目录
1)、打开自己的虚拟机,然后将下载好的spark拖或者复制粘贴进主目录中
2)、在桌面上右键打开终端,输入指令:tar -zxvf spark-3.2.4-bin-hadoop2.7.tgz(我下载的是基于2.7的Hadoop的3.2.4版本的spark)
一、安装spark
1、在官网上下载
下载地址:Index of /dist/spark
根据自己hadoop的版本进行下载 (spark的版本不重要重要的是后面是基于hadoop的哪个版本)
2、在虚拟机内进行解压
1)、打开自己的虚拟机,然后将下载好的spark拖或者复制粘贴进主目录中
2)、在桌面上右键打开终端,输入指令:tar -zxvf spark-3.2.4-bin-hadoop2.7.tgz(我下载的是基于2.7的Hadoop的3.2.4版本的spark)

3)、将解压好的spark转移到 /usr/ local中
指令:sudo mv spark-3.2.4-bin-hadoop2.7 /usr/local
需要输入的密码就是自己打开自己虚拟机所使用的密码
二、配置spark的环境
1、配置环境
点击主目录中的.bashrc这个文件,然后输入:
export SPARK_HOME=/usr/local/spark-3.2.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin

2、更新环境
将环境配置好后必须更新环境才能使用
在主目录里右键打开终端,然后输入指令:source .bashrc来更新环境

三、验证spark是否安装完毕
找到spark-3.2.4-bin-hadoop2.7的所在地,点进去,在右键打开终端,输入指令:spark-shell
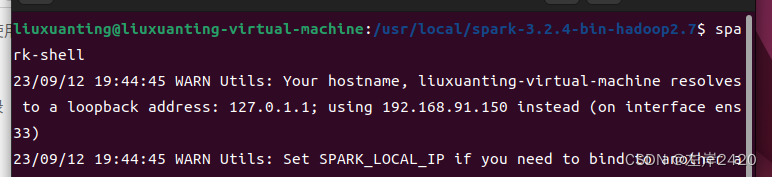
只要出现spark大图标就安装完成
 安装完成!
安装完成!