Selenium基本操作
Selenium
-
Selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至进行页面截屏
Selenium
-
安装
-
pip install selenium
-
-
加载网页
-
from selenium import webdriver
-
driver=webdriver.Chrome()
-
driver.get("http://www.baidu.com/")
-
driver.save_screenshot("aa.png")
-
-
定位和操作
-
driver.find_element_by_id("kw").send_keys("小白")
-
driver.find_element_by_id("su").click()
-
-
查看请求
-
driver.page_source
-
driver.get_cookies()
-
driver.current_url
-
-
退出
-
driver.close() 退出当前页面
-
driver.quit() 退出浏览器
-
示例
from selenium import webdriver
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 访问百度页面
wb.get("http://www.baidu.com")会自动打开Chrome浏览器,并访问百度,结果如下:

执行时如遇到以下错误,则是因为没有配置Chrome的webdriver

解决方案如下:
-
访问 chrome://version/ 查看浏览器的版本
-
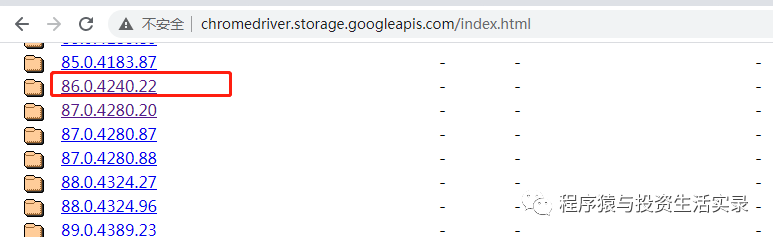
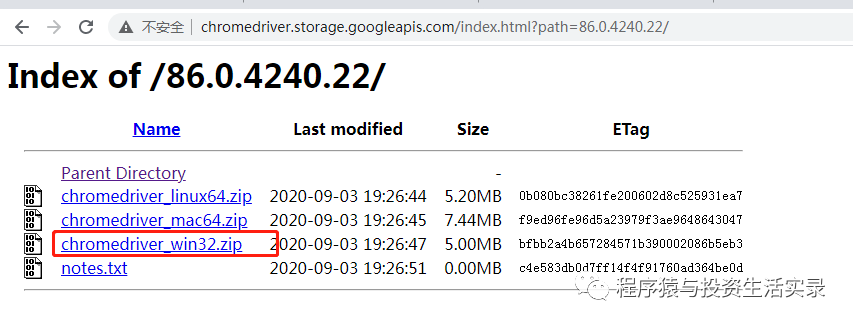
访问浏览器驱动的网址,查找Chrome对应的版本驱动,选择适合自己系统的 http://chromedriver.storage.googleapis.com/index.html
-
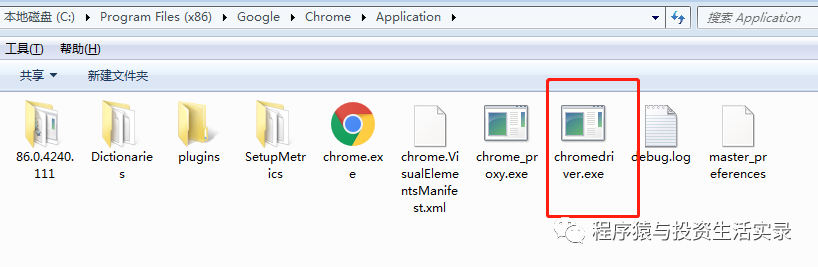
将下载后的驱动文件解压放到c盘浏览器的安装目录下,同时再放一份到Python的安装目录下


浏览器还可以设置为无窗口访问
from selenium import webdriver
# 设置无窗口
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
# 声明Chrome浏览器对象
wb=webdriver.Chrome(options=chrome_options)
# 访问百度页面
wb.get("http://www.baidu.com")常见的浏览器参数
-
参数可参考网址:https://peter.sh/experiments/chromium-command-line-switches/
# 启动就最大化
--start-maximized
# 指定缓存Cache路径
–-disk-cache-dir=”[PATH]“
# 指定Cache大小,单位Byte
–-disk-cache-size=100
# 隐身模式启动
–-incognito
# 禁用弹出拦截
--disable-popup-blocking
# 禁用插件
--disable-plugins
# 禁用图像
--disable-images设置浏览器代理
chrome_options.add_argument('--proxy-server=http://{ip}:{port}')Selenium操作页面元素
selenium 查找元素有两种方法
-
第一种是指定使用哪种方法去查找元素,比如指定 CSS 选择器或者根据 xpath 去查找。
-
第二则是直接使用 find_element() ,传入的第一个参数为需要使用的元素查找方法,第二个参数为查找值。
示例
from selenium import webdriver
from selenium.webdriver.common.by import By
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 访问百度页面
wb.get("http://www.baidu.com")
''' 查找单个元素 '''
# 通过id查找
element = wb.find_element_by_id("kw")
print(element.tag_name)
# 通过name查找
element = wb.find_element_by_name("wd")
print(element.tag_name)
# 通过xpath查找
element = wb.find_element_by_xpath('//*[@id="kw"]')
print(element.tag_name)
# 通过另一种方式查找
element = wb.find_element(By.ID, "kw")
print(element.tag_name)
element = wb.find_element(By.NAME, "wd")
print(element.tag_name)
''' 查找多个元素 '''
print("根据class 属性查找多个元素")
elements=wb.find_elements_by_class_name("s-isindex-wrap")
for ele in elements:
print(ele.tag_name)selenium 页面操作,模仿鼠标点击事件和键盘输入事件
import time
from selenium import webdriver
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 访问百度页面
wb.get("http://www.baidu.com")
# 获取百度搜索框元素
element = wb.find_element_by_id("kw")
# 在搜索框中输入关键词 python
element.send_keys("python")
# 点击"百度一下"按钮
wb.find_element_by_xpath('//*[@id="su"]').click()
# 休眼10秒
time.sleep(10)
# 退出当前页面
wb.close()浏览器操作
请求网页时,可能会存在 AJAX 异步加载的情况。而 selenium 只会加载主网页,并不会考虑到 AJAX 的情况。因此,使用时需要等待一些时间,让网页加载完全后再进行操作。
隐式加载
-
使用隐式等待时,如果 webdriver 没有找到指定的元素,将继续等待指定元素出现,直至超出设定时间,如果还是没有找到指定元素,则抛出找不到元素的异常,默认等待时间为 0。
-
隐式等待是对整个页面进行等待。需要特别说明的是:隐性等待对整个 driver 的周期都起作用,所以只要设置一次即可。
from selenium import webdriver
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 设置隐式等待时间,单位为秒
wb.implicitly_wait(10)
# 访问百度页面
wb.get("http://www.baidu.com")
# 设置搜索关键词
element = wb.find_element_by_id("kw")
element.send_keys("Python")
wb.find_element_by_xpath('//*[@id="su"]').click()
# 页面右边的"百度热榜"
element2 = wb.find_element_by_xpath('//*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1]/td[1]/a')
print(element2)显示等待
-
显式等待是对指定的元素进行等待。首先判定等待条件是否成立,如果成立,则直接返回;如果条件不成立,则等待最长时间为设置的等待时间,如果超过等待时间后仍然没有满足等待条件,则抛出异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 访问百度页面
wb.get("http://www.baidu.com")
# 设置搜索关键词
element = wb.find_element_by_id("kw")
element.send_keys("Python")
wb.find_element_by_xpath('//*[@id="su"]').click()
# 显示等待10秒,直到页面右边的"百度热榜列表"出现
WebDriverWait(wb, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "toplist1-tr")))
# 获取页面右边的"百度热榜"
element2 = wb.find_element_by_xpath('//*[@id="con-ar"]/div[2]/div/div/table/tbody[1]/tr[1]/td[1]/a')
print(element2)浏览器的前进与后退
import time
from selenium import webdriver
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 设置隐式等待时间,单位为秒
wb.implicitly_wait(10)
# 访问百度页面
wb.get("http://www.baidu.com")
time.sleep(5)
# 访问豆瓣
wb.get("https://www.douban.com/")
time.sleep(5)
# 返回上个页面
wb.back()
time.sleep(5)
# 前进到下个页面
wb.forward()浏览器添加cookie
from selenium import webdriver
# 声明Chrome浏览器对象
wb=webdriver.Chrome()
# 访问百度页面
wb.get("http://www.baidu.com")
# 获取当前的cookie
print(wb.get_cookies())
# 添加cookie
wb.add_cookie({'name': 'my_cookie', 'value': 'myCookie'})
# 获取设置的cookie
print(wb.get_cookie('my_cookie'))
# 删除设置的cookie
wb.delete_cookie('my_cookie')程序猿与投资生活实录已改名为 程序猿知秋,WX 公众号同款,欢迎关注!