0
step_x = 0.01
step_y = 0.02
step_z = 0.03
y = np.arange(0,20,step_y)
for x in np.arange(0,10,step_x):
for z in np.arange(0,3,step_z):
t = t+np.sum(x*y*z)
print('answer: ',t*step_x*step_y*step_z)
e = time.time()
print('time cost: ',(e-s))

6秒钟!
3) 使用三维数组
在使用三维数组前,我们先尝试一个for+二维数组的形式
import numpy as np
import time
s = time.time()
t = 0
step_x = 0.01
step_y = 0.02
step_z = 0.03
x = np.arange(0,10,step_x)
y = np.arange(0,20,step_y)
for z in np.arange(0,3,step_z):
t = t + np.sum(z*np.mat(x).T*np.mat(y))
print('answer: ',t*step_x*step_y*step_z)
e = time.time()
print('time cost: ',(e-s))

只花了2秒,(注意,上面z是循环次数最少的,所以保留z循环)
进一步改进:上面的
实际上可以提出二维矩阵外面,先求和在乘积,即上面的
t = t + np.sum(z*np.mat(x).T*np.mat(y))
改为:
t = t + z*np.sum(np.mat(x).T*np.mat(y))
时间从2.1秒变为1.769秒

现在使用三维数组:
4. 避免函数互相调用
比如有两个文件。
run.py
program.py
其中program.py文件有两个函数test1和test2,当运行run.py文件时都要调用test1和test2,而test2又需要调用test1里的结果,比如
# program.py
def test1():
ans = 0
for i in range(10000):
ans += i**2
return ans
def test2():
ans = test1()
k = ans**2
return k
# run.py
import program
import time
s = time.time()
ans = test3.test1()
k = test3.test2()
e = time.time()
print(ans)
print(k)
print('time cost: %.5f'%(e-s))
运行时间为
上面test2调用了test1的结果ans,所以在run里面运行test2时实际上重新再运行了一遍test1,相当于多运行了一遍,所以花了一倍的时间。改进如下:
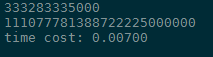
#program.py
#将test1和test2合并
def test1():
ans = 0
for i in range(10000):
ans += i**2
k = ans**2
return ans,k
#run.py
import program
import time
s = time.time()
ans,k = test3.test1()
e = time.time()
print(ans)
print(k)
print('time cost: %.5f'%(e-s))
运行时间为
总结:虽然有时候将不同函数分开写可读性很好,但有时会限制速度,在提高速度的前提下,可以适当将多个函数合并,避免互相调用。
2 优化途径
2.1 使用numba
然而,我在很多情况下使用numba都变慢了,这部分我以后再写